Базите данни трябва да работят оптимално, но това не е толкова лесна задача. Базата данни ИНФОРМАЦИОННА СХЕМА може да бъде вашето тайно оръжие във войната за оптимизиране на базата данни.
Свикнали сме да създаваме бази данни с помощта на графичен интерфейс или серия от SQL команди. Това е напълно добре, но също така е добре да разберете малко за това, което се случва на заден план. Това е важно за създаването, поддръжката и оптимизирането на база данни, а също така е добър начин за проследяване на промените, които се случват „зад кулисите“.
В тази статия ще разгледаме шепа SQL заявки, които могат да ви помогнат да надникнете в работата на MySQL база данни.
База данни INFORMATION_SCHEMA
Вече обсъдихме INFORMATION_SCHEMA база данни в тази статия. Ако още не сте го чели, определено бих ви препоръчал да го направите, преди да продължите.
Ако имате нужда от опресняване на INFORMATION_SCHEMA база данни – или ако решите да не четете първата статия – ето някои основни факти, които трябва да знаете:
INFORMATION_SCHEMAбазата данни е част от стандарта ANSI. Ще работим с MySQL, но други RDBMS имат свои варианти. Можете да намерите версии за H2 Database, HSQLDB, MariaDB, Microsoft SQL Server и PostgreSQL.- Това е базата данни, която следи всички други бази данни на сървъра; тук ще намерим описания на всички обекти.
- Както всяка друга база данни,
INFORMATION_SCHEMAбазата данни съдържа редица свързани таблици и информация за различни обекти. - Можете да направите заявка към тази база данни с SQL и да използвате резултатите за:
- Наблюдавайте състоянието и производителността на базата данни и
- Автоматично генериране на код въз основа на резултатите от заявката.
Сега нека преминем към запитване към базата данни INFORMATION_SCHEMA. Ще започнем, като разгледаме модела на данни, който ще използваме.
Моделът на данните
Моделът, който ще използваме в тази статия, е показан по-долу.
Това е опростен модел, който ни позволява да съхраняваме информация за класове, инструктори, студенти и други свързани подробности. Нека разгледаме накратко таблиците.
Ще съхраняваме списъка с инструктори в lecturer маса. За всеки лектор ще запишем first_name и last_name .
class таблицата изброява всички класове, които имаме в нашето училище. За всеки запис в тази таблица ще съхраняваме class_name , ИД на лектора, планирана start_date и end_date и всякакви допълнителни class_details . За простота ще приема, че имаме само един лектор на клас.
Класовете обикновено се организират като поредица от лекции. Те обикновено изискват един или повече изпити. Ще съхраняваме списъци със свързани лекции и изпити в lecture и exam маси. И двете ще имат идентификатора на свързания клас и очаквания start_time и end_time .
Сега имаме нужда от ученици за нашите класове. Списък с всички ученици се съхранява в student маса. Още веднъж ще съхраняваме само first_name и last_name на всеки ученик.
Последното нещо, което трябва да направим, е да проследим дейностите на учениците. Ще съхраняваме списък на всеки клас, за който се е регистрирал ученик, записите за посещаемостта на ученика и резултатите от изпитите им. Всяка от останалите три таблици – on_class , on_lecture и on_exam – ще има препратка към ученика и препратка към съответната таблица. Само on_exam таблицата ще има допълнителна стойност:оценка.
Да, този модел е много прост. Бихме могли да добавим много други подробности за студенти, преподаватели и класове. Бихме могли да съхраняваме исторически стойности, когато записи се актуализират или изтриват. Все пак този модел ще бъде достатъчен за целите на тази статия.
Създаване на база данни
Готови сме да създадем база данни на нашия локален сървър и да проучим какво се случва вътре в нея. Ще експортираме модела (във Vertabelo) с помощта на „Generate SQL script ” бутон.
След това ще създадем база данни на екземпляра на MySQL Server. Нарекох моята база данни „classes_and_students “.
Следващото нещо, което трябва да направим, е да изпълним предварително генериран SQL скрипт.
Сега имаме базата данни с всички нейни обекти (таблици, първични и външни ключове, алтернативни ключове).
Размер на базата данни
След като скриптът се изпълни, данните за „classes and students ” базата данни се съхранява в INFORMATION_SCHEMA база данни. Тези данни са в много различни таблици. Няма да ги изброявам отново тук; направихме това в предишната статия.
Нека видим как можем да използваме стандартен SQL в тази база данни. Ще започна с една много важна заявка:
SET @table_schema ="classes_and_students";ИЗБЕРЕТЕ КРЪГЛА(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) КАТО "DB Size (in D MB Size", INFORMATION MB) .TABLES.DATA_FREE )/ 1024 / 1024, 2) КАТО "Свободно пространство (в MB)" ОТ INFORMATION_SCHEMA.TABLESWHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA =@table_schema;
Запитваме само INFORMATION_SCHEMA.TABLES таблица тук. Тази таблица трябва да ни даде повече от достатъчно подробности за всички таблици на сървъра. Моля, имайте предвид, че филтрирах само таблици от „classes_and_students " база данни с помощта на SET променлива в първия ред и по-късно използвайки тази стойност в заявката. Повечето таблици съдържат колоните TABLE_NAME и TABLE_SCHEMA , които обозначават таблицата и схемата/базата данни, към които принадлежат тези данни.
Тази заявка ще върне текущия размер на нашата база данни и свободното пространство, запазено за нашата база данни. Ето действителния резултат:

Както се очакваше, размерът на празната ни база данни е по-малък от 1 MB, а запазеното свободно пространство е много по-голямо.
Размери и свойства на таблицата
Следващото интересно нещо, което трябва да направите, е да разгледате размерите на таблиците в нашата база данни. За целта ще използваме следната заявка:
SET @table_schema ="classes_and_students";ИЗБЕРЕТЕ INFORMATION_SCHEMA.TABLES.TABLES.TABLE_NAME, ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 inize, Size, 1024 MB ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) КАТО "Свободно пространство (в MB)", MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) КАТО номер_ред_таблици, MAX_RED_TABLE_ROWS, MAX_MED_READ_BROJ, MAX_MED_INFORMATION.INFORMATION_CREAM_INFORMATION_INFORMATION_INFORMATION_INFORMATION_INFORMATION_INFORMATION_INFORM. TABLESWHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA =@table_schemaGROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAMEORDER BY 2 DESC;
Заявката е почти идентична с предишната, с едно изключение:резултатът е групиран на ниво таблица.
Ето снимка на резултата, върнат от тази заявка:
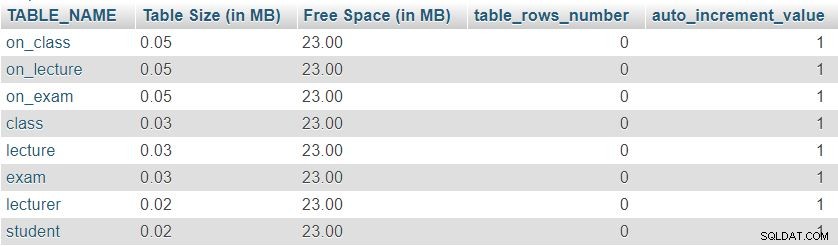
Първо, можем да забележим, че всичките осем таблици имат минимален „Размер на таблицата“ запазено за дефиниране на таблица, която включва колоните, първичния ключ и индекса. „Свободно пространство“ се разпределя еднакво между всички таблици.
Можем също да видим броя на редовете в момента във всяка таблица и текущата стойност на auto_increment свойство за всяка маса. Тъй като всички таблици са напълно празни, нямаме данни и auto_increment е зададено на 1 (стойност, която ще бъде присвоена на следващия вмъкнат ред).
Първични ключове
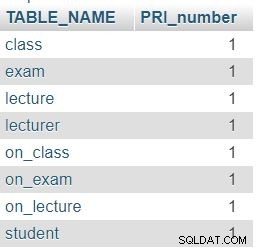
Всяка таблица трябва да има дефинирана стойност на първичен ключ, така че е разумно да проверим дали това е вярно за нашата база данни. Един от начините да направите това е като свържете списък с всички таблици със списък с ограничения. Това трябва да ни даде информацията, от която се нуждаем.
set @table_schema ="class_and_students"; изберете tab.table_name, count (*) като pri_numberfrom information_schema.tables tableft присъединяване (изберете information_schema.columns.table_schema, information_schema.column.table_name от informal_schema.columns when onforment_schema.columns.table_schema, information_schema.column.table_name от information_schema.columns when information_column.table_name. =@table_schema AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY ='PRI') col ON tab.TABLE_SCHEMA =col.TABLE_SCHEMA AND tab.TABLE_NAME =col.TABLE_NAMEWHERE tab.TABLE_SCHEMA =BY tab_schemaИзползвахме и
INFORMATION_SCHEMA.COLUMNSтаблица в тази заявка. Докато първата част на заявката просто ще върне всички таблици в базата данни, втората част (следLEFT JOIN) ще преброи броя на PRIs в тези таблици. ИзползвахмеLEFT JOINзащото искаме да видим дали дадена таблица има 0 PRI вCOLUMNSтаблица.Както се очаква, всяка таблица в нашата база данни съдържа точно една колона с първичен ключ (PRI).
„Острови“?
„Острови“ са маси, които са напълно отделени от останалата част от модела. Те се случват, когато таблицата не съдържа външни ключове и не е посочена в друга таблица. Това наистина не трябва да се случва, освен ако няма наистина основателна причина, напр. когато таблиците съдържат параметри или съхраняват резултати или отчети в модела.
SET @table_schema ="classes_and_students";ИЗБЕРЕТЕ tab.TABLE_NAME, (СЛУЧАЙ, КОГАТО f1.number_referenced Е NULL, ТОГАВА 0 ELSE f1.number_referenced END) КАТО номер_referenced, (CASE, КОГАТО f2.number_referencing Е NULL_referenced END END END . ) AS number_referencingFROM INFORMATION_SCHEMA.TABLES tabLEFT JOIN -- # table was used as a reference( SELECT INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA, INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME, COUNT(*) AS number_referenced FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA =@table_schema Група от information_schema.key_column_usage.referenced_table_schema, information_schema.key_column_usage.referenced_table_name) f1 on tab.table_schema =f1.referenced_table_schema и tab.table_name =f1.referency_table_namelet in… _COLUMN_USAGE.TABLE_SCHEMA, INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME, COUNT(*) AS number_referencing FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA =@table_schema AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL GROUP BY INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA, INFORMATION_SCHEMA.KEY_COLUMN_USAGE. TABLE_NAME) f2 ON tab.TABLE_SCHEMA =f2.TABLE_SCHEMA И tab.TABLE_NAME =f2.TABLE_NAME WHERE tab.TABLE_SCHEMA =@table_schema;Каква е идеята зад тази заявка? Е, ние използваме
INFORMATION_SCHEMA.KEY_COLUMN_USAGEтаблица, за да проверите дали някоя колона в таблицата е препратка към друга таблица или дали някоя колона се използва като препратка в която и да е друга таблица. Първата част на заявката избира всички таблици. След първото LEFT JOIN отчитаме колко пъти е била използвана колона от тази таблица като справка. След второто LEFT JOIN отчитаме колко пъти всяка колона от тази таблица е препращала към друга таблица.Върнатият резултат е:
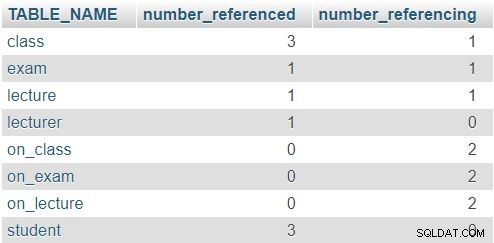
В реда за
classтаблица, числата 3 и 1 показват, че тази таблица е била спомената три пъти (вlecture,examиon_classтаблици) и че съдържа един атрибут, препращащ към друга таблица (lecturer_id). Другите таблици следват подобен модел, въпреки че действителните числа, разбира се, ще бъдат различни. Правилото тук е, че нито един ред не трябва да има 0 и в двете колони.Добавяне на редове
Засега всичко вървеше според очакванията. Успешно импортирахме нашия модел на данни от Vertabelo на локалния MySQL сървър. Всички таблици съдържат ключове, точно както искаме, и всички таблици са свързани една с друга – в нашия модел няма „острови“.
Сега ще вмъкнем някои редове в нашите таблици и ще използваме демонстрираните по-рано заявки, за да проследим промените в нашата база данни.
След като добавим 1000 реда в таблицата на лекторите, отново ще изпълним заявката от „
Table Sizes and Properties” раздел. Той ще върне следния резултат:
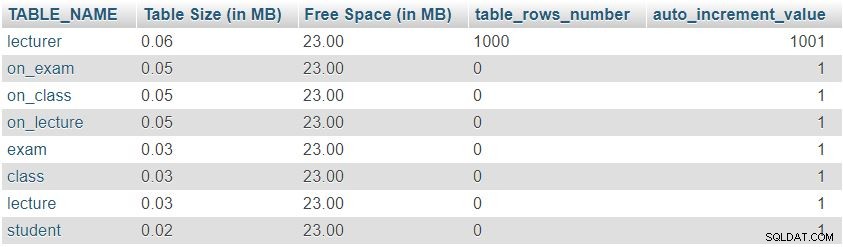
Лесно можем да забележим, че броят на редовете и стойностите на auto_increment са се променили според очакванията, но няма значителна промяна в размера на таблицата.
Това беше само тестов пример; в реални ситуации бихме забелязали значителни промени. Броят на редовете ще се промени драстично в таблици, попълнени от потребители или автоматизирани процеси (т.е. таблици, които не са речници). Проверката на размера и стойностите в такива таблици е много добър начин за бързо намиране и коригиране на нежелано поведение.
Искате ли да споделите?
Работата с бази данни е постоянен стремеж към оптимална производителност. За да бъдете по-успешни в това преследване, трябва да използвате всеки наличен инструмент. Днес видяхме няколко заявки, които са полезни в нашата борба за по-добра производителност. Открихте ли нещо друго полезно? Играли ли сте с
INFORMATION_SCHEMAбаза данни преди? Споделете своя опит в коментарите по-долу.



