На първо място "токси" не е стандартен термин. Винаги дефинирайте своите условия! Или поне дайте подходящи връзки.
А сега към самия въпрос...
Не, ще имате 3 маси.
Вие сте почти на прав път, с изключение на това, че можете да използвате базираната на набори природа на SQL, за да "слеете" много от тези стъпки. Например, маркирането на елемент 1 с тагове:'tag1', 'tag2' и 'tag3' може да стане по следния начин...
INSERT IGNORE INTO tagmap (item_id, tag_id)
SELECT 1, tag_id FROM tags WHERE tag_text IN ('tag1', 'tag2', 'tag3');
IGNORE позволява това да успее, дори ако елементът вече е свързан с някои от тези тагове.
Това предполага, че всички необходими тагове вече са в tags . Приемаме tag.tag_id е автоматично увеличение, можете да направите нещо подобно, за да сте сигурни, че са:
INSERT IGNORE INTO tags (tag_text) VALUES ('tag1'), ('tag2'), ('tag3');
Няма магия. Ако „елементът е свързан с конкретен маркер“ е част от знанията, която искате да запишете, тогава тя ще има да има някакво физическо представяне в базата данни.
Имате предвид повторно маркиране на елементи (не модифициране на самите тагове)?
За да премахнете всички тагове, които не са в списъка, направете нещо подобно:
DELETE FROM tagmap
WHERE
item_id = 1
AND tag_id NOT IN (
SELECT tag_id FROM tags
WHERE tag_text IN ('tag1', 'tag3')
);
Това ще прекъсне връзката на елемента от всички тагове с изключение на „tag1“ и „tag3“. Изпълнете INSERT по-горе и това DELETE едно след друго, за да „покриете“ както добавянето, така и премахването на маркери.
Можете да играете с всичко това в SQL Fiddle .
вярно. Дъщерна крайна точка на FK няма да задейства референтно действие (като ON DELETE CASCADE), само родителят.
BTW, вие използвате тази схема, защото искате допълнителни полета в tags (до tag_text ), нали? Ако го направите, да не загубите тези допълнителни данни само защото всички връзки са изчезнали, е желано поведение.
Но ако просто искате tag_text , бихте използвали по-проста схема, при която изтриването на всички връзки би било същото като изтриването на самия маркер:
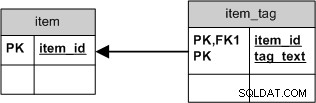
Това не само ще опрости SQL, но също така ще осигури по-добро клъстериране .
На пръв поглед „toxi“ може да изглежда, че спестява място, но това всъщност може да не е така на практика, тъй като изисква допълнителни таблици и индекси (а таговете обикновено са кратки).
Измерете, преди да решите да направите нещо подобно. Моята SQL Fiddle, спомената по-горе, използва много преднамерен ред на полета в tagmap PK, така че данните са групирани по начин, много удобен за този вид броене (запомнете:Таблиците на InnoDB са групирани
). Ще трябва да имате наистина огромно количество артикули (или да изисквате необичайно висока производителност), преди това да се превърне в проблем.
Във всеки случай,меретете върху реалистични количества данни!