Разработчик на Oracle, който често използва регулярни изрази в кода, рано или късно може да се сблъска с явление, което наистина е мистично. Дългосрочното търсене на корена на проблема може да доведе до загуба на тегло, апетит и да провокира различни видове психосоматични разстройства – всичко това може да бъде предотвратено с помощта на функцията regexp_replace. Може да има до 6 аргумента:
REGEXP_REPLACE (
- изходен_низ,
- шаблон,
- заместващ_низ,
- начална позиция на търсенето на съвпадение с шаблон (по подразбиране 1),
- позиция на срещане на шаблона в изходен низ (по подразбиране 0 е равно на всички срещания),
- модификатор (засега е тъмен кон)
)
Връща модифицирания източник_низ, в който всички срещания на шаблона се заменят със стойността, предадена в параметъра substituting_string. Често се използва кратка версия на функцията, където са посочени първите 3 аргумента, което е достатъчно за решаване на много проблеми. Ще направя същото. Да предположим, че трябва да маскираме всички символи на низа със звездички в низа „МАСКА:малки букви“. За да посочите обхвата на малките букви, трябва да отговаря шаблонът „[a-z]“.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Очакване
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Реалност
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Ако това събитие не е възпроизведено във вашата база данни, значи имате късмет досега. Но по-често започвате да ровите в код, преобразувате низове от един набор от знаци в друг и в крайна сметка идва отчаянието.
Дефиниране на проблем
Възниква въпросът – какво е толкова специалното на буквата „А“, че тя не е заменена, защото останалите главни букви също не е трябвало да бъдат заменени. Може би има други правилни букви освен тази. Необходимо е да се разгледа цялата азбука на главните букви.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Въпреки това
Ако 6-ти аргумент на функцията не е изрично посочен, например, 'i' е нечувствителност към главни и малки букви или 'c' е чувствителност към малки и големи букви при сравняване на изходен низ с шаблон, регулярният израз използва параметъра NLS_SORT на сесията/базата данни по подразбиране. Например:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Този параметър определя метода на сортиране в ORDER BY. Ако говорим за сортиране на прости отделни знаци, тогава на всеки от тях съответства определено двоично число (NLSSORT-код) и сортирането всъщност става по стойността на тези числа.
За да илюстрираме това, нека вземем първите и последните няколко знака от азбуката, както малки, така и главни, и да ги поставим в условно неподреден набор от таблица и да го наречем ABC. След това нека сортираме този набор по полето SYMBOL и показваме неговия NLSSORT-код в HEX формат до всеки символ.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
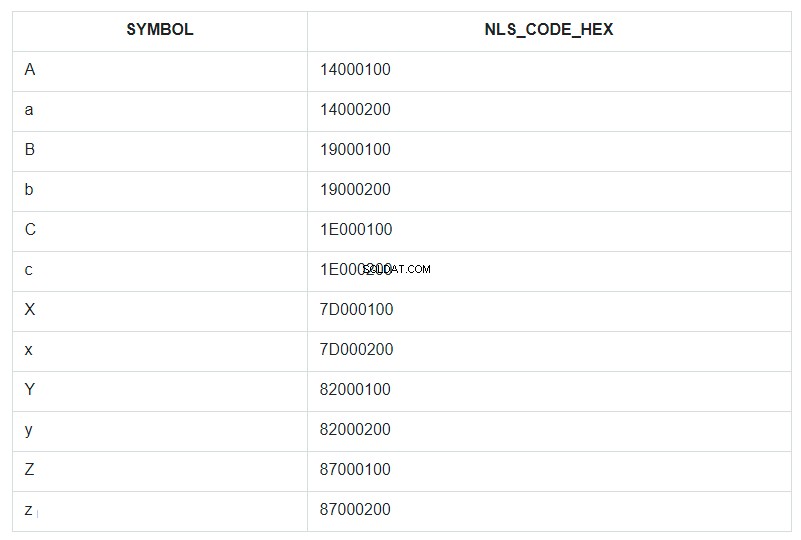
В заявката се посочва ORDER BY за полето SYMBOL, но всъщност в базата данни сортирането е преминало по стойностите от полето NLS_CODE_HEX.
Сега се върнете към диапазона от шаблона и погледнете таблицата – какво е вертикално между символа „a“ (код 14000200) и „z“ (код 87000200)? Всичко освен главната буква „А“. Това е всичко, което е заменено със звездичка. А кодът 14000100 на буквата „А“ не е включен в диапазона за замяна от 14000200 до 87000200.
Излекуване
Изрично посочете модификатора за чувствителност на малки и малки букви
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Някои източници казват, че модификаторът „c“ е зададен по подразбиране, но току-що видяхме, че това не е съвсем вярно. И ако някой не го е видял, тогава параметърът NLS_SORT на неговата сесия/база данни най-вероятно е настроен на BINARY и сортирането се извършва в съответствие с реални кодове на знаци. Всъщност, ако промените параметъра на сесията, проблемът ще бъде решен.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Тестовете бяха проведени в Oracle 12c.
Чувствайте се свободни да оставяте вашите коментари и се погрижете.