Добре, за да отговоря на въпроса ви защо SQL Server прави това, отговорът е, че заявката не е компилирана в логически ред, всеки израз се компилира по собствена заслуга, така че когато се генерира планът на заявката за вашия избран оператор, оптимизаторът не знае, че @val1 и @Val2 ще станат съответно 'val1' и 'val2'.
Когато SQL Server не знае стойността, той трябва да направи най-доброто предположение колко пъти тази променлива ще се появи в таблицата, което понякога може да доведе до неоптимални планове. Основната ми идея е, че една и съща заявка с различни стойности може да генерира различни планове. Представете си този прост пример:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Всичко, което направих тук, е да създам проста таблица и да добавя 1000 реда със стойности 1-10 за колоната val , обаче 1 се появява 991 пъти, а останалите 9 се появяват само веднъж. Предпоставката е тази заявка:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Би било по-ефективно просто да сканирате цялата таблица, отколкото да използвате индекса за търсене, след което да направите 991 търсения в отметки, за да получите стойността за Filler , но само с 1 ред следната заявка:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
ще бъде по-ефективно да се направи търсене на индекс и едно търсене на отметка, за да се получи стойността за Filler (и изпълнението на тези две заявки ще потвърди това)
Сигурен съм, че ограничението за търсене и търсене на отметки всъщност варира в зависимост от ситуацията, но е сравнително ниско. Използвайки примерната таблица, с малко опити и грешки, открих, че имам нужда от Val колона да има 38 реда със стойност 2, преди оптимизаторът да отиде за пълно сканиране на таблицата при търсене на индекс и търсене на отметка:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Така че за този пример ограничението е 3,7% от съвпадащите редове.
Тъй като заявката не знае колко реда ще съвпаднат, когато използвате променлива, тя трябва да отгатне, а най-простият начин е да откриете общия брой редове и да го разделите на общия брой различни стойности в колоната, така че в този пример приблизителният брой редове за WHERE val = @Val е 1000 / 10 =100, Действителният алгоритъм е по-сложен от този, но например това ще свърши работа. Така че, когато разгледаме плана за изпълнение на:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
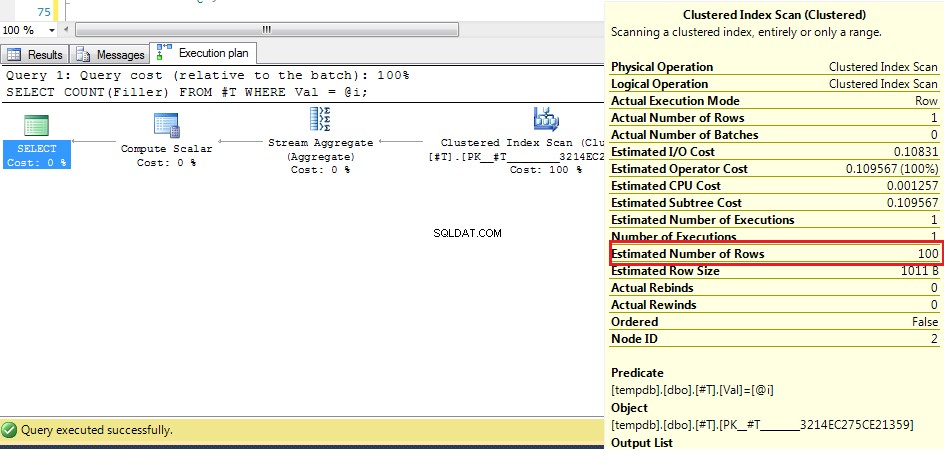
Тук можем да видим (с оригиналните данни), че приблизителният брой редове е 100, но действителните редове са 1. От предишните стъпки знаем, че с повече от 38 реда оптимизаторът ще избере клъстерно сканиране на индекс върху индекс търсене, така че тъй като най-доброто предположение за броя на редовете е по-високо от това, планът за неизвестна променлива е клъстерно сканиране на индекса.
Само за да докажем допълнително теорията, ако създадем таблица с 1000 реда числа 1-27, равномерно разпределени (така че приблизителният брой редове ще бъде приблизително 1000 / 27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
След това стартирайте заявката отново, получаваме план с търсене на индекс:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
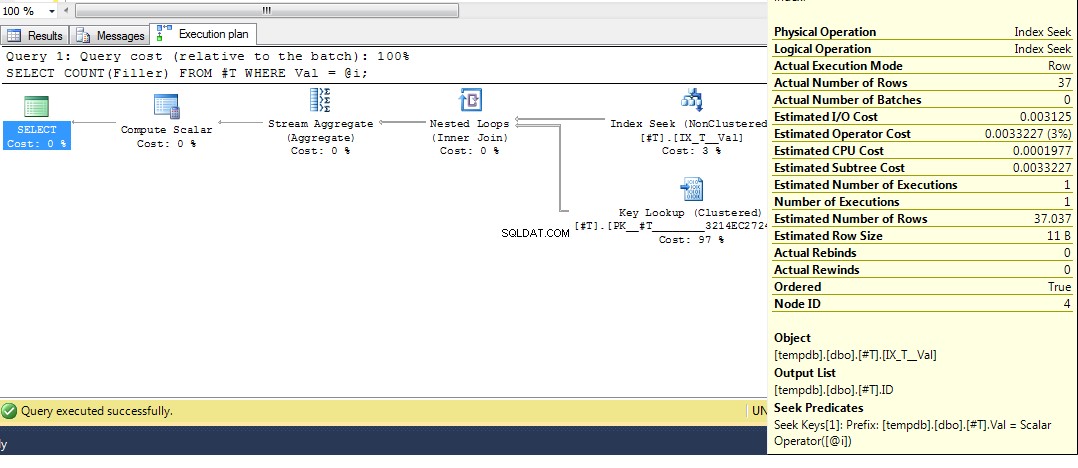
Така че се надяваме, че това доста изчерпателно покрива защо получавате този план. Сега предполагам, че следващият въпрос е как да наложите различен план, а отговорът е да използвате подсказката за заявка OPTION (RECOMPILE) , за да принудите заявката да се компилира по време на изпълнение, когато стойността на параметъра е известна. Връщане към оригиналните данни, където е най-добрият план за Val = 2 е търсене, но използването на променлива дава план с индексно сканиране, можем да изпълним:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
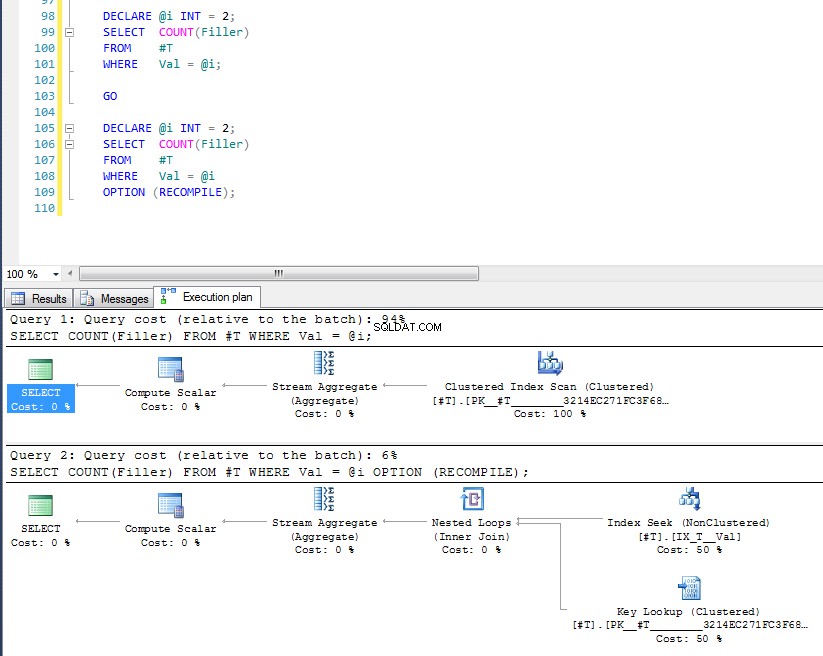
Можем да видим, че последният използва търсенето на индекс и ключово търсене, защото е проверил стойността на променливата по време на изпълнение и е избран най-подходящият план за тази конкретна стойност. Проблемът с OPTION (RECOMPILE) това означава, че не можете да се възползвате от кешираните планове за заявки, така че има допълнителни разходи за компилиране на заявката всеки път.