Според Wikipedia груповото вмъкване е процес или метод, предоставен от система за управление на база данни за зареждане на множество редове данни в таблица на база данни. Ако коригираме това обяснение към израза BULK INSERT, груповото вмъкване позволява импортиране на външни файлове с данни в SQL Server.
Да приемем, че нашата организация има CSV файл от 1 500 000 реда и искаме да го импортираме в конкретна таблица в SQL Server, за да използваме израза BULK INSERT в SQL Server. Можем да намерим няколко метода за справяне с тази задача. Може да използва BCP (b улкс опипи rogram), съветник за импортиране и експортиране на SQL Server или пакет услуга за интеграция на SQL Server. Въпреки това, операторът BULK INSERT е много по-бърз и мощен. Друго предимство е, че предлага няколко параметъра, които помагат да се определят настройките на процеса на групово вмъкване.
Нека започнем с основна извадка. След това ще преминем през по-сложни сценарии.
Подготовка
На първо място, имаме нужда от примерен CSV файл. Изтегляме примерен CSV файл от уебсайта на E for Excel (колекция от пробни CSV файлове с различен номер на ред). Тук ще използваме 1,500,000 Sales Records.
Изтеглете zip файл, разархивирайте го, за да получите CSV файл, и го поставете в локалното си устройство.
Импортиране на CSV файл в таблица на SQL Server
Ние импортираме нашия CSV файл в таблицата на местоназначението в най-простата форма. Поставих моя примерен CSV файл на C:устройството. Сега създаваме таблица, за да импортираме данните от CSV файла в нея:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Следният оператор BULK INSERT импортира CSV файла в таблицата Sales:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Вероятно сте забелязали специфичните параметри на горния израз за групово вмъкване. Нека ги изясним:
- ПЪРВО определя началната точка на израза за вмъкване. В примера по-долу искаме да пропуснем заглавките на колони, затова задаваме този параметър на 2.

- TERMINATOR НА ПОЛЕ дефинира символа, който разделя полетата едно от друго. SQL Server открива всяко поле по този начин.
- ROWTERMINATOR не се различава много от FIELDTERMINATOR. Той определя разделителния характер на редовете.
В примерния CSV файл FIELDTERMINATOR е много ясен и е запетая (,). За да откриете този параметър, отворете CSV файла в Notepad++ и отидете на Преглед -> Покажи символ -> Покажи всички харти. CRLF знаците са в края на всяко поле.
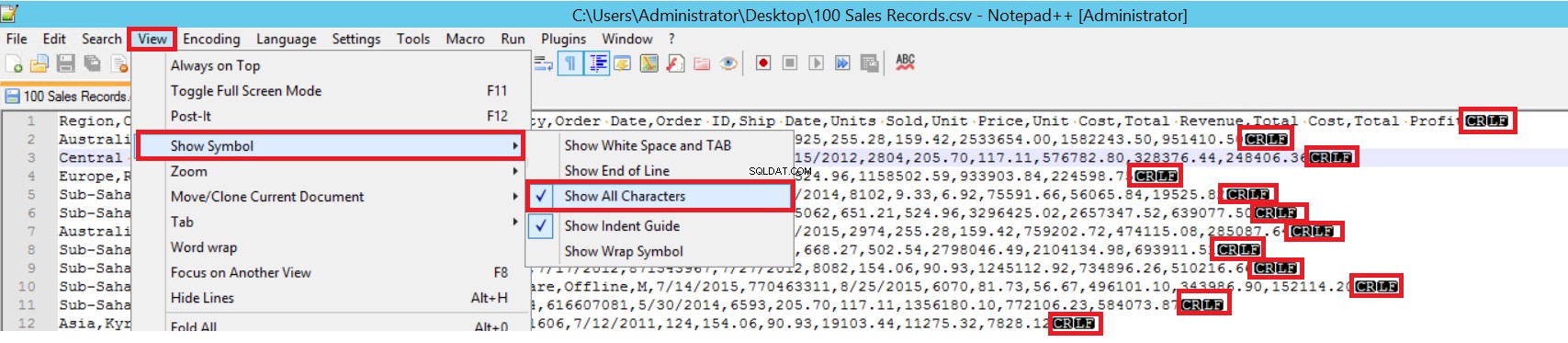
CR =връщане на карета и LF =подаване на ред. Те се използват за маркиране на прекъсване на ред в текстов файл. Индикаторът е „\n“ в израза за групово вмъкване.
Друг начин за импортиране на CSV файл в таблица с групово вмъкване е като използвате параметъра FORMAT. Имайте предвид, че този параметър е наличен само в SQL Server 2017 и по-нови версии.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Това беше най-простият сценарий, при който целевата таблица и CSV файлът имат равен брой колони. Въпреки това, когато таблицата на местоназначението има повече колони, тогава CSV файлът е типичен. Нека го разгледаме.
Добавяме първичен ключ към таблицата Продажби, за да разрушим съпоставянията на колоните за равенство. Създаваме таблицата за продажби с първичен ключ и импортираме CSV файла чрез командата за групово вмъкване.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Но дава грешка:
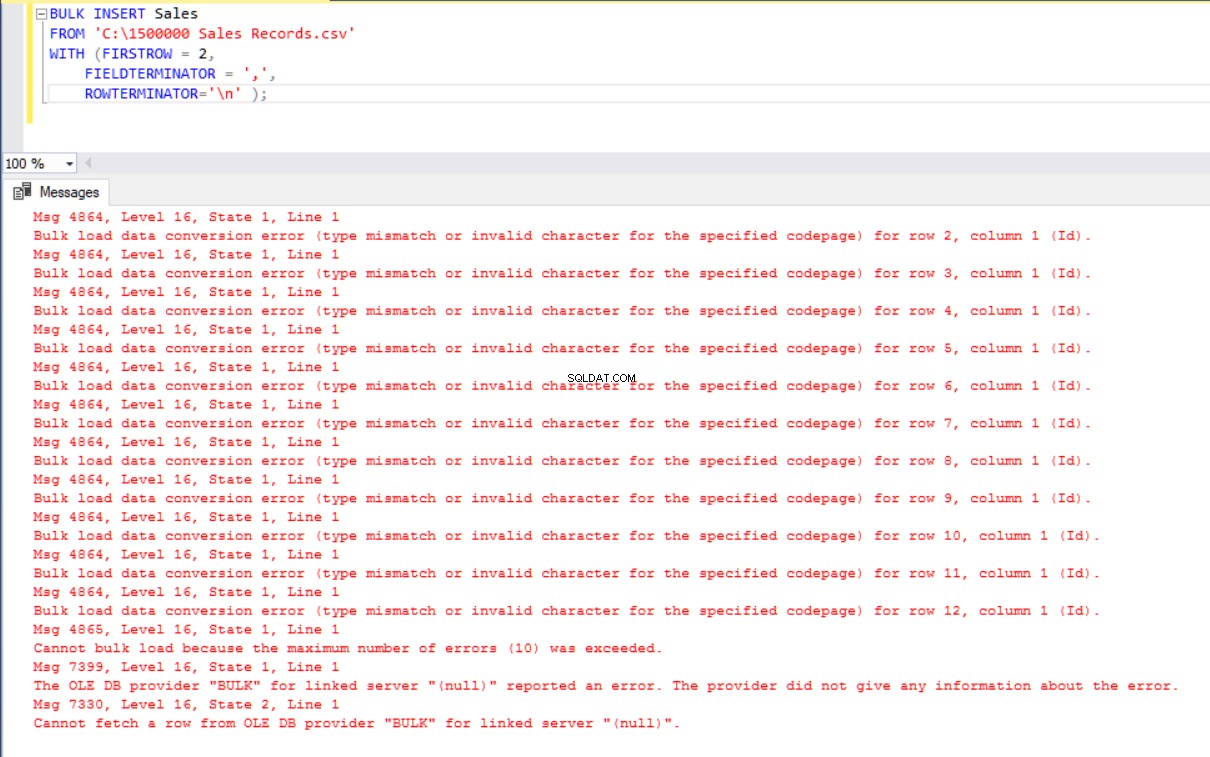
За да преодолеем грешката, създаваме изглед на таблицата Продажби с преобразуване на колони към CSV файла. След това импортираме CSV данните върху този изглед в таблицата Продажби:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Отделете и заредете голям CSV файл в малка партида
SQL Server придобива заключване към таблицата на местоназначението по време на операцията за групово вмъкване. По подразбиране, ако не зададете параметъра BATCHSIZE, SQL Server отваря транзакция и вмъква всички CSV данни в нея. С този параметър SQL Server разделя CSV данните според стойността на параметъра.
Нека разделим всички CSV данни на няколко набора от по 300 000 реда всеки.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Данните ще бъдат импортирани пет пъти на части.
- Ако изразът ви за групово вмъкване не включва параметъра BATCHSIZE, ще възникне грешка и SQL Server ще върне обратно целия процес на групово вмъкване.
- С този параметър, зададен на израз за групово вмъкване, SQL Server връща назад само частта, където е възникнала грешката.
Няма оптимална или най-добра стойност за този параметър, тъй като стойността му може да се промени според системните изисквания на вашата база данни.
Задайте поведението в случай на грешки
Ако възникне грешка в някои сценарии на групово копиране, можем или да отменим процеса на групово копиране, или да го продължим. Параметърът MAXERRORS ни позволява да посочим максималния брой грешки. Ако процесът на групово вмъкване достигне тази максимална стойност на грешката, той отменя операцията за групово импортиране и се връща назад. Стойността по подразбиране за този параметър е 10.
Например, имаме повредени типове данни в 3 реда на CSV файла. Параметърът MAXERRORS е зададен на 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Цялата операция за групово вмъкване ще бъде отменена, защото има повече грешки от стойността на параметъра MAXERRORS.
Ако променим параметъра MAXERRORS на 4, изразът за групово вмъкване ще пропусне тези редове с грешки и ще вмъкне правилни структурирани редове с данни. Процесът на групово вмъкване ще бъде завършен.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
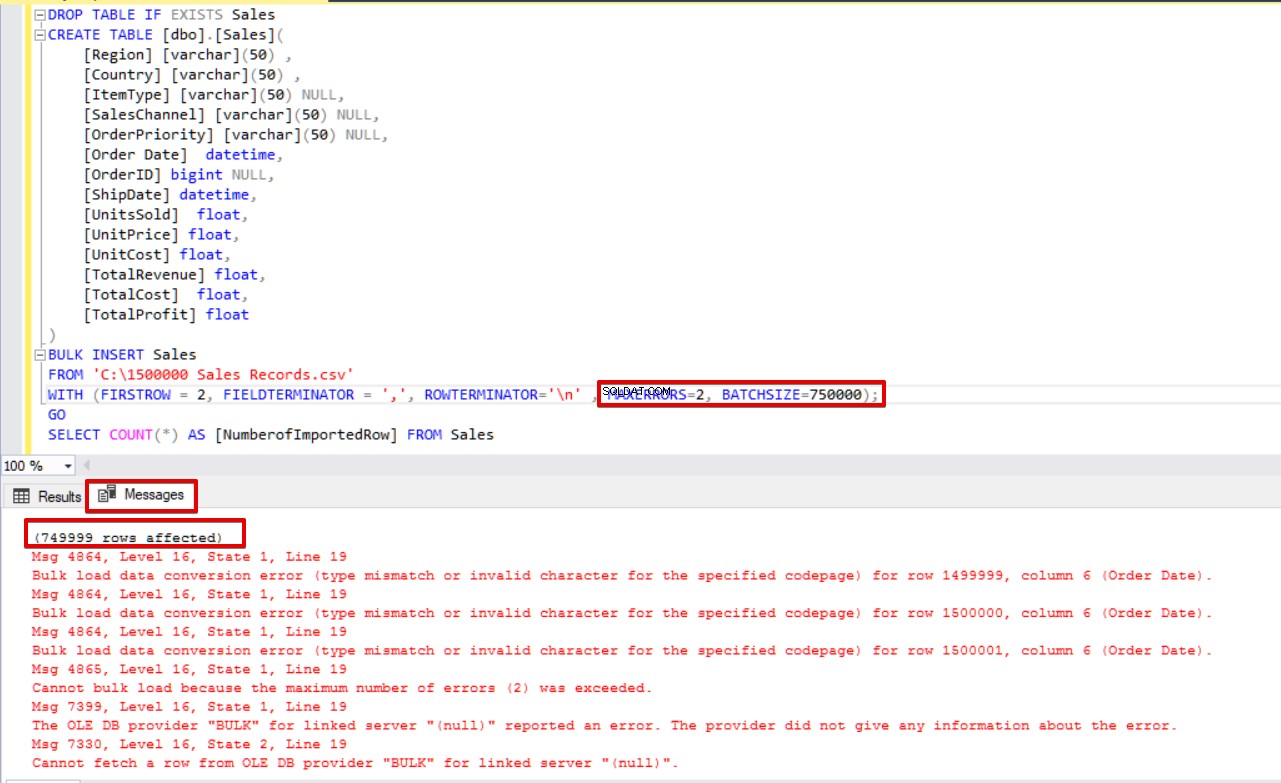
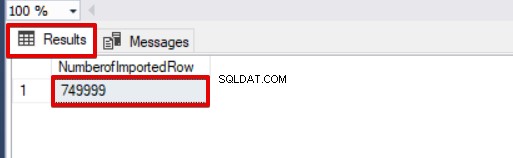
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Ако използваме едновременно BATCHSIZE и MAXERRORS, процесът на групово копиране няма да отмени цялата операция на вмъкване. Ще отмени само разделената част.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Разгледайте изображението по-долу, което показва резултата от изпълнението на скрипта:
Други опции на процеса на групово вмъкване
FIRE_TRIGGERS – активиране на тригери в таблицата на местоназначението по време на операцията за групово вмъкване
По подразбиране, по време на процеса на групово вмъкване, тригерите за вмъкване, посочени в целевата таблица, не се задействат. Все пак в някои ситуации може да искаме да ги активираме.
Решението е използването на опцията FIRE_TRIGGERS в изрази за групово вмъкване. Но, моля, имайте предвид, че това може да повлияе и да намали производителността на операцията за масово вмъкване. Това е така, защото тригерите/тригерите могат да извършват отделни операции в базата данни.
Първоначално не задаваме параметъра FIRE_TRIGGERS и процесът на групово вмъкване няма да задейства тригера за вмъкване. Вижте следния T-SQL скрипт:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogКогато този скрипт се изпълни, тригерът за вмъкване няма да се задейства, защото опцията FIRE_TRIGGERS не е зададена.
Сега нека добавим опцията FIRE_TRIGGERS към израза за групово вмъкване:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 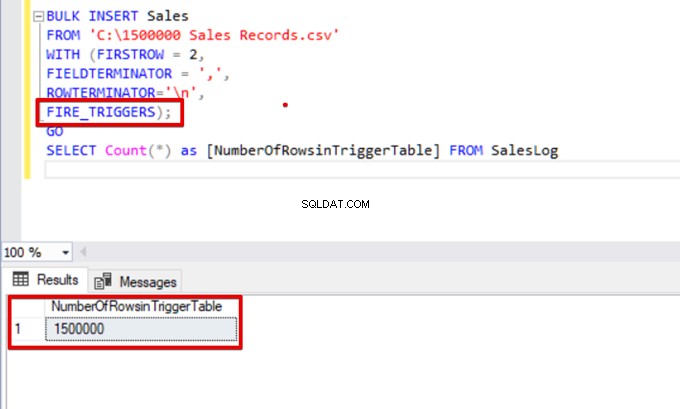
CHECK_CONSTRAINTS – активиране на ограничение за проверка по време на операцията за групово вмъкване
Ограниченията за проверка ни позволяват да наложим целостта на данните в таблиците на SQL Server. Целта на ограничението е да провери вмъкнати, актуализирани или изтрити стойности в съответствие с тяхното регулиране на синтаксиса. Като например, ограничението NOT NULL осигурява, че стойността NULL не може да променя определена колона.
Тук се фокусираме върху ограниченията и взаимодействията с групови вмъквания. По подразбиране, по време на процеса на групово вмъкване, всяка проверка и ограничения на външния ключ се игнорират. Но има някои изключения.
Според Microsoft „Ограниченията за УНИКАЛЕН и ПЪРВИЧЕН КЛЮЧ винаги се прилагат. При импортиране в символна колона, за която е дефинирано ограничението NOT NULL, BULK INSERT вмъква празен низ, когато в текстовия файл няма стойност.“
В следващия T-SQL скрипт добавяме ограничение за проверка към колоната OrderDate, която контролира датата на поръчката, по-голяма от 01.01.2016 г.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'В резултат на това процесът на групово вмъкване пропуска контрола на ограничението за проверка. Въпреки това, SQL Server показва ограничението за проверка като ненадеждно:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'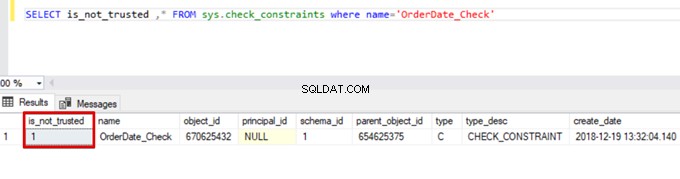
Тази стойност показва, че някой е вмъкнал или актуализирал някои данни в тази колона, като е пропуснал ограничението за проверка. В същото време тази колона може да съдържа непоследователни данни относно това ограничение.
Опитайте се да изпълните израза за групово вмъкване с опцията CHECK_CONSTRAINTS. Резултатът е ясен:ограничението за проверка връща грешка поради неправилни данни.
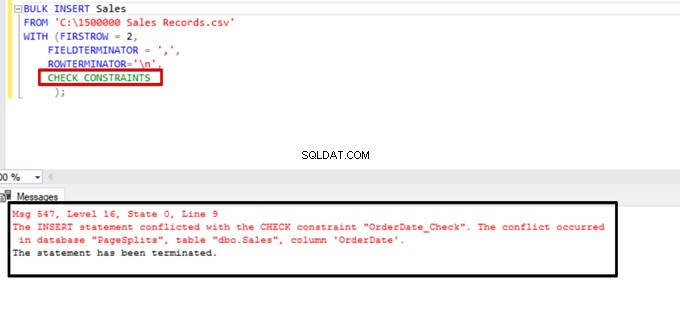
TABLOCK – увеличете производителността при множество групови вмъквания в една целева таблица
Основната цел на механизма за заключване в SQL Server е да защитава и гарантира целостта на данните. В основната концепция на статията за заключване на SQL Server можете да намерите подробности за механизма за заключване.
Ще се съсредоточим върху подробностите за заключване на процеса на групово вмъкване.
Ако изпълните израза за групово вмъкване без опцията TABLELOCK, той придобива заключването на редове или таблици според йерархията на заключване. Но в някои случаи може да искаме да изпълним множество процеси на групово вмъкване срещу една целева таблица и по този начин да намалим времето за работа.
Първо, ние изпълняваме два оператора за групово вмъкване едновременно и анализираме поведението на заключващия механизъм. Отворете два прозореца за заявка в SQL Server Management Studio и изпълнете следните оператори за групово вмъкване едновременно.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);Изпълнете следната DMV (Dynamic Management View) заявка – тя помага да наблюдавате състоянието на процеса на групово вмъкване:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID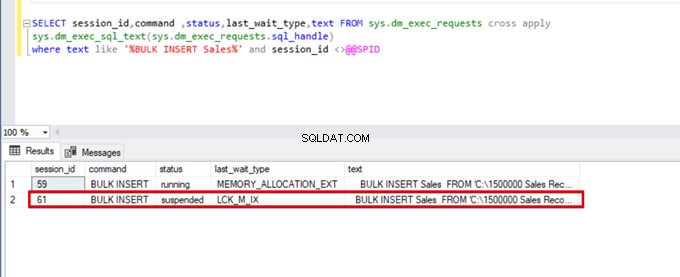
Както можете да видите на горното изображение, сесия 61, състоянието на процеса на групово вмъкване е спряно поради заключване. Ако потвърдим проблема, сесия 59 заключва дестинационната таблица за групово вмъкване. След това сесия 61 изчаква освобождаването на това заключване, за да продължи процеса на групово вмъкване.
Сега добавяме опцията TABLOCK към изразите за групово вмъкване и изпълняваме заявките.
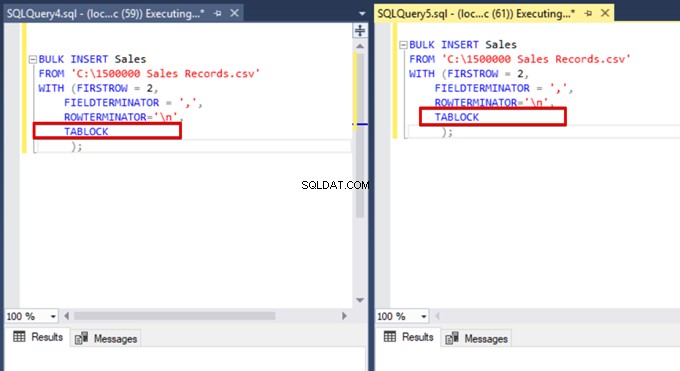
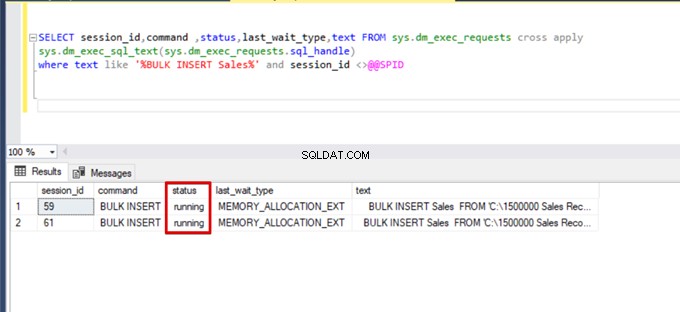
Когато изпълним отново заявката за наблюдение на DMV, не можем да видим никакъв спрян процес на групово вмъкване, тъй като SQL Server използва определен тип заключване, наречен заключване на групово актуализиране (BU). Този тип заключване позволява едновременно обработване на множество операции за групово вмъкване срещу една и съща маса. Тази опция също така намалява общото време на процеса на групово вмъкване.
Когато изпълним следната заявка по време на процеса на групово вмъкване, можем да наблюдаваме подробностите за заключване и типовете заключване:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()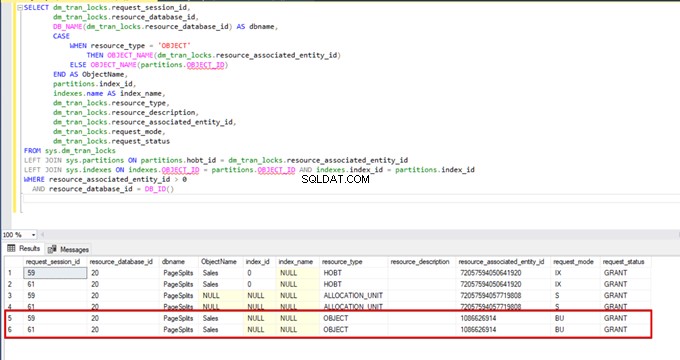
Заключение
Настоящата статия изследва всички подробности за операцията за групово вмъкване в SQL Server. По-специално, споменахме командата BULK INSERT и нейните настройки и опции. Освен това анализирахме различни сценарии, близки до реалните проблеми.
Полезен инструмент:
dbForge Data Pump – SSMS добавка за попълване на SQL бази данни с външни изходни данни и мигриране на данни между системите.