В предишната публикация обсъдихме как да проверим дали MySQL репликацията е в добра форма. Разгледахме и някои от типичните проблеми. В тази публикация ще разгледаме още някои проблеми, които може да видите, когато се занимавате с MySQL репликация.
Липсващи или дублирани записи
Това е нещо, което не трябва да се случва, но се случва много често - ситуация, в която SQL инструкция, изпълнена на главния, е успешна, но същата инструкция, изпълнена на един от подчинените, се проваля. Основната причина е отклонението на подчинения - нещо (обикновено грешни транзакции, но също и други проблеми или грешки в репликацията) кара подчинения да се различава от своя господар. Например, ред, който е съществувал на главния, не съществува на подчинен и не може да бъде изтрит или актуализиран. Колко често се появява този проблем зависи най-вече от настройките ви за репликация. Накратко, има три начина, по които MySQL съхранява двоични регистрационни събития. Първо, „изявление“ означава, че SQL е написан в обикновен текст, точно както е бил изпълнен на главен. Тази настройка има най-висок толеранс при отклонение на подчинените, но също така е и тази, която не може да гарантира последователност на подчинените – трудно е да се препоръча да се използва в производството. Вторият формат, "ред", съхранява резултата от заявката вместо израза на заявката. Например събитие може да изглежда така:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Това означава, че актуализираме ред в таблицата 'tab' в схемата 'test', където първата колона има стойност 2, а втората колона има стойност 5. Задаваме първата колона на 2 (стойността не се променя), а втората колона до 4. Както виждате, няма много място за интерпретация - точно е дефинирано кой ред се използва и как се променя. В резултат на това този формат е чудесен за подчинена последователност, но, както можете да си представите, е много уязвим, когато става въпрос за отклоняване на данни. Все пак това е препоръчителният начин за изпълнение на MySQL репликация.
И накрая, третото, „смесено“, работи по начин, че онези събития, които са безопасни за запис под формата на изявления, използват формат „изявление“. Тези, които биха могли да причинят отклонение на данните, ще използват формат „ред“.
Как ги откривате?
Както обикновено, ПОКАЖЕТЕ СТАТУС НА ДОБРЕНО ще ни помогне да идентифицираме проблема.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Както можете да видите, грешките са ясни и разбираеми (и по същество са идентични между MySQL и MariaDB.
Как решавате проблема?
Това, за съжаление, е сложната част. На първо място, трябва да идентифицирате източника на истината. Кой хост съдържа правилните данни? Господар или роб? Обикновено предполагате, че е главен, но не го приемайте по подразбиране - проучете! Възможно е след преодоляване на срива част от приложението все още да издава записи към стария главен, който сега действа като подчинен. Възможно е read_only да не е зададен правилно на този хост или може би приложението използва суперпотребител за свързване с база данни (да, виждахме това в производствени среди). В такъв случай робът може да бъде източник на истина - поне до известна степен.
В зависимост от това кои данни трябва да останат и кои да отидат, най-добрият начин на действие би бил да се идентифицира какво е необходимо, за да се върне репликацията в синхрон. На първо място, репликацията е нарушена, така че трябва да се погрижите за това. Влезте в главния и проверете двоичния дневник, дори който е причинил прекъсване на репликацията.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Както можете да видите, ние пропускаме едно събитие:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Нека го проверим в двоичните регистрационни файлове на главната:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Виждаме, че това е вмъкване, което задава първата колона на 3, а втората на 7. Нека проверим как изглежда нашата таблица сега:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Сега имаме две възможности, в зависимост от това кои данни трябва да преобладават. Ако правилните данни са на главния, можем просто да изтрием ред с id=3 на подчинения. Просто се уверете, че сте деактивирали двоичното регистриране, за да избегнете въвеждането на грешни транзакции. От друга страна, ако решим, че правилните данни са на подчинения, трябва да изпълним команда REPLACE на главния, за да зададем ред с id=3 да коригира съдържанието на (3, 10) от текущото (3, 7). При подчинения обаче ще трябва да пропуснем текущия GTID (или, за да бъдем по-точни, ще трябва да създадем празно GTID събитие), за да можем да рестартираме репликацията.
Изтриването на ред на подчинен е просто:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Вмъкването на празен GTID е почти толкова просто:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Друг метод за решаване на този конкретен проблем (стига да приемем господаря като източник на истина) е да се използват инструменти като pt-table-checksum и pt-table-sync, за да се идентифицира къде подчинения не е съгласуван със своя господар и какво SQL трябва да се изпълни на главния, за да върне подчинения обратно в синхрон. За съжаление, този метод е по-скоро тежък - много натоварване се добавя към master и куп заявки се записват в потока за репликация, което може да повлияе на забавянето на подчинените и общата производителност на настройката за репликация. Това е особено вярно, ако има значителен брой редове, които трябва да бъдат синхронизирани.
И накрая, както винаги, можете да изградите отново своя подчинен, като използвате данни от главния – по този начин можете да сте сигурни, че подчинения ще бъде обновен с най-пресните и актуални данни. Това всъщност не е непременно лоша идея - когато говорим за голям брой редове за синхронизиране с помощта на pt-table-checksum/pt-table-sync, това идва със значителни излишни разходи в производителността на репликация, цялостния процесор и I/O необходимо натоварване и човекочасове.
ClusterControl ви позволява да възстановите подчинен, като използвате ново копие на основните данни.
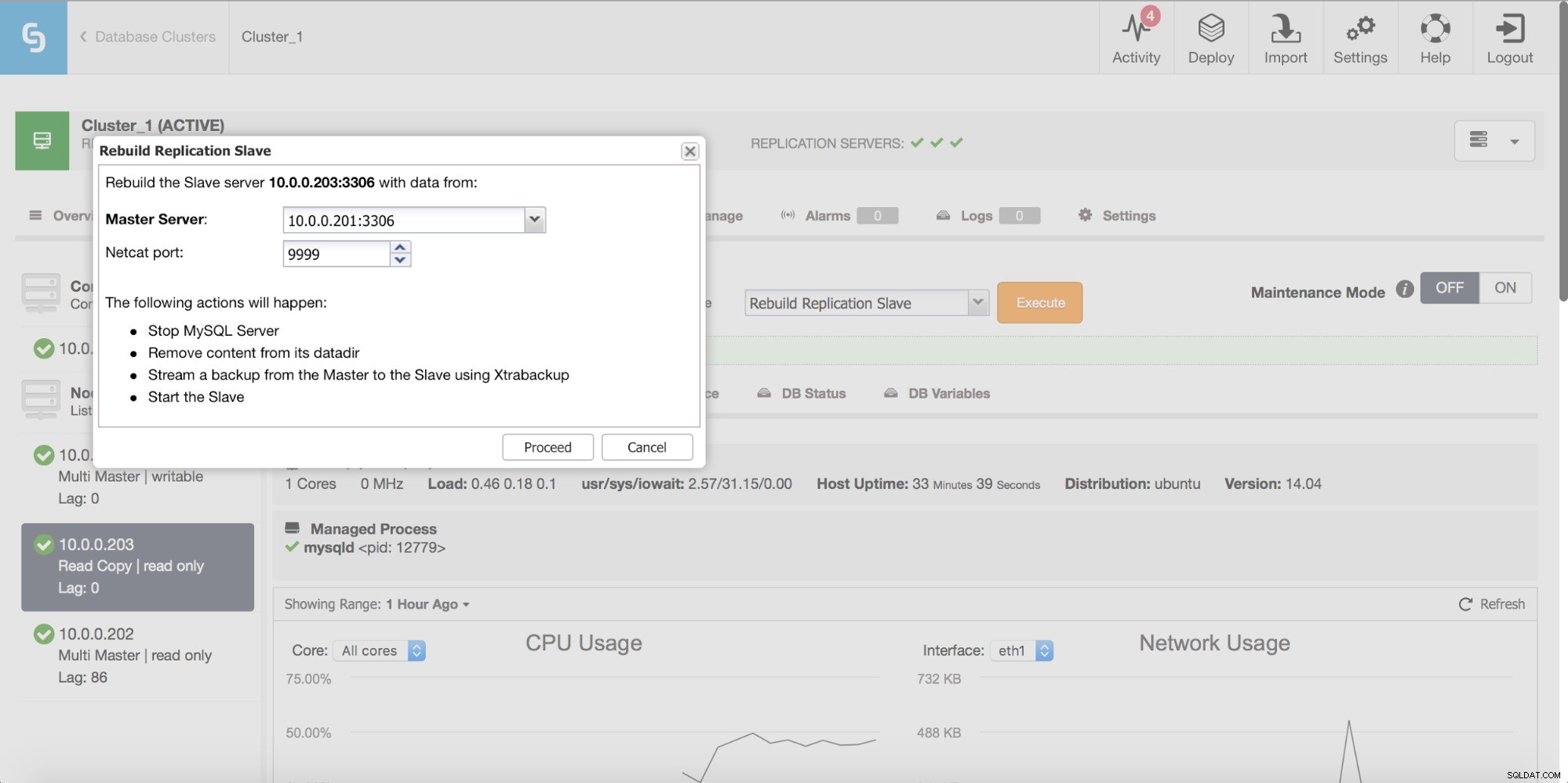
Проверки за последователност
Както споменахме в предишната глава, последователността може да се превърне в сериозен проблем и да причини много главоболия за потребителите, изпълняващи настройки за репликация на MySQL. Нека видим как можете да проверите дали вашите MySQL подчинени устройства са в синхрон с главния и какво можете да направите по въпроса.
Как да открием непоследователно подчинено устройство
За съжаление, типичният начин потребителят да разбере, че робът е непоследователен, е като се сблъска с един от проблемите, които споменахме в предишната глава. За да се избегне това, е необходимо проактивно наблюдение на подчинената консистенция. Нека проверим как може да се направи.
Ще използваме инструмент от Percona Toolkit:pt-table-checksum. Той е проектиран да сканира клъстер за репликация и да идентифицира всякакви несъответствия.
Изградихме персонализиран сценарий с помощта на sysbench и въведохме малко несъответствие в един от подчинените. Какво е важно (ако искате да го тествате, както направихме ние), трябва да приложите корекция по-долу, за да принудите pt-table-checksum да разпознава схемата „sbtest“ като несистемна схема:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Първо ще изпълним pt-table-checksum по следния начин:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Няколко важни бележки за начина, по който извикахме инструмента. На първо място потребителят, който задаваме, трябва да съществува на всички подчинени устройства. Ако искате, можете също да използвате „--slave-user“, за да дефинирате друг, по-малко привилегирован потребител за достъп до подчинени устройства. Друго нещо, което си струва да се обясни - ние използваме базирана на ред репликация, която не е напълно съвместима с pt-table-checksum. Ако имате репликация, базирана на ред, това, което се случва, е pt-table-checksum ще промени формата на двоичния дневник на ниво сесия на „изявление“, тъй като това е единственият поддържан формат. Проблемът е, че такава промяна ще работи само на първо ниво подчинени устройства, които са директно свързани с главен. Ако имате междинни главни (така че, повече от едно ниво подчинени), използването на pt-table-checksum може да наруши репликацията. Ето защо, по подразбиране, ако инструментът открие базирана на ред репликация, той излиза и отпечатва грешка:
„Реплика slave1 има binlog_format ROW, което може да доведе до прекъсване на репликацията на pt-table-checksum. Моля, прочетете „Реплики, използващи репликация, базирана на редове“ в раздела ОГРАНИЧЕНИЯ на документацията на инструмента. Ако разбирате рисковете, посочете --no-check-binlog-format, за да деактивирате тази проверка.“
Използвахме само едно ниво на подчинени, така че беше безопасно да посочим „--no-check-binlog-format“ и да продължим напред.
Накрая задаваме максималното забавяне на 5 секунди. Ако този праг бъде достигнат, pt-table-checksum ще спре за време, необходимо, за да доведе изоставането под прага.
Както можете да видите от изхода,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2е открито несъответствие в таблица sbtest.sbtest2.
По подразбиране pt-table-checksum съхранява контролните суми в таблицата percona.checksums. Тези данни могат да се използват за друг инструмент от Percona Toolkit, pt-table-sync, за да се идентифицират кои части от таблицата трябва да бъдат проверени в детайли, за да се намери точната разлика в данните.
Как да коригирам непоследователно подчинено устройство
Както бе споменато по-горе, ще използваме pt-table-sync, за да направим това. В нашия случай ще използваме данни, събрани от pt-table-checksum, въпреки че е възможно също да насочим pt-table-sync към два хоста (главен и подчинен) и той ще сравни всички данни на двата хоста. Това определено е по-отнемащ време и ресурси процес, следователно, стига да вече имате данни от pt-table-checksum, е много по-добре да го използвате. Ето как го изпълнихме, за да тестваме изхода:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Както можете да видите, в резултат на това е генериран някакъв SQL. Важно е да се отбележи, че променливата --replicate. Това, което се случва тук, е да насочваме pt-table-sync към таблица, генерирана от pt-table-checksum. Ние също го насочваме към master.
За да проверим дали SQL има смисъл, използвахме опцията --print. Моля, имайте предвид, че генерираният SQL е валиден само в момента, в който е генериран - не можете наистина да го съхранявате някъде, да го прегледате и след това да изпълните. Всичко, което можете да направите, е да проверите дали SQL има някакъв смисъл и веднага след това да изпълните отново инструмента с флага --execute:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeТова трябва да върне подчинения в синхрон с главния. Можем да го проверим с pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Както можете да видите, в таблицата sbtest.sbtest2 вече няма разлики.
Надяваме се, че сте намерили тази публикация в блога информативна и полезна. Щракнете тук, за да научите повече за MySQL репликацията. Ако имате въпроси или предложения, не се колебайте да се свържете с нас чрез коментарите по-долу.