SQL Server ни предоставя редица функции на прозореца, които ни помагат да извършваме изчисления в набор от редове, без да е необходимо да повтаряме извикванията към базата данни. За разлика от стандартните агрегатни функции, функциите на прозореца няма да групират редовете в един изходен ред, те ще върнат една обобщена стойност за всеки ред, запазвайки отделните идентичности за тези редове. Терминът Window тук не е свързан с операционната система Microsoft Windows, той описва набора от редове, които функцията ще обработи.
Един от най-полезните типове прозоречни функции са функциите на прозореца за класиране, които се използват за класиране на конкретни стойности на полета и категоризирането им според ранга на всеки ред, което води до единична агрегирана стойност за всеки участващ ред. Има четири функции на прозореца за класиране, поддържани в SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK() и NTILE(). Всички тези функции се използват за изчисляване на ROWID за предоставения прозорец с редове по свой собствен начин.
Четири прозоречни функции за класиране използват клаузата OVER(), която дефинира зададен от потребителя набор от редове в рамките на набор от резултати от заявка. Чрез дефиниране на клаузата OVER() можете също да включите клаузата PARTITION BY, която определя набора от редове, които функцията на прозореца ще обработи, като предоставите колони или колони, разделени със запетая, за да дефинирате дяла. Освен това може да бъде включена клаузата ORDER BY, която определя критериите за сортиране в дяловете, през които функцията ще премине през редовете по време на обработка.
В тази статия ще обсъдим как на практика да използваме четири функции на прозореца за класиране:ROW_NUMBER(), RANK(), DENSE_RANK() и NTILE() и разликата между тях.
За да обслужим нашата демонстрация, ще създадем нова проста таблица и ще вмъкнем няколко записа в таблицата с помощта на T-SQL скрипта по-долу:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Можете да проверите дали данните са вмъкнати успешно, като използвате следния оператор SELECT:
SELECT * FROM StudentScore ORDER BY Student_ScoreС приложен сортиран резултат, наборът от резултати е както следва:

ROW_NUMBER()
Функцията за прозорец за класиране ROW_NUMBER() връща уникален пореден номер за всеки ред в дяла на посочения прозорец, като се започне от 1 за първия ред във всеки дял и без да се повтарят или пропускат числата в резултата от класирането на всеки дял. Ако има дублиращи се стойности в набора от редове, идентификационните номера на класирането ще бъдат присвоени произволно. Ако е посочена клаузата PARTITION BY, номерът на реда за класиране ще бъде нулиран за всеки дял. В предварително създадената таблица заявката по-долу показва как да използвате функцията за прозорец за класиране ROW_NUMBER за класиране на редовете в таблицата StudentScore според резултата на всеки ученик:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
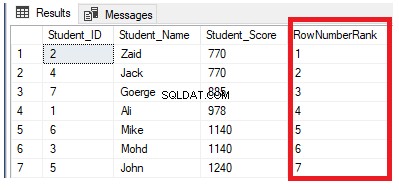
От набора от резултати по-долу става ясно, че функцията на прозореца ROW_NUMBER класира редовете на таблицата според стойностите на колоната Student_Score за всеки ред, като генерира уникален номер на всеки ред, който отразява класирането му Student_Score, започвайки от числото 1 без дубликати или пропуски и работа с всички редове като един дял. Можете също така да видите, че дублиращите се резултати са присвоени на различни рангове на случаен принцип:
Ако модифицираме предишната заявка, като включим клаузата PARTITION BY, за да имаме повече от един дял, както е показано в заявката на T-SQL по-долу:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
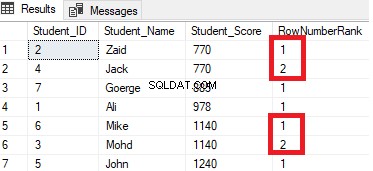
Резултатът ще покаже, че функцията на прозореца ROW_NUMBER ще класира редовете на таблицата според стойностите на колоната Student_Score за всеки ред, но ще се справи с редовете, които имат същата стойност на Student_Score като един дял. Ще видите, че за всеки ред ще бъде генериран уникален номер, отразяващ неговото класиране на Student_Score, като се започне от числото 1 без дубликати или пропуски в рамките на същия дял, нулиране на номера на ранга при преминаване към различна стойност на Student_Score.
Например, учениците с резултат 770 ще бъдат класирани в рамките на този резултат, като му се присвои номер на ранг. Въпреки това, когато бъде преместен на ученик с резултат 885, началният номер на ранга ще бъде нулиран, за да започне отново от 1, както е показано по-долу:
RANK()
Функцията за прозорец за класиране RANK() връща уникален номер на ранг за всеки отделен ред в рамките на дяла според определена стойност на колона, започвайки от 1 за първия ред във всеки дял, със същия ранг за дублиращи се стойности и оставяйки празнини между ранговете; тази празнина се появява в последователността след дублиращите се стойности. С други думи, функцията на прозореца за класиране RANK() се държи като функцията ROW_NUMBER() с изключение на редовете с равни стойности, където ще се класира със същия идентификатор на ранг и ще генерира празнина след него. Ако модифицираме предишната заявка за класиране, за да използваме функцията за класиране RANK():
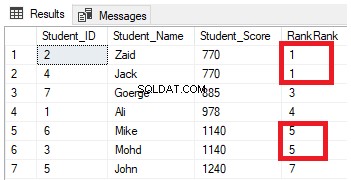
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreЩе видите от резултата, че функцията на прозореца RANK ще класира редовете на таблицата според стойностите на колоната Student_Score за всеки ред, като стойността на класирането отразява неговия Student_Score, започвайки от числото 1, и класира редовете, които имат същия Student_Score с същата стойност на ранга. Можете също да видите, че два реда с Student_Score равен на 770 се класират с една и съща стойност, оставяйки празнина, която е пропуснатото число 2, след втория класиран ред. Същото се случва и с редовете, където Student_Score е равен на 1140, които са класирани със същата стойност, оставяйки празнина, която е липсващото число 6, след втория ред, както е показано по-долу:
Промяна на предишната заявка чрез включване на клаузата PARTITION BY, за да има повече от един дял, както е показано в T-SQL заявката по-долу:
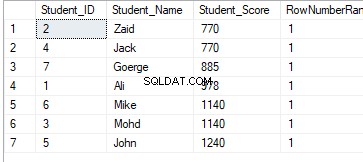
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreРезултатът от класирането няма да има значение, тъй като класирането ще се извършва според стойностите на Student_Score за всеки дял, а данните ще бъдат разделени според стойностите на Student_Score. И поради факта, че всеки дял ще има редове с еднакви стойности на Student_Score, редовете със същите стойности на Student_Score в същия дял ще бъдат класирани със стойност, равна на 1. По този начин, при преминаване към втория дял, рангът ще се нулира, като се започне отново с числото 1, като всички стойности на класирането са равни на 1, както е показано по-долу:
DENSE_RANK()
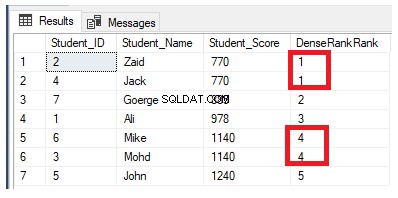
Функцията на прозореца за класиране DENSE_RANK() е подобна на функцията RANK() чрез генериране на уникален номер на ранг за всеки отделен ред в рамките на дяла в съответствие с определена стойност на колоната, започвайки от 1 за първия ред във всеки дял, класирайки редовете с равни стойности със същия номер на ранг, с изключение на това, че не пропуска нито един ранг, като не оставя празнини между ранговете.
Ако пренапишем предишната заявка за класиране, за да използваме функцията за класиране DENSE_RANK():
Отново променете предишната заявка, като включите клаузата PARTITION BY, за да имате повече от един дял, както е показано в T-SQL заявката по-долу:
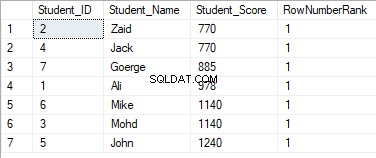
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Стойностите за класиране няма да имат значение, където всички редове ще бъдат класирани със стойност 1, поради присвояване на дублиращите се стойности на една и съща стойност на класиране и нулиране на началния идентификатор на ранга при обработка на нов дял, както е показано по-долу:
NTILE(N)
Функцията на прозореца за класиране NTILE(N) се използва за разпределяне на редовете в редовете, зададени в определен брой групи, предоставяйки на всеки ред в набора от редове уникален номер на групата, започвайки с числото 1, което показва групата, към която принадлежи този ред to, където N е положително число, което определя броя на групите, които трябва да разпределите редовете, в които са зададени.
С други думи, ако трябва да разделите конкретни редове с данни в таблицата на 3 групи въз основа на определени стойности на колони, функцията за прозорец за класиране NTILE(3) ще ви помогне да постигнете това лесно.
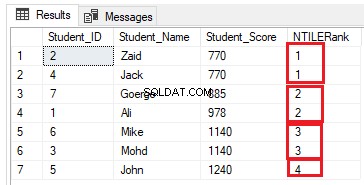
Броят на редовете във всяка група може да се изчисли чрез разделяне на броя на редовете на необходимия брой групи. Ако модифицираме предишната заявка за класиране, за да използваме функцията за прозорец за класиране NTILE(4), за да класираме седем реда на таблицата в четири групи като T-SQL заявката по-долу:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Броят на редовете трябва да бъде (7/4=1,75) редове във всяка група. Използвайки функцията NTILE(), SQL Server Engine ще присвои 2 реда към първите три групи и един ред към последната група, за да има всички редове, включени в групите, както е показано в набора от резултати по-долу:
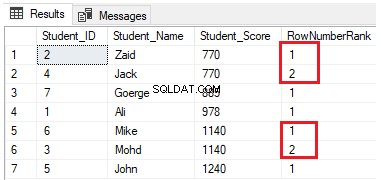
Промяна на предишната заявка чрез включване на клаузата PARTITION BY, за да има повече от един дял, както е показано в T-SQL заявката по-долу:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreРедовете ще бъдат разпределени в четири групи на всеки дял. Например, първите два реда с Student_Score, равен на 770, ще бъдат в един и същи дял и ще бъдат разпределени в групите, класиращи всяка една с уникален номер, както е показано в набора от резултати по-долу:
Събиране на всички
За да имаме по-ясен сценарий за сравнение, нека съкратим предишната таблица, добавим друг критерий за класификация, който е класът на учениците, и накрая вмъкнем нови седем реда, използвайки T-SQL скрипта по-долу:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
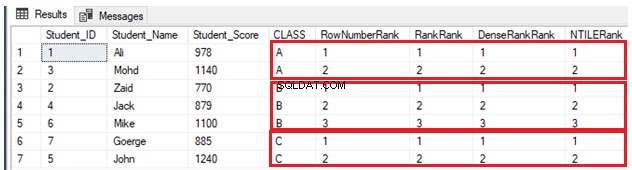
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')След това ще класираме седем реда според резултата на всеки ученик, като разделяме учениците според техния клас. С други думи, всеки дял ще включва един клас и всеки клас ученици ще бъде класиран според резултатите си в рамките на същия клас, като се използват четири по-рано описани функции на прозореца за класиране, както е показано в T-SQL скрипта по-долу:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOПоради факта, че няма дублиращи се стойности, четири функции на прозореца за класиране ще работят по същия начин, връщайки същия резултат, както е показано в набора от резултати по-долу:
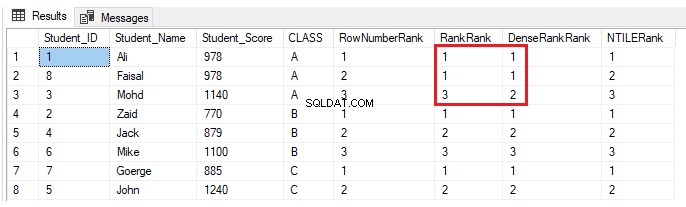
Ако друг ученик е включен в клас A с резултат, този друг ученик в същия клас вече има, като се използва изявлението INSERT по-долу:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Нищо няма да се промени за функциите на прозореца за класиране ROW_NUMBER() и NTILE(). Функциите RANK и DENSE_RANK() ще присвоят един и същ ранг за учениците с еднакъв резултат, с празнина в ранговете след дублиращите се рангове при използване на функцията RANK и без празнина в ранговете след дублиращите се при използване на DENSE_RANK( ), както е показано в резултата по-долу:
Практически сценарий
Функциите на прозореца за класиране се използват широко от разработчиците на SQL Server. Един от често срещаните сценарии за използване на функциите за класиране, когато искате да извлечете конкретни редове и да пропуснете други, като използвате функцията на прозореца за класиране ROW_NUMBER(,) в CTE, както в T-SQL скрипта по-долу, който връща учениците с ранг между 2 и 5 и пропуснете останалите:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Резултатът ще покаже, че ще бъдат върнати само ученици с ранг между 2 и 5:
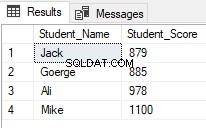
Започвайки от SQL Server 2012, нова полезна команда, OFFSET FETCH беше въведен, който може да се използва за изпълнение на същата предишна задача чрез извличане на конкретни записи и пропускане на останалите, като се използва скриптът T-SQL по-долу:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Извличане на същия предишен резултат, както е показано по-долу:
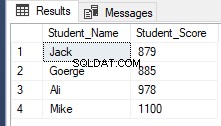
Заключение
SQL Server ни предоставя четири функции на прозореца за класиране, които ни помагат да класираме предоставените редове, зададени според конкретни стойности на колони. Тези функции са:ROW_NUMBER(), RANK(), DENSE_RANK() и NTILE(). Всички тези функции за класиране изпълняват задачата за класиране по свой собствен начин, връщайки същия резултат, когато няма дублиращи се стойности в редовете. Ако има дублирана стойност в набора от редове, функцията RANK ще присвои един и същ идентификатор за класиране за всички редове с една и съща стойност, оставяйки празнини между ранговете след дубликатите. Функцията DENSE_RANK също ще присвои един и същ идентификатор за класиране за всички редове с една и съща стойност, но няма да остави никаква празнина между ранговете след дубликатите. Преминаваме през различни сценарии в тази статия, за да обхванем всички възможни случаи, които ви помагат да разберете на практика функциите на прозореца за класиране.
Препратки:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- Клауза OFFSET FETCH (SQL Server Compact)