Прилагането на удобно за потребителя търсене може да бъде трудно, но също така може да се направи много ефективно. откъде да знам това? Неотдавна имах нужда да внедря търсачка в мобилно приложение. Приложението е изградено върху Ionic framework и ще се свърже с бекенд на CakePHP 2. Идеята беше да се показват резултатите, докато потребителят пише. Имаше няколко опции за това, но не всички отговаряха на изискванията на моя проект.
За да илюстрираме какво включва този вид задача, нека си представим търсенето на песни и техните възможни връзки (като изпълнители, албуми и т.н.).
Записите трябва да бъдат сортирани по релевантност, което ще зависи от това дали търсената дума съвпада с полета от самия запис или от други колони в свързани таблици. Също така, търсенето трябва да приложи поне някои основни думи. (Stemming се използва за получаване на кореновата форма за дума. „Stems“, „stemmer“, „stemming“ и „stemmed“ всички имат един и същ корен:„stem“.)
Подходът, представен тук, беше тестван с няколкостотин хиляди записа и успя да извлече полезни резултати, докато потребителят пишеше.
Продукти за пълнотекстово търсене, които да обмислите
Има няколко начина, по които можем да приложим този вид търсене. Нашият проект имаше някои ограничения по отношение на времето и ресурсите на сървъра, така че трябваше да поддържаме решението възможно най-просто. В крайна сметка се появиха няколко претендента:
Elasticsearch
Elasticsearch предоставя пълнотекстови търсения в услуга, ориентирана към документи. Той е проектиран да управлява огромни количества натоварване по разпределен начин:може да класира резултатите по уместност, да извършва агрегирания и да работи с основополагащи думи и синоними. Този инструмент е предназначен за търсене в реално време. От техния уебсайт:
Elasticsearch изгражда разпределени възможности върху Apache Lucene, за да предостави най-мощните налични възможности за пълнотекстово търсене. Мощен, удобен за разработчиците API за заявки поддържа многоезично търсене, геолокация, контекстуални предложения ли имахте предвид, автоматично довършване и фрагменти с резултати.
Elasticsearch може да работи като REST услуга, отговаряйки на http заявки и може да се настрои много бързо. Въпреки това, стартирането на двигателя като услуга изисква да имате някои привилегии за достъп до сървъра. И ако вашият хостинг доставчик не поддържа Elasticsearch от кутията, ще трябва да инсталирате някои пакети.
Изводът е, че този продукт е чудесен вариант, ако искате солидно решение за търсене. (Забележка:Може да се нуждаете от VPS или специален сървър, тъй като хардуерните изисквания са доста взискателни.)
Сфинкс
Подобно на Elasticsearch, Sphinx също предоставя много солиден продукт за пълнотекстово търсене:Craigslist обслужва повече от 300 000 000 заявки на ден с него. Sphinx не предоставя вграден RESTful интерфейс. Реализира се на C, с по-малък хардуерен отпечатък от Elasticsearch (който е внедрен в Java и може да работи на всяка ОС с jvm). Ще ви е необходим и root достъп до сървъра с специална RAM/CPU, за да стартирате правилно Sphinx.
Пълнотекстово търсене в MySQL
Исторически, пълнотекстови търсения се поддържаха в двигателите на MyISAM. След версия 5.6 MySQL поддържаше и пълнотекстови търсения в InnoDB системи за съхранение. Това беше страхотна новина, тъй като позволява на разработчиците да се възползват от референтната цялост на InnoDB, способността за извършване на транзакции и заключванията на ниво ред.
Има основно два подхода за пълнотекстови търсения в MySQL:естествен език и булев режим. (Трета опция допълва търсенето на естествен език с втора заявка за разширение.)
Основната разлика между естествения и булевия режим е, че булевият позволява определени оператори като част от търсенето. Например булеви оператори могат да се използват, ако дадена дума има по-голяма релевантност от другите в заявката или ако конкретна дума трябва да присъства в резултатите и т.н. Струва си да се отбележи, че и в двата случая резултатите могат да бъдат сортирани според уместността, изчислена от MySQL по време на търсене.
Вземане на решения
Най-доброто решение за нашия проблем беше да използваме InnoDb пълнотекстови търсения в булев режим. Защо?
- Имахме малко време да внедрим функцията за търсене.
- Към този момент нямахме големи данни, които да преборим, нито огромно натоварване, което да изисква нещо като Elasticsearch или Sphinx.
- Използвахме споделен хостинг, който не поддържа Elasticsearch или Sphinx и хардуерът беше доста ограничен на този етап.
- Въпреки че искахме произтичащи думи в нашата функция за търсене, това не беше прекъсване на сделката:можехме да го приложим (в рамките на ограничения) чрез някакво просто PHP кодиране и денормализиране на данните
- Пълнотекстови търсения в булев режим могат да търсят думи със заместващи знаци (за основната дума) и да сортират резултатите въз основа на уместността.
Търсене в пълен текст в булев режим
Както споменахме по-горе, търсенето на естествен език е най-простият подход:просто потърсете фраза или дума в колоните, където сте задали пълнотекстов индекс и ще получите резултати, сортирани по уместност.
В нормализирания модел Vertabelo
Нека видим как ще работи обикновеното търсене. Първо ще създадем примерна таблица:
-- Създаден от Vertabelo (https://vertabelo.com)-- Дата на последна промяна:2016-04-25 15:01:22.153-- tables-- Таблица:artistsCREATE TABLE изпълнители ( id int(11) НЕ NULL AUTO_INCREMENT, име varchar(255) NOT NULL, биографичен текст NOT NULL, CONSTRAINT artists_pk ОСНОВЕН КЛЮЧ (id)) ENGINE InnoDB;СЪЗДАВАНЕ НА ПЪЛЕН ТЕКСТОВ ИНДЕКС artists_idx_1 НА изпълнители (име);-- Край на файла.
В режим на естествен език
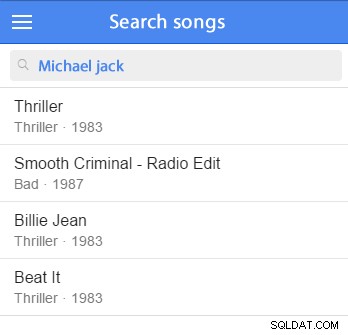
Можете да вмъкнете някои примерни данни и да започнете тестване. (Би било добре да го добавите към примерния си набор от данни.) Например, ще опитаме да потърсим Майкъл Джексън:
ИЗБЕРЕТЕ *FROM artistsWHERE MATCH (artists.name) СРЕЩУ („Майкъл Джаксън“ В РЕЖИМ НА ПРИРОДЕН ЕЗИК)
Тази заявка ще намери записи, които съответстват на думите за търсене, и ще сортира съвпадащите записи по релевантност; колкото по-добро е съвпадението, толкова по-подходящо е то и толкова по-висок резултат ще се появи в списъка.
В булев режим
Можем да извършим същото търсене в булев режим. Ако не приложим никакви оператори към нашата заявка, единствената разлика ще бъде, че резултатите не сортирани по уместност:
ИЗБЕРЕТЕ *FROM artistsWHERE MATCH (artists.name) СРЕЩУ („Майкъл Джексън“ В БУЛЕВ РЕЖИМ)
Операторът за заместващ знак в булев режим
Тъй като искаме да търсим основни и частични думи, ще ни трябва операторът за заместващ знак (*). Този оператор може да се използва при търсене в булев режим, поради което избрахме този режим.
Така че, нека да разгърнем силата на булевото търсене и да опитаме да потърсим част от името на художника. Ще използваме оператора за заместващ знак, за да съпоставим всеки изпълнител, чието име започва с „Mich“:
ИЗБЕРЕТЕ *ОТ ИЗПЪЛНИТЕЛИ WHERE МАЧ (име) СРЕЩУ ('Mich*' В БУЛЕВ РЕЖИМ) Сортиране по уместност в булев режим
Сега нека видим изчислената уместност за търсенето. Това ще ни помогне да разберем сортирането, което ще правим по-късно с Cake:
ИЗБЕРЕТЕ *, СЪВЪВСТАВАЙТЕ (име) СРЕЩУ ('mich*' В БУЛЕВ РЕЖИМ) КАТО РАЗГЛЕЖДАНЕ ОТ ИЗПЪЛНИТЕЛИ КЪДЕТО СЪВЪВПАДАНЕ (име) СРЕЩУ ('mich*' В БУЛЕВ РЕЖИМ) ПОРЪЧКА ПО ранг DESC Тази заявка извлича съвпаденията при търсене и стойността за уместност, която MySQL изчислява за всеки запис. Оптимизаторът на двигателя ще открие, че избираме уместността, така че няма да си прави труда да преизчислява ранга.
Изход на думи в пълнотекстово търсене
Когато включим произтичащи от думи в търсене, търсенето става по-удобно за потребителя. Дори ако резултатът не е дума сама по себе си, алгоритмите се опитват да генерират същия корен за производни думи. Например, основата „argu“ не е английска дума, но може да се използва като основа за „argue“, „argued“, „argues“, „arguing“, „Argus“ и други думи.
Създаването подобрява резултатите, тъй като потребителят може да въведе дума, която няма точно съвпадение, но нейната „основа“ има. Въпреки че стемерът на PHP или Python на Snowball може да бъде опция (ако имате root SSH достъп до вашия сървър), ние ще използваме класа PorterStemmer.php.
Този клас имплементира алгоритъма, предложен от Мартин Портър за основни думи на английски. Както е посочено от автора в неговия уебсайт, той е безплатен за използване за всякакви цели. Просто пуснете файла във вашата директория на доставчици в CakePHP, включете библиотеката във вашия модел и извикайте статичния метод, за да спрете дума:
//включете библиотеката (трябва да се нарича PorterStemmer.php) в папката Vendors на CakePHPApp::import('Vendor', 'PorterStemmer'); //поставете основата на дума (думите трябва да се поставят една по една)echo PorterStemmer::Stem(‘stemming’); //изходът ще бъде ‘stem’ Нашата цел е да направим търсенето бързо и ефективно и да можем да сортираме резултатите по тяхната уместност на целия текст. За да направим това, ще трябва да използваме основата на думите по два начина:
- Думите, въведени от потребителя
- Данни, свързани с песента (които ще съхраняваме в колони и ще сортираме за резултати въз основа на уместността)
Първият тип изход на думи може да се осъществи по следния начин:
App::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /премахнете нежеланите знаци$words =explode(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($words като $word) { $stemmedSearch .=PorterStemmer::Stem($ дума). "* ";//добавяме заместващия знак след всяка дума $unstemmedSearch =$word . "* ";//за търсене в колоната на изпълнителя, която не е stemmed}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { //в противен случай mySql ще се оплаче, тъй като не можете да използвате само заместващия знак $stemmedSearch =""; $unstemmedSearch ="";} Създадохме два низа:един за търсене на името на изпълнителя (без основопоставяне) и един за търсене в другите колони, свързани с основата. Това ще ни помогне по-късно да изградим нашето „срещу“ част от заявката за пълен текст. Сега нека видим как можем да спрем и сортираме данните за песента.
Денормализиране на данните за песен
Нашите критерии за сортиране ще се основават на съвпадение първо с изпълнителя на песента (без отделно). Следва името на песента, албумът и свързаните категории. Изходът ще се използва за всички вторични критерии за търсене.
За да илюстрирам това, да предположим, че търся „nirvana“ и има песен, наречена „Nirvana Games“ от „XYZ“, и друга песен, наречена „Polly“ от изпълнителя „Nirvana“. Резултатите трябва да изброят първо „Polly“, тъй като съвпадението на името на изпълнителя е по-важно от съвпадението на името на песента (въз основа на моите критерии).
За да направя това, добавих 4 полета в songs таблица, по една за всеки от критериите за търсене/сортиране, които искаме:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_artist`, ADD `denorm_album(`5 ALBUM) denorm_trackname`,ДОБАВЕТЕ `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ДОБАВЯНЕ НА ПЪЛЕН ТЕКСТ (`denorm_artist`), ДОБАВЯНЕ НА ПЪЛЕН ТЕКСТ (`denorm_trackname`), ДОБАВЯНЕ НА ПЪЛЕН ТЕКСТ (`denorm_album`),`te ADD FULLTEXT (`denorm_album`);
Пълният ни модел на база данни ще изглежда така:
Всеки път, когато запазвате песен с помощта на добавяне/редактиране в CakePHP, просто трябва да съхраните името на изпълнителя в колоната denorm_artist без да го спирам. След това добавете името на заглавната песен в denorm_trackname поле (подобно на това, което направихме в търсения текст) и запазете името на основния албум в denorm_album колона. И накрая, съхранете основния набор от категории за песента в denorm_categories поле, обединяване на думите и добавяне на един интервал между всяко име на категория.
Пълнотекстово търсене и сортиране по уместност в CakePHP
Продължавайки с примера за търсене на „Nirvana“, нека видим какво може да постигне подобна на тази заявка:
ИЗБЕРЕТЕ име на песен, MATCH(denorm_artist) СРЕЩУ ('Nirvana*' В БУЛЕВ РЕЖИМ) като ранг1, MATCH(denorm_trackname) СРЕЩУ ('Nirvana*' В БУЛЕВ РЕЖИМ) като ранг2, MATCH(denorm_album) ПРОТИВ* ('N В БУЛЕВ РЕЖИМ) като ранг3, МАЧ (denorm_categories) СРЕЩУ ('Nirvana*' В БУЛЕВ РЕЖИМ) като ранг 4 ОТ песни, КЪДЕТО СЪВЪВПАДАТ(denorm_artist) СРЕЩУ ('Nirvana*' В БУЛЕВ РЕЖИМ) ИЛИ СВЪВПАДАНЕ (име'denorm_track) ' В БУЛЕВ РЕЖИМ) ИЛИ МАЧИ(denorm_album) СРЕЩУ ('Nirvana*' В БУЛЕВ РЕЖИМ) ИЛИ МАЧИ(denorm_categories) СРЕЩУ ('Nirvana*' В БУЛЕВ РЕЖИМ) ПОРЪЧАЙТЕ ПО ранг1 DESC, ранг2 DESC, ранг 4 DESC, ранг 4 DESC предварително> Ще получим следния изход:
| име на песен | ранг1 | ранг2 | ранг3 | ранг4 |
| Поли | 0,0906190574169159 | 0 | 0 | 0 |
| нирвана игри | 0 | 0,0906190574169159 | 0 | 0 |
За да направите това в CakePHP, намерете методът трябва да бъде извикан с помощта на комбинация от параметри „полета“, „условия“ и „поръчка“. Продължавайки с предишния примерен код на PHP:
//в рамките на файла на модела на Song.php $fields =array( "Song.trackname", "MATCH(Song.denorm_artist) СРЕЩУ ({$unstemmedSearch} В БУЛЕВ РЕЖИМ) като `rank1`", "МАЧ (Песен. denorm_trackname) СРЕЩУ ({$stemmedSearch} В БУЛЕВ РЕЖИМ) като `rank2`", "МАЧИ(Song.denorm_album) СРЕЩУ ({$stemmedSearch} В БУЛЕВ РЕЖИМ) като `rank3`", "МАЧИ(Song.denorm_categories) {$stemmedSearch} В БУЛЕВ РЕЖИМ) като `rank4`" );$order ="`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";$conditions =array( "ИЛИ" => array( "СЪВТОРВАНЕ(Song.denorm_artist) СРЕЩУ ({$unstemmedSearch} В БУЛЕВ РЕЖИМ)", "СЪВТЪРЖАНЕ(Song.denorm_trackname) СРЕЩУ ({$stemmedSearch} В БУЛЕВ РЕЖИМ)", "СЪВТЪРЖИ (ПЕСЕН. denorm_album) СРЕЩУ ({$stemmedSearch} В БУЛЕВ РЕЖИМ)", "СЪВТОРВАНЕ(Song.denorm_categories) СРЕЩУ ({$stemmedSearch} В БУЛЕВ РЕЖИМ)" ) );$results =$this->find (‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order); $results ще бъде масивът от песни, сортирани по критериите, които дефинирахме по-рано.
Това решение може да се използва за генериране на търсения, които са смислени за потребителя – без да се изисква твърде много време от разработчиците или добавяне на голяма сложност към кода.
Да направим CakePHP търсенията още по-добри
Струва си да се спомене, че „подправянето“ на денормализираните колони с повече данни може да доведе до по-добри резултати.
Под „подправка“ имам предвид, че бихте могли да включите в денормализираните колони повече данни от допълнителни колони, които смятате за полезни с цел да направите резултатите по-подходящи, например, ако знаехте, че страната на даден изпълнител може да фигурира в думите за търсене, вие може да добави държавата заедно с името на изпълнителя в denorm_artist колона. Това ще подобри качеството на резултатите от търсенето.
От моя опит (в зависимост от действителните данни, които използвате и колоните, които денормализирате) най-високите резултати обикновено са наистина точни. Това е чудесно за мобилни приложения, тъй като превъртането надолу по дълъг списък може да бъде разочароващо за потребителя.
И накрая, ако трябва да получите повече данни от таблиците, за които се отнася песента, винаги можете да се присъедините и да получите изпълнителя, категориите, албумите, коментарите на песента и т.н. Ако използвате филтъра за поведение на CakePHP, бих предлагаме добавяне на приставката EagerLoader, за да извършите ефективно обединяването.
Ако имате свой собствен подход за прилагане на пълнотекстово търсене, моля, споделете го в коментарите по-долу. Всички можем да се поучим от опита на другия.