В тази статия ще обсъдим типичните грешки, с които могат да се сблъскат начинаещите разработчици, докато проектират T-SQL код. Освен това ще разгледаме най-добрите практики и някои полезни съвети, които могат да ви помогнат при работа със SQL Server, както и заобиколни решения за подобряване на производителността.
Съдържание:
1. Типове данни
2. *
3. Псевдоним
4. Ред на колони
5. NOT IN срещу NULL
6. Формат на дата
7. Филтър за дата
8. Изчисление
9. Преобразувайте имплицитно
10. LIKE &Потиснат индекс
11. Unicode срещу ANSI
12. СЪБОРЯВАНЕ
13. БИНАРНО СЪБОРЯВАНЕ
14. Стил на код
15. [var]char
16. Дължина на данните
17. ISNULL срещу COALESCE
18. Математика
19. UNION срещу UNION ALL
20. Прочетете отново
21. Подзаявка
22. СЛУЧАЙ, КОГАТО
23. Скаларна функция
24. ПРЕГЛЕДИ
25. КУРСОРИ
26. STRING_CONCAT
27. SQL инжекция
Типове данни
Основният проблем, с който се сблъскваме, когато работим със SQL Server, е неправилен избор на типове данни.
Да приемем, че имаме две еднакви таблици:
ДЕКЛАРИРАНЕ НА ТАБЛИЦА @Employees1 ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , BirthDate VARCHAR(20)) ВМЕСТЕ ВЪВ @Employees1VALUES (123, 'YES', '2012-09-RE2EmployEploy 01') INT ПЪРВИЧЕН КЛЮЧ , IsMale BIT , Дата на раждане ДАТА) ВЪВЕТЕ ВЪВ @Employees2VALUES (123, 1, '2012-09-01')
Нека изпълним заявка, за да проверим каква е разликата:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
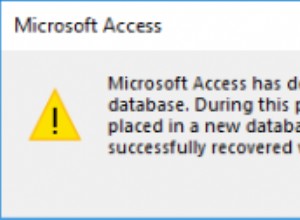
В първия случай типовете данни са по-излишни, отколкото биха могли да бъдат. Защо трябва да съхраняваме битова стойност като ДА/НЕ ред? Защо трябва да съхраняваме дата като ред? Защо трябва да използваме BIGINT за служители в таблицата, а не INT ?
Това води до следните недостатъци:
- Таблиците може да заемат много място на диска;
- Трябва да прочетем повече страници и да поставим повече данни в BufferPool за обработка на данни.
- Лоша производителност.
*
Сблъсквал съм се със ситуацията, когато разработчиците извличат всички данни от таблица и след това от страна на клиента използват DataReader за да изберете само задължителните полета. Не препоръчвам да използвате този подход:
ИЗПОЛЗВАЙТЕ AdventureWorks2014GOSET STATISTICS TIME, IO ONSELECT *FROM Person.PersonSELECT BusinessEntityID , First Name , MiddleName , LastNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Ще има значителна разлика във времето за изпълнение на заявката. В допълнение, покриващият индекс може да намали броя на логическите четения.
Таблица „Лице“. Брой на сканиране 1, логически четения 3819, физически четения 3, ... Времена за изпълнение на SQL Server:CPU време =31 ms, изминало време =1235 ms. Таблица 'Лице'. Брой сканиране 1, логически четения 109, физически четения 1, ... Времена на изпълнение на SQL Server:CPU време =0 ms, изминало време =227 ms.
Псевдоним
Нека създадем таблица:
ИЗПОЛЗВАЙТЕ AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') НЕ Е NULL DROP TABLE Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency (CurrencyCode NCHAR(3) PRIMARY SalesVALUESINSERT.INSERT INTO>
Да приемем, че имаме заявка, която връща количеството идентични редове в двете таблици:
ИЗБЕРЕТЕ COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency)
Всичко ще работи както се очаква, докато някой не преименува колона в Sales.UserCurrency таблица:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
След това ще изпълним заявка и ще видим, че получаваме всички редове в Sales.Currency таблица, вместо 1 ред. Когато изгражда план за изпълнение, на етапа на обвързване, SQL Server ще провери колоните на Sales.UserCurrency, няма да намери CurrencyCode там и решава, че тази колона принадлежи към Продажби.Валута маса. След това оптимизаторът ще премахне CurrencyCode =CurrencyCode състояние.
Затова препоръчвам да използвате псевдоними:
ИЗБЕРЕТЕ COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode ОТ Sales.UserCurrency u)
Последователност на колони
Да приемем, че имаме таблица:
АКО OBJECT_ID('dbo.DatePeriod') НЕ Е NULL DROP TABLE dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod (Начална дата ДАТА, Крайна дата ДАТА)
Винаги вмъкваме данни там въз основа на информацията за реда на колоните.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Да предположим, че някой промени реда на колоните:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Данните ще бъдат вмъкнати в различен ред. В този случай е добра идея да посочите изрично колони в оператора INSERT:
INSERT INTO dbo.DatePeriod (начална дата, крайна дата)ИЗБЕРЕТЕ '2015-01-01', '2015-01-31'
Ето още един пример:
ИЗБЕРЕТЕ ТОП(1) *ОТ dbo.DatePeriod ПОРЪЧАЙТЕ С 2 DESC
По коя колона ще подредим данни? Това ще зависи от реда на колоните в таблица. В случай, че някой промени реда, получаваме грешни резултати.
NOT IN срещу NULL
Нека поговорим за НЕ В изявление.
Например, трябва да напишете няколко заявки:върнете записите от първата таблица, които не съществуват във втората таблица и виза. Обикновено младите разработчици използват IN и НЕ В :
ДЕКЛАРИРАНЕ @t1 ТАБЛИЦА (t1 INT, УНИКАЛЕН КЛУСТРИРАН(t1))ВМЪКВАНЕ В @t1 СТОЙНОСТИ (1), (2)ДЕКЛАРИРАНЕ @t2 ТАБЛИЦА (t2 INT, УНИКАЛЕН КЛУСТЕР(t2))ВМЪКВАНЕ В @t2 СТОЙНОСТИ (1 )ИЗБЕРЕТЕ *ОТ @t1WHERE t1 НЕ В (ИЗБЕРЕТЕ t2 ОТ @t2)ИЗБЕРЕТЕ *ОТ @t1WHERE t1 IN (ИЗБЕРЕТЕ t2 ОТ @t2)
Първата заявка върна 2, втората – 1. Освен това ще добавим още една стойност във втората таблица – NULL :
INSERT INTO @t2 СТОЙНОСТИ (1), (NULL)
При изпълнение на заявката с НЕ ВЪВ , няма да получим никакви резултати. Защо IN работи, а НЕ In не? Причината е, че SQL Server използва TRUE , FALSE и НЕИЗВЕСТНО логика при сравняване на данни.
Когато изпълнява заявка, SQL Server интерпретира условието IN по следния начин:
a IN (1, NULL) ==a=1 ИЛИ a=NULL
НЕ В :
a НЕ В (1, NULL) ==a<>1 И a<>NULL
Когато сравнявате стойност с NULL, SQL Server връща НЕИЗВЕСТНО. Или 1=NULL или NULL=NULL – и двете водят до НЕИЗВЕСТНО. Доколкото имаме И в израза, и двете страни връщат НЕИЗВЕСТНО.
Искам да отбележа, че този случай не е рядък. Например маркирате колона като NOT NULL. След известно време друг разработчик решава да разреши NULL за тази колона. Това може да доведе до ситуация, когато клиентски отчет спре да работи, след като в таблицата се вмъкне стойност NULL.
В този случай бих препоръчал изключване на стойности NULL:
ИЗБЕРЕТЕ *ОТ @t1, КЪДЕТО t1 НЕ ВЪВ ( ИЗБЕРЕТЕ t2 ОТ @t2, КЪДЕТО t2 НЕ Е NULL)
Освен това е възможно да използвате ИЗКЛЮЧЕНИЕ :
ИЗБЕРЕТЕ * ОТ @t1ИЗКЛЮЧЕТЕ * ОТ @t2
Като алтернатива можете да използвате НЕ СЪЩЕСТВУВА :
ИЗБЕРЕТЕ *ОТ @t1, КЪДЕТО НЕ СЪЩЕСТВУВА( ИЗБЕРЕТЕ 1 ОТ @t2, КЪДЕТО t1 =t2 )
Кой вариант е по-предпочитан? Последната опция с НЕ СЪЩЕСТВУВА изглежда е най-продуктивният, тъй като генерира по-оптималния предикат надолу оператор за достъп до данни от втората таблица.
Всъщност стойностите NULL може да върнат неочакван резултат.
Помислете за това на този конкретен пример:
ИЗПОЛЗВАЙТЕ AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Цвят ='Grey'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Цвят <> 'Сив'
Както можете да видите, не сте получили очаквания резултат поради причината, че стойностите NULL имат отделни оператори за сравнение:
SELECT COUNT_BIG(*)FROM Production.ProductWHERE Цвят IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Цветът НЕ Е NULL
Ето още един пример с CHECK ограничения:
АКО OBJECT_ID('tempdb.dbo.#temp') НЕ Е NULL DROP TABLE #tempGOCREATE TABLE #temp ( Цвят VARCHAR(15) --NULL , ОГРАНИЧЕНИЕ CK ПРОВЕРКА (Цвят В ('Черен', 'Бял') ))
Създаваме таблица с разрешение за вмъкване само на бели и черни цветове:
INSERT INTO #temp VALUES ('Black')(1 ред(а) засегнати)
Всичко работи според очакванията.
INSERT INTO #temp VALUES ('Red') Инструкцията INSERT е в конфликт с ограничението CHECK... Инструкцията е прекратена.
Сега нека добавим NULL:
INSERT INTO #temp VALUES (NULL)(1 ред(а) засегнати)
Защо ограничението CHECK предаде стойността NULL? Е, причината е, че има достатъчно НЕ ЛОЖНО условие да се направи запис. Заобиколното решение е изрично да дефинирате колона като NOT NULL или използвайте NULL в ограничението.
Формат на датата
Много често може да имате затруднения с типовете данни.
Например, трябва да получите текущата дата. За да направите това, можете да използвате функцията GETDATE:
ИЗБЕРЕТЕ GETDATE()
След това просто копирайте върнатия резултат в задължителна заявка и изтрийте часа:
ИЗБЕРЕТЕ *ОТ sys.objectsWHERE create_date <'2016-11-14'
Вярно ли е?
Датата се посочва от низова константа:
ЗАДАДЕТЕ ЕЗИК Английски ЗАДАЙТЕ ФОРМАТ НА ДАТА DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Всички стойности имат еднозначна интерпретация:
---------- ----------- ----------- -----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Това няма да причини проблеми, докато заявката с тази бизнес логика не се изпълни на друг сървър, където настройките може да се различават:
ЗАДАДЕТЕ ФОРМАТ НА ДАТА MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dec -2016'SELECT @d1, @d2, @d3, @d4
Въпреки това, тези опции могат да доведат до неправилно тълкуване на датата:
---------- ----------- ----------- -----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Освен това този код може да доведе както до видима, така и до латентна грешка.
Помислете за следния пример. Трябва да вмъкнем данни в тестова таблица. На тестов сървър всичко работи перфектно:
ДЕКЛАРИРАНЕ НА ТАБЛИЦА @t (a DATETIME)ВМЕСЕТЕ В @t VALUES ('05/13/2016')
Все пак от страна на клиента тази заявка ще има проблеми, тъй като настройките на сървъра ни се различават:
ДЕКЛАРИРАНЕ НА ТАБЛИЦА @t (a DATETIME)ЗАДАВАНЕ НА ДАТА ФОРМАТИРАНЕ DMYINSERT В @t СТОЙНОСТИ ('05/13/2016') Съобщение 242, ниво 16, състояние 3, ред 28 Преобразуването на тип данни varchar в тип данни за дата и час доведе до стойност извън диапазона.
И така, какъв формат трябва да използваме, за да декларираме константи за дата? За да отговорите на този въпрос, изпълнете тази заявка:
ЗАДАДЕТЕ ФОРМАТ НА ДАТА YMDSET ЕЗИК Английски ДЕКЛАРИ @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='121 'ИЗБЕРЕТЕ @d1, @d2, @d3, @d4GOSET ЕЗИК DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'ИЗБЕРЕТЕ @d1, @d2, @d3, @d4
Интерпретацията на константите може да се различава в зависимост от инсталирания език:
---------- ----------- ----------- -----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Затова е по-добре да използвате последните две опции. Освен това бих искал да добавя, че изричното уточняване на датата не е добра идея:
SET LANGUAGE FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29 Проверка на преобразуването на датата и/оу де l'heure à partir d'une chaîne de caractères.
Следователно, ако искате константите с датите да бъдат интерпретирани правилно, трябва да ги посочите в следния формат ГГГГММДД.
Освен това бих искал да насоча вниманието ви към поведението на някои типове данни:
ЗАДАДЕТЕ ЕЗИК EnglishSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d01 DATE ='2016-01-12 12' , @d2 DATETIME ='2016-01-12'ИЗБЕРЕТЕ @d1, @d2
За разлика от DATETIME, DATE типът се интерпретира правилно с различни настройки на сървър:
------------------2016-01-12 2016-01-12---------------- ---2016-01-12 2016-12-01
Филтър за дата
За да продължим, ще разгледаме как да филтрираме ефективно данните. Да започнем от тях DATETIME/DATE:
ИЗПОЛЗВАЙТЕ AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Сега ще се опитаме да разберем колко реда връща заявката за определен ден:
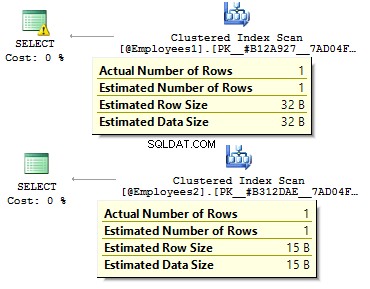
ИЗБЕРЕТЕ COUNT_BIG(*)ОТ dbo.DatabaseLogWHERE PostTime ='20140716'
Заявката ще върне 0. Когато изгражда план за изпълнение, SQL сървърът се опитва да предаде низова константа към типа данни на колоната, която трябва да филтрираме:
Създайте индекс:
СЪЗДАЙТЕ НЕКЛУСТРИРАН ИНДЕКС IX_PostTime НА dbo.DatabaseLog (PostTime)
Има правилни и неправилни опции за извеждане на данни. Например, трябва да изтриете колоната за време:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='16'40'7
Или трябва да посочим диапазон:
ИЗБЕРЕТЕ COUNT_BIG(*)ОТ dbo.DatabaseLogWHERE PostTime МЕЖДУ '20140716' И '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE2 PostTime'17'16 PostTime'17'16 PostTime'17'07>
Имайки предвид оптимизацията, мога да кажа, че тези две заявки са най-правилните. Въпросът е, че всички преобразувания и изчисления на индексни колони, които се филтрират, могат да намалят драстично производителността и да увеличат времето за логически отчитания:
Таблица 'DatabaseLog'. Брой сканиране 1, логически показания 7, ...Таблица 'DatabaseLog'. Сканиране 1, логически четения 2, ...
PostTime полето не е било включено в индекса преди и не можахме да видим никаква ефективност при използването на този правилен подход при филтриране. Друго нещо е, когато трябва да изведем данни за един месец:
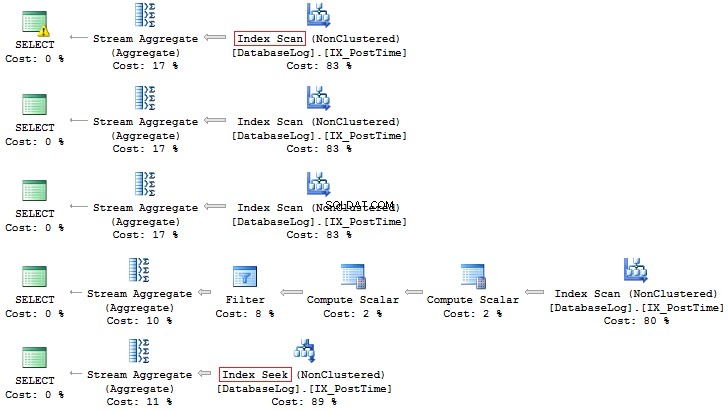
ИЗБЕРЕТЕ COUNT_BIG(*)ОТ dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) КАТО '201407%'ИЗБЕРЕТЕ COUNT_BIG(*)ОТ dbo.DatabaseLogWHERE DATEPART(ГОДИНА, PostTime) =2014, MONTH(MONTH PART) PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE ГОДИНА(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='2014'ogHERHERM.Database. PostTime>='20140701' И PostTime <'20140801'
Отново, последният вариант е по-предпочитан:
Освен това винаги можете да създадете индекс въз основа на изчислено поле:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') НЕ Е NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ДОБАВЕТЕ MonthLastDay ДОБАВЕТЕ МЕСЕЦ ПОСЛЕДЕН ДЕН КАТО РЕДАКТИВЕН ДЕН.
В сравнение с предишната заявка разликата в логическите показания може да е значителна (ако става дума за големи таблици):
ЗАДАДЕТЕ STATISTICS IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE OFFWHERE MonthLastDay'Day SET'20140701' 20140701 Брой сканиране 1, логически показания 7, ...Таблица 'DatabaseLog'. Сканиране 1, логически четения 3, ...
Изчисление
Както вече беше обсъдено, всякакви изчисления на индексни колони намаляват производителността и увеличават времето на логическо четене:
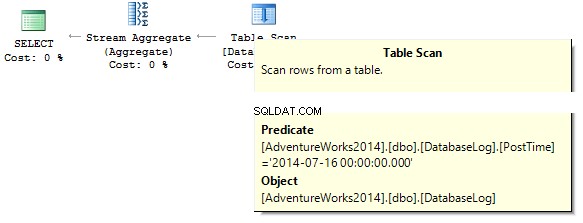
ИЗПОЛЗВАЙТЕ AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2 SELECT BusinessEntityIDFROM'EntityPerson. Брой на сканирането 1, логически отчита 67, ...Таблица 'Лице'. Брой сканиране 0, логическо четене 3, ...
Ако погледнем плановете за изпълнение, тогава в първия SQL Server изпълнява IndexScan :
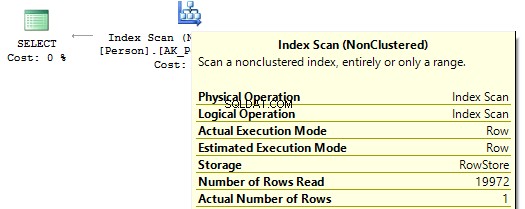
След това, когато няма изчисления в колоните на индекса, ще видим IndexSeek :

Неявно конвертиране
Нека да разгледаме тези две заявки, които филтрират по една и съща стойност:
ИЗПОЛЗВАЙТЕ AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Плановете за изпълнение предоставят следната информация:
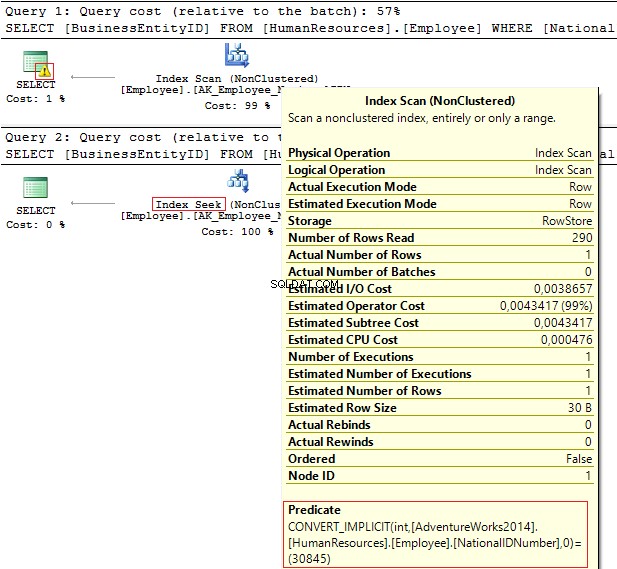
- Предупреждение и IndexScan на първия план
- IndexSeek – на втория.
Таблица „Служител“. Сканиране 1, логически показания 4, ...Таблица 'Служител'. Брой на сканиране 0, логическо четене 2, ...
Националният идентификационен номер колоната има NVARCHAR(15) тип данни. Константата, която използваме за филтриране на данни, е зададена като INT което ни води до имплицитно преобразуване на тип данни. От своя страна това може да намали производителността. Можете да го наблюдавате, когато някой промени типа данни в колоната, но заявките не се променят.
Важно е да се разбере, че имплицитното преобразуване на тип данни може да доведе до грешки по време на изпълнение. Например, преди полето PostalCode да е числово, се оказа, че пощенският код може да съдържа букви. По този начин типът данни беше актуализиран. Все пак, ако вмъкнем пощенски код по азбучен ред, старата заявка вече няма да работи:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Съобщение 245, ниво 16, състояние 1, ред 16 Преобразуването не бе успешно при преобразуване на стойността на данните от типа nvarchar1 'K4B' в nvarchar тип стойност 'K4B'. междун.
Друг пример е, когато трябва да използвате EntityFramework в проекта, който по подразбиране интерпретира всички полета на ред като Unicode:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Следователно се генерират неправилни заявки:

За да разрешите този проблем, уверете се, че типовете данни съвпадат.
Харесвам и потиснат индекс
Всъщност наличието на покриващ индекс не означава, че ще го използвате ефективно.
Нека го проверим на този конкретен пример. Да приемем, че трябва да изведем всички редове, които започват с...
ИЗПОЛЗВАЙТЕ AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Адрес]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person.[Адрес]WHERE LEFT(AddressLine1, 3)' =SELECT AddressLine1, 3'. Адрес]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 КАТО '100%'
Ще получим следните логически показания и планове за изпълнение:
Таблица „Адрес“. Брой на сканирането 1, логически отчита 216, ...Таблица 'Адрес'. Брой на сканирането 1, логически отчита 216, ...Таблица 'Адрес'. Брой на сканирането 1, логически отчита 216, ...Таблица 'Адрес'. Брой на сканирането 1, логически отчитания 4, ...
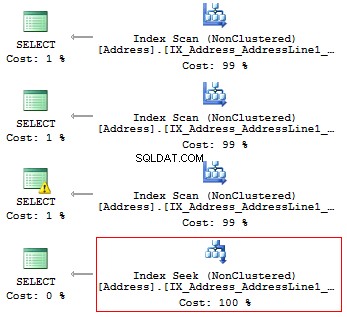
По този начин, ако има индекс, той не трябва да съдържа никакви изчисления или преобразуване на типове, функции и т.н.
Но какво правите, ако трябва да намерите появата на подниз в низ?
ИЗБЕРЕТЕ AddressLine1FROM Person.[Address]WHERE AddressLine1 КАТО '%100%'v
Ще се върнем към този въпрос по-късно.
Unicode срещу ANSI
Важно е да запомните, че има UNICODE и ANSI струни. Типът UNICODE включва NVARCHAR/NCHAR (2 байта към един символ). За съхраняване на ANSI низове, възможно е да се използва VARCHAR/CHAR (1 байт до 1 символ). Има и TEXT/NTEXT , но не препоръчвам да ги използвате, тъй като могат да намалят производителността.
Ако посочите Unicode константа в заявка, тогава е необходимо да я предхождате със символа N. За да го проверите, изпълнете следната заявка:
ИЗБЕРЕТЕ '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI 文本 UNICODE
Ако N не предхожда константата, тогава SQL Server ще се опита да намери подходящ символ в ANSI кодирането. Ако не успее да намери, ще покаже въпросителен знак.
СОБИРАНЕ
Много често, когато се интервюира за позицията среден/старши разработчик на DB, интервюиращият често задава следния въпрос:Тази заявка ще върне ли данните?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'ИЗБЕРЕТЕ @a, @bWHERE @a =@b
Зависи. Първо, символът N не предхожда низова константа, така че ще се интерпретира като ANSI. Второ, много зависи от текущата стойност COLLATE, която е набор от правила, при избора и сравняването на низови данни.
ИЗПОЛЗВАЙТЕ [master]GOIF DB_ID('test') НЕ Е NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE(') @abGOD ) ='Ф'ИЗБЕРЕТЕ @a, @bWHERE @a =@b Този израз COLLATE ще върне въпросителни знаци, тъй като символите им са равни:
---- ----? ?
Ако променим израза COLLATE за друг израз:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
В този случай заявката няма да върне нищо, тъй като знаците на кирилица ще бъдат интерпретирани правилно.
Следователно, ако константа на низ заема UNICODE, тогава е необходимо да се зададе N пред низова константа. Все пак не бих препоръчал да го зададете навсякъде поради причините, които обсъдихме по-горе.
Друг въпрос, който трябва да бъде зададен по време на интервюто, се отнася до сравнението на редовете.
Помислете за следния пример:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Тези редове равни ли са? За да проверим това, трябва изрично да посочим COLLATE:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Тъй като при сравняването и избора на редове съществуват чувствителни към малки и големи букви (CS) и нечувствителни (CI) COLLATE, не можем да кажем със сигурност дали са равни. Освен това има различни COLLATE както на тестов сървър, така и на клиентска страна.
Има случай, когато COLLATE на целева база и tempdb не съвпадат.
Създайте база данни с COLLATE:
ИЗПОЛЗВАЙТЕ [главен]GOIF DB_ID('test') НЕ Е NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Albanian_100_CS_ASGOUSE VALUE testGOCREATE (t. ')GOIF OBJECT_ID('tempdb.dbo.#t1') НЕ Е NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') НЕ Е NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo).#t3.#t3. НЕ Е NULL ИЗПУСКАНЕ НА ТАБЛИЦА #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT INTO #t1 STOS ('a')СЪЗДАВАНЕ НА ТАБЛИЦА #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 STOS ('a') ИЗБЕРЕТЕ c =CAST('a' КАТО CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')ИЗБЕРЕТЕ 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation ')UNION ALLSELECT 'тест', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') ОТ tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, FROM #collation') t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') ОТ # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') ОТ #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') ОТ @t Когато създава таблица, тя наследява COLLATE от база данни. Единствената разлика за първата временна таблица, за която определяме структура изрично без COLLATE, е, че тя наследява COLLATE от tempdb база данни.
------ --------------------------------tempdb Cyrillic_General_CI_AStest Albanian_100_CS_ASt Albanian_100_CS_AS#t1 Cyrillic_General_CI_AS#t2 Албански_100_CS_AS#t3 Албански_100_CS_AS@t Albanian_100_CS_AS
Ще опиша случая, когато COLLATE не съвпадат в конкретния пример с #t1.
Например данните не се филтрират правилно, тъй като COLLATE може да не вземе предвид случай:
ИЗБЕРЕТЕ *ОТ #t1WHERE c ='A'
Като алтернатива може да имаме конфликт за свързване на таблици с различни COLLATE:
ИЗБЕРЕТЕ *ОТ #t1JOIN t ON [#t1].c =t.c
Всичко изглежда работи перфектно на тестов сървър, докато на клиентски сървър получаваме грешка:
Съобщение 468, ниво 16, състояние 9, ред 93 Не може да разреши конфликта на съпоставяне между „Albanian_100_CS_AS“ и „Cyrillic_General_CI_AS“ в операцията за равно на.
За да го заобиколим, трябва да зададем хакове навсякъде:
ИЗБЕРЕТЕ *ОТ #t1JOIN t ON [#t1].c =t.c COLLATE database_default
БИНАРНО СЪБОРЯВАНЕ
Сега ще разберем как да използваме COLLATE във ваша полза.
Помислете за примера с появата на подниз в низ:
ИЗБЕРЕТЕ AddressLine1FROM Person.[Address]WHERE AddressLine1 КАТО '%100%'
Възможно е да се оптимизира тази заявка и да се намали времето за нейното изпълнение.
Първо трябва да генерираме голяма таблица:
USE [master]GOIF DB_ID('test') НЕ Е NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE test (Test) NEXT. Тест на БАЗА ДАННИ МОДИФИЦИРАНЕ НА ФАЙЛ (ИМЕ =N'test_log', РАЗМЕР =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) НЕ НУЛИ , unicode NVARCHAR(100) НЕ НУЛВО)GO;С E1(N) КАТО ( SELECT * FROM СТОЙНОСТИ (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (ИЗБЕРЕТЕ 1 ОТ E1 a, E1 b), E4(N) AS (ИЗБЕРЕТЕ 1 ОТ E2 a, E2 b), E8(N) AS (ИЗБЕРЕТЕ 1 ОТ E4 a, E4 b) INSERT INTO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') ОТ E8) t Създайте изчислени колони с двоични COLLATE и индекси:
ALTER TABLE t ДОБАВЯНЕ на ansi_bin КАТО UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t ДОБАВЯНЕ na unicode_bin КАТО UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX (NONCLUSTERED INDEX (NONCLUSTERED INDEX) NONCLUSTERED INDEX (NONCLUSTERED nicod NONCLUSTERED INDEX) ansiONCREAD unicod_INCOD. ansi_bin)СЪЗДАДЕТЕ НЕКЛУСТРИРАН ИНДЕКС unicode_bin ВКЛЮЧЕНО t (unicode_bin)
Изпълнете процеса на филтриране:
ЗАДАДЕТЕ ВРЕМЕ НА СТАТИСТИКА, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicode LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin%' LIKE '%AB --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicode_bin КАТО '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TIME, IO OFF
Както можете да видите, тази заявка връща следния резултат:
Време за изпълнение на SQL сървъра:CPU време =350 ms, изминало време =354 ms. Времена за изпълнение на SQL сървър:CPU време =335 ms, изминало време =355 ms. Време за изпълнение на SQL сървър:време на CPU =16 ms, изминало време =18 ms. Времена за изпълнение на SQL Server:CPU време =17 ms, изминало време =18 ms.
Въпросът е, че филтърът, базиран на двоично сравнение, отнема по-малко време. По този начин, ако трябва да филтрирате появата на низове често и бързо, тогава е възможно да съхранявате данни с COLLATE, завършващ с BIN. Въпреки това трябва да се отбележи, че всички двоични COLLATE са чувствителни към главни букви.
Стил на кода
Стилът на кодиране е строго индивидуален. Все пак този код трябва просто да се поддържа от други разработчици и да отговаря на определени правила.
Създайте отделна база данни и таблица вътре:
ИЗПОЛЗВАЙТЕ [главен]GOIF DB_ID('test') НЕ Е NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREEY.mplo PRIMARE DATARY.
След това напишете заявката:
изберете идентификатор на служител от служител
Сега променете COLLATE на всеки, който е чувствителен към главни букви:
ALTER DATABASE тест COLLATE Latin1_General_CS_AI
След това опитайте да изпълните заявката отново:
Съобщение 208, ниво 16, състояние 1, ред 19 Невалидно име на обект „служител“.
Оптимизаторът използва правила за текущия COLLATE на стъпката на обвързване, когато проверява за таблици, колони и други обекти, както и сравнява всеки обект от синтаксичното дърво с реален обект от системен каталог.
Ако искате да генерирате заявки ръчно, трябва винаги да използвате правилния регистър на буквите в имената на обекти.
Що се отнася до променливите, COLLATE се наследяват от основната база данни. Следователно, трябва да използвате правилния случай, за да работите и с тях:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid
В този случай няма да получите грешка:
-----------------------Cyrillic_General_CI_AS-----------1
Все пак може да се появи грешка в случай на друг сървър:
-------------------------Latin1_General_CS_ASMsg 137, ниво 15, състояние 2, ред 4 Трябва да се декларира скаларната променлива "@empid". [var]char
Както знаете, има фиксирани (CHAR , NCHAR ) и променлива (VARCHAR , NVARCHAR ) типове данни:
DECLARE @a CHAR(20) ='text' , @b VARCHAR(20) ='text'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'SELECT [a =b] =IIF(@a =@b, 'TRUE', 'FALSE') , [b =a] =IIF(@b =@a, 'TRUE', 'FALSE') , [a LIKE b] =IIF(@a LIKE @b, 'TRUE', 'FALSE') , [b LIKE a] =IIF(@ b КАТО @a, 'ВЯРНО', 'НЕВЕРНО')
Ако ред има фиксирана дължина, да речем 20 символа, но сте написали само 4 символа, тогава SQL Server ще добави 16 празни места вдясно по подразбиране:
--- --- ---- ---- ---------------------- ----------- -----------4 4 20 4 "текст " "текст"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
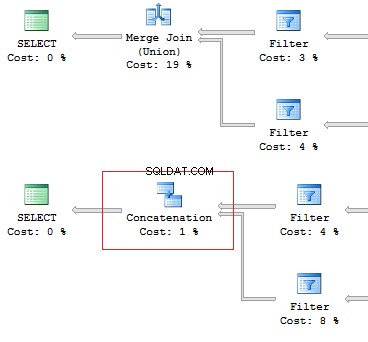
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
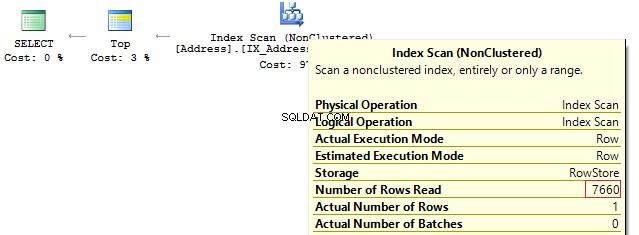
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
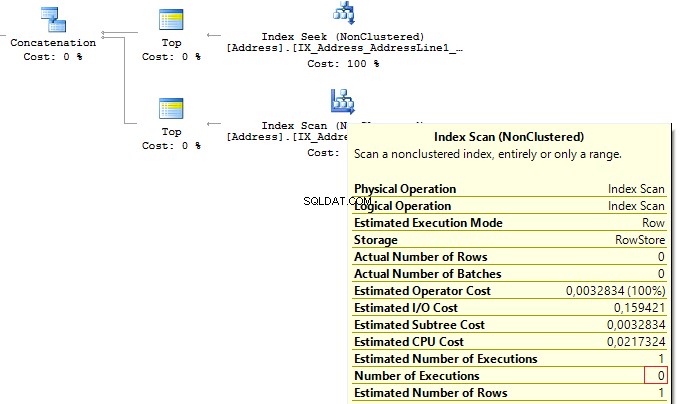
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
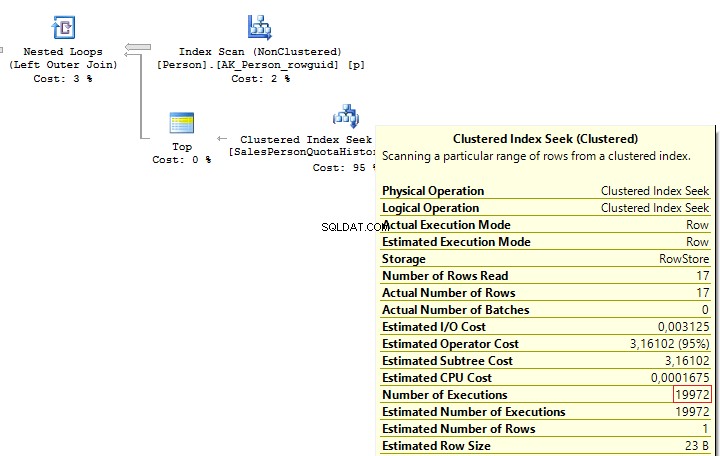
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
We get the following result:
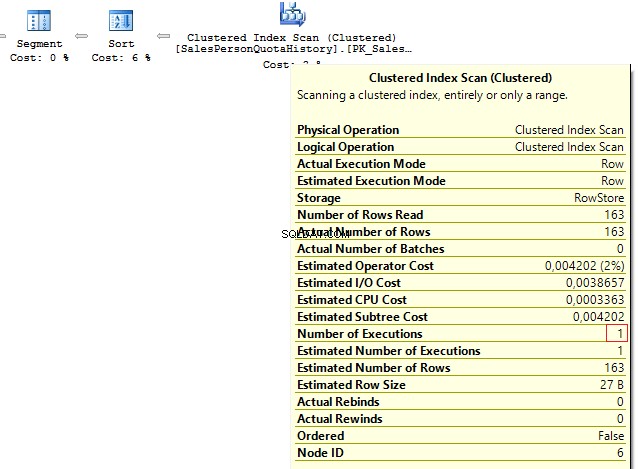
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
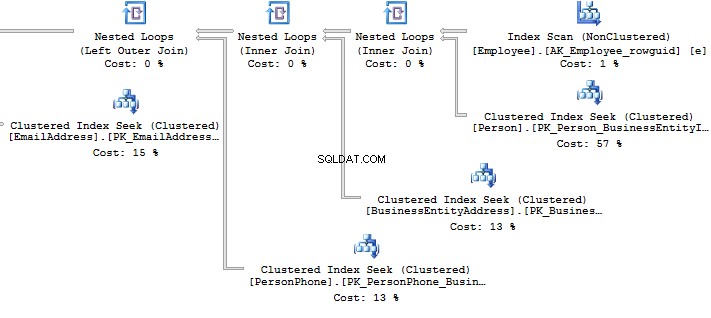
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
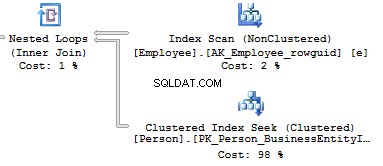
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
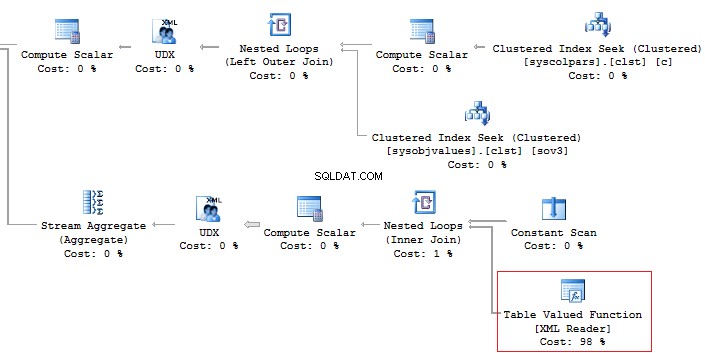
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
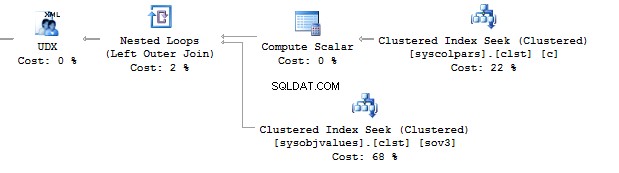
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.