Производителността е изключително важна в много потребителски продукти като електронна търговия, платежни системи, игри, приложения за транспорт и т.н. Въпреки че базите данни са вътрешно оптимизирани чрез множество механизми, за да отговорят на техните изисквания за производителност в съвременния свят, много зависи и от разработчика на приложението — в края на краищата само разработчикът знае какви заявки трябва да изпълнява приложението.
Разработчиците, които се занимават с релационни бази данни, са използвали или поне са чували за индексирането и това е много често срещана концепция в света на бази данни. Най-важната част обаче е да разберете какво да индексирате и как индексирането ще увеличи времето за отговор на заявката. За да направите това, трябва да разберете как ще направите заявка за вашите таблици на база данни. Подходящ индекс може да бъде създаден само когато знаете точно как изглеждат вашите заявки и модели за достъп до данни.
С проста терминология, индексът съпоставя ключовете за търсене към съответните данни на диска, като използва различни структури от данни в паметта и на диска. Индексът се използва за ускоряване на търсенето чрез намаляване на броя на записите за търсене.
Най-често се създава индекс на колоните, посочени в WHERE клауза на заявка, тъй като базата данни извлича и филтрира данни от таблиците въз основа на тези колони. Ако не създадете индекс, базата данни сканира всички редове, филтрира съвпадащите редове и връща резултата. С милиони записи тази операция на сканиране може да отнеме много секунди и това високо време за реакция прави API и приложенията по-бавни и неизползваеми. Нека видим пример —
Ще използваме MySQL с машина за база данни InnoDB по подразбиране, въпреки че концепциите, обяснени в тази статия, са повече или по-малко еднакви в други сървъри на бази данни, както и като Oracle, MSSQL и т.н.
Създайте таблица, наречена index_demo със следната схема:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Как да проверим дали използваме InnoDB машина?
Изпълнете командата по-долу:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;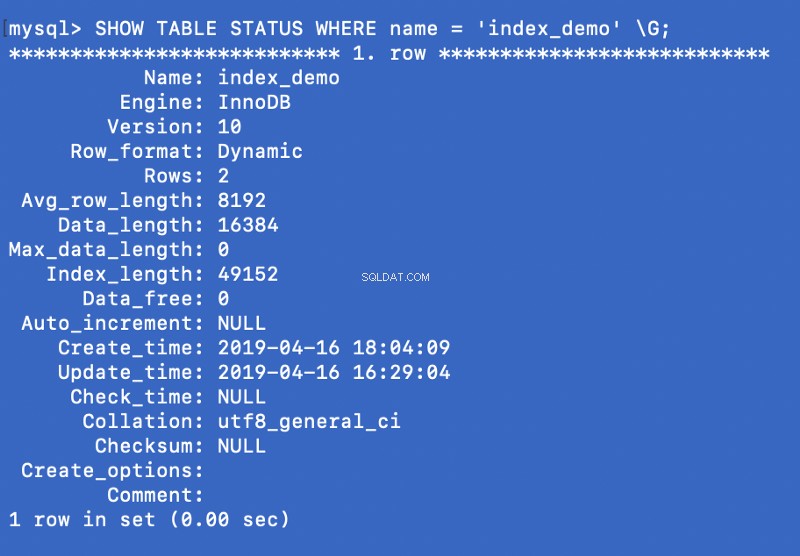
Engine колоната в горната екранна снимка представлява двигателя, който се използва за създаване на таблицата. Тук InnoDB се използва.
Сега вмъкнете някои произволни данни в таблицата, моята таблица с 5 реда изглежда по следния начин:
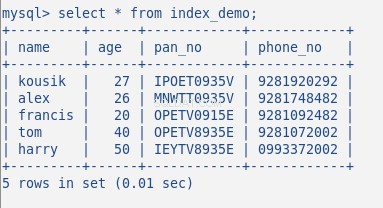
Досега не съм създал индекс на тази таблица. Нека проверим това с командата:SHOW INDEX . Връща 0 резултата.

В този момент, ако изпълним обикновен SELECT заявка, тъй като няма дефиниран от потребителя индекс, заявката ще сканира цялата таблица, за да разбере резултата:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN показва как машината за заявки планира да изпълни заявката. На горната екранна снимка можете да видите, че rows колоната връща 5 &possible_keys връща null . possible_keys представлява всички налични индекси, които могат да се използват в тази заявка. key колоната представлява кой индекс действително ще бъде използван от всички възможни индекси в тази заявка.
Първичен ключ:
Горната заявка е много неефективна. Нека оптимизираме тази заявка. Ще направим phone_no колона PRIMARY KEY като приемем, че в нашата система не могат да съществуват двама потребители с един и същ телефонен номер. Вземете предвид следното, когато създавате първичен ключ:
- Първичният ключ трябва да бъде част от много жизненоважни заявки във вашето приложение.
- Първичният ключ е ограничение, което уникално идентифицира всеки ред в таблица. Ако няколко колони са част от първичния ключ, тази комбинация трябва да е уникална за всеки ред.
- Първичният ключ трябва да е Non-null. Никога не правете полетата с възможност за нула свой първичен ключ. Според стандартите на ANSI SQL първичните ключове трябва да са сравними един с друг и определено трябва да можете да разберете дали стойността на колоната на първичния ключ за конкретен ред е по-голяма, по-малка или равна на същата от друг ред. Тъй като
NULLозначава недефинирана стойност в SQL стандартите, не можете да сравните детерминистичноNULLс всяка друга стойност, така че логичноNULLне е разрешено. - Идеалният тип първичен ключ трябва да бъде число като
INTилиBIGINTтъй като целочислените сравнения са по-бързи, така че преминаването през индекса ще бъде много бързо.
Често ние дефинираме id поле като AUTO INCREMENT в таблици и го използвайте като първичен ключ, но изборът на първичен ключ зависи от разработчиците.
Ами ако не създадете първичен ключ сами?
Не е задължително сами да създавате първичен ключ. Ако не сте дефинирали първичен ключ, InnoDB имплицитно създава такъв за вас, защото InnoDB по дизайн трябва да има първичен ключ във всяка таблица. Така че след като създадете първичен ключ по-късно за тази таблица, InnoDB изтрива предварително автоматично дефинирания първичен ключ.
Тъй като към момента нямаме дефиниран първичен ключ, нека видим какво InnoDB създаде по подразбиране за нас:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED показва всички индекси, които не са използвани от потребителя, но се управляват изцяло от MySQL.
Тук виждаме, че MySQL е дефинирал съставен индекс (ще обсъдим съставните индекси по-късно) на DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR , &всички колони, дефинирани в таблицата. При липса на първичен ключ, дефиниран от потребителя, този индекс се използва за уникално намиране на записи.
Каква е разликата между ключ и индекс?
Въпреки че термините key &index се използват взаимозаменяемо, key означава ограничение, наложено върху поведението на колоната. В този случай ограничението е, че първичният ключ е поле без нула, което уникално идентифицира всеки ред. От друга страна, index е специална структура от данни, която улеснява търсенето на данни в таблицата.
Нека сега създадем основния индекс на phone_no &прегледайте създадения индекс:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Обърнете внимание, че CREATE INDEX не може да се използва за създаване на основен индекс, но ALTER TABLE се използва.

На горната екранна снимка виждаме, че един основен индекс е създаден в колоната phone_no . Колоните на следните изображения са описани по следния начин:
Table :Таблицата, върху която е създаден индексът.
Non_unique :Ако стойността е 1, индексът не е уникален, ако стойността е 0, индексът е уникален.
Key_name :Името на създадения индекс. Името на основния индекс винаги е PRIMARY в MySQL, независимо дали сте предоставили име на индекс или не, докато създавате индекса.
Seq_in_index :Поредният номер на колоната в индекса. Ако множество колони са част от индекса, поредният номер ще бъде присвоен въз основа на това как колоните са били подредени по време на времето за създаване на индекса. Поредният номер започва от 1.
Collation :как колоната е сортирана в индекса. A означава възходящо, D означава низходящ, NULL означава, че не е сортирано.
Cardinality :Прогнозният брой уникални стойности в индекса. Повече кардиналност означава по-големи шансове оптимизаторът на заявки да избере индекса за заявки.
Sub_part :Индексният префикс. Това е NULL ако цялата колона е индексирана. В противен случай показва броя на индексираните байтове, в случай че колоната е частично индексирана. Ще дефинираме частичен индекс по-късно.
Packed :Показва как е опакован ключът; NULL ако не е.
Null :YES ако колоната може да съдържа NULL стойности и празно, ако не е така.
Index_type :Показва коя структура от данни за индексиране се използва за този индекс. Някои възможни кандидати са — BTREE , HASH , RTREE , или FULLTEXT .
Comment :Информацията за индекса не е описана в собствената му колона.
Index_comment :Коментарът за индекса, посочен, когато сте създали индекса с COMMENT атрибут.
Сега нека видим дали този индекс намалява броя на редовете, които ще бъдат търсени за даден phone_no в WHERE клауза на заявка.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
В тази моментна снимка забележете, че rows колоната върна 1 само possible_keys &key и двете връщат PRIMARY . Така че това по същество означава, че се използва първичният индекс, наречен PRIMARY (името се присвоява автоматично, когато създавате първичен ключ), оптимизаторът на заявки просто отива директно към записа и го извлича. Много е ефективно. Точно за това е предназначен индексът — да се сведе до минимум обхвата на търсене с цената на допълнително пространство.
Клъстерен индекс:
clustered index се разпределя с данните в същото пространство за таблици или същия дисков файл. Можете да считате, че клъстерираният индекс е B-Tree индекс, чиито крайни възли са действителните блокове данни на диска, тъй като индексът и данните се намират заедно. Този вид индекс физически организира данните на диска според логическия ред на индексния ключ.
Какво означава организация на физическите данни?
Физически данните са организирани на диск върху хиляди или милиони дискове/блокове данни. За клъстериран индекс не е задължително всички дискови блокове да се съхраняват заразно. Физическите блокове от данни през цялото време се преместват насам-натам от ОС, когато е необходимо. Системата от база данни няма абсолютен контрол върху това как се управлява физическото пространство от данни, но вътре в блок от данни записите могат да се съхраняват или управляват в логическия ред на индексния ключ. Следната опростена диаграма го обяснява:
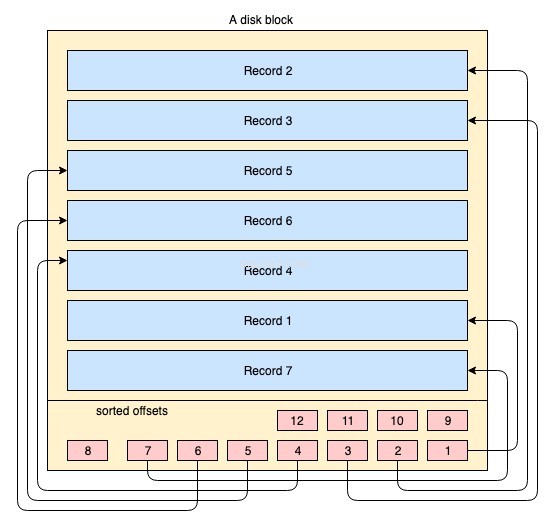
- Големият правоъгълник с жълт цвят представлява дисков блок/блок от данни
- правоъгълниците в син цвят представляват данни, съхранявани като редове в този блок
- областта на долния колонтитул представлява индекса на блока, където се намират червените малки правоъгълници в сортиран ред на конкретен ключ. Тези малки блокчета не са нищо друго освен вид указатели, сочещи към отмествания на записите.
Записите се съхраняват на дисковия блок в произволен ред. Всеки път, когато се добавят нови записи, те се добавят в следващото налично пространство. Всеки път, когато съществуващ запис се актуализира, ОС решава дали този запис все още може да се побере в същата позиция или трябва да бъде разпределена нова позиция за този запис.
Така че позицията на записите се обработва изцяло от ОС и не съществува определена връзка между реда на всеки два записа. За да се извлекат записите в логическия ред на ключа, страниците на диска съдържат индексна секция в долния колонтитул, индексът съдържа списък с изместени указатели в реда на ключа. Всеки път, когато запис се променя или създава, индексът се коригира.
По този начин наистина не е нужно да се грижите за действителното организиране на физическия запис в определен ред, по-скоро се поддържа малка индексна секция в този ред и извличането или поддържането на записи става много лесно.
Предимство на клъстерирания индекс:
Това подреждане или съвместно разположение на свързани данни всъщност прави клъстерирания индекс по-бърз. Когато данните се извличат от диск, пълният блок, съдържащ данните, се чете от системата, тъй като нашата дискова IO система записва и чете данни на блокове. Така че в случай на заявки за диапазон е напълно възможно събраните данни да се буферират в паметта. Да кажем, че задействате следната заявка:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Блок от данни се извлича в паметта, когато се изпълни заявката. Да кажем, че блокът от данни съдържа phone_no в диапазона от 9010000000 до 9030000000 . Така че какъвто и диапазон да поискате в заявката, е само подмножество от наличните данни в блока. Ако сега стартирате следващата заявка, за да получите всички телефонни номера в диапазона, кажете от 9015000000 до 9019000000 , не е необходимо да извличате повече блокове от диска. Пълните данни могат да бъдат намерени в текущия блок данни, по този начин clustered_index намалява броя на IO на диска, като разпределя свързани данни колкото е възможно повече в един и същ блок от данни. Това намалено IO води до подобряване на производителността.
Така че, ако имате добре обмислен първичен ключ и вашите заявки се основават на първичния ключ, производителността ще бъде супер бърза.
Ограничения на клъстерирания индекс:
Тъй като клъстерираният индекс оказва влияние върху физическата организация на данните, може да има само един клъстериран индекс на таблица.
Връзка между първичен ключ и клъстериран индекс:
Не можете да създадете клъстериран индекс ръчно, като използвате InnoDB в MySQL. MySQL го избира вместо вас. Но как избира? Следните извадки са от документацията на MySQL:
Когато дефиниратеPRIMARY KEYна вашата маса,InnoDBго използва като клъстериран индекс. Дефинирайте първичен ключ за всяка таблица, която създавате. Ако няма логическа уникална и ненулева колона или набор от колони, добавете нова колона с автоматично увеличение, чиито стойности се попълват автоматично.
Ако не дефиниратеPRIMARY KEYза вашата таблица MySQL намира първияUNIQUEиндекс, където всички ключови колони саNOT NULLиInnoDBго използва като клъстериран индекс.
Ако таблицата нямаPRIMARY KEYили подходящUNIQUEиндекс,InnoDBвътрешно генерира скрит клъстериран индекс с имеGEN_CLUST_INDEXвърху синтетична колона, съдържаща стойности за идентификатор на ред. Редовете са подредени по идентификатора, койтоInnoDBприсвоява на редовете в такава таблица. Идентификационният номер на реда е 6-байтово поле, което се увеличава монотонно с вмъкването на нови редове. По този начин редовете, подредени от идентификатора на реда, са физически в ред на вмъкване.
Накратко, механизмът MySQL InnoDB всъщност управлява първичния индекс като клъстериран индекс за подобряване на производителността, така че първичният ключ и действителният запис на диска са групирани заедно.
Структура на индекса на първичния ключ (клъстериран):
Индексът обикновено се поддържа като B+ дърво на диск и в паметта и всеки индекс се съхранява в блокове на диска. Тези блокове се наричат индексни блокове. Записите в индексния блок винаги се сортират по ключа за индекс/търсене. Индексният блок на листа на индекса съдържа локатор на редове. За първичния индекс, локаторът на редове се отнася до виртуален адрес на съответното физическо местоположение на блоковете данни на диска, където се намират редовете, които се сортират според ключа на индекса.
В следващата диаграма правоъгълниците отляво представляват индексни блокове на ниво лист, а правоъгълниците от дясната страна представляват блоковете данни. Логично блоковете данни изглеждат подравнени в сортиран ред, но както вече беше описано по-рано, действителните физически местоположения може да са разпръснати тук и там.
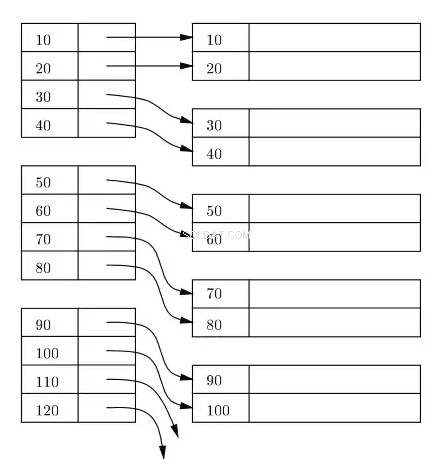
Възможно ли е да се създаде първичен индекс върху непървичен ключ?
В MySQL автоматично се създава първичен индекс и ние вече описахме по-горе как MySQL избира основния индекс. Но в света на базата данни всъщност не е необходимо да създавате индекс в колоната с първичен ключ - първичният индекс може да бъде създаден и във всяка колона, която не е първичен ключ. Но когато са създадени върху първичния ключ, всички ключови записи са уникални в индекса, докато в другия случай първичният индекс може също да има дублиран ключ.
Възможно ли е да се изтрие първичен ключ?
Възможно е да изтриете първичен ключ. Когато изтриете първичен ключ, свързаният клъстериран индекс, както и свойството за уникалност на тази колона се губят.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Предимства на първичния индекс:
- Заявките за диапазон, базирани на първичен индекс, са много ефективни. Може да има възможност дисковият блок, който базата данни е прочела от диска, да съдържа всички данни, принадлежащи на заявката, тъй като основният индекс е клъстериран и записите са подредени физически. Така че местоположението на данните може да бъде предоставено от първичния индекс.
- Всяка заявка, която се възползва от първичния ключ, е много бърза.
Недостатъци на първичния индекс:
- Тъй като първичният индекс съдържа директна препратка към адреса на блока от данни през виртуалното адресно пространство и дисковите блокове са физически организирани в реда на индексния ключ, всеки път, когато операционната система прави някакво разделяне на страница на диск поради
DMLоперации катоINSERT/UPDATE/DELETE, основният индекс също трябва да бъде актуализиран. Така чеDMLоперации оказва известен натиск върху производителността на първичния индекс.
Вторичен индекс:
Всеки индекс, различен от клъстериран, се нарича вторичен индекс. Вторичните индекси не оказват влияние върху физическите места за съхранение за разлика от първичните индекси.
Кога имате нужда от вторичен индекс?
Може да имате няколко случая на употреба във вашето приложение, при които не заявявате базата данни с първичен ключ. В нашия пример phone_no е първичният ключ, но може да се наложи да потърсим базата данни с pan_no , или name . В такива случаи имате нужда от вторични индекси за тези колони, ако честотата на такива заявки е много висока.
Как да създадем вторичен индекс в MySQL?
Следната команда създава вторичен индекс в name колона в index_demo таблица.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Структура на вторичния индекс:
В диаграмата по-долу, правоъгълниците с червен цвят представляват вторични индексни блокове. Вторичният индекс също се поддържа в дървото B+ и е сортиран според ключа, върху който е създаден индексът. Листовите възли съдържат копие на ключа на съответните данни в първичния индекс.
За да разберете, можете да приемете, че вторичният индекс има препратка към адреса на първичния ключ, въпреки че не е така. Извличането на данни чрез вторичния индекс означава, че трябва да преминете през две B+ дървета – едното е самото дърво на вторичен индекс B+, а другото е дървото на първичния индекс B+.
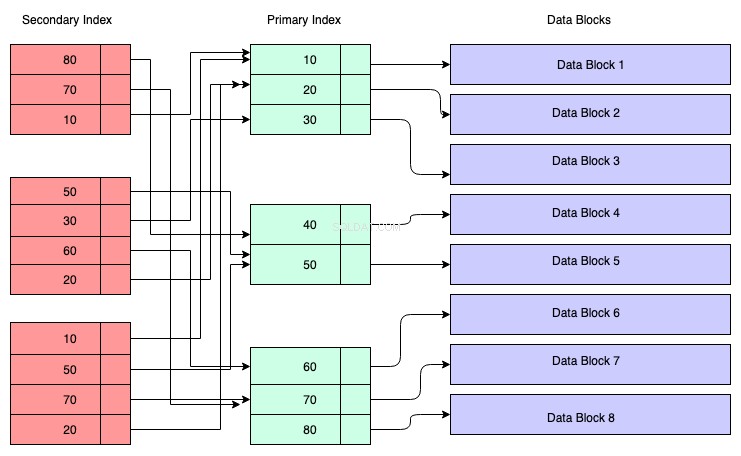
Предимства на вторичния индекс:
Логично можете да създадете толкова вторични индекси, колкото искате. Но в действителност колко индекса всъщност изисква сериозен процес на мислене, тъй като всеки индекс има свое собствено наказание.
Недостатъци на вторичния индекс:
С DML операции като DELETE / INSERT , вторичният индекс също трябва да бъде актуализиран, така че копието на колоната с първичен ключ да може да бъде изтрито/вмъкнато. В такива случаи наличието на много вторични индекси може да създаде проблеми.
Освен това, ако първичният ключ е много голям, като URL , тъй като вторичните индекси съдържат копие на стойността на колоната с първичен ключ, това може да бъде неефективно по отношение на съхранението. Повече вторични ключове означава по-голям брой дублирани копия на стойността на колоната на първичния ключ, така че повече място за съхранение в случай на голям първичен ключ. Също така самият първичен ключ съхранява ключовете, така че комбинираният ефект върху съхранението ще бъде много висок.
Обмисляне преди да изтриете основен индекс:
В MySQL можете да изтриете първичен индекс, като изпуснете първичния ключ. Вече видяхме, че вторичният индекс зависи от първичен индекс. Така че, ако изтриете първичен индекс, всички вторични индекси трябва да бъдат актуализирани, за да съдържат копие на новия първичен индексен ключ, който MySQL автоматично коригира.
Този процес е скъп, когато съществуват няколко вторични индекса. Освен това други таблици може да имат препратка към външния ключ към първичния ключ, така че трябва да изтриете тези препратки към външни ключове, преди да изтриете първичния ключ.
Когато първичен ключ бъде изтрит, MySQL автоматично създава друг първичен ключ вътрешно и това е скъпа операция.
УНИКАЛЕН ключов индекс:
Подобно на първичните ключове, уникалните ключове също могат да идентифицират записи уникално с една разлика — колоната с уникалния ключ може да съдържа null стойности.
За разлика от други сървъри на бази данни, в MySQL една колона с уникален ключ може да има толкова null стойности, колкото е възможно. В стандарта на SQL null означава неопределена стойност. Така че, ако MySQL трябва да съдържа само един null стойност в колона с уникален ключ, трябва да приеме, че всички нулеви стойности са еднакви.
Но логически това не е правилно, тъй като null означава недефинирани — и недефинирани стойности не могат да се сравняват една с друга, това е естеството на null . Тъй като MySQL не може да потвърди, че всички null s означава същото, позволява множество null стойности в колоната.
Следната команда показва как да създадете уникален ключов индекс в MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Съставен индекс:
MySQL ви позволява да дефинирате индекси на множество колони, до 16 колони. Този индекс се нарича многоколонен/съставен/съставен индекс.
Да приемем, че имаме индекс, дефиниран на 4 колони — col1 , col2 , col3 , col4 . Със съставен индекс имаме възможност за търсене в col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Така че можем да използваме всеки ляв префикс на индексираните колони, но не можем да пропуснем колона от средата и да използваме това като — (col1, col3) или (col1, col2, col4) или col3 или col4 и т.н. Това са невалидни комбинации.
Следните команди създават 2 съставни индекса в нашата таблица:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Ако имате заявки, съдържащи WHERE клауза върху множество колони, напишете клаузата в реда на колоните на съставния индекс. Индексът ще бъде от полза за тази заявка. Всъщност, докато определяте колоните за съставен индекс, можете да анализирате различни случаи на използване на вашата система и да се опитате да измислите реда на колоните, който ще бъде от полза за повечето от вашите случаи на употреба.
Съставните индекси могат да ви помогнат в JOIN &SELECT запитвания също. Пример:в следния SELECT * заявка, composite_index_2 се използва.

Когато са дефинирани няколко индекса, MySQL оптимизаторът на заявки избира този индекс, който елиминира най-големия брой редове или сканира възможно най-малко редове за по-добра ефективност.
Защо използваме съставни индекси ? Защо не дефинираме множество вторични индекси в колоните, които ни интересуват?
MySQL използва само един индекс на таблица на заявка с изключение на UNION. (В UNION всяка логическа заявка се изпълнява отделно и резултатите се обединяват.) Така че дефинирането на множество индекси в множество колони не гарантира, че тези индекси ще бъдат използвани, дори ако са част от заявката.
MySQL поддържа нещо, наречено индексна статистика, което помага на MySQL да изведе как изглеждат данните в системата. Индексната статистика обаче е обобщение, но въз основа на тези мета данни MySQL решава кой индекс е подходящ за текущата заявка.
Как работи съставният индекс?
Колоните, използвани в съставните индекси, се обединяват заедно и тези конкатенирани ключове се съхраняват в сортиран ред с помощта на B+ дърво. Когато извършвате търсене, конкатенацията на вашите ключове за търсене се съпоставя с тези на съставния индекс. След това, ако има някакво несъответствие между подреждането на вашите ключове за търсене и подреждането на колоните на съставния индекс, индексът не може да се използва.
В нашия пример за следния запис се формира съставен индексен ключ чрез конкатенация на pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Как да определите дали имате нужда от съставен индекс:
- Първо анализирайте заявките си според вашите случаи на употреба. Ако видите, че определени полета се появяват заедно в много заявки, може да помислите за създаване на съставен индекс.
- Ако създавате индекс в
col1&съставен индекс в (col1,col2), тогава само съставният индекс трябва да е наред.col1Само може да се обслужва от самия съставен индекс, тъй като това е префикс отляво на индекса. - Помислете за кардиналността. Ако колоните, използвани в съставния индекс, в крайна сметка имат висока мощност заедно, те са добър кандидат за съставния индекс.
Покриващ индекс:
Покриващият индекс е специален вид съставен индекс, при който всички колони, посочени в заявката, съществуват някъде в индекса. Така че оптимизаторът на заявки не трябва да удря базата данни, за да получи данните - по-скоро той получава резултата от самия индекс. Пример:вече сме дефинирали съставен индекс на (pan_no, name, age) , така че сега помислете за следната заявка:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Колоните, споменати в SELECT &WHERE клаузите са част от съставния индекс. Така че в този случай всъщност можем да получим стойността на age колона от самия съставен индекс. Нека видим какво е EXPLAIN командата показва за тази заявка:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';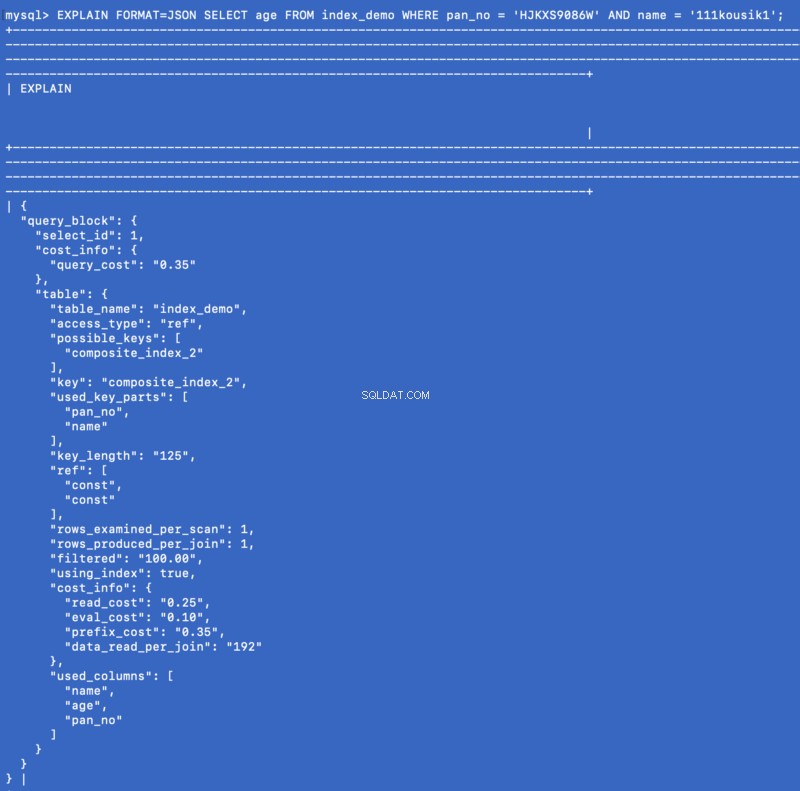
В горния отговор имайте предвид, че има ключ — using_index който е настроен на true което означава, че покриващият индекс е бил използван за отговор на заявката.
Не знам доколко покриващите индекси се оценяват в производствена среда, но очевидно изглежда, че това е добра оптимизация, в случай че заявката отговаря на сметката.
Частичен индекс:
Вече знаем, че индексите ускоряват нашите заявки с цената на пространството. Колкото повече индекси имате, толкова по-голямо е изискването за съхранение. Вече създадохме индекс, наречен secondary_idx_1 в колоната name . Колоната name може да съдържа големи стойности с всякаква дължина. Също така в индекса метаданните на локаторите на редове или указателите на редове имат свой собствен размер. Така че като цяло индексът може да има голямо натоварване на съхранение и памет.
В MySQL е възможно да се създаде и индекс за първите няколко байта данни. Пример:следната команда създава индекс на първите 4 байта от името. Въпреки че този метод намалява наднорменото натоварване на паметта с определена сума, индексът не може да елиминира много редове, тъй като в този пример първите 4 байта може да са общи за много имена. Обикновено този вид индексиране на префикси се поддържа на CHAR ,VARCHAR , BINARY , VARBINARY тип колони.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Какво се случва под капака, когато дефинираме индекс?
Нека стартираме SHOW EXTENDED команда отново:
SHOW EXTENDED INDEXES FROM index_demo;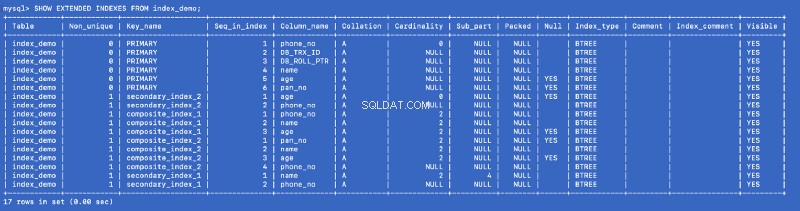
Дефинирахме secondary_index_1 на name , но MySQL е създал съставен индекс на (name , phone_no ) където phone_no е колоната с първичен ключ. Създадохме secondary_index_2 на age &MySQL създаде съставен индекс на (age , phone_no ). Създадохме composite_index_2 включено (pan_no , name , age ) &MySQL създаде съставен индекс на (pan_no , name , age , phone_no ). Съставният индекс composite_index_1 вече има phone_no като част от него.
Така че какъвто и индекс да създадем, MySQL във фонов режим създава поддържащ съставен индекс, който на свой ред сочи към първичния ключ. Това означава, че първичният ключ е първокласен гражданин в света на индексирането на MySQL. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html