Използване на SET CHARACTER SET utf8 след използване на SET NAMES utf8 всъщност ще нулира character_set_connection и collation_connection до@@character_set_database и @@collation_database съответно.
ръководството заявява, че
-
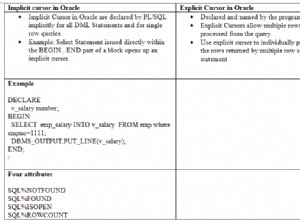
SET NAMES xе еквивалентен наSET character_set_client = x; SET character_set_results = x; SET character_set_connection = x; -
и
SET CHARACTER SET xе еквивалентен наSET character_set_client = x; SET character_set_results = x; SET collation_connection = @@collation_database;
докато SET collation_connection = x също така вътрешно изпълнява SET character_set_connection = <<character_set_of_collation_x>> и SET character_set_connection = x вътрешно също изпълнява SET collation_connection = <<default_collation_of_character_set_x .
Така че по същество нулирате character_set_connection до @@character_set_database и collation_connection до @@collation_database . Ръководството обяснява използването на тези променливи:
За да обобщим това, процедурата за кодиране/транскодиране, която MySQL използва за обработка на заявката и нейните резултати представляват многоетапно нещо:
- MySQL третира входящата заявка като кодирана в
character_set_client. - MySQL транскодира израза от
character_set_clientвcharacter_set_connection - когато сравнява стойностите на низове със стойности на колони, MySQL транскодира стойността на низа от
character_set_connectionв набора от знаци на дадена колона на базата данни и използва съпоставянето на колони, за да извърши сортиране и сравнение. - MySQL изгражда набора от резултати, кодиран в
character_set_results(това включва данни за резултатите, както и метаданни за резултати, като имена на колони и т.н.)
Така че може да се окаже, че SET CHARACTER SET utf8 не би било достатъчно, за да осигури пълна поддръжка на UTF-8. Помислете за набор от знаци в базата данни по подразбиране latin1 и колони, дефинирани с utf8 -charset и преминете през стъпките, описани по-горе. Като latin1 не може да покрие всички знаци, които UTF-8 може да покрие, може да загубите информация за знаци в стъпка 3 .
- Стъпка 3 : Като се има предвид, че вашата заявка е кодирана в UTF-8 и съдържа знаци, които не могат да бъдат представени с
latin1, тези знаци ще бъдат загубени при транскодиране отutf8наlatin1(наборът от символи по подразбиране в базата данни), което прави заявката ви неуспешна.
Така че мисля, че е безопасно да се каже, че SET NAMES ... е правилният начин за справяне с проблемите с набора от знаци. Въпреки че мога да добавя, че настройвате правилно променливите на вашия MySQL сървър (всички необходими променливи могат да бъдат зададени статично във вашия my.cnf ) ви освобождава от излишните разходи за производителност на допълнителната заявка, необходима при всяко свързване.