Репликацията е един от най-често срещаните начини за постигане на висока наличност за MySQL и MariaDB. Той стана много по-стабилен с добавянето на GTID и е щателно тестван от хиляди и хиляди потребители. MySQL репликацията обаче не е свойство „настрой и забрави“, трябва да се наблюдава за потенциални проблеми и да се поддържа, за да остане в добра форма. В тази публикация в блога бихме искали да споделим някои съвети и трикове как да поддържате, отстранявате и коригирате проблеми с MySQL репликацията.
Как да определим дали MySQL репликацията е в добра форма?
Това е най-важното умение, което трябва да притежава всеки, който се грижи за настройката за репликация на MySQL. Нека да разгледаме къде да търсим информация за състоянието на репликация. Има малка разлика между MySQL и MariaDB и ще обсъдим и това.
ПОКАЗВАНЕ НА СТАТУС НА ПОДЧИСТВАНЕ
Това е най-разпространеният метод за проверка на състоянието на репликация на подчинен хост – той е с нас от винаги и обикновено е първото място, където отиваме, ако очакваме, че има някакъв проблем с репликацията.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Някои подробности може да се различават между MySQL и MariaDB, но по-голямата част от съдържанието ще изглежда еднакво. Промените ще бъдат видими в секцията GTID, тъй като MySQL и MariaDB го правят по различен начин. От SHOW SLAVE STATUS можете да извлечете някои части от информация - кой главен се използва, кой потребител и кой порт се използва за свързване към главната. Имаме някои данни за текущата позиция на двоичен журнал (вече не е толкова важна, тъй като можем да използваме GTID и да забравим за binlogs) и състоянието на SQL и I/O нишки за репликация. След това можете да видите дали и как е конфигурирано филтрирането. Можете също да намерите информация за грешки, забавяне на репликацията, SSL настройки и GTID. Примерът по-горе идва от MySQL 5.7 slave, който е в здраво състояние. Нека да разгледаме пример, при който репликацията е нарушена.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Тази извадка е взета от MariaDB 10.1, можете да видите промените в долната част на изхода, за да го накарате да работи с MariaDB GTID. Това, което е важно за нас, е грешката - можете да видите, че нещо не е наред в SQL нишката:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Ще обсъдим този конкретен проблем по-късно, засега е достатъчно, че ще видите как можете да проверите дали има грешки в репликацията, като използвате ПОКАЗВАНЕ НА СТАТУС НА СЛАВ.
Друга важна информация, която идва от SHOW SLAVE STATUS е - колко силно изостава нашия slave. Можете да го проверите в колоната „Seconds_Behind_Master“. Този показател е особено важен за проследяване, ако знаете, че приложението ви е чувствително, когато става въпрос за остарели четения.
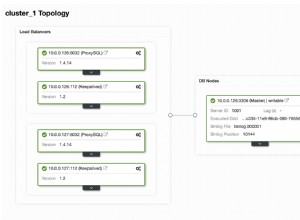
В ClusterControl можете да проследявате тези данни в секцията „Общ преглед“:
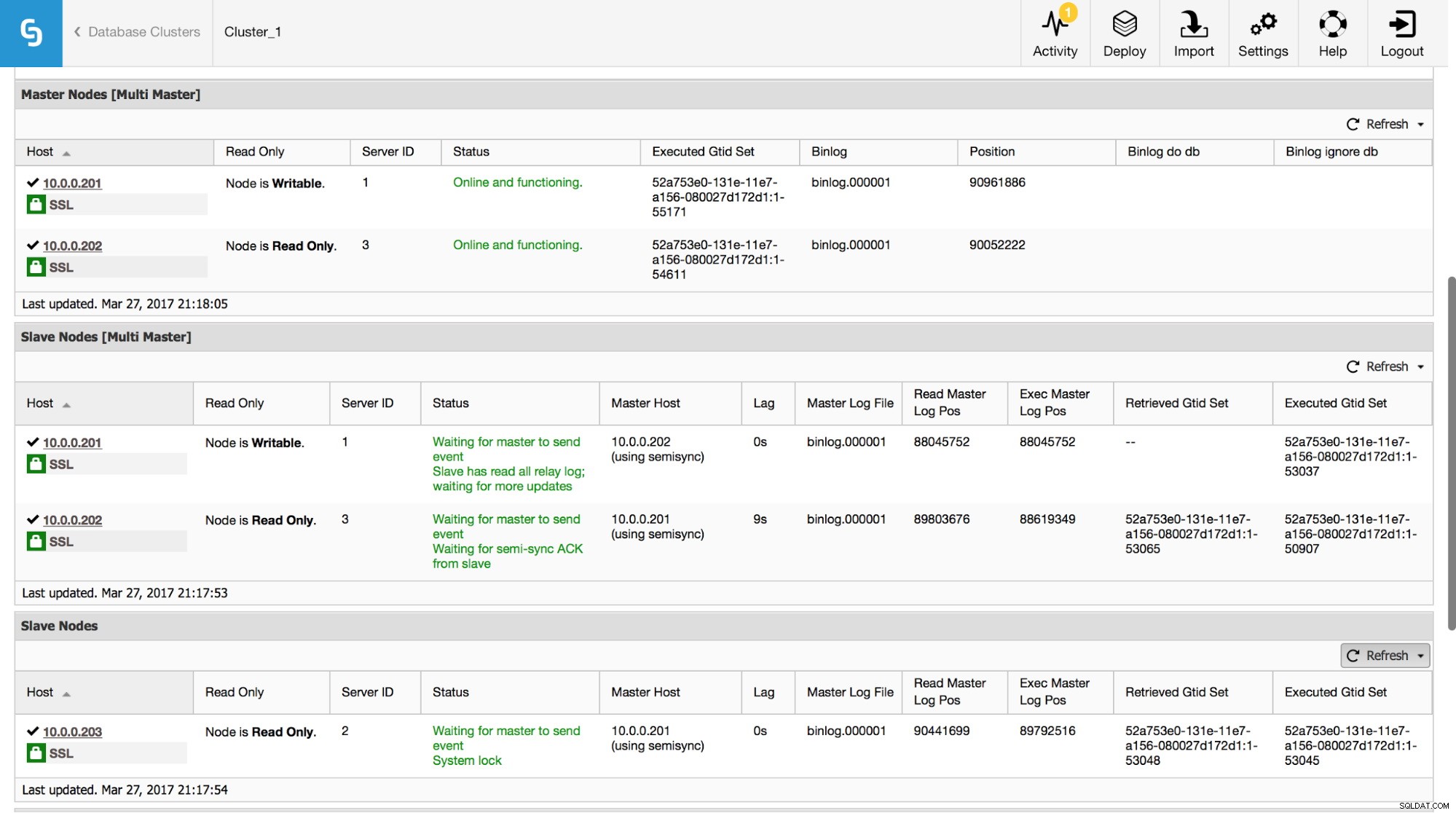
Направихме видима цялата най-важна информация от командата SHOW SLAVE STATUS. Можете да проверите състоянието на репликацията, кой е главен, дали има забавяне на репликацията или не, позициите на двоичен журнал. Можете също да намерите извлечени и изпълнени GTID.
Схема за изпълнение
Друго място, където можете да търсите информация за репликацията, е performance_schema. Това се отнася само за MySQL 5.7 на Oracle – по-стари версии и MariaDB не събира тези данни.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)По-долу можете да намерите някои примери за налични данни в някои от тези таблици.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Както можете да видите, можем да проверим състоянието на репликацията, последната грешка, получения набор от транзакции и някои други данни. Какво е важно – ако сте активирали многонишкова репликация, в таблицата replication_applier_status_by_worker ще видите състоянието на всеки един работник – това ви помага да разберете състоянието на репликация за всяка от работните нишки.
Закъснение при репликация
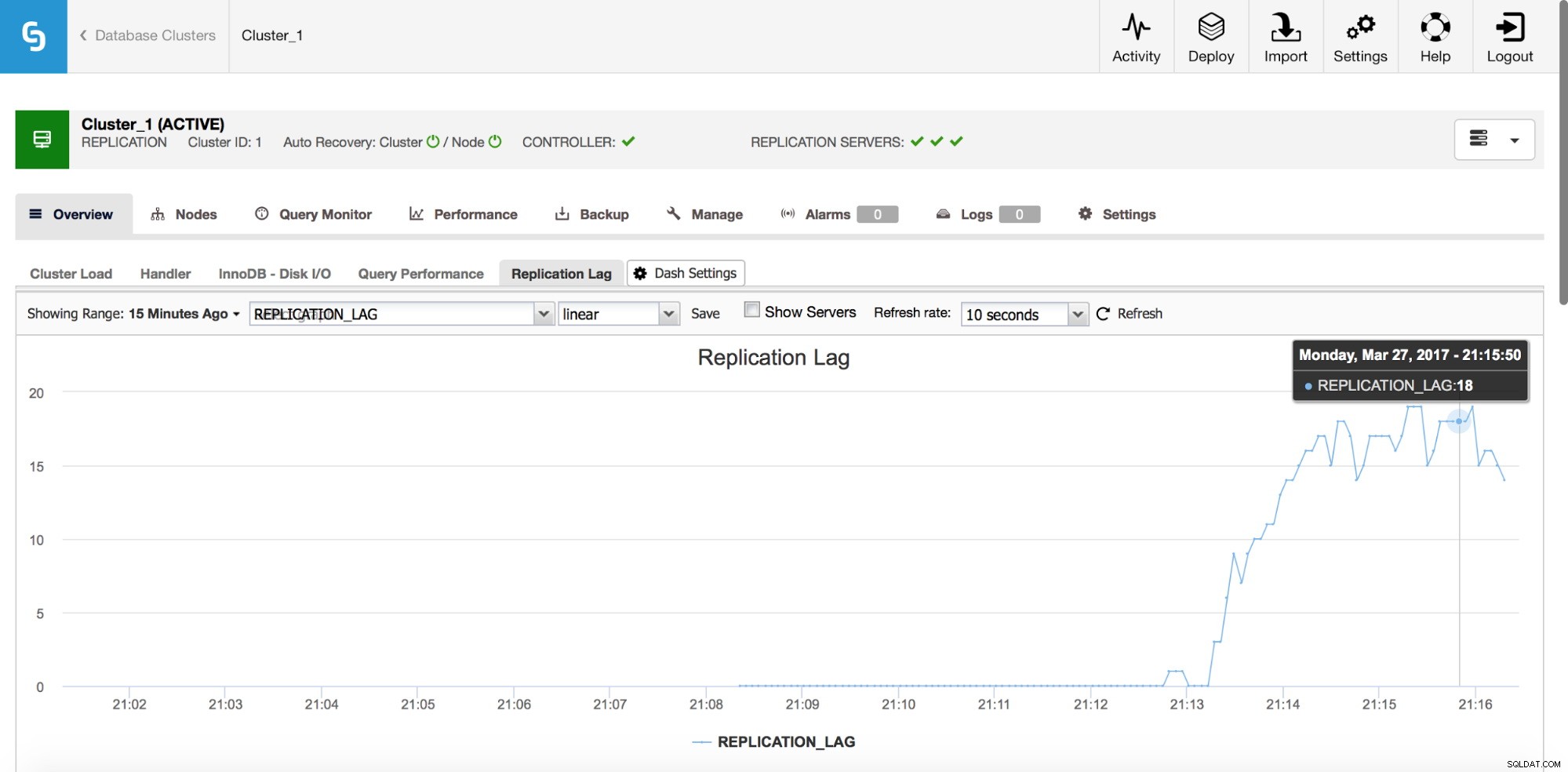
Закъснението определено е един от най-често срещаните проблеми, с които ще се сблъскате, когато работите с MySQL репликация. Закъснението при репликация се появява, когато един от подчинените не е в състояние да се справи с количеството операции на запис, извършени от главния. Причините могат да бъдат различни - различна хардуерна конфигурация, по-голямо натоварване на подчинения, висока степен на паралелизиране на запис на главния, който трябва да бъде сериализиран (когато използвате единична нишка за репликация) или записите не могат да бъдат паралелизирани в същата степен, както е е бил на главния (когато използвате многонишкова репликация).
Как да го открием?
Има няколко метода за откриване на забавянето на репликацията. На първо място, можете да отметнете “Seconds_Behind_Master” в изхода SHOW SLAVE STATUS - той ще ви каже дали ведомото устройство изостава или не. Работи добре в повечето случаи, но в по-сложни топологии, когато използвате междинни главни, на хостове някъде ниско във веригата на репликация, може да не е точно. Друго, по-добро решение е да разчитате на външни инструменти като pt-heartbeat. Идеята е проста - таблица се създава с, наред с другото, колона с времеви печат. Тази колона се актуализира на главната на редовни интервали. След това на подчинено устройство можете да сравните клеймото за дата от тази колона с текущото време – то ще ви каже колко далеч е подчинено.
Независимо от начина, по който изчислявате изоставането, уверете се, че вашите хостове са синхронизирани по време. Използвайте ntpd или друго средство за синхронизиране на времето – ако има отклонение във времето, ще видите „фалшиво“ забавяне на вашите подчинени устройства.
Как да намалим забавянето?
Това не е лесен въпрос за отговор. Накратко, зависи от това какво причинява изоставането и какво се е превърнало в пречка. Има два типични модела - slave е I/O bound, което означава, че неговата I/O подсистема не може да се справи с количеството операции за запис и четене. Второ – подчинената е свързана с процесора, което означава, че нишката за репликация използва целия процесор, който може (една нишка може да използва само едно ядро на процесора) и все още не е достатъчна за обработка на всички операции по запис.
Когато процесорът е тясно място, решението може да бъде толкова просто, колкото да се използва многонишкова репликация. Увеличете броя на работните нишки, за да позволите по-висока паралелизация. Не винаги е възможно обаче - в такъв случай може да искате да поиграете малко с променливи за групови commit (както за MySQL, така и за MariaDB), за да забавите ангажиментите за лек период от време (тук говорим за милисекунди) и по този начин , увеличаване на паралелизирането на комитациите.
Ако проблемът е в I/O, проблемът е малко по-труден за решаване. Разбира се, трябва да прегледате вашите InnoDB I/O настройки - може би има място за подобрения. Ако настройката на my.cnf не помогне, нямате твърде много опции – подобрете заявките си (където е възможно) или надстройте своята I/O подсистема до нещо по-способно.
Повечето от прокси сървърите (например всички прокси сървъри, които могат да бъдат разгърнати от ClusterControl:ProxySQL, HAProxy и MaxScale) ви дават възможност да премахнете подчинен от ротация, ако забавянето на репликацията премине някакъв предварително дефиниран праг. Това в никакъв случай не е метод за намаляване на изоставането, но може да бъде полезно да се избегнат остарели четения и като страничен ефект да се намали натоварването на подчинено устройство, което би трябвало да му помогне да навакса изоставането.
Разбира се, настройката на заявката може да бъде решение и в двата случая – винаги е добре да подобрите заявки, които са натоварени с процесора или I/O.
Грешни транзакции
Неправилните транзакции са транзакции, които са били изпълнени само на подчинен, а не на главен. Накратко, те правят роб несъвместим с господаря. Когато използвате репликация, базирана на GTID, това може да доведе до сериозни проблеми, ако подчинението бъде повишено до главен. Имаме задълбочена публикация по тази тема и ви насърчаваме да я разгледате и да се запознаете с това как да откривате и коригирате проблеми с грешни транзакции. Там също така включихме информация как ClusterControl открива и обработва грешни транзакции.
Няма Binlog файл на главния
Как да идентифицирам проблема?
При някои обстоятелства може да се случи подчинен да се свърже с главен и да поиска несъществуващ двоичен регистрационен файл. Една от причините за това може да бъде грешната транзакция - в даден момент от време транзакция е била изпълнена на подчинен и по-късно този подчинен става главен. Други хостове, които са конфигурирани да подчиняват този главен, ще поискат тази липсваща транзакция. Ако е било изпълнено преди много време, има вероятност двоичните регистрационни файлове вече да са изчистени.
Друг, по-типичен пример - искате да осигурите подчинен с помощта на xtrabackup. Копирате архива на хост, прилагате дневника, сменяте собственика на MySQL директорията с данни - типични операции, които правите за възстановяване на архив. Вие изпълнявате
SET GLOBAL gtid_purged=въз основа на данните от xtrabackup_binlog_info и стартирате CHANGE MASTER TO ... MASTER_AUTO_POSITION=1 (това е в MySQL, MariaDB има малко по-различен процес), стартирайте подчинения и след това получавате грешка като:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'в MySQL или:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'в MariaDB.
Това основно означава, че главният няма всички двоични регистрационни файлове, необходими за изпълнение на всички липсващи транзакции. Най-вероятно резервното копие е твърде старо и главният вече е изчистил някои от двоичните регистрационни файлове, създадени между времето, когато е създадено резервното копие, и когато подчиненото е предоставено.
Как да реша този проблем?
За съжаление, не можете да направите много в този конкретен случай. Ако имате някои MySQL хостове, които съхраняват двоични регистрационни файлове за по-дълго време от главния, можете да опитате да използвате тези регистрационни файлове, за да възпроизведете липсващи транзакции на подчинения. Нека да разгледаме как може да се направи.
Първо, нека да разгледаме най-стария GTID в двоичните регистрационни файлове на главния:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)И така, „binlog.000021“ е най-новият (и единствен) файл. Нека проверим кой е първият запис на GTID в този файл:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Както виждаме, най-старият двоичен запис в дневника, който е наличен, е:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Трябва също да проверим кой е последният GTID, покрит в архива:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Това е:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666, така че ни липсват две събития:
5d1e2227-07c6-11e7-8123-080027495a667
Нека видим дали можем да намерим тези транзакции на друго подчинено устройство.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Изглежда, че „binlog.000003“ е най-новият двоичен журнал. Трябва да проверим дали липсващите ни GTID могат да бъдат намерени в него:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Моля, имайте предвид, че може да искате да копирате binlog файлове извън производствения сървър, тъй като обработката им може да увеличи натоварването. Тъй като потвърдихме, че тези GTID съществуват, можем да ги извлечем:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlСлед бърз scp, можем да приложим тези събития към подчинения
slave1:~# mysql -ppass < to_apply_on_slave1.sqlСлед като приключим, можем да проверим дали тези GTID са били приложени, като погледнем в изхода на ПОКАЗВАНЕ НА СТАТУС НА РАБОТА:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set изглежда добре, затова можем да стартираме подчинени нишки:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Нека проверим дали работи добре. Отново ще използваме изхода SHOW SLAVE STATUS:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Изглежда добре, работи и работи!
Друг метод за решаване на този проблем ще бъде да направите резервно копие още веднъж и да осигурите отново подчинения, като използвате нови данни. Това доста вероятно ще бъде по-бързо и определено по-надеждно. Не се случва често да имате различни политики за изчистване на binlog на главния и на подчинените)
Ще продължим да обсъждаме други видове проблеми с репликацията в следващата публикация в блога.