Високата наличност е задължителна в наши дни, тъй като повечето организации не могат да си позволят да загубят данните си. Високата наличност обаче винаги идва с цена (която може да варира много.) Всякакви настройки, които изискват почти незабавни действия, обикновено изискват скъпа среда, която да отразява точно производствената настройка. Но има и други опции, които могат да бъдат по-евтини. Те може да не позволяват незабавно преминаване към клъстер за възстановяване след бедствие, но все пак ще позволят непрекъснатост на бизнеса (и няма да източват бюджета.)
Пример за този тип настройка е DR среда със „студен режим на готовност“. Това ви позволява да намалите разходите си, като същевременно можете да създадете нова среда на външно място, ако бедствието се случи. В тази публикация в блога ще демонстрираме как да създадете такава настройка.
Първоначална настройка
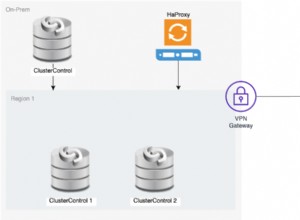
Да предположим, че имаме доста стандартна настройка за главна/подчинена MySQL репликация в нашия собствен център за данни. Той е високодостъпна настройка с ProxySQL и Keepalived за обработка на виртуален IP. Основният риск е, че центърът за данни ще стане недостъпен. Това е малък DC, може би е само един доставчик без BGP. И в тази ситуация ще приемем, че ако връщането на базата данни ще отнеме часове, това е наред, стига да е възможно да се върне обратно.
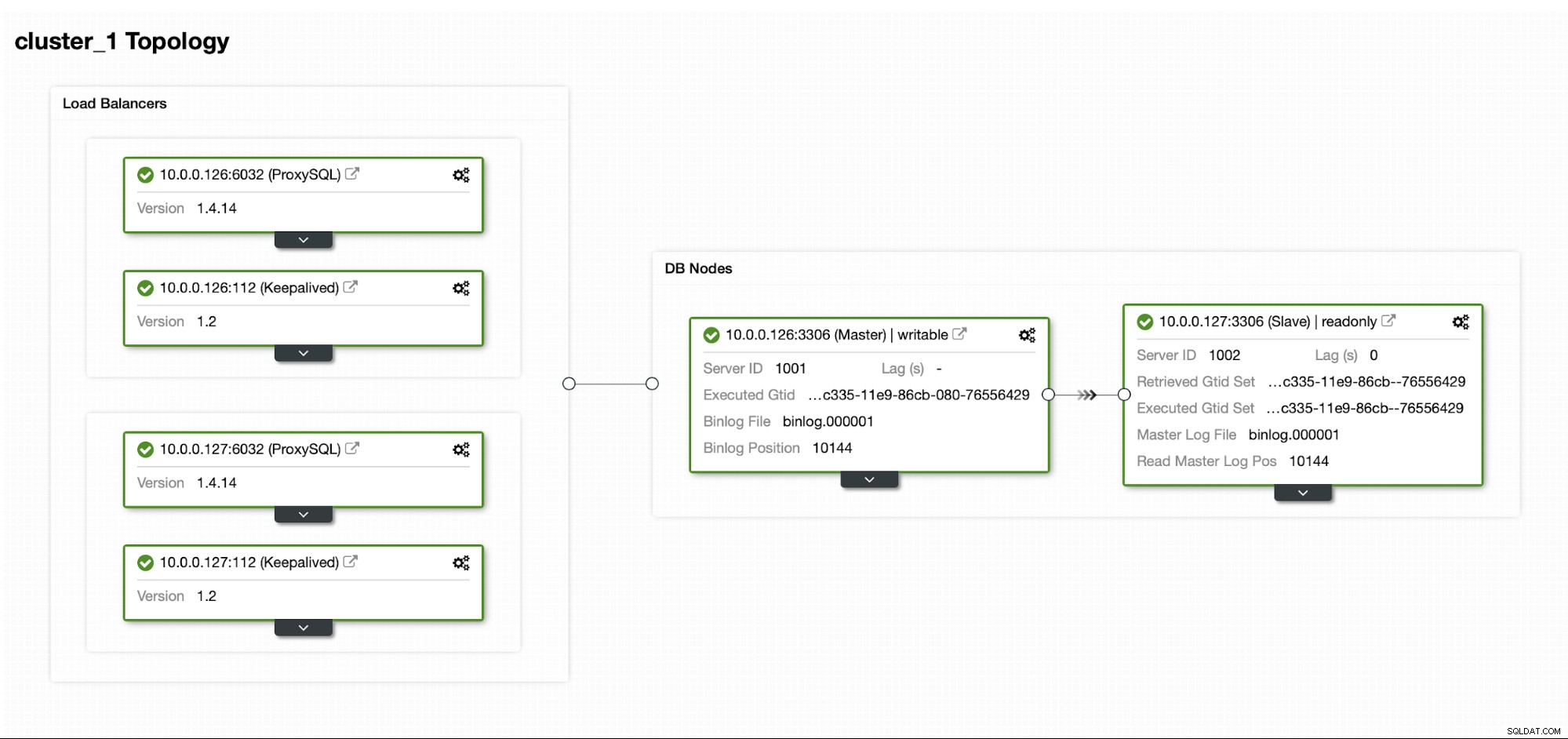
За внедряване на този клъстер използвахме ClusterControl, който можете да изтеглите безплатно. За нашата DR среда ще използваме EC2 (но може да бъде и всеки друг доставчик на облак.)
Предизвикателството
Основният проблем, с който трябва да се справим, е как трябва да гарантираме, че имаме нови данни, за да възстановим нашата база данни в средата за възстановяване при бедствия? Разбира се, в идеалния случай бихме имали роб за репликация и работещ в EC2... но тогава трябва да платим за това. Ако сме ограничени с бюджета, можем да се опитаме да го заобиколим с резервни копия. Това не е идеалното решение, тъй като в най-лошия случай никога няма да можем да възстановим всички данни.
Под „най-лошия сценарий“ имаме предвид ситуация, в която няма да имаме достъп до оригиналните сървъри на база данни. Ако успеем да достигнем до тях, данните нямаше да бъдат загубени.
Решението
Ще използваме ClusterControl, за да настроим график за архивиране, за да намалим вероятността данните да бъдат загубени. Ще използваме и функцията ClusterControl за качване на архиви в облака. Ако центърът за данни няма да бъде наличен, можем да се надяваме, че избраният от нас облачен доставчик ще бъде достъпен.
Настройване на графика за архивиране в ClusterControl
Първо ще трябва да конфигурираме ClusterControl с нашите облачни идентификационни данни.
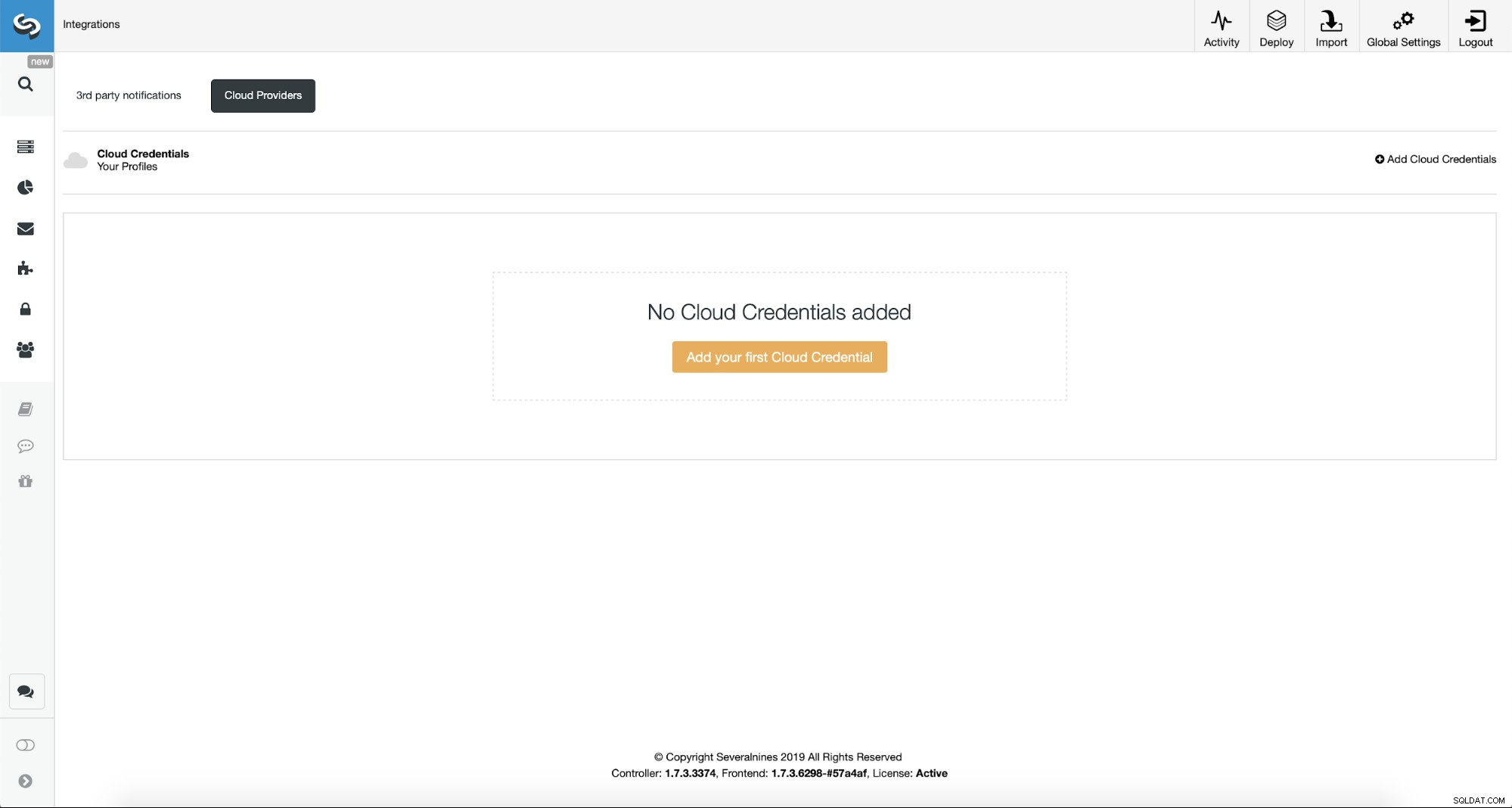
Можем да направим това, като използваме „Интеграции“ от лявото странично меню.
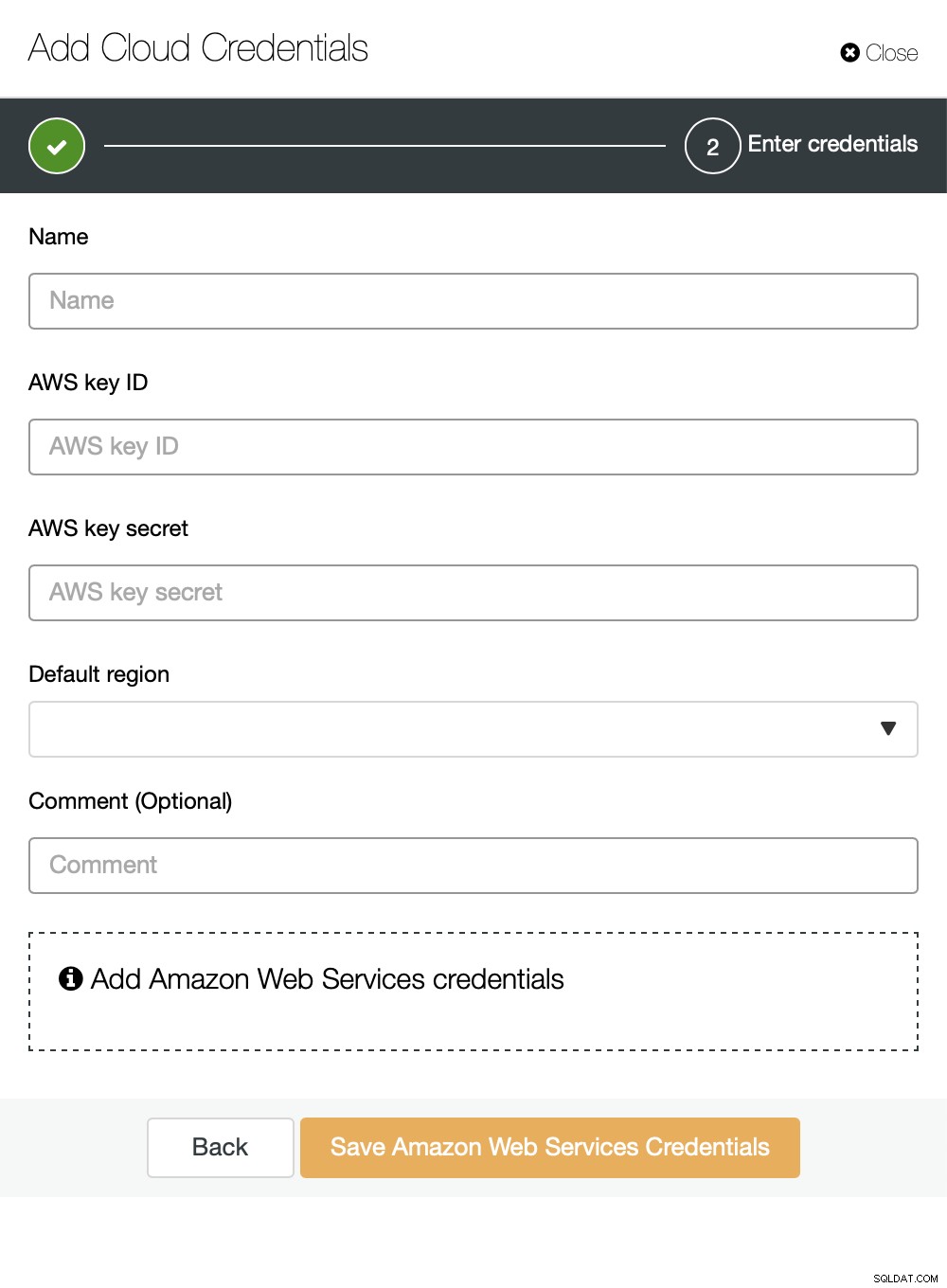
Можете да изберете Amazon Web Services, Google Cloud или Microsoft Azure като облак искате ClusterControl да качва резервни копия. Ще продължим с AWS, където ClusterControl ще използва S3 за съхраняване на резервни копия.
След това трябва да предадем идентификатор на ключ и секретен ключ, изберете региона по подразбиране и изберете име за този набор от идентификационни данни.
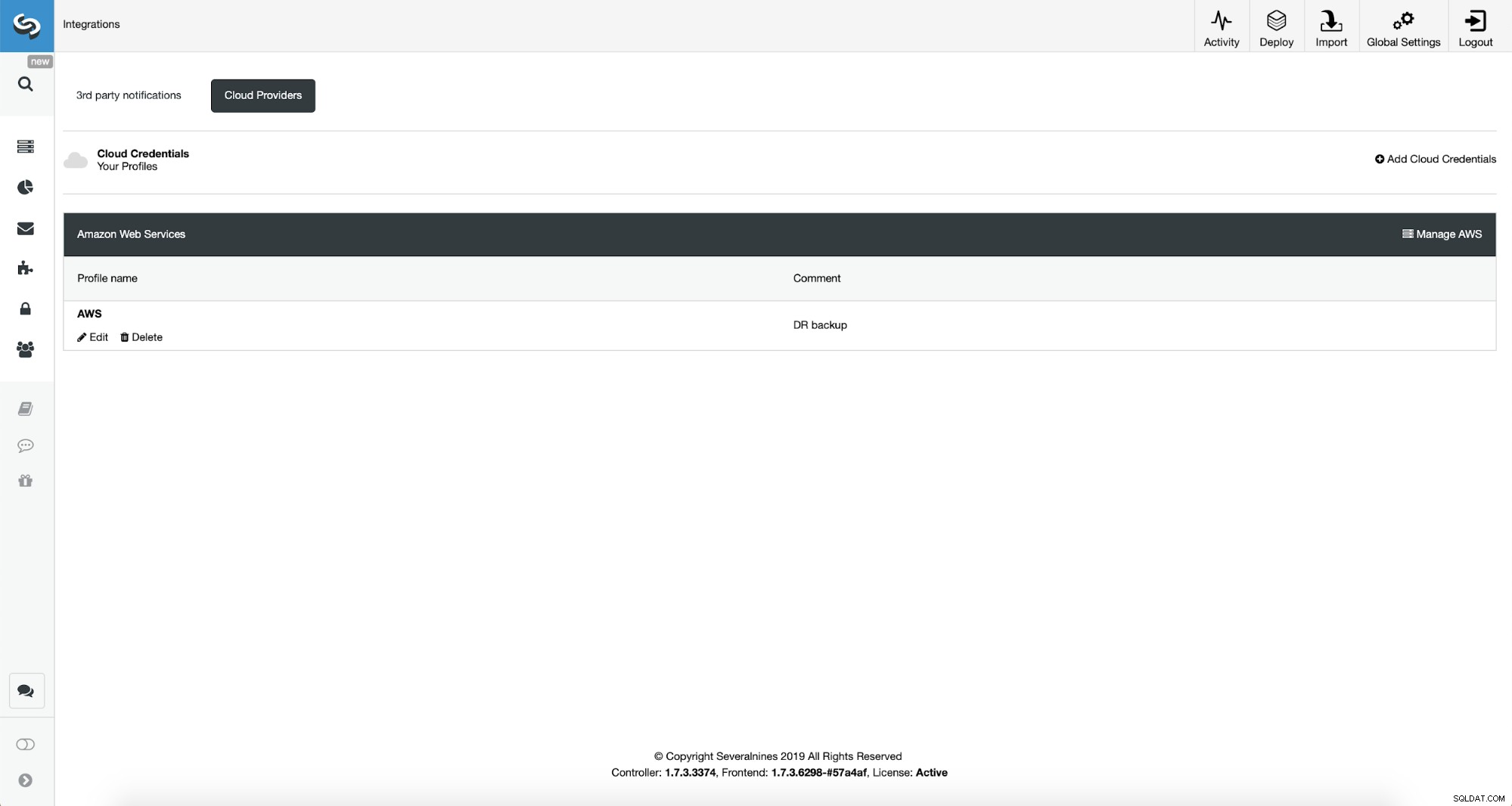
След като това стане, можем да видим идентификационните данни, които току-що добавихме, изброени в ClusterControl.
Сега ще продължим с настройката на графика за архивиране.
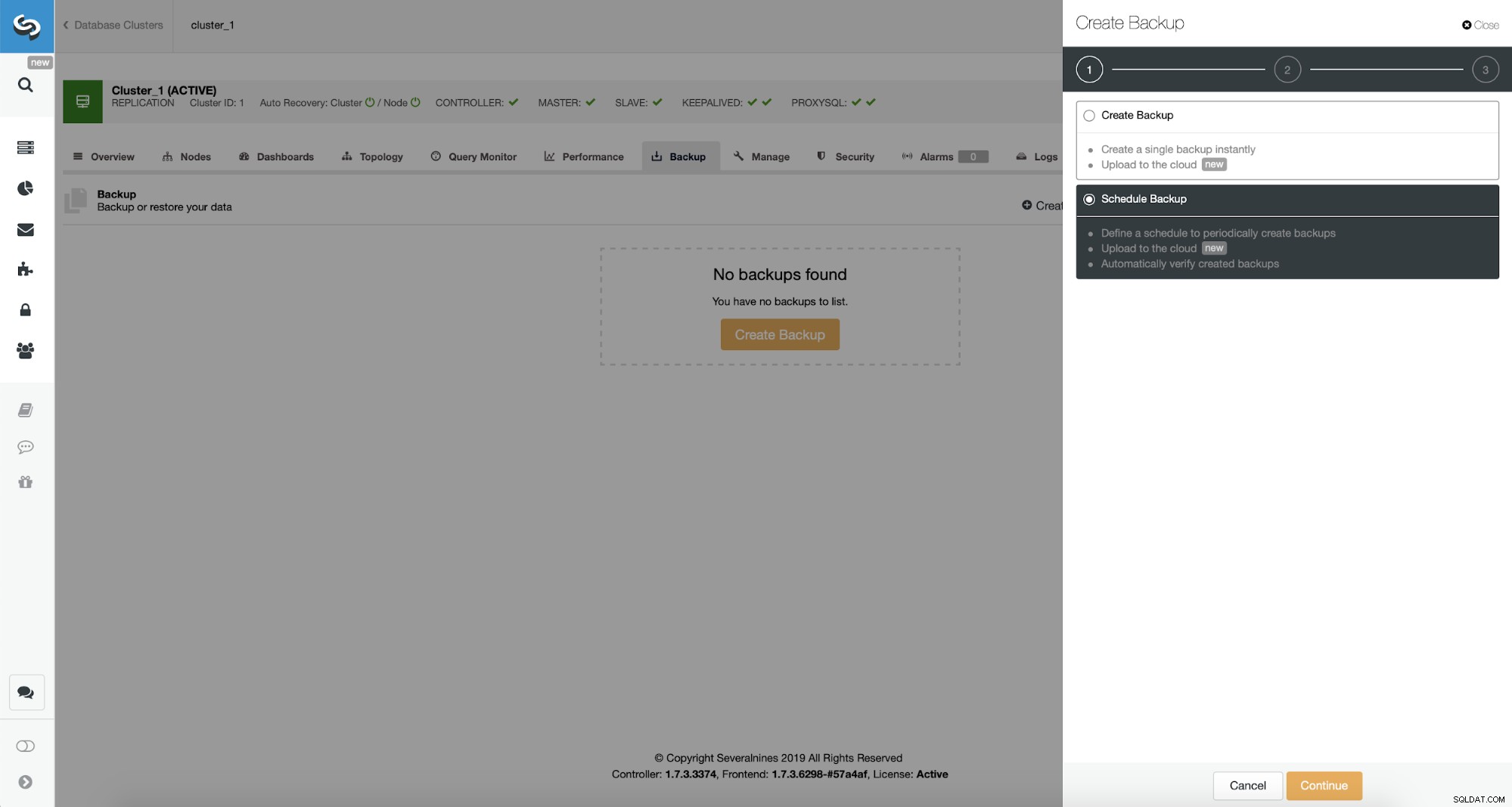
ClusterControl ви позволява или да създадете резервно копие незабавно, или да го планирате. Ще преминем към втория вариант. Това, което искаме, е да създадем следния график:
- Пълно архивиране се създава веднъж на ден
- Постепенно архивиране, създавано на всеки 10 минути.
Идеята тук е както следва. В най-лошия случай ще загубим само 10 минути от трафика. Ако центърът за данни стане недостъпен отвън, но ще работи вътрешно, бихме могли да се опитаме да избегнем загуба на данни, като изчакаме 10 минути, копираме най-новото допълнително архивиране на някакъв лаптоп и след това можем ръчно да го изпратим към нашата база данни за DR, като използваме дори телефонно тетъринг и клетъчна връзка за заобикаляне на повреда на ISP. Ако няма да можем да извлечем данните от стария център за данни за известно време, това има за цел да сведе до минимум количеството транзакции, които ще трябва ръчно да обединим в базата данни за DR.
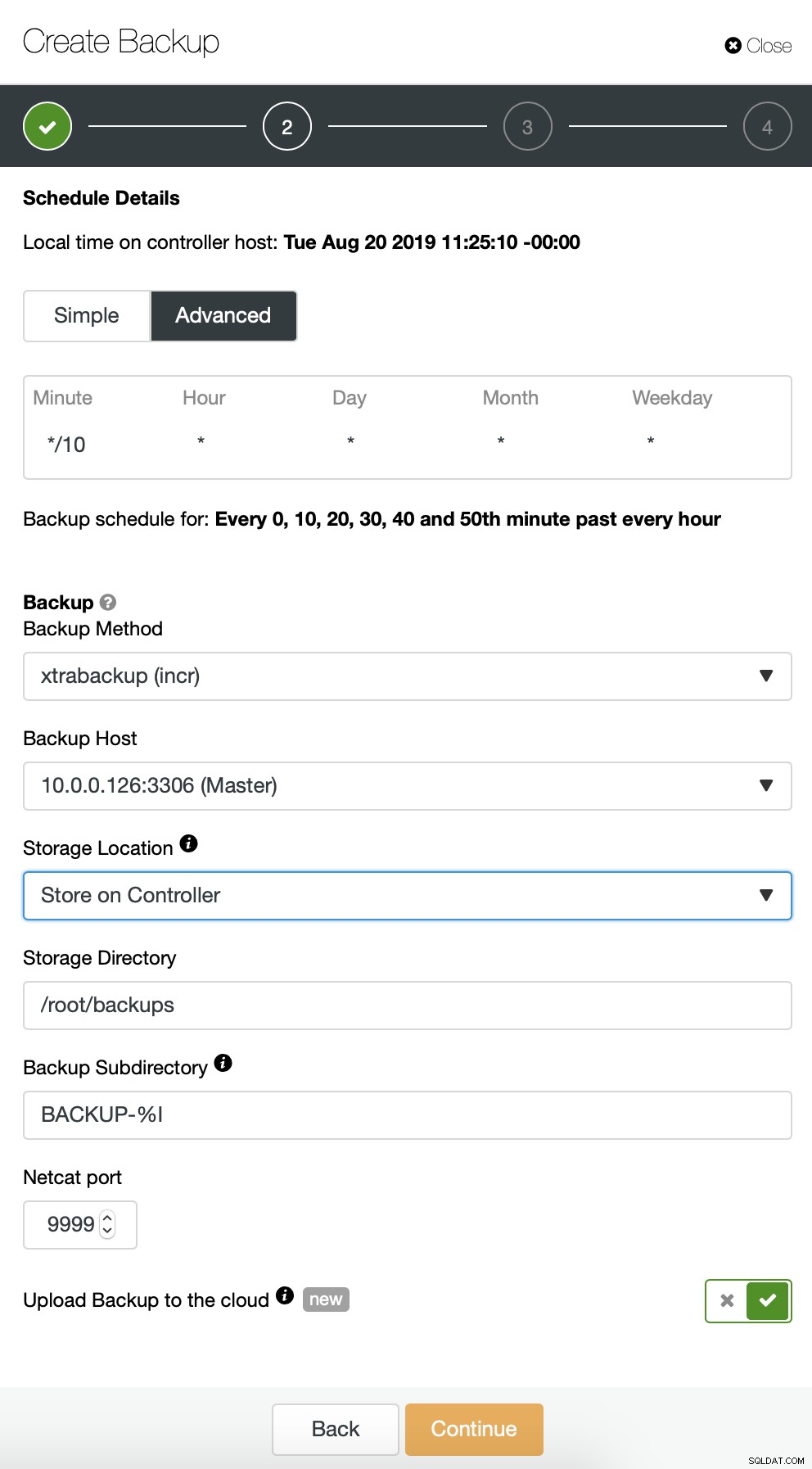
Започваме с пълно архивиране, което ще се случва всеки ден в 2:00 часа сутринта. Ще използваме master, за да вземем архива от, ще го съхраняваме на контролера в директорията /root/backups/. Също така ще активираме опцията „Качване на архивно копие в облака“.
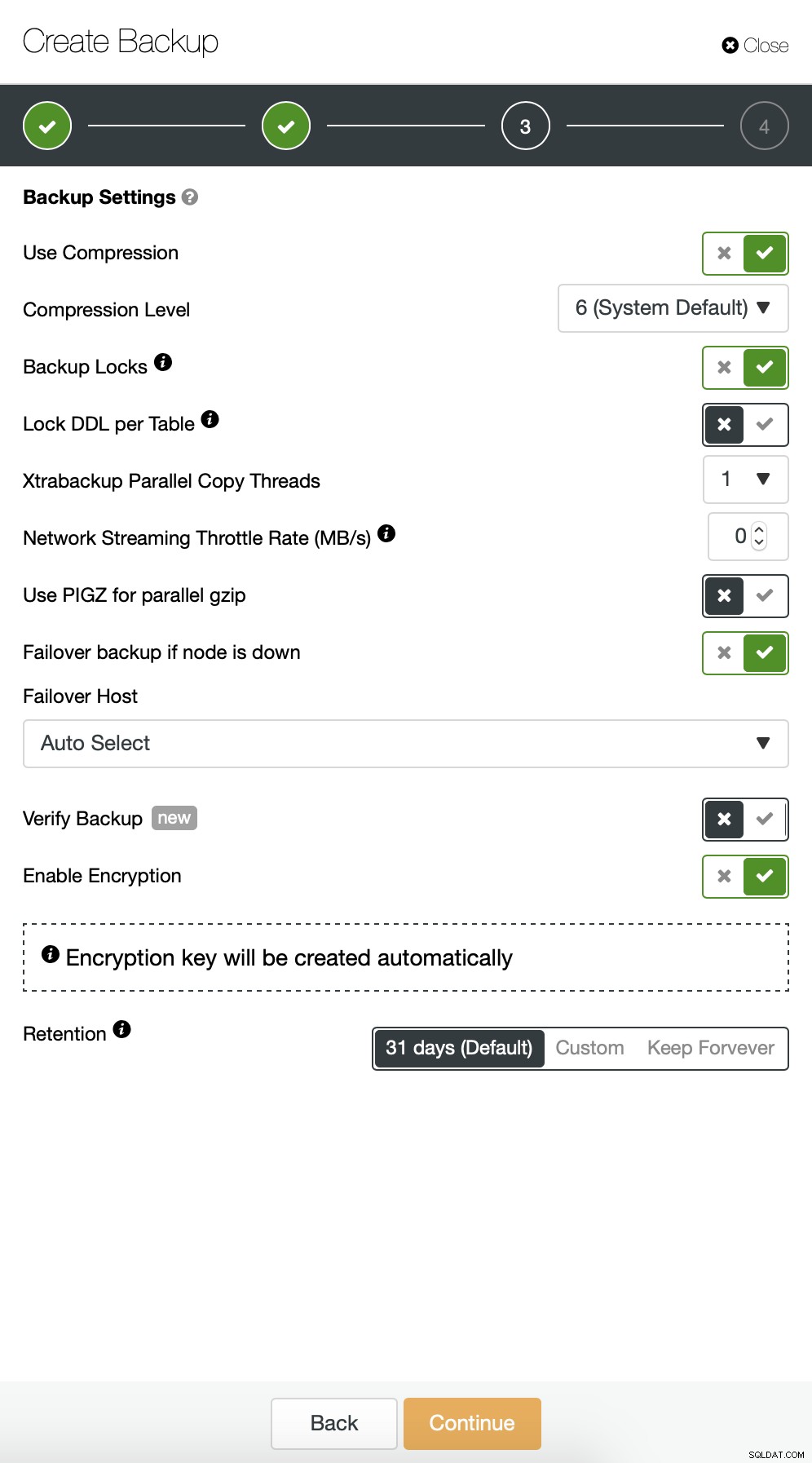
След това искаме да направим някои промени в конфигурацията по подразбиране. Решихме да използваме автоматично избран хост за отказване (в случай, че нашият главен обект не е наличен, ClusterControl ще използва всеки друг възел, който е наличен). Искахме също да активираме криптирането, тъй като ще изпращаме резервните си копия по мрежата.
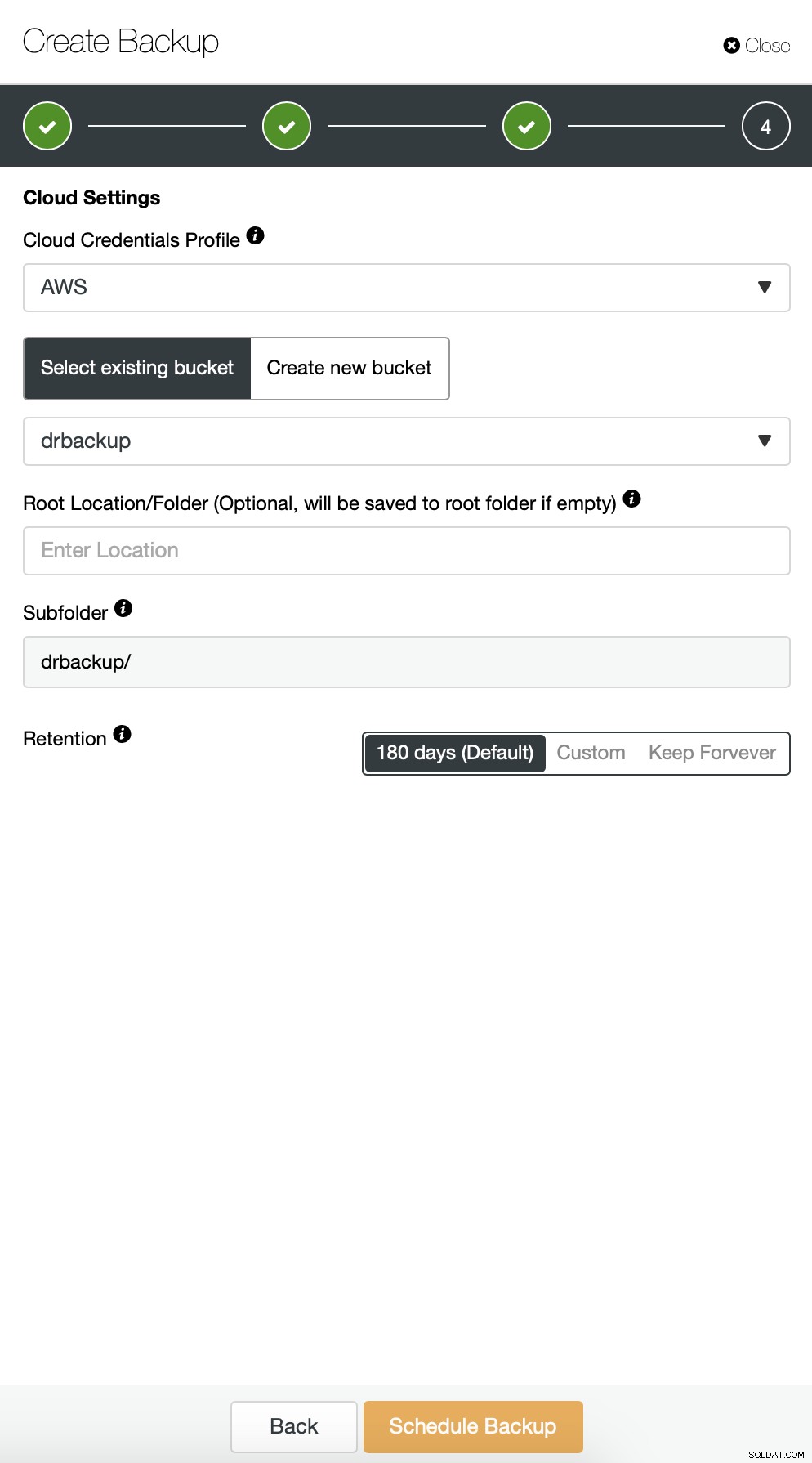
След това трябва да изберем идентификационните данни, да изберем съществуваща S3 кофа или да създадем нов, ако е необходимо.
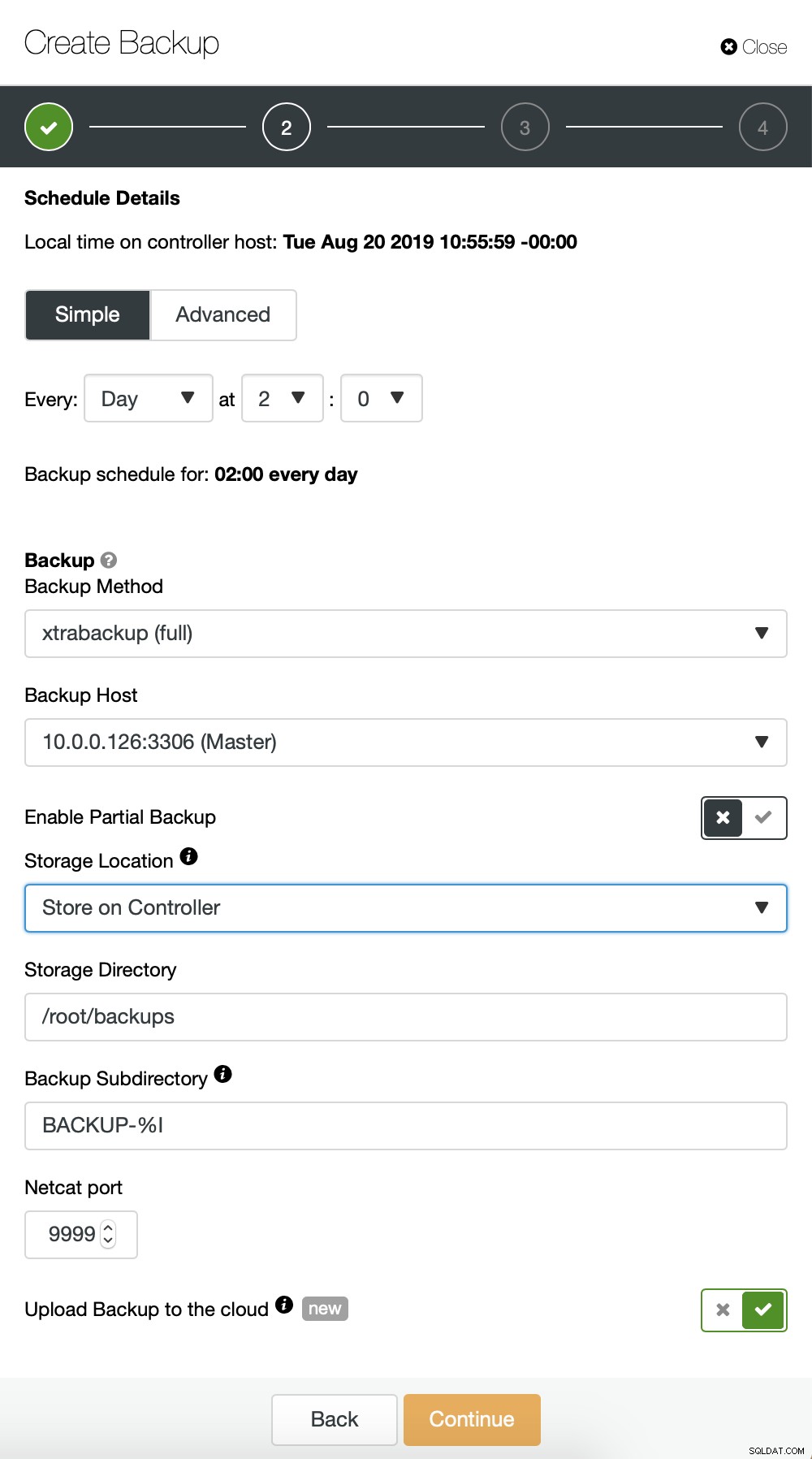
По принцип повтаряме процеса за инкременталното архивиране, този път използвахме диалоговия прозорец „Разширени“, за да стартирате архивирането на всеки 10 минути.
Останалите настройки са подобни, ние също можем да използваме повторно кофата S3.
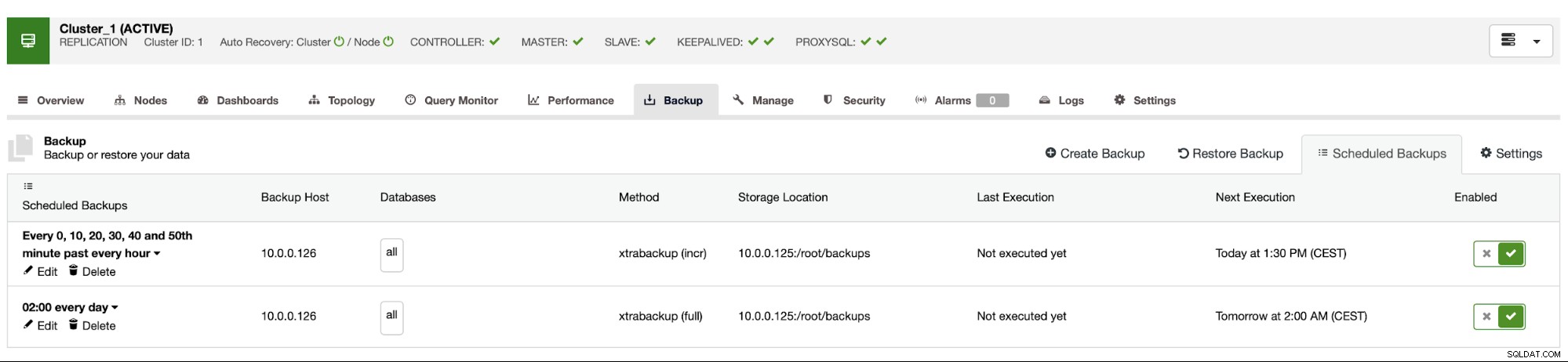
Графикът за архивиране изглежда както по-горе. Не е нужно да стартираме пълно архивиране ръчно, ClusterControl ще стартира инкрементално архивиране по график и ако открие, че няма налично пълно архивиране, ще изпълни пълно архивиране вместо инкрементално.
С такава настройка можем спокойно да кажем, че можем да възстановим данните на всяка външна система с 10-минутна детайлност.
Ръчно възстановяване от резервно копие
Ако се случи, че ще трябва да възстановите резервното копие на екземпляра за възстановяване след бедствие, трябва да предприемете няколко стъпки. Силно препоръчваме да тествате този процес от време на време, като се уверите, че работи правилно и че сте опитни в изпълнението му.
Първо, трябва да инсталираме инструмента за команден ред AWS на целевия ни сървър:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userСлед това трябва да го конфигурираме с подходящи идентификационни данни:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonСега можем да тестваме дали имаме достъп до данните в нашата S3 кофа:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Сега трябва да изтеглим данните. Ще създадем директория за архивите – не забравяйте, че трябва да изтеглим целия набор от архивни копия – като се започне от пълно архивиране до последното допълнително, което искаме да приложим.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Сега има две опции. Можем да изтеглим резервни копия едно по едно:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Можем също, особено ако имате строг график на ротация, да синхронизираме цялото съдържание на пакета с това, което имаме локално на сървъра:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Както си спомняте, резервните копия са криптирани. Трябва да имаме ключ за криптиране, който се съхранява в ClusterControl. Уверете се, че копието му е съхранено на безопасно място, извън главния център за данни. Ако не можете да го достигнете, няма да можете да дешифрирате резервни копия. Ключът може да бъде намерен в конфигурацията на ClusterControl:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Кодира се с помощта на base64, така че първо трябва да го декодираме и да го съхраним във файла, преди да започнем да декриптираме архива:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> пас
Сега можем да използваме повторно този файл, за да декриптираме резервни копия. Засега да кажем, че ще направим едно пълно и две постепенни резервни копия.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Данните са декриптирани, сега трябва да продължим с настройката на нашия MySQL сървър. В идеалния случай това трябва да бъде точно същата версия като на производствените системи. Ще използваме Percona Server за MySQL:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Нищо сложно, просто редовна инсталация. След като е готов, трябва да го спрем и да премахнем съдържанието на директорията с данни.
service mysql stop
rm -rf /var/lib/mysql/*За да възстановим архива, ще ни трябва Xtrabackup – инструмент, който CC използва, за да го създаде (поне за Perona и Oracle MySQL, MariaDB използва MariaBackup). Важно е този инструмент да е инсталиран в същата версия като на производствените сървъри:
apt install percona-xtrabackup-24Това е всичко, което трябва да подготвим. Сега можем да започнем да възстановяваме архива. При инкременталните архиви е важно да имате предвид, че трябва да ги подготвите и приложите върху основния архив. Базовото архивиране също трябва да бъде подготвено. От решаващо значение е да стартирате подготовката с опцията „--apply-log-only“, за да предотвратите изпълнението на фазата на връщане назад на xtrabackup. В противен случай няма да можете да приложите следващото инкрементално архивиране.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/В последната команда позволихме на xtrabackup да изпълнява връщането назад на незавършени транзакции - след това няма да прилагаме повече инкрементални архиви. Сега е време да попълните директорията с данни с архива, стартирайте MySQL и вижте дали всичко работи както се очаква:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Както виждате, всичко е наред. MySQL стартира правилно и успяхме да осъществим достъп до него (и данните са там!) Успяхме успешно да върнем нашата база данни обратно и работеща на отделно място. Общото необходимо време зависи стриктно от размера на данните - трябваше да изтеглим данни от S3, да ги декриптираме и декомпресираме и накрая да подготвим архива. Все пак това е много евтина опция (трябва да плащате само за данни от S3), която ви дава възможност за непрекъснатост на бизнеса, ако се случи бедствие.