Въведение
Независимо от технологията на базата данни, е необходимо да имате настройка за наблюдение, както за откриване на проблеми, така и за предприемане на действия, или просто за да знаете текущото състояние на нашите системи.
За целта има няколко инструмента, платени и безплатни. В този блог ще се съсредоточим върху един по-специално:Nagios Core.
Какво е Nagios Core?
Nagios Core е система с отворен код за наблюдение на хостове, мрежи и услуги. Позволява да конфигурирате сигнали и има различни състояния за тях. Позволява внедряването на плъгини, разработени от общността, или дори ни позволява да конфигурираме собствени скриптове за наблюдение.
Как да инсталирам Nagios?
Официалната документация ни показва как да инсталираме Nagios Core на системи CentOS или Ubuntu.
Нека видим пример за необходимите стъпки за инсталиране на CentOS 7.
Необходими са пакети
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipИзтеглете Nagios Core, Nagios Plugins и NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzДобавяне на потребител и група на Nagios
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheИнсталиране на Nagios
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgПриставка Nagios и инсталиране на NRPE
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginДобавяме следния ред в края на нашия файл /usr/local/nagios/etc/objects/command.cfg, за да използваме NRPE при проверка на нашите сървъри:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Нагиос започва
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdДостъп до мрежата
Създаваме потребителя за достъп до уеб интерфейса и можем да влезем в сайта.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://IP_Address/nagios/
 Nagios Web Access
Nagios Web Access Как да конфигурирам Nagios?
Сега, когато имаме инсталиран нашия Nagios, можем да продължим с конфигурацията. За това трябва да отидем до местоположението, съответстващо на нашата инсталация, в нашия пример /usr/local/nagios/etc.
Има няколко различни конфигурационни файла, които ще трябва да създадете или редактирате, преди да започнете да наблюдавате каквото и да било.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: CGI конфигурационният файл съдържа редица директиви, които засягат работата на CGI. Той също така съдържа препратка към основния конфигурационен файл, така че CGI да знаят как сте конфигурирали Nagios и къде се съхраняват дефинициите на вашите обекти.
- htpasswd.users: Този файл съдържа потребителите, създадени за достъп до уеб интерфейса на Nagios.
- nagios.cfg: Основният конфигурационен файл съдържа редица директиви, които влияят върху това как работи демонът Nagios Core.
- обекти: Когато инсталирате Nagios, тук се поставят няколко примерни файла за конфигурация на обекта. Можете да използвате тези примерни файлове, за да видите как работи наследяването на обекти и да научите как да дефинирате свои собствени дефиниции на обекти. Обектите са всички елементи, които участват в логиката за наблюдение и уведомяване.
- resource.cfg: Това се използва за задаване на незадължителен ресурсен файл, който може да съдържа макродефиниции. Макросите ви позволяват да препращате към информацията за хостове, услуги и други източници във вашите команди.
В обектите можем да намерим шаблони, които могат да се използват при създаване на нови обекти. Например, можем да видим, че в нашия файл /usr/local/nagios/etc/objects/templates.cfg има шаблон, наречен linux-server, който ще се използва за добавяне на нашите сървъри.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Използвайки този шаблон, нашите хостове ще наследят конфигурацията, без да се налага да ги указват един по един на всеки сървър, който добавяме.
Също така имаме предварително дефинирани команди, контакти и периоди от време.
Командите ще бъдат използвани от Nagios за неговите проверки и това е, което добавяме в конфигурационния файл на всеки сървър, за да го наблюдаваме. Например PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Имаме възможност да създадем контакти или групи и да посочим кои сигнали искам да достигна до кое лице или група.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}За нашите проверки и сигнали можем да конфигурираме в кои часове и дни искаме да ги получаваме. Ако имаме услуга, която не е критична, вероятно не искаме да се събуждаме призори, така че би било добре да алармираме само в работно време, за да избегнем това.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Нека видим сега как да добавим сигнали към нашите Nagios.
Ще наблюдаваме нашите PostgreSQL сървъри, така че първо ги добавяме като хостове в нашата директория с обекти. Ще създадем 3 нови файла:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}След това трябва да ги добавим към файла nagios.cfg и тук имаме 2 опции.
Добавете нашите хостове (cfg файлове) един по един, като използвате променливата cfg_file (опция по подразбиране) или добавете всички cfg файлове, които имаме в директория, като използвате променливата cfg_dir.
Ще добавим файловете един по един, следвайки стратегията по подразбиране.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgС това ние наблюдаваме нашите домакини. Сега просто трябва да добавим какви услуги искаме да наблюдаваме. За това ще използваме някои вече дефинирани проверки (check_ssh и check_ping) и ще добавим някои основни проверки на операционната система, като натоварване и дисково пространство, наред с други, като използваме NRPE.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаКакво е NRPE?
Nagios Remote Plugin Executor. Този инструмент ни позволява да изпълняваме плъгини Nagios на отдалечен хост по възможно най-прозрачен начин.
За да го използваме, трябва да инсталираме сървъра във всеки възел, който искаме да наблюдаваме, и нашият Nagios ще се свърже като клиент към всеки един от тях, изпълнявайки съответния(те) плъгин(ове).
Как да инсталирам NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpeСлед това редактираме конфигурационния файл /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>И рестартираме услугата NRPE:
[example@sqldat.com ~]# systemctl restart nrpeМожем да тестваме връзката, като изпълним следното от нашия сървър Nagios:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Как да наблюдавам PostgreSQL?
Когато наблюдавате PostgreSQL, има две основни области, които трябва да се вземат предвид:операционна система и бази данни.
За операционната система NRPE има конфигурирани някои основни проверки, като например дисково пространство и натоварване, наред с други. Тези проверки могат да бъдат активирани много лесно по следния начин.
В нашите възли редактираме файла /usr/local/nagios/etc/nrpe.cfg и отиваме на мястото, където са следните редове:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Имената в квадратни скоби са тези, които ще използваме в нашия сървър Nagios, за да активираме тези проверки.
В нашия Nagios редактираме файловете на 3-те възела:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgДобавяме тези проверки, които видяхме по-рано, оставяйки нашите файлове както следва:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}И рестартираме услугата nagios:
[example@sqldat.com ~]# systemctl start nagiosВ този момент, ако отидем в секцията за услуги в уеб интерфейса на нашия Nagios, трябва да имаме нещо като следното:
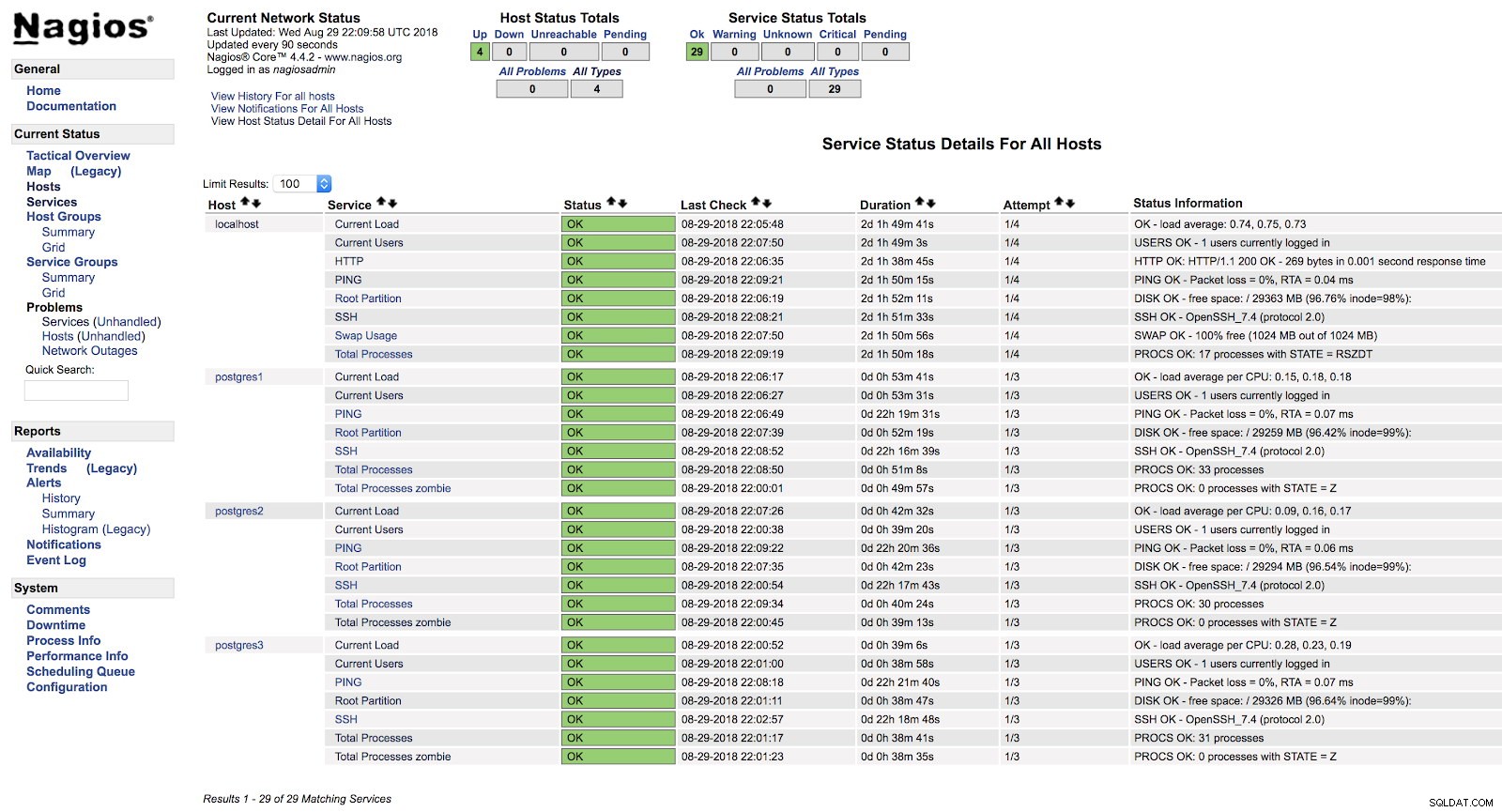 Сигнали за хост на Nagios
Сигнали за хост на Nagios По този начин ще покрием основните проверки на нашия сървър на ниво операционна система.
Имаме още много проверки, които можем да добавим и дори можем да създадем свои собствени проверки (ще видим пример по-късно).
Сега нека видим как да наблюдаваме нашата база данни PostgreSQL с помощта на две от основните плъгини, предназначени за тази задача.
Check_postgres
Един от най-популярните плъгини за проверка на PostgreSQL е check_postgres от Bucardo.
Нека видим как да го инсталираме и как да го използваме с нашата PostgreSQL база данни.
Необходими са пакети
[example@sqldat.com ~]# yum install perl-develИнсталиране
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksТази последна команда създава връзките за използване на всички функции на тази проверка, като например check_postgres_connection, check_postgres_last_vacuum или check_postgres_replication_slots наред с други.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Добавяме в нашия конфигурационен файл NRPE (/usr/local/nagios/etc/nrpe.cfg) реда за изпълнение на проверката, която искаме да използваме:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100В нашия пример добавихме 4 основни проверки за PostgreSQL. Ще наблюдаваме заключване, раздуване, връзка и бекенд.
Във файла, съответстващ на нашата база данни в сървъра Nagios (/usr/local/nagios/etc/objects/postgres1.cfg), добавяме следните записи:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}И след рестартиране на двете услуги (NRPE и Nagios) на двата сървъра, можем да видим нашите сигнали конфигурирани.
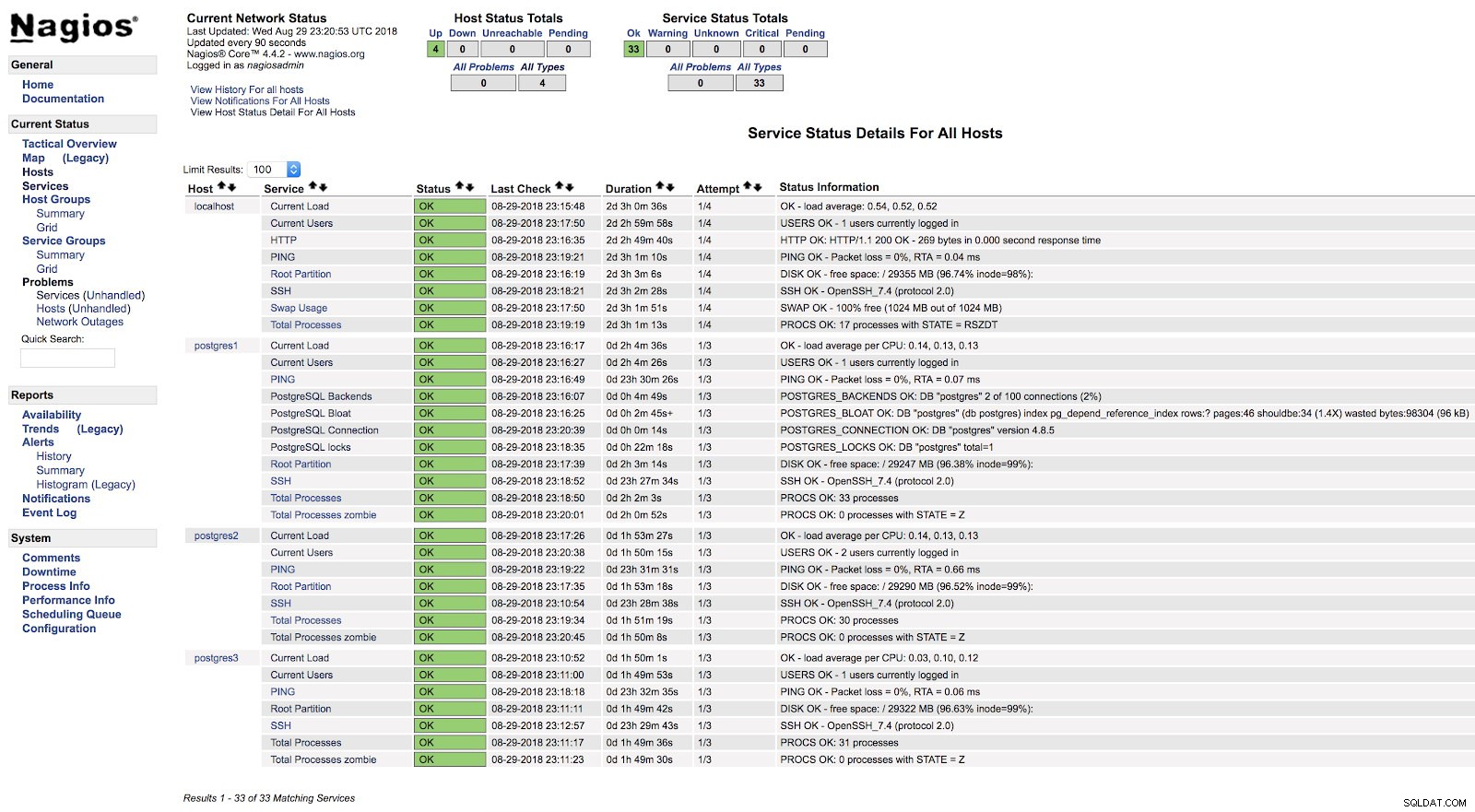 Сигнали на Nagios check_postgres
Сигнали на Nagios check_postgres В официалната документация на приставката check_postgres можете да намерите информация какво още да наблюдавате и как да го направите.
Check_pgactivity
Сега е ред за check_pgactivity, също популярна за наблюдение на нашата PostgreSQL база данни.
Инсталиране
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityДобавяме в нашия конфигурационен файл NRPE (/usr/local/nagios/etc/nrpe.cfg) реда за изпълнение на проверката, която искаме да използваме:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10В нашия пример ще добавим 4 основни проверки за PostgreSQL. Ще наблюдаваме бекендове, връзки, невалидни индекси и ключалки.
Във файла, съответстващ на нашата база данни в сървъра Nagios (/usr/local/nagios/etc/objects/postgres2.cfg), добавяме следните записи:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}И след рестартиране на двете услуги (NRPE и Nagios) на двата сървъра, можем да видим нашите сигнали конфигурирани.
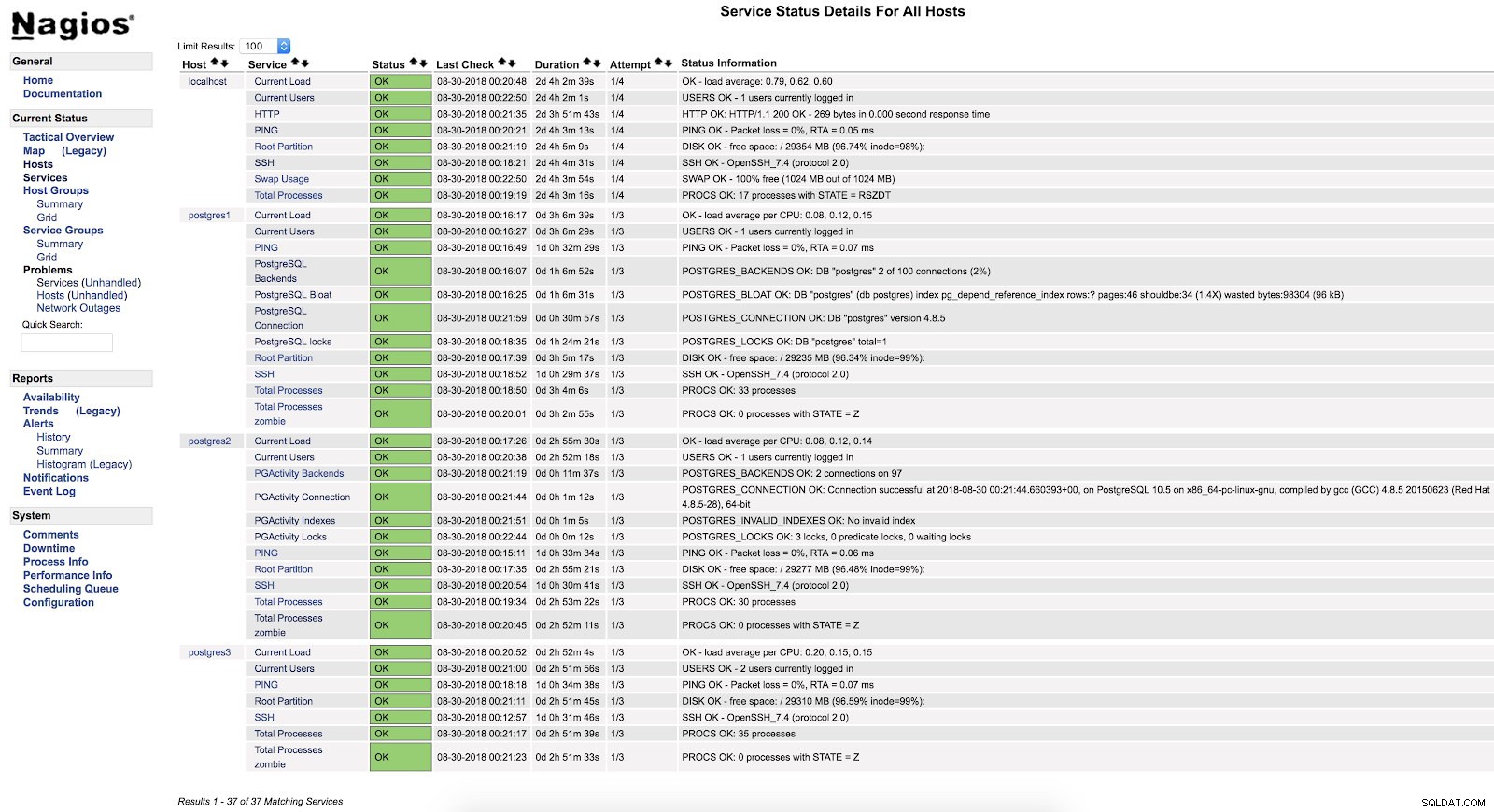 Сигнали за Nagios check_pgactivity
Сигнали за Nagios check_pgactivity Проверете регистъра на грешките
Една от най-важните проверки или най-важната е да проверите нашия регистър за грешки.
Тук можем да намерим различни типове грешки, като FATAL или безизходица, и това е добра отправна точка за анализиране на всеки проблем, който имаме в нашата база данни.
За да проверим нашия регистър за грешки, ще създадем наш собствен скрипт за наблюдение и ще го интегрираме в нашия Nagios (това е само пример, този скрипт ще бъде основен и има много място за подобрение).
Скрипт
Ще създадем файла /usr/local/nagios/libexec/check_postgres_log.sh на нашия PostgreSQL3 сървър.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiВажното в скрипта е да създаде правилно изходите, съответстващи на всяко състояние. Тези изходи се четат от Nagios и всяко число съответства на състояние:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNВ нашия пример ще използваме само 2 състояния, OK и CRITICAL, тъй като се интересуваме само от това дали има грешки от типа FATAL в нашия регистър на грешките през текущия час.
Текстът, който използваме преди излизането си, ще бъде показан от уеб интерфейса на нашия Nagios, така че трябва да е възможно най-ясно, за да го използваме като ръководство за проблема.
След като приключим с нашия скрипт за наблюдение, ще продължим да му даваме разрешения за изпълнение, ще го присвоим на потребителя nagios и ще го добавим към нашия сървър на база данни NRPE, както и към нашия Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Рестартирайте NRPE и Nagios. След това можем да видим нашата проверка в интерфейса на Nagios:
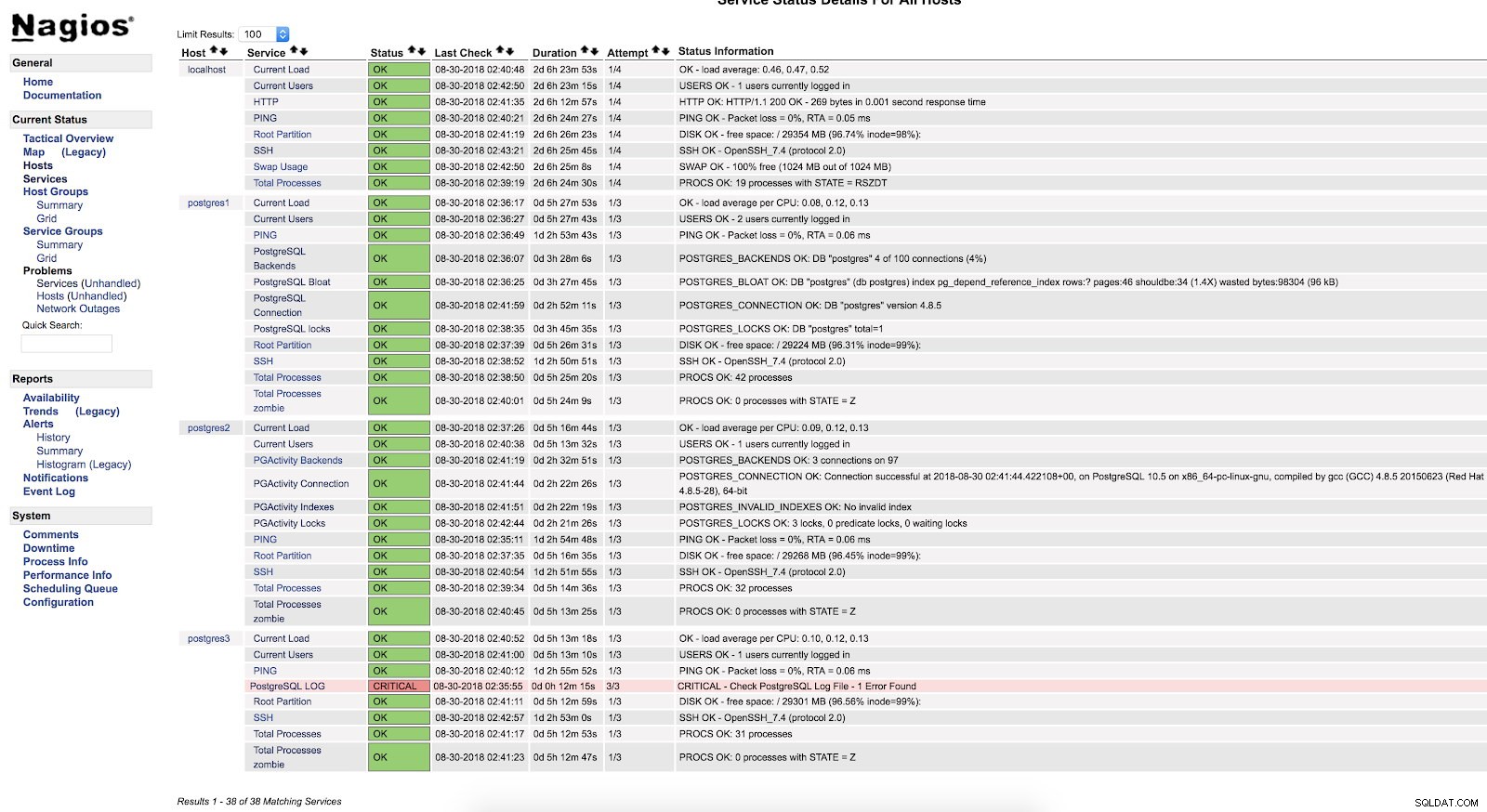 Сигнали за Nagios Script
Сигнали за Nagios Script Както виждаме, той е в КРИТИЧНО състояние, така че ако отидем в дневника, можем да видим следното:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"За повече информация относно това какво можем да наблюдаваме в нашата база данни PostgreSQL, препоръчвам ви да проверите нашите блогове за производителност и мониторинг или този уебинар за ефективността на Postgres.
Безопасност и производителност
Когато конфигурираме каквото и да е наблюдение, било то с помощта на плъгини или наш собствен скрипт, трябва да сме много внимателни с 2 много важни неща – безопасността и производителността.
Когато задаваме необходимите разрешения за наблюдение, трябва да бъдем възможно най-рестриктивни, ограничавайки достъпа само локално или от нашия сървър за наблюдение, използвайки защитени ключове, криптиране на трафика, позволявайки на връзката до минимума, необходим за работа на наблюдението.
По отношение на производителността мониторингът е необходим, но също така е необходимо да се използва безопасно за нашите системи.
Трябва да внимаваме да не генерираме неоправдано висок достъп до диск или да изпълняваме заявки, които влияят негативно върху производителността на нашата база данни.
Ако имаме много транзакции в секунда, генериращи гигабайти регистрационни файлове, и продължаваме да търсим грешки непрекъснато, това вероятно не е най-доброто за нашата база данни. Затова трябва да поддържаме баланс между това, което наблюдаваме, колко често и въздействието върху производителността.
Заключение
Има няколко начина за внедряване на мониторинг или за конфигурирането му. Можем да го направим толкова сложно или просто, колкото искаме. Целта на този блог беше да ви запознае с мониторинга на PostgreSQL с помощта на един от най-използваните инструменти с отворен код. Също така видяхме, че конфигурацията е много гъвкава и може да бъде съобразена с различни нужди.
И не забравяйте, че винаги можем да разчитаме на общността, затова оставям някои връзки, които биха могли да са от голяма полза.
Форум за поддръжка:https://support.nagios.com/forum/
Известни проблеми:https://github.com/NagiosEnterprises/nagioscore/issues
Плъгини Nagios:https://exchange.nagios.org/directory/Plugins
Nagios Plugin за ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol