В наши дни има много доставчици на облак. Те могат да бъдат малки или големи, локални или с центрове за данни, разположени в целия свят. Много от тези облачни доставчици предлагат някакъв вид решение за управлявана релационна база данни. Поддържаните бази данни обикновено са MySQL или PostgreSQL или някакъв друг вид релационна база данни.
Когато проектирате всякакъв вид инфраструктура на база данни, е важно да разберете нуждите на вашия бизнес и да решите какъв вид наличност трябва да постигнете.
В тази публикация в блога ще разгледаме опциите за висока наличност за базирани на MySQL решения от един от най-големите доставчици на облак – Google Cloud Platform.
Разгръщане на високодостъпна среда с помощта на GCP SQL екземпляр
За този блог искаме много проста среда - една база данни, с може би една или две реплики. Искаме да можем лесно да преминаваме при отказ и да възстановяваме операциите възможно най-скоро, ако главният се провали. Ще използваме MySQL 5.7 като версия по избор и ще започнем със съветника за внедряване на инстанция:
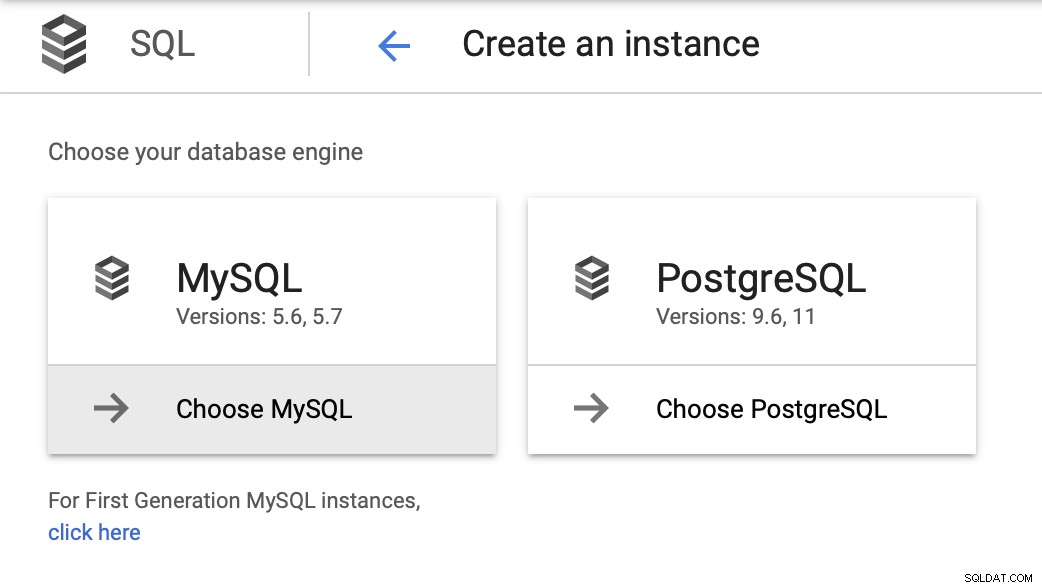
След това трябва да създадем основната парола, да зададем името на екземпляра и определете къде трябва да се намира:
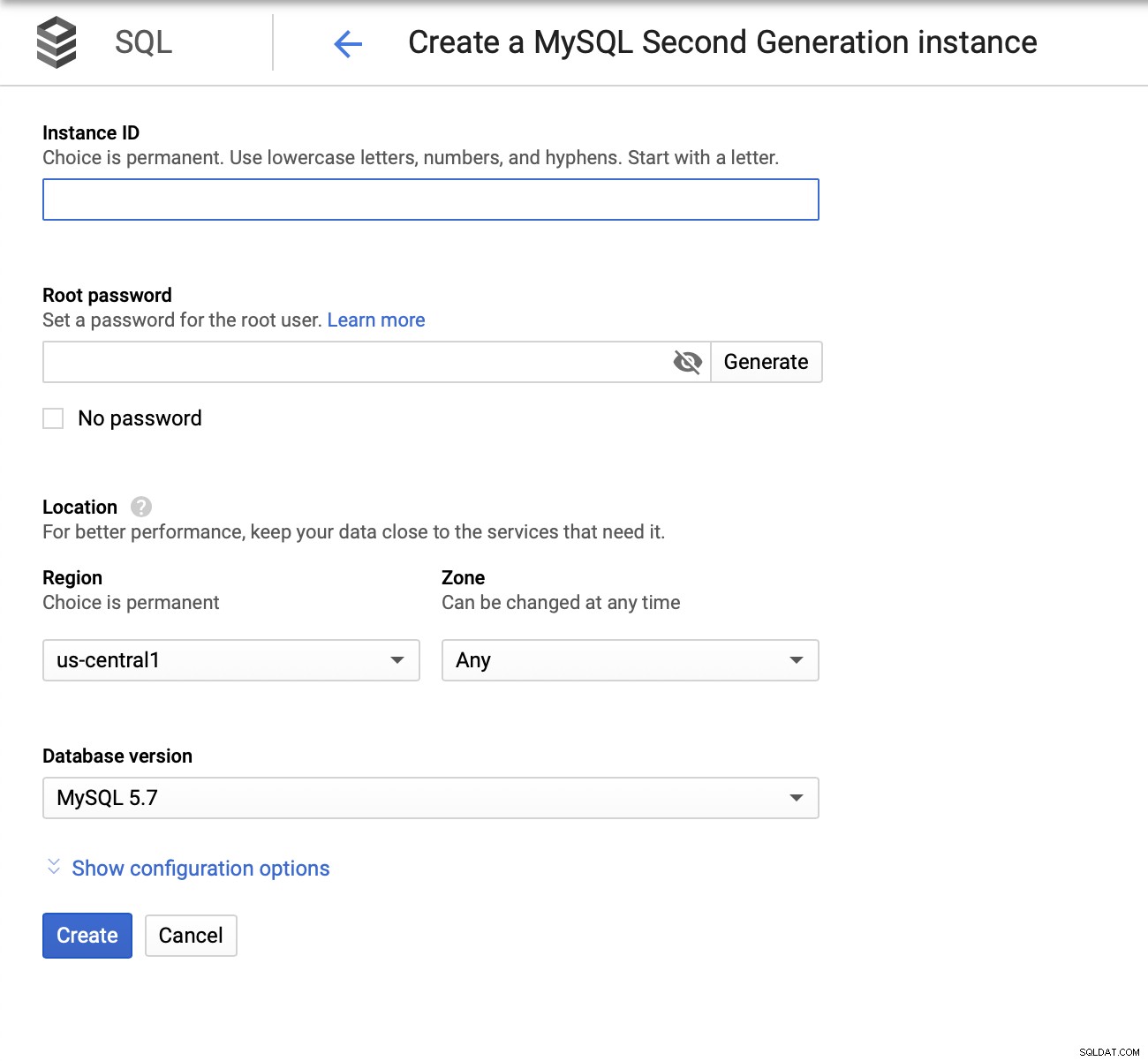
След това ще разгледаме опциите за конфигурация:
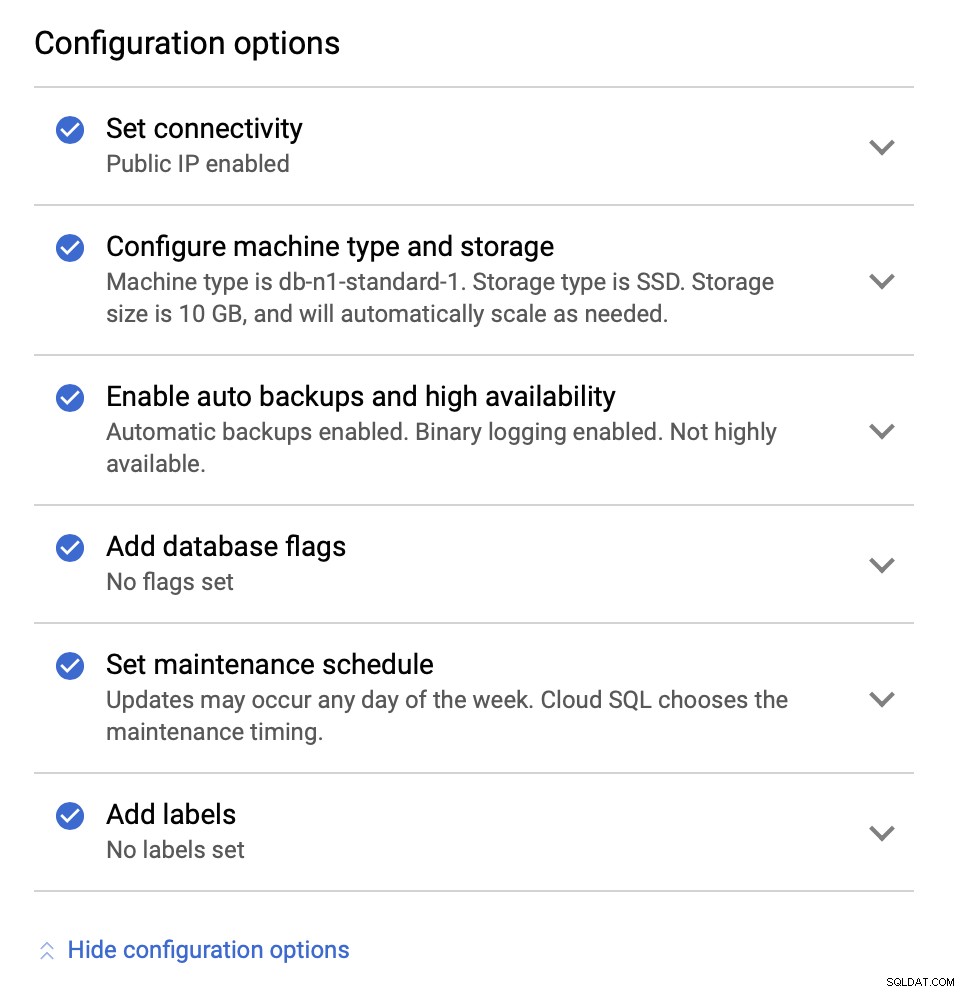
Можем да правим промени по отношение на размера на инстанцията (ще продължим с db-n1-standard-4), съхранение и график за поддръжка. Това, което е най-важно за нас в тази настройка, са опциите за висока наличност:
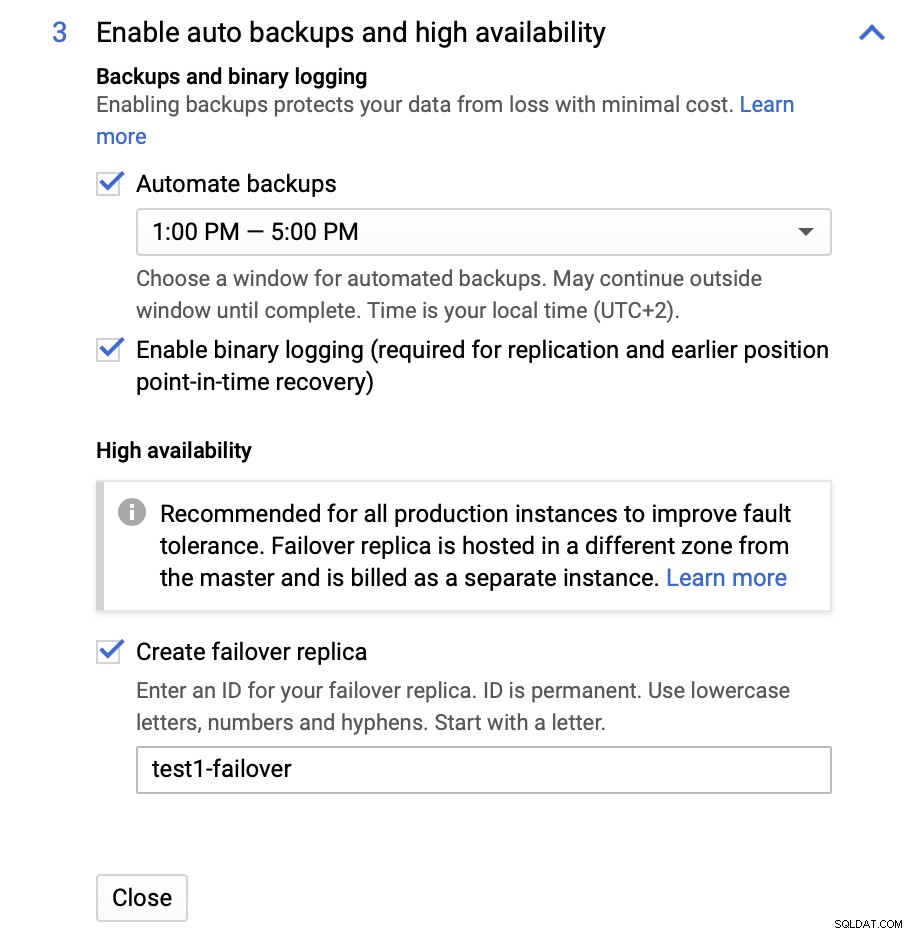
Тук можем да изберем да създадем реплика за отказване. Тази реплика ще бъде повишена до главен, ако оригиналният главен файл не успее.

След като разгърнем настройката, нека добавим подчинен за репликация:
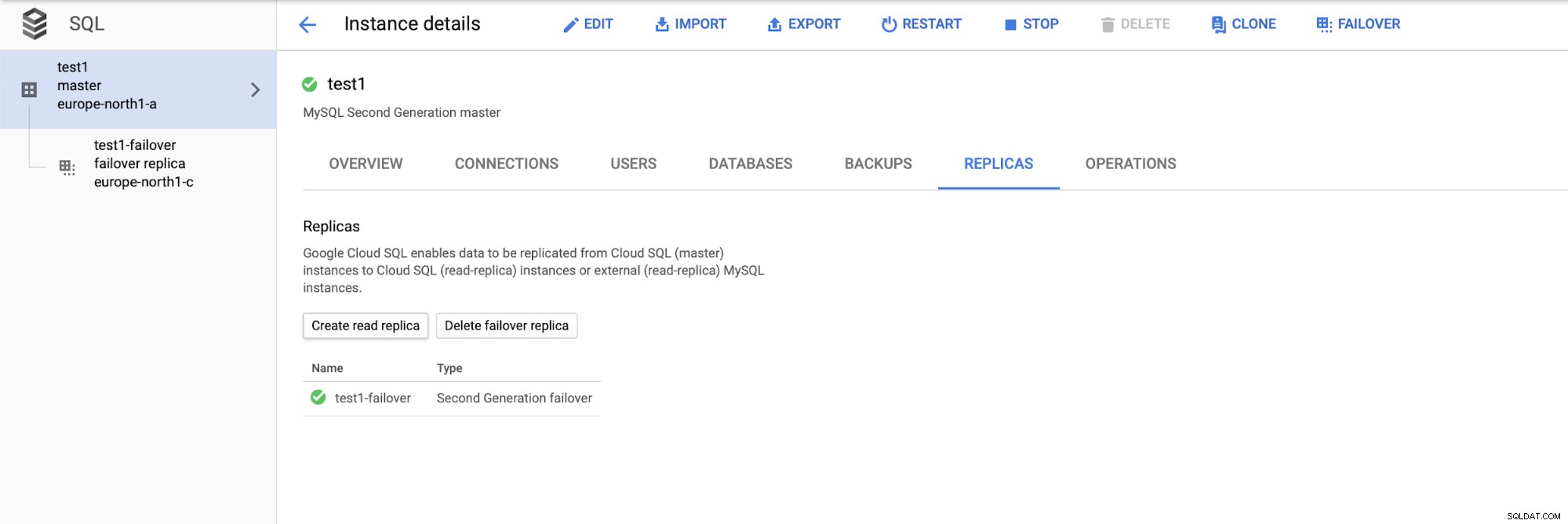
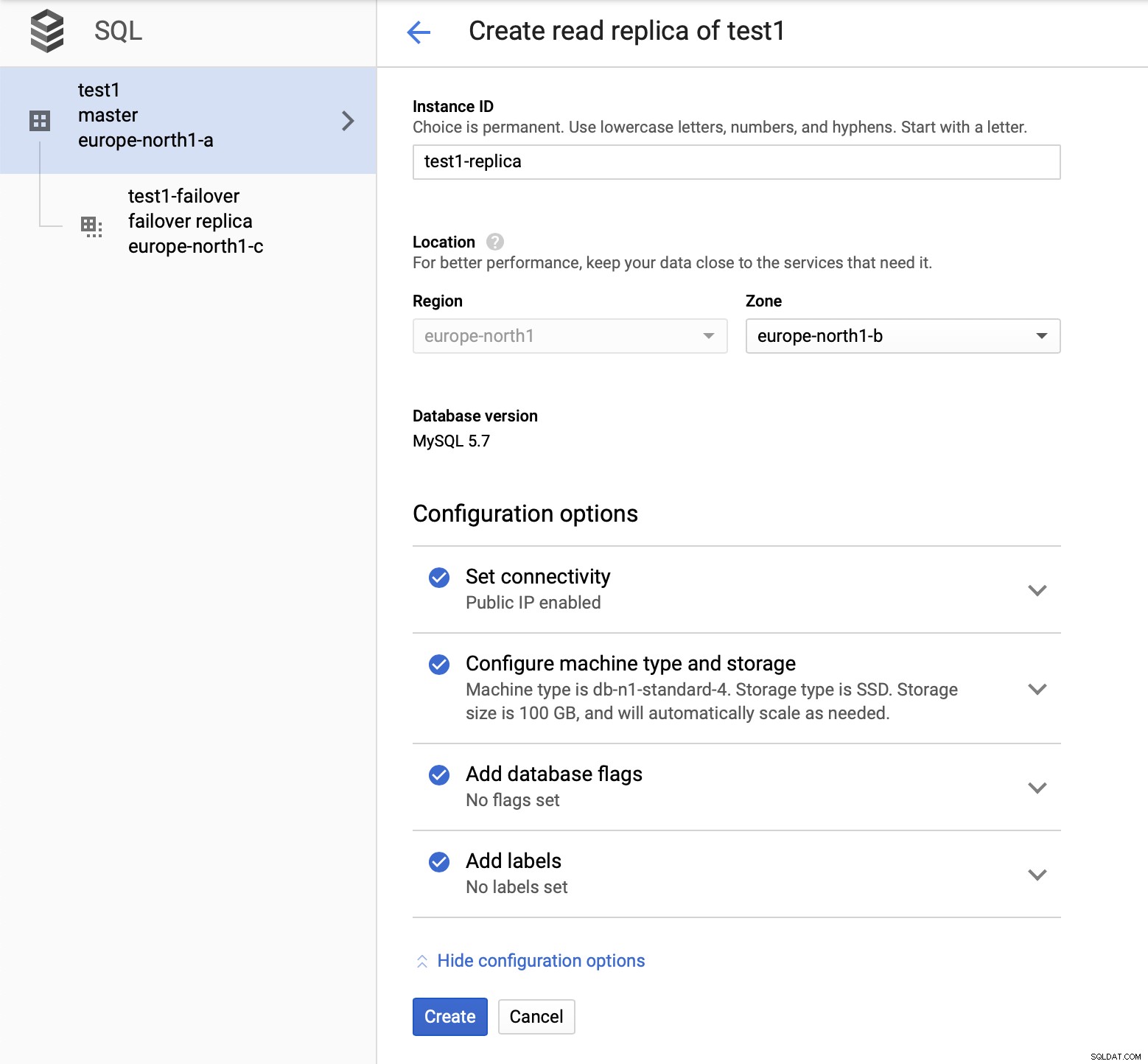
След като процесът на добавяне на репликата приключи, ние сме готови за някои тестове. Ще стартираме тестово работно натоварване, използвайки Sysbench на нашия главен, реплика за преодоляване на срив и реплика за четене, за да видим как ще се получи това. Ще стартираме три екземпляра на Sysbench, като използваме крайните точки и за трите типа възли.
След това ще задействаме ръчното преминаване при отказ чрез потребителския интерфейс:
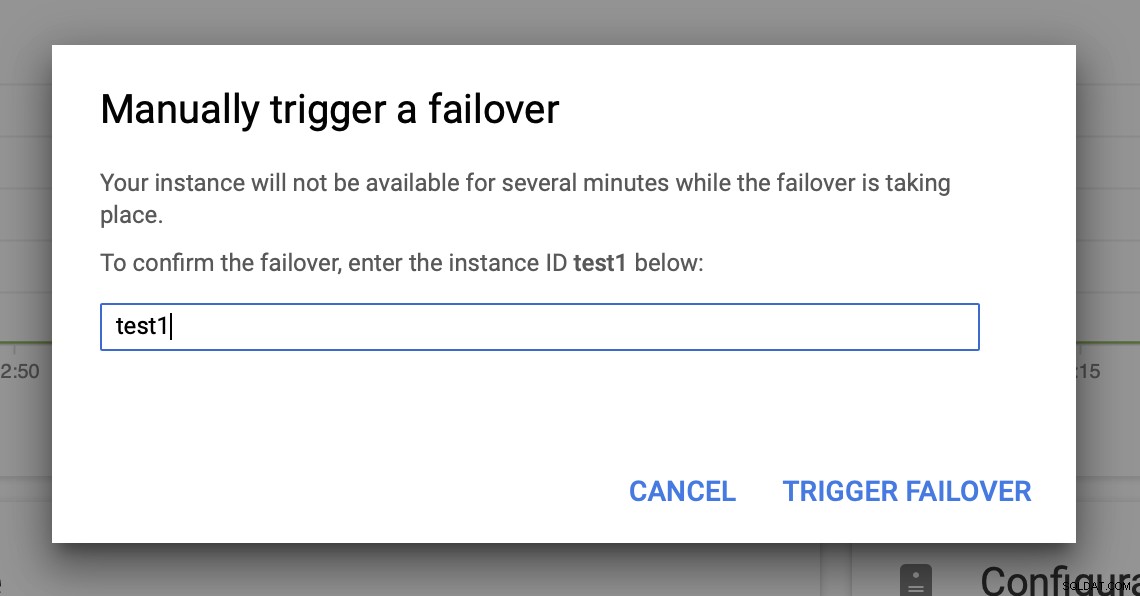
Тестване на отказ от MySQL на Google Cloud Platform?
Стигнах до този момент без никакви подробни познания за това как работят SQL възлите в GCP. Имах обаче някои очаквания въз основа на предишен опит с MySQL и това, което видях при другите доставчици на облак. Като начало, преминаването към възела за отказ трябва да бъде много бързо. Това, което бихме искали, е да запазим наличните подчинени устройства за репликация, без да е необходимо повторно изграждане. Бихме искали също така да видим колко бързо можем да изпълним превключването при отказ втори път (тъй като не е необичайно проблемът да се разпространява от една база данни в друга).
Това, което установихме по време на нашите тестове...
- Докато се провали, главният елемент стана достъпен отново след 75 – 80 секунди.
- Репликата при отказ не беше налична в продължение на 5-6 минути.
- Репликата за четене беше налична по време на процеса на отказ, но стана недостъпна за 55 - 60 секунди след като репликата за преодоляване на отказ стана налична
За какво не сме сигурни...
Какво се случва, когато репликата за преодоляване на отказ не е налична? Въз основа на времето изглежда, че репликата за преодоляване на отказ се възстановява. Това има смисъл, но тогава времето за възстановяване би било силно свързано с размера на екземпляра (особено I/O производителността) и размера на файла с данни.
Какво се случва с репликата за четене, след като репликата за преодоляване на отказ е била възстановена? Първоначално прочетената реплика беше свързана с главния. Когато главният се провали, бихме очаквали репликата за четене да предостави остарял изглед на набора от данни. След като се появи новият главен, той трябва да се свърже отново чрез репликация към екземпляра (който преди е бил реплика за преодоляване на срив и който е бил повишен до главен). Няма нужда от минута престой, когато се изпълнява CHANGE MASTER.
По-важното е, че по време на процеса на отказ няма начин да се изпълни друго превключване (което има смисъл):
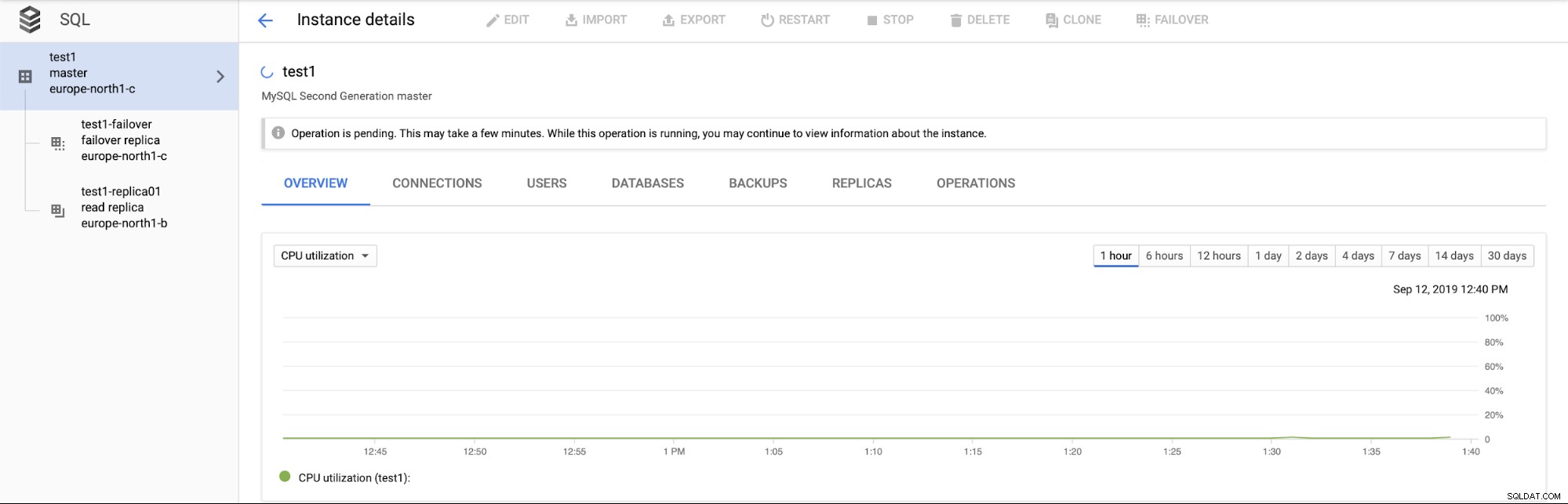
Също така не е възможно да се популяризира реплика за четене (което не е задължително да има смисъл - очакваме да можем да популяризираме реплики за четене по всяко време).

Важно е да се отбележи, че разчитането на прочетените реплики осигурява висока наличност (без създаване на реплика при отказ) не е жизнеспособно решение. Можете да популяризирате реплика за четене, за да станете главен, но ще бъде създаден нов клъстер; отделен от останалите възли.
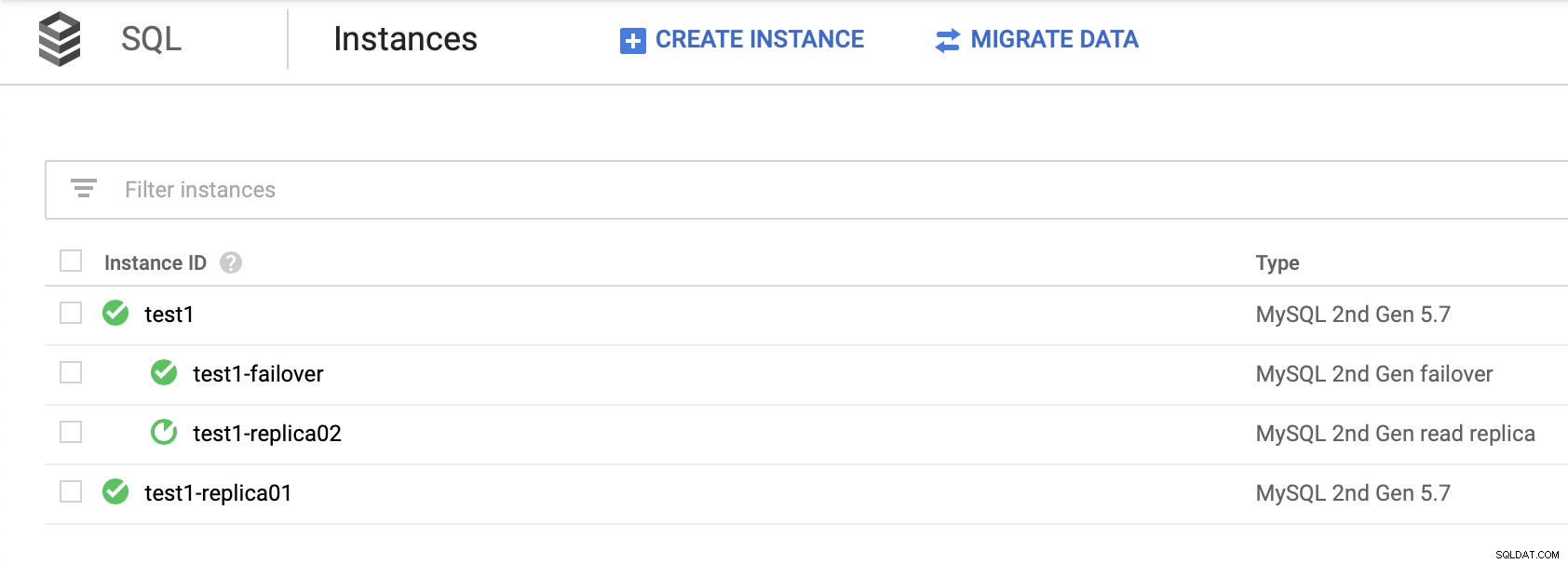
Няма начин да подчините другите си реплики от новия клъстер. Единственият начин да направите това е да създадете нови реплики, но това е отнемащ време процес. Освен това е практически неизползваем, което прави репликата за преодоляване на отказ да бъде единствената реална опция за висока наличност за SQL възли в Google Cloud Platform.
Заключение
Въпреки че е възможно да се създаде високодостъпна среда за SQL възли в GCP, главният няма да бъде достъпен за около минута и половина. Целият процес (включително възстановяването на репликата за преодоляване на отказ и някои действия върху прочетените реплики) отне няколко минути. През това време не успяхме да задействаме допълнителен отказ, нито успяхме да популяризираме реплика за четене.
Имаме ли потребители на GCP? Как постигате висока наличност?