Според Wikipedia „Груповата вмъкване е процес или метод, предоставен от система за управление на база данни за зареждане на множество редове данни в таблица на база данни.“ Ако коригираме това обяснение в съответствие с израза BULK INSERT, груповото вмъкване позволява импортиране на външни файлове с данни в SQL Server. Да приемем, че нашата организация има CSV файл от 1 500 000 реда и искаме да импортираме този файл в конкретна таблица в SQL Server, така че лесно да използваме оператора BULK INSERT в SQL Server. Разбира се, можем да намерим няколко методологии за импортиране за обработка на този процес на импортиране на CSV файл, напр. можем да използваме bcp (b улкс опип rogram), съветник за импортиране и експортиране на SQL Server или пакет услуга за интеграция на SQL Server. Въпреки това, операторът BULK INSERT е много по-бърз и стабилен от използването на други методологии. Друго предимство на израза за групово вмъкване е, че предлага няколко параметъра, които помагат да се определят настройките на процеса на групово вмъкване.
Първо ще започнем много основна извадка и след това ще преминем през различни сложни сценарии.
Подготовка
Преди да стартираме пробите, имаме нужда от примерен CSV файл. Затова ще изтеглим примерен CSV файл от уебсайта на E for Excel, където можете да намерите различни примерни CSV файлове с различен номер на ред. Можете да намерите връзката в края на статията. В нашите сценарии ще използваме 1 500 000 записа за продажби. Изтеглете zip файл, след което разархивирайте CSV файла и го поставете в локалното си устройство.

Импортирайте CSV файл в таблица на SQL Server
Сценарий 1:Дестинацията и CSV файлът имат равен брой колони
В този първи сценарий ще импортираме CSV файла в таблицата на местоназначението в най-простата форма. Поставих моя примерен CSV файл на C:устройството и сега ще създадем таблица, в която ще импортираме данни от CSV файла.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
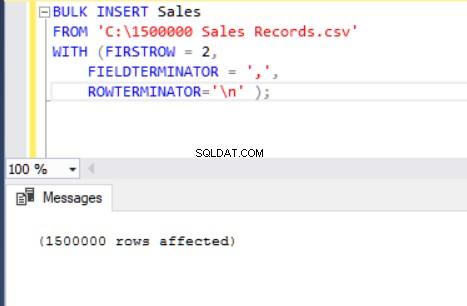
Следният оператор BULK INSERT импортира CSV файла в таблицата Sales.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
Сега ще обясним параметрите на горния израз за групово вмъкване.
Параметърът FIRSTROW определя началната точка на оператора за вмъкване. В примера по-долу искаме да пропуснем заглавките на колони, така че задаваме този параметър на 2.

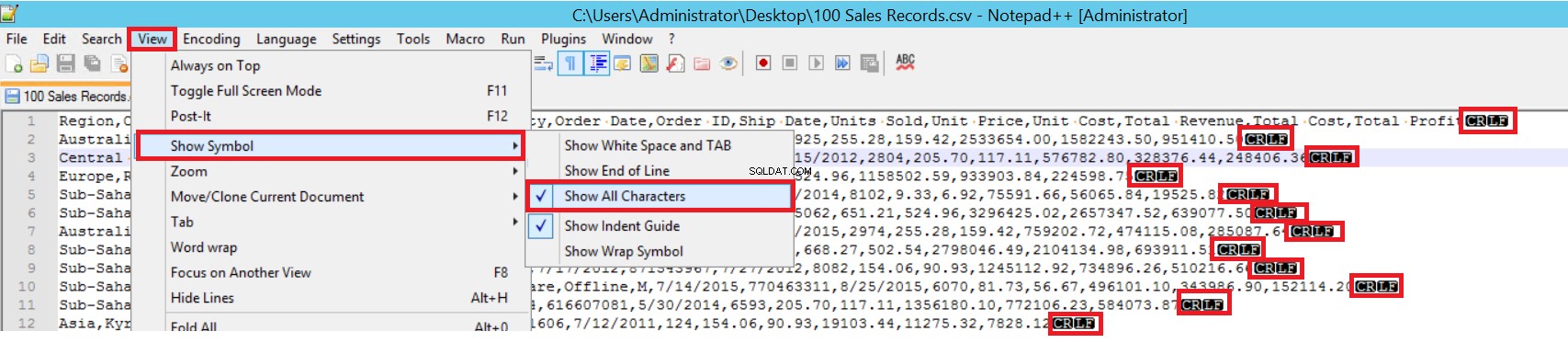
FIELDTERMINATOR дефинира знака, който разделя полетата едно от друго. SQL Server открива всяко поле по такъв начин. ROWTERMINATOR не се различава много от FIELDTERMINATOR. Той определя характера на разделяне на редовете. В примерния CSV файл терминаторът на полето е много ясен и представлява запетая (,). Но как можем да открием полеви терминатор? Отворете CSV файла в Notepad++ и след това отидете на View->Show Symbol->Show All Charters и след това разберете CRLF знаците в края на всяко поле.
CR =връщане на карета и LF =подаване на ред. Те се използват за маркиране на прекъсване на ред в текстов файл и се обозначава със знака „\n“ в израза за групово вмъкване.
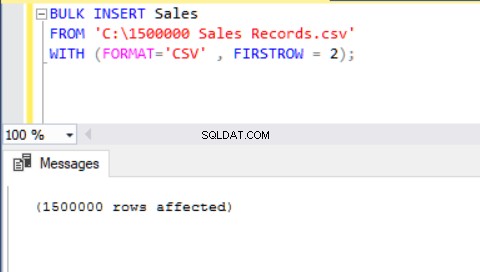
Друг метод за импортиране на CSV файл в таблица с помощта на групово вмъкване е използването на параметъра FORMAT. Моля, имайте предвид, че параметърът FORMAT е наличен само в SQL Server 2017 и по-нови версии.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Сега ще анализираме друг сценарий.
Сценарий 2:Таблицата на местоназначението има повече колони от CSV файла
В този сценарий ще добавим първичен ключ към таблицата Продажби и този случай нарушава съпоставянията на колоните за равенство. Сега ще създадем таблицата за продажби с първичен ключ, ще опитаме да импортираме CSV файла чрез командата за групово вмъкване и след това ще получим грешка.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
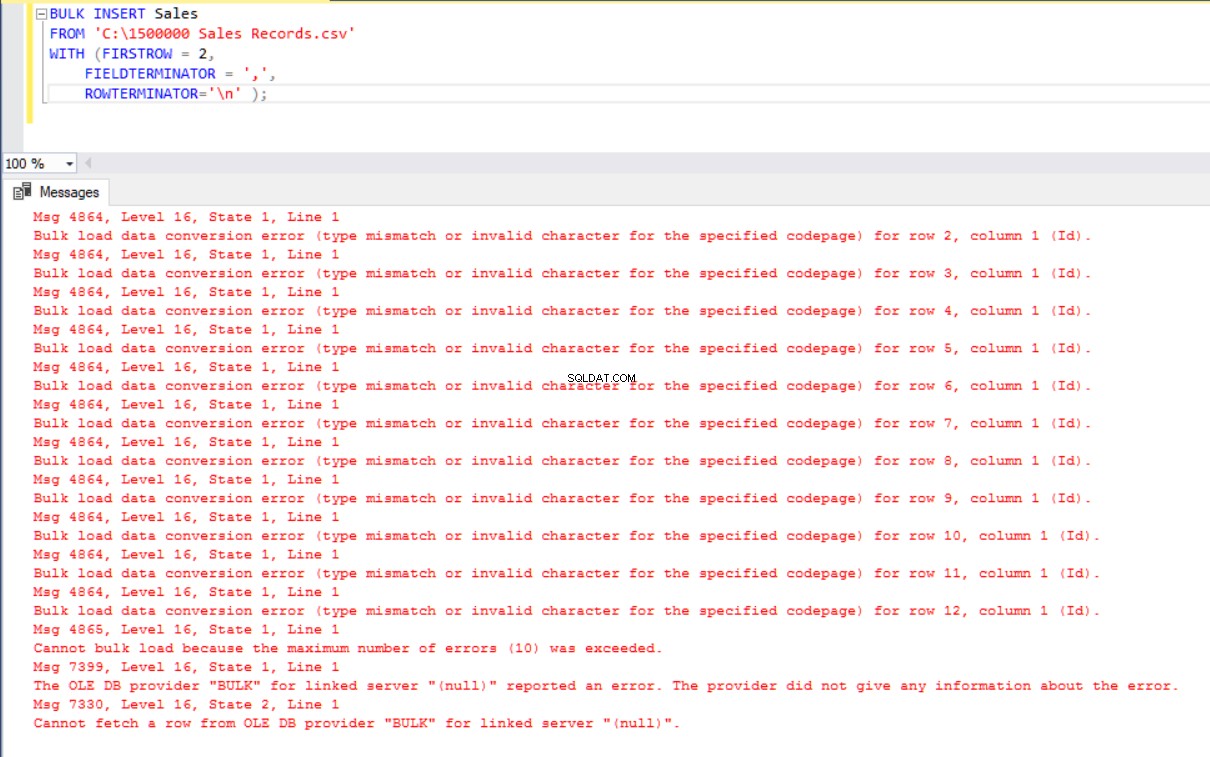
За да преодолеем тази грешка, ще създадем изглед на таблицата „Продажби“ със съпоставяне на колони с CSV файла и ще импортираме CSV данните върху този изглед в таблицата „Продажби“.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Сценарий 3:Как да отделя и зареди CSV файл в малка партида?
SQL Server придобива заключване към таблицата местоназначение по време на операцията за групово вмъкване. По подразбиране, ако не зададете параметъра BATCHSIZE, SQL Server отваря транзакция и вмъква всички CSV данни в тази транзакция. Въпреки това, ако зададете параметъра BATCHSIZE, SQL Server разделя CSV данните според стойността на този параметър. В следващата извадка ще разделим всички CSV данни на няколко набора от по 300 000 реда всеки. Така данните ще бъдат импортирани 5 пъти.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
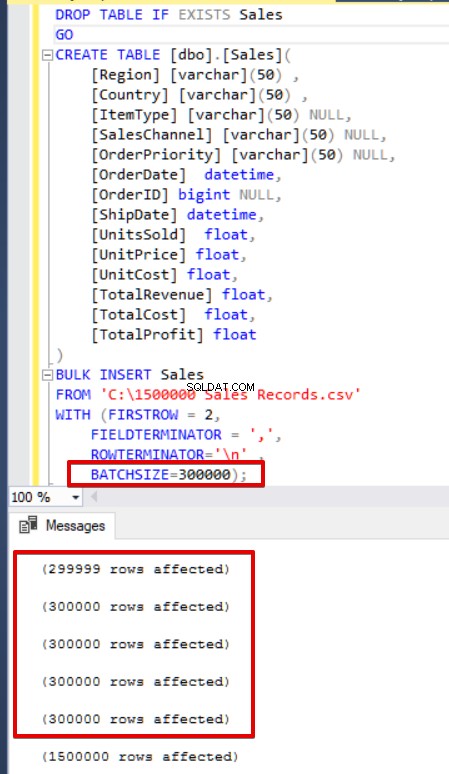
Ако вашият израз за групово вмъкване не включва параметъра за размер на партидата (BATCHSIZE), ще възникне грешка и SQL Server ще отмени целия процес на групово вмъкване. От друга страна, ако зададете параметъра за размер на партидата на израз за групово вмъкване, SQL Server ще върне назад само тази разделена част, където е възникнала грешката. Няма оптимална или най-добра стойност за този параметър, тъй като стойността на този параметър може да бъде променена според системните изисквания на вашата база данни.
Сценарий 4:Как да анулирате Процес за импортиране при получаване на грешка?
В някои сценарии на групово копиране, ако възникне грешка, може да искаме или да отменим процеса на групово копиране, или да продължим процеса. Параметърът MAXERRORS ни позволява да посочим максималния брой грешки. Ако процесът на групово вмъкване достигне тази максимална стойност на грешката, операцията за групово импортиране ще бъде отменена и връщана назад. Стойността по подразбиране за този параметър е 10.
В следващия пример умишлено ще повредим типа данни в 3 реда на CSV файла и ще зададем параметъра MAXERRORS на 2. В резултат на това цялата операция на групово вмъкване ще бъде отменена, тъй като номерът на грешката надвишава максималния параметър за грешка.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
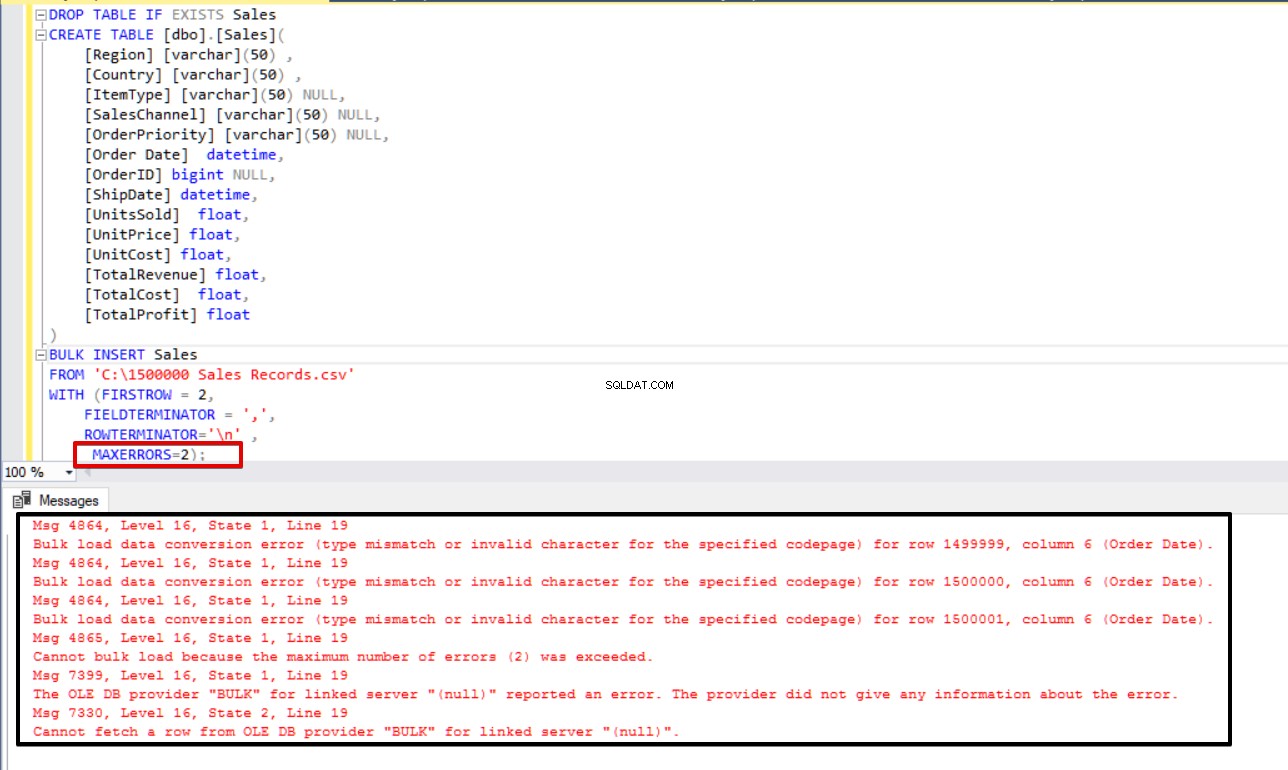
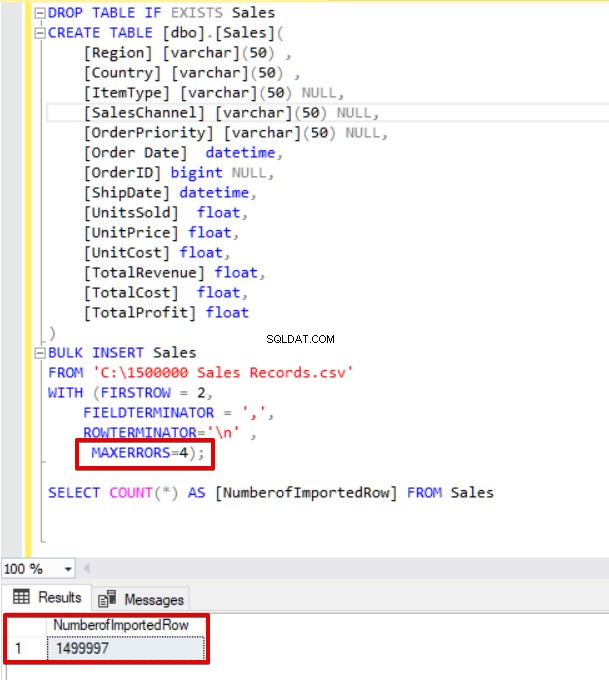
Сега ще променим параметъра за максимална грешка на 4. В резултат на това операторът за групово вмъкване ще пропусне тези редове и ще вмъкне правилни структурирани редове с данни и ще завърши процеса на групово вмъкване.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
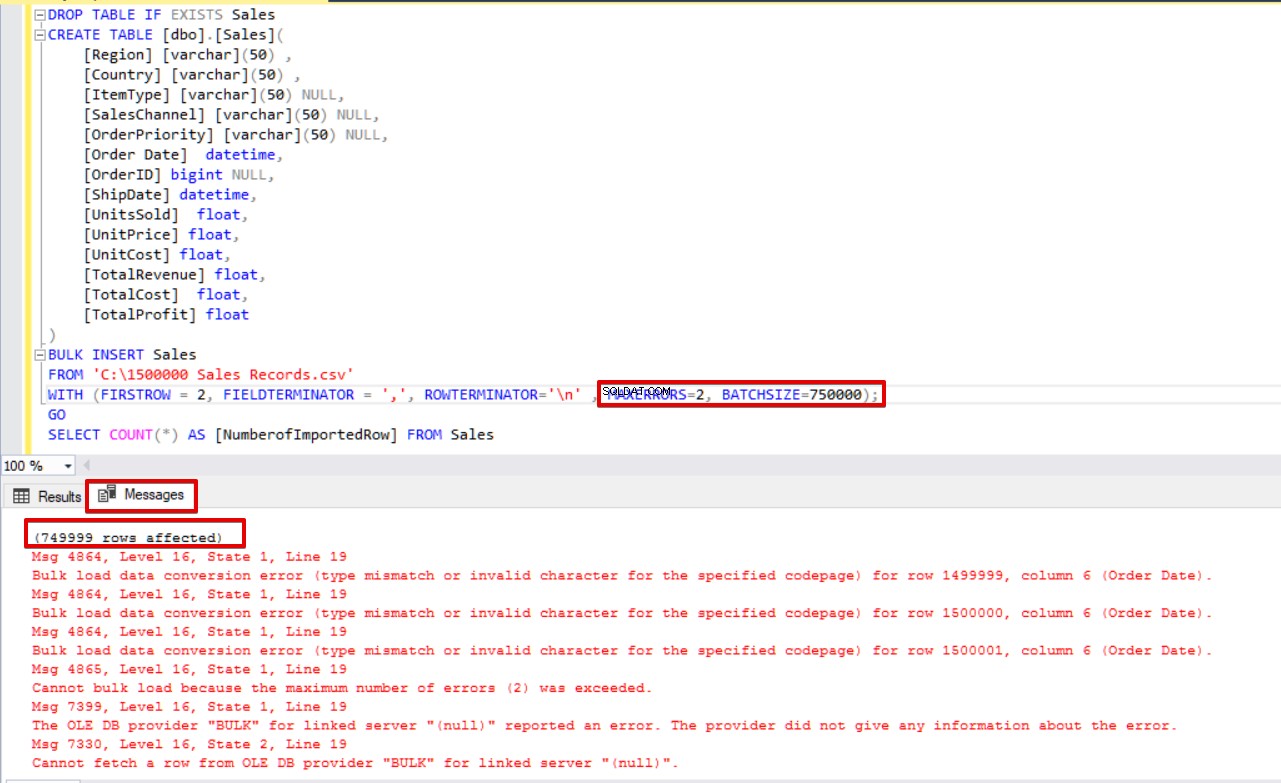
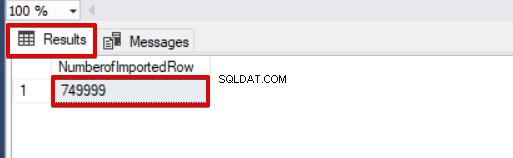
Освен това, ако използваме едновременно и двата, размера на партидата и максималните параметри за грешка, процесът на групово копиране няма да отмени цялата операция на вмъкване, а само ще отмени разделената част.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
В тази първа част от тази поредица от статии обсъдихме основите на използването на операцията за групово вмъкване в SQL Server и анализирахме няколко сценария, които са близки до проблемите в реалния живот.
Групово вмъкване на SQL Server – част 2
Полезни връзки:
Обемна вложка
E за Excel – Примерни CSV файлове/набори от данни за тестване (до 1,5 милиона записа)
Изтегляне на Notepad++
Полезен инструмент:
dbForge Data Pump – SSMS добавка за попълване на SQL бази данни с външни изходни данни и мигриране на данни между системите.