Събрах примерна трансформация (щракнете с десния бутон и изберете връзката за запазване) въз основа на това, което сте предоставили. Единствената стъпка, за която се чувствам малко несигурна, са последните въвеждане на таблица. По същество пиша данните за присъединяване в таблицата и я оставям да се провали, ако вече съществува конкретна връзка.
забележка:
Това решение всъщност не отговаря на „Всички подходи трябва да включват някои от валидиране и стратегия за връщане назад, ако вмъкването се провали или не успее да поддържа референтна цялост“. критерии, макар че вероятно няма да се провали. Ако наистина искате да настроите нещо сложно, ние можем, но това определено трябва да ви подтикне към тези трансформации.

Поток от данни по стъпка
1. Започваме с четене във вашия файл. В моя случай го преобразувах в CSV, но разделът също е добре. 
2. Сега ще вмъкнем имената на служителите в таблицата Employee с помощта на combination lookup/update .След вмъкването добавяме Employee_id към нашия поток от данни като id и премахнете EmployeeName от потока от данни.

3. Тук просто използваме стъпка Select Values, за да преименуваме id поле към идентификатор на служител 
4. Вмъкнете заглавията на длъжностите точно както направихме служителите и добавете идентификатора на заглавието към нашия поток от данни, като също така изтриете JobLevelHistory от потока от данни.

5. Просто преименуване на идентификатора на заглавието в title_id (вижте стъпка 3) 
6. Вмъкнете офиси, вземете идентификатори, премахнете OfficeHistory от потока.

7. Просто преименуване на идентификатора на офиса на office_id (вижте стъпка 3)

8. Копирайте данните от последната стъпка в два потока със стойностите employee_id,office_id и employee_id,title_id съответно.

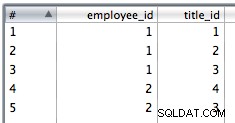
9. Използвайте вмъкване на таблица, за да вмъкнете данните за присъединяване. Избрах го да игнорира грешки при вмъкване, тъй като може да има дубликати и PK ограниченията ще направят някои редове неуспешни.
Изходни таблици