Почти всеки проблем с производителността, свързан с изчислените колони, който съм срещал през годините, е имал една (или повече) от следните основни причини:
- Ограничения при внедряването
- Липса на поддръжка на модела на разходите в оптимизатора на заявки
- Разширяване на дефиницията на изчислена колона преди започване на оптимизация
Пример за ограничение на внедряването не може да създаде филтриран индекс върху изчислена колона (дори когато е запазен). Не можем да направим много по отношение на тази проблемна категория; трябва да използваме заобиколни решения, докато чакаме подобренията на продукта.
Липсата на оптимизаторподдръжка на модела на разходите означава, че SQL Server приписва малка фиксирана цена на скаларните изчисления, независимо от сложността или изпълнението. Вследствие на това сървърът често решава да преизчисли съхранена стойност на изчислена колона, вместо да чете директно запазената или индексирана стойност. Това е особено болезнено, когато изчисленият израз е скъп, например когато включва извикване на скаларна функция, дефинирана от потребителя.
Проблемите околоразширяването на дефиницията са малко по-ангажирани и имат широкообхватни ефекти.
Проблемите с изчисленото разширение на колона
SQL Server обикновено разширява изчислените колони в техните основни дефиниции по време на фазата на обвързване на нормализиране на заявката. Това е много ранна фаза в процеса на компилиране на заявка, доста преди да бъдат взети каквито и да било решения за избор на план (включително тривиален план).
На теория извършването на ранно разширяване може да даде възможност за оптимизации, които иначе биха били пропуснати. Например, оптимизаторът може да е в състояние да прилага опростявания, като се има предвид друга информация в заявката и метаданните (например ограничения). Това е същият вид разсъждение, което води до разширяване на дефинициите на изглед (освен ако NOEXPAND използва се подсказка).
По-късно в процеса на компилация (но все още преди да бъде разгледан дори тривиален план), оптимизаторът търси да съпостави обратните изрази с постоянни или индексирани изчислени колони. Проблемът е, че дейностите на оптимизатора междувременно може да са променили разширените изрази така, че обратното съвпадение вече не е възможно.
Когато това се случи, окончателният план за изпълнение изглежда така, сякаш оптимизаторът е пропуснал „очевидна“ възможност да използва постоянна или индексирана изчислена колона. Има няколко подробности в плановете за изпълнение, които могат да помогнат да се определи причината, което прави този проблем потенциално разочароващ за отстраняване на грешки и отстраняване.
Съпоставяне на изрази с изчислени колони
Струва си да бъде особено ясно, че тук има два отделни процеса:
- Ранно разширяване на изчислените колони; и
- По-късни опити за съвпадение на изрази с изчислени колони.
По-специално, имайте предвид, че всеки израз на заявка може да бъде съпоставен с подходяща изчислена колона по-късно, а не само изрази, възникнали от разширяването на изчислени колони.
Съвпадението на израза на изчислените колони може да даде възможност за подобрения на плана, дори когато текстът на оригиналната заявка не може да бъде променен. Например, създаването на изчислена колона, която да съответства на известен израз на заявка, позволява на оптимизатора да използва статистически данни и индекси, свързани с изчислената колона. Тази функция е концептуално подобна на съвпадението на индексирани изгледи в Enterprise Edition. Изчисленото съвпадение на колони е функционално във всички издания.
От практическа гледна точка моят собствен опит е, че съпоставянето на общи изрази на заявка с изчислени колони наистина може да се възползва от производителността, ефективността и стабилността на плана за изпълнение. От друга страна, рядко (ако изобщо) съм намирал, че изчисленото разширение на колони си заслужава. Просто изглежда никога не дава полезни оптимизации.
Използване на изчислени колони
Изчислени колони, които не са нито едно постоянните или индексираните имат валидни употреби. Например, те могат да поддържат автоматична статистика, ако колоната е детерминирана и точна (без елементи с плаваща запетая). Те могат да се използват и за спестяване на място за съхранение (за сметка на малко допълнително използване на процесора по време на изпълнение). Като последен пример, те могат да осигурят чист начин да се гарантира, че простото изчисление винаги се извършва правилно, вместо да бъде изрично изписано в заявки всеки път.
Устойчиво изчислени колони бяха добавени към продукта специално, за да позволят индексите да бъдат изградени върху детерминирани, но "неточни" (с плаваща запетая) колони. Според моя опит това предназначение е сравнително рядко. Може би това е просто защото не срещам много данни с плаваща запетая.
Като оставим настрана индексите с плаваща запетая, постоянните колони са доста често срещани. До известна степен това може да се дължи на факта, че неопитните потребители приемат, че изчислената колона трябва винаги да бъде запазена, преди да може да бъде индексирана. По-опитните потребители могат да използват постоянни колони, просто защото са установили, че производителността обикновено е по-добра по този начин.
Индексирано изчислените колони (постоянни или не) могат да се използват за осигуряване на подреждане и ефективен метод за достъп. Може да бъде полезно да съхранявате изчислена стойност в индекс, без да я запазвате в основната таблица. По същия начин, подходящи изчислени колони могат също да бъдат включени в индекси, вместо да бъдат ключови колони.
Слаба производителност
Основна причина за лоша производителност е обикновен неуспех при използване на индексирана или постоянна стойност на изчислената колона, както се очаква. Загубих броя на въпросите, които съм имал през годините, питайки защо оптимизаторът би избрал ужасен план за изпълнение, когато съществува очевидно по-добър план, използващ индексирана или постоянна изчислена колона.
Точната причина във всеки случай варира, но почти винаги е или погрешно решение, базирано на разходите (защото на скаларите се приписва ниска фиксирана цена); или неуспех да се съпостави разширен израз обратно към постоянна изчислена колона или индекс.
Неуспехите при обратния мач са особено интересни за мен, защото често включват сложни взаимодействия с ортогонални характеристики на двигателя. Също толкова често, неуспехът за „обратно съвпадение“ оставя израз (а не колона) на позиция във вътрешното дърво на заявката, която предотвратява съвпадението на важно правило за оптимизация. И в двата случая резултатът е един и същ:неоптимален план за изпълнение.
Сега мисля, че е справедливо да се каже, че хората обикновено индексират или запазват изчислена колона със силното очакване, че съхранената стойност действително ще бъде използвана. Може да бъде доста шок да видите SQL Server да преизчислява основния израз всеки път, като същевременно игнорира съзнателно предоставената съхранена стойност. Хората не винаги се интересуват много от вътрешните взаимодействия и недостатъците на модела на разходите, които са довели до нежелания резултат. Дори когато съществуват заобиколни решения, те изискват време, умения и усилия за откриване и тестване.
Накратко:много хора просто биха предпочели SQL Server да използва постоянната или индексирана стойност. Винаги.
Нова опция
В исторически план не е имало начин да се принуди SQL Server винаги да използва съхранената стойност (няма еквивалент на NOEXPAND намек за изгледи). Има някои обстоятелства, при които ръководството за план ще работи, но не винаги е възможно да се генерира необходимата форма на плана на първо място и не всички елементи и позиции на плана могат да бъдат принудени (например филтри и изчисляване на скалари).
Все още няма чисто, напълно документирано решение, но скорошна актуализация на SQL Server 2016 предостави интересен нов подход. Прилага се за екземпляри на SQL Server 2016, закърпени с най-малко Кумулативна актуализация 2 за SQL Server 2016 SP1 или Кумулативна актуализация 4 за SQL Server 2016 RTM.
Съответната актуализация е документирана в:КОРЕКЦИЯ:Не може да се изгради отново дялът онлайн за таблица, която съдържа изчислена колона за разделяне в SQL Server 2016
Както толкова често с документацията за поддръжка, това не казва точно какво е променено в двигателя, за да се реши проблемът. Съдейки по заглавието и описанието, със сигурност не изглежда много подходящо за настоящите ни опасения. Независимо от това, тази корекция въвежда нов поддържан флаг за проследяване 176 , което се проверява в кодов метод, наречен FDontExpandPersistedCC . Както подсказва името на метода, това предотвратява разширяването на постоянна изчислена колона.
Има три важни предупреждения за това:
- Изчислената колона трябва да е постоянна . Дори ако е индексирана, колоната също трябва да бъде запазена.
- Обратното съвпадение от общи изрази на заявка към постоянни изчислени колони е деактивирано .
- Документацията не описва функцията на флага за проследяване и не го предписва за друга употреба. Ако решите да използвате флаг за проследяване 176, за да предотвратите разширяване на постоянни изчислени колони, това ще бъде на ваш собствен риск.
Този флаг за проследяване е ефективен като стартиращ –T опция, както в глобален, така и в обхват на сесията, използвайки DBCC TRACEON , и на заявка с OPTION (QUERYTRACEON) .
Пример
Това е опростена версия на въпрос (базиран на проблем от реалния свят), на който отговорих в Stack Exchange на администратори на бази данни преди няколко години. Дефиницията на таблицата включва постоянна изчислена колона:
СЪЗДАДЕТЕ ТАБЛИЦА dbo.T( ID цяло число IDENTITY NOT NULL, A varchar(20) NOT NULL, B varchar(20) НЕ NULL, C varchar(20) NOT NULL, D дата NULL, Изчислено като A + '-' + B + '-' + C ПЕРСИСТИРАН, ОГРАНИЧЕНИЕ PK_T_ID ПЪРВИЧЕН КЛУСТЕР (ID),);GOINSERT dbo.T WITH (TABLOCKX) (A, B, C, D)SELECT A =STR(SV.number % 10, 2 ), B =STR(SV.число % 20, 2), C =STR(SV.номер % 30, 2), D =DATEADD(ДЕН, 0 - SV.номер, SYSUTCDATETIME())FROM master.dbo.spt_values КАТО SVWHERE SV.[type] =N'P';
Заявката по-долу връща всички редове от таблицата в определен ред, като същевременно връща следващата стойност на колона D в същия ред:
ИЗБЕРЕТЕ T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D ОТ dbo.T AS T2, КЪДЕ T2.Computed =T1.Computed И T2.D> T1.D ПОРЪЧКА ПО T2.D ASC )ОТ dbo.T КАТО T1 ПОРЪЧКА ПО T1.Computed, T1.D;
Очевиден покриващ индекс за подкрепа на окончателното подреждане и търсене в подзаявката е:
СЪЗДАЙТЕ УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС IX_T_Computed_D_IDON dbo.T (Computed, D, ID);
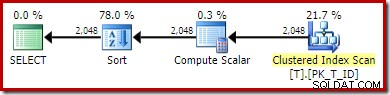
Планът за изпълнение, предоставен от оптимизатора, е изненадващ и разочароващ:
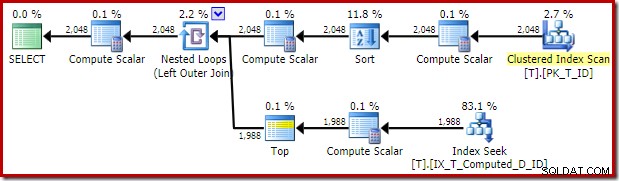
Търсенето на индекс от вътрешната страна на присъединяването на вложени цикли изглежда е добре. Сканирането и сортирането на клъстериран индекс на външния вход обаче е неочаквано. Вместо това бихме се надявали да видим подредено сканиране на нашия покриващ неклъстериран индекс.
Можем да принудим оптимизатора да използва неклъстерирания индекс с намек за таблица:
ИЗБЕРЕТЕ T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D ОТ dbo.T AS T2, КЪДЕ T2.Computed =T1.Computed И T2.D> T1.D ПОРЪЧКА ПО T2.D ASC )ОТ dbo.T КАТО T1 С (ИНДЕКС(IX_T_Computed_D_ID)) -- Ново! ПОРЪЧАЙТЕ ПО T1.Computed, T1.D;
Полученият план за изпълнение е:
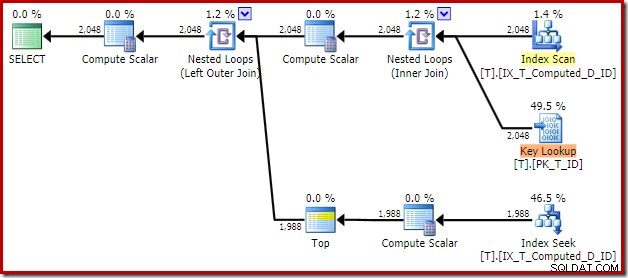
Сканирането на неклъстерирания индекс премахва сортирането, но добавя ключово търсене! Проверките в този нов план са изненадващи, като се има предвид, че нашият индекс определено покрива всички колони, необходими на заявката.
Разглеждане на свойствата на оператора Key Lookup:
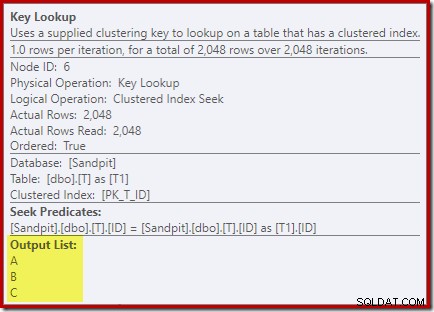
По някаква причина оптимизаторът е решил, че три колони, които не са споменати в заявката, трябва да бъдат извлечени от основната таблица (тъй като не присъстват в нашия неклъстериран индекс по дизайн).
Разглеждайки плана за изпълнение, откриваме, че търсените колони са необходими от вътрешната страна Index Seek:

Първата част от този предикат за търсене съответства на корелацията T2.Computed = T1.Computed в оригиналната заявка. Оптимизаторът разшири дефинициите и на двете изчислени колони, но успя да съвпадне само с постоянната и индексирана изчислена колона за псевдонима от вътрешната страна T1 . Напускане на T2 разширената препратка доведе до необходимостта от външната страна на съединението да предостави колоните на основната таблица (A , B и C ), необходими за изчисляване на този израз за всеки ред.
Както понякога се случва, възможно е да се пренапише тази заявка, така че проблемът да изчезне (една опция е показана в стария ми отговор на въпроса за Stack Exchange). Използвайки SQL Server 2016, можем също да опитаме флаг за проследяване 176, за да предотвратим разширяването на изчислените колони:
ИЗБЕРЕТЕ T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D ОТ dbo.T AS T2, КЪДЕ T2.Computed =T1.Computed И T2.D> T1.D ПОРЪЧКА ОТ T2.D ASC )ОТ dbo.T КАТО T1 ПОРЪЧКА ОТ T1.Computed, T1.DOPTION (QUERYTRACEON 176); -- Ново!
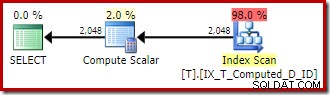
Планът за изпълнение вече е значително подобрен:
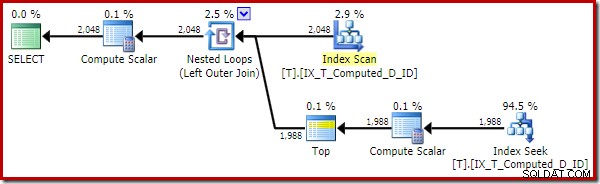
Този план за изпълнение съдържа само препратки към изчислените колони. Compute Scalars не правят нищо полезно и биха били почистени, ако оптимизаторът беше малко по-подреден в къщата.
Важният момент е, че оптималният индекс вече се използва правилно, а сортирането и търсенето по ключ са елиминирани. Всичко това като попречи на SQL Server да направи нещо, което никога не бихме очаквали да направи на първо място (разширяване на постоянна и индексирана изчислена колона).
Използване на LEAD
Първоначалният въпрос на Stack Exchange беше насочен към SQL Server 2008, където LEAD не е налично. Нека се опитаме да изразим изискването на SQL Server 2016 с помощта на по-нов синтаксис:
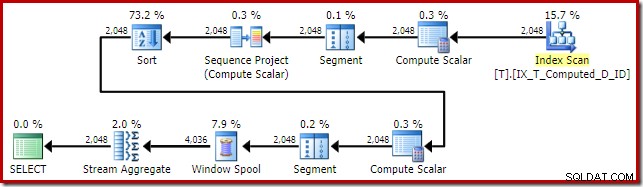
ИЗБЕРЕТЕ T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)ОТ dbo.T КАТО T1ORDER BY T1.Computed;Планът за изпълнение на SQL Server 2016 е:
Тази форма на плана е доста типична за обикновена функция на прозорец в режим на ред. Единственият неочакван елемент е операторът Sort в средата. Ако наборът от данни беше голям, това сортиране може да има голямо влияние върху производителността и използването на паметта.
Проблемът отново е изчислено разширяване на колоните. В този случай един от разширените изрази се намира в позиция, която не позволява на нормалната логика на оптимизатора да опростява сортирането.
Изпробване на точно същата заявка с флаг за проследяване 176:
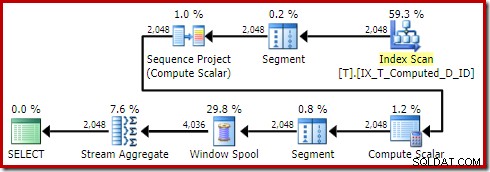
ИЗБЕРЕТЕ T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)ОТ dbo.T КАТО T1 ORDER BY T1.ComputedOPTION (QUERYTRACEON 176 );Произвежда плана:
Сортът е изчезнал както трябва. Обърнете внимание също така мимоходом, че тази заявка отговаря на изискванията за тривиален план, избягвайки изцяло оптимизация, базирана на разходите.
Деактивирано съвпадение на общия израз
Едно от предупрежденията, споменати по-рано, беше, че флагът за проследяване 176 също деактивира съвпадението от изрази в изходната заявка към постоянни изчислени колони.
За да илюстрирате, разгледайте следната версия на примерната заявка.
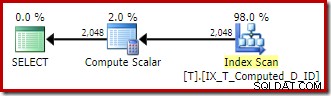
LEADизчислението е премахнато и препратките към изчислената колона вSELECTиORDER BYклаузите са заменени с основните изрази. Стартирайте го първо без флаг за проследяване 176:ИЗБЕРЕТЕ T1.ID, изчислен =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T КАТО T1 ПОРЪЧКА ОТ T1.A + '-' + T1.B + '-' + T1.C;Изразите се съпоставят с персистираната изчислена колона и планът за изпълнение е просто подредено сканиране на неклъстерирания индекс:
Compute Scalar там отново е просто остатъчен архитектурен боклук.
Сега опитайте същата заявка с активиран флаг за проследяване 176:
ИЗБЕРЕТЕ T1.ID, изчислен =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T КАТО T1 ПОРЪЧКА ОТ T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Ново!Новият план за изпълнение е:
Неклъстерното индексно сканиране е заменено с клъстерирано индексно сканиране. Скаларът за изчисляване оценява израза, а сортирането подрежда по резултата. Лишен от възможността да съпоставя изрази с постоянни изчислени колони, оптимизаторът не може да използва постоянната стойност или неклъстерирания индекс.
Имайте предвид, че ограничението за съвпадение на изрази се прилага само за постоянни изчислени колони, когато флагът за проследяване 176 е активен. Ако направим изчислената колона индексирана, но не постоянна, съвпадението на изразите работи правилно.
За да премахнем постоянния атрибут, първо трябва да премахнем неклъстерирания индекс. След като промяната е направена, можем да върнем индекса обратно (тъй като изразът е детерминистичен и точен):
ИЗПУСКАНЕ ИНДЕКС IX_T_Computed_D_ID НА dbo.T;GOALTER TABLE dbo.TALTER КОЛОНА ComputedDROP ПОСТЪПНА;GOCREATE УНИКАЛЕН НЕКЛУСТРИРАН ИНДЕКС IX_T_Computed_D_IDON dbo.T (Computed, D, ID);Оптимизаторът вече няма проблеми да съпоставя израза на заявката с изчислената колона, когато флагът за проследяване 176 е активен:
-- Изчислената колона вече не се запазва-- но все още е индексирана. TF 176 активен.ИЗБЕРЕТЕ T1.ID, изчислен =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T КАТО T1 ПОРЪЧКА ПО T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);Планът за изпълнение се връща към оптималното неклъстерно сканиране на индекс без сортиране:
За да обобщим:Флагът за проследяване 176 предотвратява постоянното разширяване на изчислената колона. Като страничен ефект, той също така предотвратява съвпадението на израза на заявката само с постоянни изчислени колони.
Метаданните на схемата се зареждат само веднъж, по време на фазата на свързване. Флаг за проследяване 176 предотвратява разширяването, така че дефиницията на изчислената колона не се зарежда по това време. По-късното съпоставяне на израз към колона не може да работи без дефиницията на изчислената колона, с която да съвпада.
Първоначалното натоварване на метаданните включва всички колони, а не само тези, посочени в заявката (тази оптимизация се извършва по-късно). Това прави всички изчислени колони достъпни за съпоставяне, което като цяло е добро нещо. За съжаление, ако една от заредените изчислени колони съдържа скаларна дефинирана от потребителя функция, нейното присъствие деактивира паралелизма за цялата заявка, дори когато проблемната колона не се използва. Флагът за проследяване 176 също може да помогне за това, ако въпросната колона е запазена. Като не се зарежда дефиницията, скаларна дефинирана от потребителя функция никога не е налице, така че паралелизмът не е деактивиран.
Последни мисли
Струва ми се, че светът на SQL Server е по-добро място, ако оптимизаторът третира постоянните или индексирани изчислени колони по-скоро като обикновени колони. В почти всички случаи това би отговаряло по-добре на очакванията на разработчиците, отколкото сегашното споразумение. Разширяването на изчислените колони в техните основни изрази и по-късно опитите да ги съпоставим обратно не е толкова успешно на практика, колкото теорията може да предполага.
Докато SQL Server не осигури специфична поддръжка за предотвратяване на постоянно или индексирано разширяване на изчислени колони, нов флаг за проследяване 176 е примамлива опция за потребителите на SQL Server 2016, макар и несъвършена. Малко е жалко, че деактивира общото съвпадение на изрази като страничен ефект. Също така е жалко, че изчислената колона трябва да бъде запазена, когато е индексирана. Тогава съществува риск от използване на флаг за проследяване за различна от документираната му цел, която трябва да се вземе предвид.
Справедливо е да се каже, че по-голямата част от проблемите с изчислените заявки за колони в крайна сметка могат да бъдат разрешени по други начини, като се има предвид достатъчно време, усилия и опит. От друга страна, флагът за проследяване 176 често изглежда работи като магия. Изборът, както се казва, е ваш.
За да завършим, ето някои интересни проблеми с изчислените колони, които се възползват от флаг за проследяване 176:
- Изчисленият индекс на колона не се използва
- ПЕРСИСТирана изчислена колона, която не се използва при разделянето на функциите на прозорец
- Устойчива изчислена колона, причиняваща сканиране
- Изчисленият индекс на колона не се използва с MAX типове данни
- Сериозен проблем с производителността с постоянни изчислени колони и присъединявания
- Защо SQL Server „изчислява скаларен“, когато ИЗБИРАМ постоянна изчислена колона?
- Базови колони, използвани вместо постоянни изчислени колони от машина
- Изчислената колона с UDF деактивира паралелизма за заявки към *други* колони