Всички вие сте чували за мащабирането - вашата архитектура трябва да бъде мащабируема, трябва да можете да увеличавате мащаба, за да посрещнете търсенето, така нататък и така нататък. Какво означава това, когато говорим за бази данни? Как изглежда мащабирането зад кулисите? Тази тема е обширна и няма начин да се обхванат всички аспекти. Тази серия от публикации в два блога е опит да ви даде представа за темата за мащабируемостта на базата данни.
Защо мащабираме?
Първо, нека да разгледаме какво представлява мащабируемостта. Накратко, ние говорим за способността да се справят с по-голямо натоварване от вашите системи за бази данни. Може да е въпрос на справяне с краткотрайни пикове в дейността, може да е въпрос на справяне с постепенно нарастващо натоварване в средата на вашата база данни. Може да има много причини да обмислите мащабиране. Повечето от тях идват със собствените си предизвикателства. Можем да прекараме известно време в разглеждане на примери за ситуацията, в която може да искаме да се разширим.
Увеличаване на потреблението на ресурси
Това е най-общото – натоварването ви се е увеличило до точката, в която съществуващите ви ресурси вече не са в състояние да се справят с него. Може да е всичко. Натоварването на процесора се е увеличило и вашият клъстер от база данни вече не е в състояние да доставя данни с разумно и стабилно време за изпълнение на заявката. Използването на паметта нарасна до степен, че базата данни вече не е свързана с процесора, а стана I/O-обвързана и като такава производителността на възлите на базата данни е значително намалена. Мрежата може да бъде и вратна врата. Може да се изненадате да видите какви ограничения, свързани с работата в мрежа, са присвоени на вашите облачни екземпляри. Всъщност това може да се превърне в най-често срещаното ограничение, с което трябва да се справите, тъй като мрежата е всичко в облака – не само данните, изпращани между приложението и базата данни, но също така и съхранението е прикрепено през мрежата. Може да е и използване на диск - просто ви липсва дисково пространство или, по-вероятно, като се има предвид, че в днешно време можем да имаме доста големи дискове, размерът на базата данни надвишава "управляемия" размер. Поддръжката като промяна на схемата се превръща в предизвикателство, производителността е намалена поради размера на данните, архивирането отнема години, за да се завърши. Всички тези случаи може да са валиден случай за необходимост от увеличаване на мащаба.
Внезапно увеличаване на натоварването
Друг примерен случай, в който се изисква мащабиране, е внезапно увеличаване на натоварването. По някаква причина (независимо дали става дума за маркетингови усилия, вирусно съдържание, извънредна или подобна ситуация) вашата инфраструктура изпитва значително увеличение на натоварването на клъстера на базата данни. Натоварването на процесора надхвърля покрива, дисковият I/O забавя заявките и т.н. Почти всеки ресурс, който споменахме в предишния раздел, може да бъде претоварен и да започне да създава проблеми.
Планирана операция
Третата причина, която бихме искали да подчертаем, е по-общата – някаква планирана операция. Това може да бъде планирана маркетингова дейност, която очаквате да донесе повече трафик, Черен петък, тестване на натоварване или почти всичко, което знаете предварително.
Всяка от тези причини има свои собствени характеристики. Ако можете да планирате предварително, можете да подготвите процеса в детайли, да го тествате и да го изпълнявате, когато пожелаете. Най-вероятно ще искате да го правите в период на „нисък трафик“, стига нещо подобно да съществува във вашите работни натоварвания (не е задължително да съществува). От друга страна, внезапните скокове в натоварването, особено ако са достатъчно значителни, за да повлияят на производството, ще принудят незабавна реакция, без значение колко сте подготвени и колко е безопасно - ако услугите ви вече са засегнати, можете просто направете го, вместо да чакате.
Типове мащабиране на базата данни
Има два основни типа мащабиране:вертикално и хоризонтално. И двете имат плюсове и минуси, и двете са полезни в различни ситуации. Нека да ги разгледаме и да обсъдим случаите на употреба и за двата сценария.
Вертикално мащабиране
Този метод за мащабиране е може би най-старият:ако хардуерът ви не е достатъчно мощен, за да се справи с натоварването, увеличете го. Тук говорим просто за добавяне на ресурси към съществуващи възли с намерението да ги направим достатъчно способни да се справят с поставените задачи. Това има някои последици, които бихме искали да разгледаме.
Предимства на вертикалното мащабиране
Най-важното е, че всичко остава същото. Имахте три възела в клъстер на база данни, все още имате три възела, само по-способни. Няма нужда да препроектирате вашата среда, да променяте начина, по който приложението трябва да осъществява достъп до базата данни - всичко остава абсолютно същото, защото по отношение на конфигурацията нищо не се е променило.
Друго значително предимство на вертикалното мащабиране е, че то може да бъде много бързо, особено в облачни среди. Целият процес е до голяма степен да спрете съществуващия възел, да направите промяна в хардуера, да стартирате възела отново. За класически, on-prem настройки, без никаква виртуализация, това може да е трудно - може да не разполагате с по-бърз процесор за смяна, надграждането на дискове до по-големи или по-бързи също може да отнеме време, но за облачни среди, независимо дали е публична или частна, това може да бъде толкова лесно, колкото да изпълните три команди:спиране на екземпляра, надграждане на екземпляр до по-голям размер, стартиране на екземпляр. Виртуалните IP адреси и томовете с възможност за повторно прикачване улесняват преместването на данни между екземпляри.
Недостатъци на вертикалното мащабиране
Основният недостатък на вертикалното мащабиране е, че просто има своите граници. Ако работите с най-големия наличен размер на екземпляра, с най-бързите дискови томове, не можете да направите много друго. Също така не е толкова лесно да увеличите значително производителността на клъстера от база данни. Това зависи най-вече от първоначалния размер на екземпляра, но ако вече използвате доста производителни възли, може да не успеете да постигнете 10x мащабиране с помощта на вертикално мащабиране. Възли, които биха били 10 пъти по-бързи, може просто да не съществуват.
Хоризонтално мащабиране
Хоризонталното мащабиране е различен звяр. Вместо да се увеличаваме с размера на екземпляра, оставаме на същото ниво, но разширяваме хоризонтално, като добавяме още възли. Отново има плюсове и минуси на този метод.
Плюсове на хоризонталното мащабиране
Основното предимство на хоризонталното мащабиране е, че теоретично небето е границата. Няма изкуствено твърдо ограничение на мащабиране, въпреки че ограниченията съществуват, главно поради факта, че комуникацията в клъстера е все по-голяма и по-голяма с всеки нов възел, добавен към клъстера.
Друго значително предимство би било, че можете да разширите клъстера, без да имате нужда от престой. Ако искате да надстроите хардуера, трябва да спрете екземпляра, да го надстроите и след това да започнете отново. Ако искате да добавите още възли към клъстера, всичко, което трябва да направите, е да осигурите тези възли, да инсталирате какъвто и да е софтуер, от който се нуждаете, включително базата данни, и да го оставите да се присъедини към клъстера. По избор (в зависимост от това дали клъстерът има вътрешни методи за предоставяне на нови възли с данните) може да се наложи да го осигурите с данни сами. Обикновено обаче това е автоматизиран процес.
Недостатъци на хоризонталното мащабиране
Основният проблем, с който трябва да се справите, е, че добавянето на все повече и повече възли затруднява управлението на цялата среда. Трябва да можете да кажете кои възли са налични, такъв списък трябва да се поддържа и актуализира с всеки създаден нов възел. Може да имате нужда от външни решения като услуга за директории (Consul или Etcd), за да следите възлите и тяхното състояние. Това, очевидно, увеличава сложността на цялата среда.
Друг потенциален проблем е, че процесът на мащабиране отнема време. Добавянето на нови възли и осигуряването им със софтуер и особено данни изисква време. Колко зависи от хардуера (главно входно/изходна и мрежова пропускателна способност) и размера на данните. За големи настройки това може да отнеме значително време и това може да бъде блокиращо за ситуации, при които мащабирането трябва да се случи незабавно. Часовете на изчакване за добавяне на нови възли може да не са приемливи, ако клъстерът на базата данни е засегнат до степен, че операциите не се изпълняват правилно.
Предварителни условия за мащабиране
Репликация на данни
Преди да бъде направен опит за мащабиране, вашата среда трябва да отговаря на няколко изисквания. Като начало, вашето приложение трябва да може да се възползва от повече от един възел. Ако може да използва само един възел, вашите опции са почти ограничени до вертикално мащабиране. Можете да увеличите размера на такъв възел или да добавите някои хардуерни ресурси към голия сървър и да го направите по-производителен, но това е най-доброто, което можете да направите:винаги ще бъдете ограничени от наличието на по-ефективен хардуер и в крайна сметка ще откриете себе си без опция за по-нататъшно увеличаване.
От друга страна, ако имате средствата да използвате множество възли на база данни от вашето приложение, можете да се възползвате от хоризонталното мащабиране. Нека спрем до тук и да обсъдим какво ви е необходимо, за да използвате множество възли до пълния им потенциал.
За начало, възможността за разделяне на четения от записвания. Традиционно приложението се свързва само с един възел. Този възел се използва за обработка на всички записи и всички четения, изпълнени от приложението.

Добавянето на втори възел към клъстера от гледна точка на мащабирането не променя нищо . Трябва да имате предвид, че ако един възел не успее, другият ще трябва да се справи с трафика, така че в нито един момент сумата на натоварването на двата възела не трябва да е твърде висока, за да може един единствен възел да се справи.

С три налични възела можете да използвате напълно два възела. Това ни позволява да мащабираме част от трафика за четене:ако един възел има 100% капацитет (а ние предпочитаме да работим най-много 70%), тогава два възела представляват 200%. Три възела:300%. Ако един възел не работи и ако натиснем останалите възли почти до границата, можем да кажем, че можем да работим със 170 - 180% от капацитета на един възел, ако клъстерът е влошен. Това ни дава хубави 60% натоварване на всеки възел, ако и трите възела са налични.
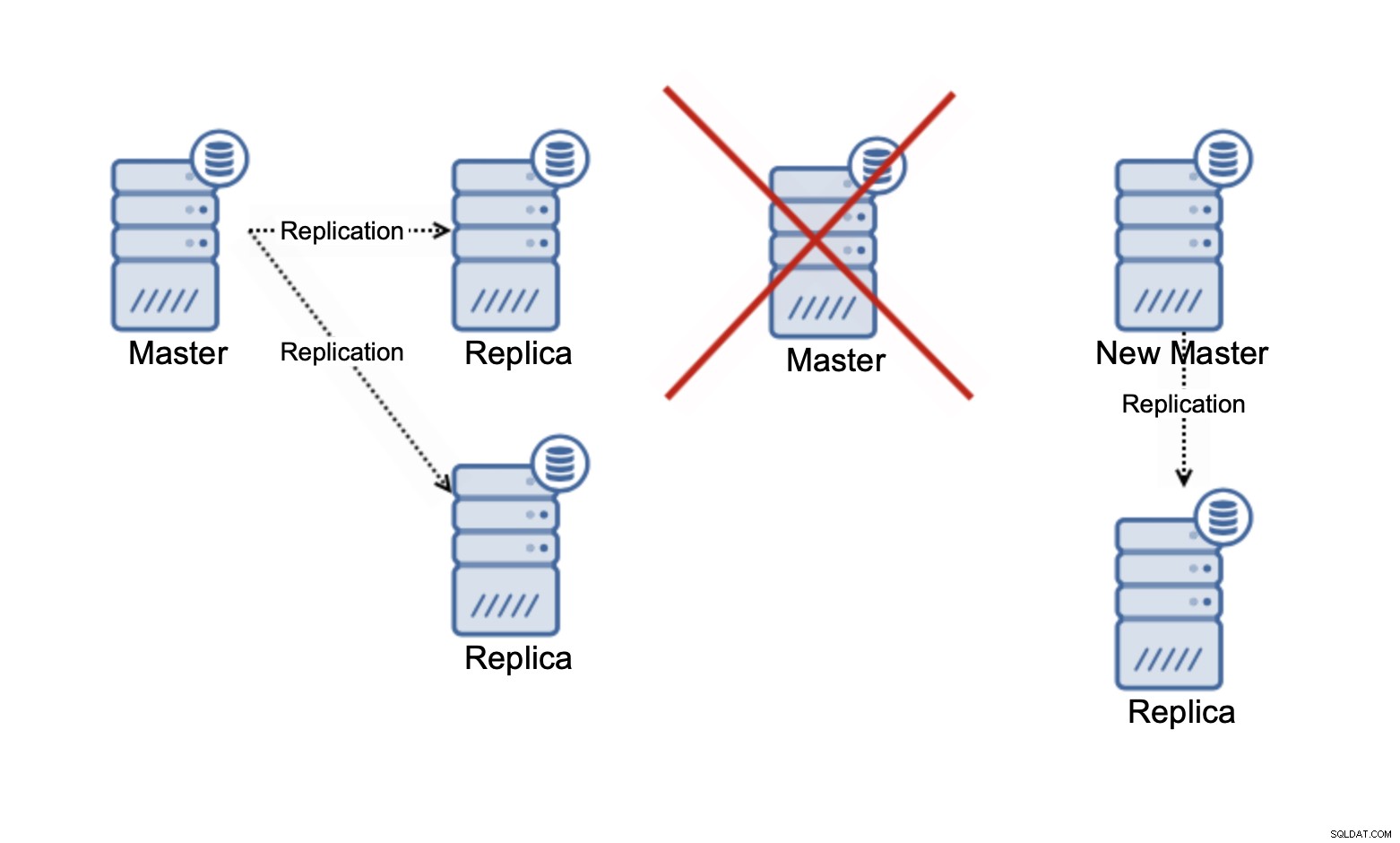
Моля, имайте предвид, че в момента говорим само за мащабиране на прочитанията . В нито един момент репликацията може да подобри капацитета ви за запис. При асинхронна репликация имате само един записващ (главен), а за синхронната репликация, като Galera, където наборът от данни се споделя между всички възли, всяко записване, което се случва на един възел, ще трябва да се извърши на останалите възли на клъстер.
В клъстер Galera с три възела, ако пишете един ред, вие всъщност пишете три реда, по един за всеки възел. Добавянето на повече възли или реплики няма да направи разлика. Вместо да пишете един и същ ред на три възела, ще го напишете на пет. Ето защо разделянето на вашите записи в клъстер с няколко главни, където наборът от данни се споделя между всички възли (има клъстери с множество главни, където данните се разделят, например MySQL NDB Cluster - тук историята на мащабируемостта на запис е напълно различна), няма много смисъл. Той добавя допълнителни разходи за справяне с потенциални конфликти при запис във всички възли, докато всъщност не променя нищо по отношение на общия капацитет за запис.
Балансиране на натоварването и разделяне на четене/запис
Възможността за разделяне на четения от записвания е задължителна, ако искате да мащабирате своите четения в настройки за асинхронна репликация. Трябва да можете да изпращате трафик за запис до един възел и след това да изпращате четенията до всички възли в топологията на репликация. Както споменахме по-рано, тази функционалност също е доста полезна в клъстерите с множество главни, тъй като ни позволява да премахнем конфликтите при запис, които могат да възникнат, ако се опитате да разпределите записите между множество възли в клъстера. Как можем да извършим разделянето на четене/запис? Има няколко метода, които можете да използвате, за да го направите. Нека се задълбочим в тази тема за малко.
Разделяне на R/W ниво на приложение
Най-простият сценарий, както и най-рядко срещаният:вашето приложение може да бъде конфигурирано кои възли да получават записи и кои възли да получават четене. Тази функционалност може да бъде конфигурирана по няколко начина, като най-простият е твърдо кодираният списък на възлите, но също така може да бъде нещо подобно на динамичния инвентар на възли, актуализиран от фонови нишки. Основният проблем с този подход е, че цялата логика трябва да бъде написана като част от приложението. С твърдо кодиран списък от възли, най-простият сценарий ще изисква промени в кода на приложението за всяка промяна в топологията на репликация. От друга страна, по-напреднали решения като внедряване на откриване на услуга биха били по-сложни за поддържане в дългосрочен план.
R/W разделен в конектора
Друга опция би била да се използва конектор за извършване на разделяне на четене/запис. Не всички имат тази опция, но някои имат. Пример би бил php-mysqlnd или Connector/J. Как е интегриран в приложението, може да се различава в зависимост от самия конектор. В някои случаи конфигурирането трябва да се направи в приложението, в някои случаи трябва да се направи в отделен конфигурационен файл за конектора. Предимството на този подход е, че дори ако трябва да разширите приложението си, по-голямата част от новия код е готова за използване и поддържана от външни източници. Това улеснява справянето с такава настройка и трябва да пишете по-малко код (ако има такъв).
Разделяне на R/W в loadbalancer
Накрая, едно от най-добрите решения:балансиране на натоварването. Идеята е проста - прехвърлете данните си през балансиране на натоварването, което ще може да прави разлика между четене и запис и да ги изпраща на правилното място. Това е голямо подобрение от гледна точка на използваемостта, тъй като можем да отделим откриването на база данни и маршрутизирането на заявки от приложението. Единственото нещо, което приложението трябва да направи, е да изпрати трафика на базата данни към една крайна точка, която се състои от име на хост и порт. Останалото се случва на заден план. Балансьорите на натоварване работят, за да насочват заявките към възлите на базата данни в бекенда. Балансьорите на натоварване могат също да извършват откриване на топология на репликация или можете да внедрите правилна инвентаризация на услуги, като използвате etcd или consul и да я актуализирате чрез инструментите за оркестриране на инфраструктурата като Ansible.
Това завършва първата част на този блог. Във втория ще обсъдим предизвикателствата, пред които сме изправени при мащабиране на нивото на базата данни. Ще обсъдим също някои начини, по които можем да мащабираме нашите клъстери от база данни.