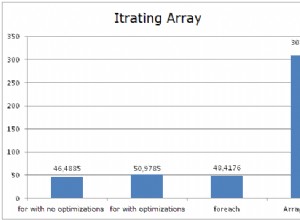
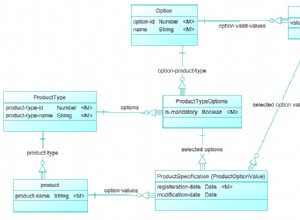
Има добро сравнение на InnoDB и MySQL Cluster (ndb), наскоро публикувано в документите... заслужава си да разгледате:https://dev.mysql.com/doc/refman/5.1/en/mysql-cluster-compared.html
Архитектурата на клъстера се състои от пул от MySQL сървъри, които са достъпни от приложението(ата); тези MySQL сървъри всъщност не съхраняват данните на клъстера, данните са разделени върху групата от възли с данни по-долу. Всеки MySQL сървър има достъп до данните във всички възли за данни. Ако един MySQL сървър промени част от данни, тя е незабавно видима за всички останали MySQL сървъри.
Очевидно тази архитектура прави изключително лесно мащабирането на базата данни. За разлика от разделянето, приложението не трябва да знае къде се съхраняват данните - то може просто да балансира натоварването на всички налични MySQL сървъри. За разлика от мащабирането с MySQL репликация, Cluster ви позволява да мащабирате записите също толкова добре, колкото и четенията. Нови възли за данни или MySQL сървъри могат да се добавят към съществуващ клъстер без загуба на услуга за приложението.
Архитектурата за споделено нищо на MySQL Cluster означава, че може да осигури изключително висока наличност (99,999%+). Всеки път, когато промените данни, те се репликират синхронно на втори възел на данни; ако един възел с данни се повреди, заявките за четене и запис на приложенията се обработват автоматично от възела за архивиране на данни.
Поради разпределения характер на MySQL Cluster, някои операции могат да бъдат по-бавни (например JOIN, които имат хиляди междинни резултати - въпреки че има налично прототипно решение, което се справя с това), но други могат да бъдат много бързи и могат да се мащабират изключително добре (например първични резултати). ключ чете и записва). Имате възможност да съхранявате таблици (или дори колони) в паметта или на диска и като изберете опцията за памет (с промени в контролна точка на диска във фонов режим) транзакциите могат да бъдат много бързо.
MySQL Cluster може да бъде по-сложен за настройка от един MySQL сървър, но може да ви попречи да прилагате разделяне или разделяне на четене/запис във вашето приложение. Люлки и кръгови кръстовища.
За да получите най-добрата производителност и мащабируемост от MySQL Cluster, може да се наложи да настроите приложението си (вижте Бялата книга за настройка на производителността на клъстера:https://www.mysql.com/why-mysql/white-papers/mysql_wp_cluster_perfomance.php ). Ако притежавате приложението, това обикновено не е голяма работа, но ако използвате приложение на някой друг, което не можете да промените, това може да е проблем.
Последната забележка е, че не е необходимо да бъде всичко или нищо - можете да изберете да съхранявате някои от вашите таблици в Cluster, а някои да използвате други машини за съхранение, това е опция за всяка таблица. Също така можете да репликирате между Cluster и други машини за съхранение (например, използвайте Cluster за вашата база данни по време на изпълнение и след това репликирайте в InnoDB, за да генерирате сложни отчети).