Функциите OVER и PARTITION BY са функции, използвани за разделяне на набор от резултати според определени критерии.
Тази статия обяснява как тези две функции могат да се използват във връзка за извличане на разделени данни по много специфични начини.
Подготовка на някои примерни данни
За да изпълним нашите примерни заявки, нека първо създадем база данни с име „studentdb“.
Изпълнете следната команда в прозореца на заявката си:
СЪЗДАВАНЕ НА БАЗА ДАННИ schooldb;
След това трябва да създадем таблицата „student“ в базата данни „studentdb“. Таблицата на учениците ще има пет колони:идентификатор, име, възраст, пол и общ_резултат.
Както винаги, уверете се, че сте добре архивирани, преди да експериментирате с нов код. Вижте тази статия за архивиране на бази данни на SQL Server, ако не сте сигурни.
Изпълнете следната заявка, за да създадете студентската таблица.
ИЗПОЛЗВАЙТЕ schooldbCREATE TABLE student( id INT ПРАВИЛЕН КЛЮЧ ИДЕНТИЧНОСТ, име VARCHAR(50) NOT NULL, пол VARCHAR(50) NOT NULL, възраст INT NOT NULL, total_score INT NOT NULL, )
И накрая, трябва да вмъкнем някои фиктивни данни, с които да работим в базата данни.
ИЗПОЛЗВАЙТЕ schooldbINSERT В СТОЙНОСТИТЕ на ученик ('Jolly', 'Female', 20, 500), ('Jon', 'Male', 22, 545), ('Sara', 'Female', 25, 600), („Лора“, „Жена“, 18, 400), („Алан“, „Мъж“, 20, 500), („Кейт“, „Жена“, 22, 500), („Джоузеф“, „Мъж“ , 18, 643), („Мишки“, „Мъжки“, 23, 543), („Мъдър“, „Мъжки“, 21, 499), („Елида“, „Женски“, 27, 400);
Вече сме готови да работим по проблем и да видим кой можем да използваме Over и Partition By, за да го разрешим.
Проблем
Имаме 10 записа в таблицата на учениците и искаме да покажем името, идентификатора и пола за всички ученици, а в допълнение искаме да покажем и общия брой ученици, които принадлежат към всеки пол, средната възраст на ученици от всеки пол и сумата от стойностите в колоната total_score за всеки пол.
Резултатът, който търсим, е както следва:
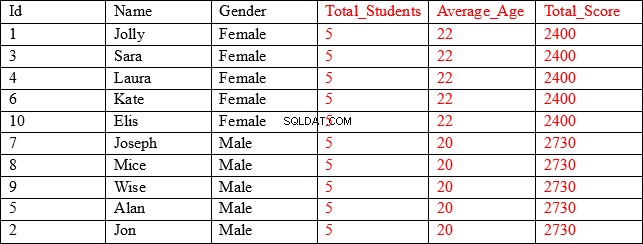
Както можете да видите, първите три колони (показани в черно) съдържат индивидуални стойности за всеки запис, докато последните три колони (показани в червено) съдържат обобщени стойности, групирани по колоната за пол. Например в колоната Average_Age първите пет реда показват средната възраст и общия резултат от всички записи, където полът е Жена.
Нашият набор от резултати съдържа обобщени резултати, обединени с неагрегирани колони.
За да извлечем обобщените резултати, групирани по конкретна колона, можем да използваме клаузата GROUP BY както обикновено.
ИЗПОЛЗВАЙТЕ schooldbSELECT пол, брой(пол) КАТО Total_Students, AVG(age) като Average_Age, SUM(total_score) като Total_ScoreFROM studentGROUP BY пол
Нека видим как можем да извлечем Total_Students, Average_Age и Total_Score на учениците, групирани по пол.
Ще видите следните резултати:

Сега нека да разширим това и да добавим „id“ и „name“ (неагрегираните колони в израза SELECT) и да видим дали можем да получим желания резултат.
ИЗПОЛЗВАЙТЕ schooldbSELECT id, име, пол, брой(пол) КАТО total_students, AVG(age) като Average_Age, SUM(total_score) като Total_ScoreFROM studentGROUP ПО пол
Когато изпълните горната заявка, ще видите грешка:

Грешката казва, че колоната с идентификатор на таблицата на учениците е невалидна в израза SELECT, тъй като използваме клауза GROUP BY в заявката.
Това означава, че ще трябва да приложим агрегатна функция към колоната id или ще трябва да я използваме в клаузата GROUP BY. Накратко, тази схема не решава проблема ни.
Решение с помощта на JOIN оператор
Едно решение за това би било да се използва операторът JOIN, за да се присъединят колоните с обобщени резултати към колони, съдържащи неагрегирани резултати.
За да направите това, имате нужда от подзаявка, която извлича пол, Total_Students, Average_Age и Total_Score на учениците, групирани по пол. След това тези резултати могат да бъдат присъединени към резултатите, получени от подзаявката с външния оператор SELECT. Това ще бъде приложено към колоната за пол на подзаявката, съдържаща обобщения резултат и колоната за пол на таблицата за ученици. Външният оператор SELECT ще включва неагрегирани колони, т.е. „id“ и „name“, както е по-долу.
ИЗПОЛЗВАЙТЕ schooldbSELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_ScoreFROM studentINNER JOIN(SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_total_Age, Average_total_Age студентГРУПА ПО пол) КАТО Aggregationon Aggregation.gender =student.gender
Горната заявка ще ви даде желания резултат, но не е оптималното решение. Трябваше да използваме оператор JOIN и подзаявка, която увеличава сложността на скрипта. Това не е елегантно или ефективно решение.
По-добър подход е да използвате клаузите OVER и PARTITION BY във връзка.
Решение с използване на OVER и PARTITION BY
За да използвате клаузите OVER и PARTITION BY, просто трябва да посочите колоната, по която искате да разделите своите обобщени резултати. Това се обяснява най-добре с помощта на пример.
Нека да разгледаме постигането на нашия резултат с помощта на OVER и PARTITION BY.
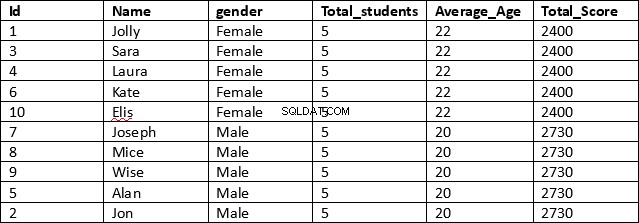
ИЗПОЛЗВАЙТЕ schooldbSELECT идентификатор, име, пол, COUNT(пол) НАД (РАЗДЕЛЕНИЕ ПО пол) КАТО Total_students,AVG(възраст) НАД (РАЗДЕЛЕНИЕ ПО пол) КАТО Average_Age,SUM(общ_резултат) НАД (РАЗДЕЛЕНИЕ ПО пол) КАТО Total_ScoreFROM ученик
Това е много по-ефективен резултат. В първия ред на скрипта се извличат колоните за идентификация, име и пол. Тези колони не съдържат обобщени резултати.
След това за колоните, които съдържат обобщени резултати, ние просто указваме обобщената функция, последвана от клаузата OVER и след това в скобите указваме клаузата PARTITION BY, последвана от името на колоната, за която искаме нашите резултати да бъдат разделени, както е показано по-долу.
Препратки
- Microsoft – Разбиране на клаузата OVER
- Midnight DBA – Въведение в OVER и PARTITION BY
- StackOverflow – Разлика между PARTITION BY и GROUP BY