SQL Server 2008 въведе редки колони като метод за намаляване на съхранението за нулеви стойности и предоставяне на по-разширяеми схеми. Компромисът е, че има допълнителни разходи, когато съхранявате и извличате стойности, различни от NULL. Заинтересувах се да разбера цената за съхраняване на стойности, различни от NULL, след като разговарях с клиент, който използва този тип данни в промежуточна среда. Те търсят да оптимизират производителността на запис и се чудех дали използването на редки колони има някакъв ефект, тъй като техният метод изискваше вмъкване на ред в таблицата и след това актуализиране. Създадох измислен пример за тази демонстрация, обяснен по-долу, за да определя дали това е добра методология, която те могат да използват.
Вътрешен преглед
Като бърз преглед не забравяйте, че когато създавате колона за таблица, която позволява NULL стойности, ако тя е колона с фиксирана дължина (напр. INT), тя винаги ще използва цялата ширина на колоната на страницата, дори когато колоната е НУЛА. Ако е колона с променлива дължина (напр. VARCHAR), тя ще консумира най-малко два байта в масива за отместване на колони, когато е NULL, освен ако колоните не са след последната попълнена колона (вижте публикацията в блога на Кимбърли Редът на колоните няма значение...по принцип , но – ЗАВИСИ). Рядката колона не изисква никакво пространство на страницата за NULL стойности, независимо дали е колона с фиксирана дължина или с променлива дължина и независимо от това какви други колони са попълнени в таблицата. Компромисът е, че когато се попълни разредена колона, тя отнема четири (4) повече байта място за съхранение, отколкото колона, която не е разредена. Например:
| Тип колона | Изискване за съхранение |
|---|---|
| Колона BIGINT, не рядка, с не стойност | 8 байта |
| Колона BIGINT, не рядка, с стойност | 8 байта |
| BIGINT колона, рядка, с не стойност | 0 байта |
| BIGINT колона, рядка, с стойност | 12 байта |
Ето защо е от съществено значение да се потвърди, че ползата от съхранението надвишава потенциалния удар на производителността от извличането – което може да е незначително въз основа на баланса на четене и запис спрямо данните. Очакваните спестявания на място за различни типове данни са документирани в предоставената по-горе връзка за книги онлайн.
Сценарии за тестване
Зададох четири различни сценария за тестване, описани по-долу, и всяка таблица имаше колона ID (INT), колона Name (VARCHAR(100)) и колона Type (INT), а след това 997 NULLABLE колони.
| Идентификатор на теста | Описание на таблицата | DML операции |
|---|---|---|
| 1 | 997 колони от тип данни INT, NULLABLE, неразредени | Вмъквайте един ред наведнъж, като попълвате ID, Име, Тип и десет (10) произволни NULLABLE колони |
| 2 | 997 колони от тип данни INT, NULLABLE, рядко | Вмъквайте един ред наведнъж, като попълвате ID, Име, Тип и десет (10) произволни NULLABLE колони |
| 3 | 997 колони от тип данни INT, NULLABLE, неразредени | Вмъквайте един ред наведнъж, като попълвате само ID, Име, Тип, след което актуализирайте реда, добавяйки стойности за десет (10) произволни NULLABLE колони |
| 4 | 997 колони от тип данни INT, NULLABLE, рядко | Вмъквайте един ред наведнъж, като попълвате само ID, Име, Тип, след което актуализирайте реда, добавяйки стойности за десет (10) произволни NULLABLE колони |
| 5 | 997 колони от тип данни VARCHAR, NULLABLE, неразредени | Вмъквайте един ред наведнъж, като попълвате ID, Име, Тип и десет (10) произволни NULLABLE колони |
| 6 | 997 колони от тип данни VARCHAR, NULLABLE, рядко | Вмъквайте един ред наведнъж, като попълвате ID, Име, Тип и десет (10) произволни NULLABLE колони |
| 7 | 997 колони от тип данни VARCHAR, NULLABLE, неразредени | Вмъквайте един ред наведнъж, като попълвате само ID, Име, Тип, след което актуализирайте реда, добавяйки стойности за десет (10) произволни NULLABLE колони |
| 8 | 997 колони от тип данни VARCHAR, NULLABLE, рядко | Вмъквайте един ред наведнъж, като попълвате само ID, Име, Тип, след което актуализирайте реда, добавяйки стойности за десет (10) произволни NULLABLE колони |
Всеки тест беше проведен два пъти с набор от данни от 10 милиона реда. Прикачените скриптове могат да се използват за възпроизвеждане на тестване, като стъпките бяха както следва за всеки тест:
- Създайте нова база данни с предварително оразмерени данни и регистрационни файлове
- Създайте подходящата таблица
- Статистика за изчакване на моментна снимка и статистика за файлове
- Отбележете началния час
- Изпълнете DML (едно вмъкване или едно вмъкване и една актуализация) за 10 милиона реда
- Отбележете времето за спиране
- Статистика за изчакване на моментна снимка и статистически данни за файла и запис в таблица за регистриране в отделна база данни в отделно хранилище
- Моментна снимка dm_db_index_physical_stats
- Изхвърлете базата данни
Тестването беше извършено на Dell PowerEdge R720 с 64GB памет и 12GB, разпределени за SQL Server 2014 SP1 CU4 екземпляр. Fusion-IO SSD бяха използвани за съхранение на данни за файловете на базата данни.
Резултати
Резултатите от теста са представени по-долу за всеки тестов сценарий.
Продължителност
Във всички случаи е необходимо по-малко време (средно 11,6 минути) за попълване на таблицата, когато са използвани редки колони, дори когато редът е бил вмъкнат за първи път, след това актуализиран. Когато редът беше вмъкнат за първи път и след това актуализиран, тестът отне почти два пъти повече време за изпълнение в сравнение с момента, когато редът беше вмъкнат, тъй като бяха изпълнени два пъти повече модификации на данни.
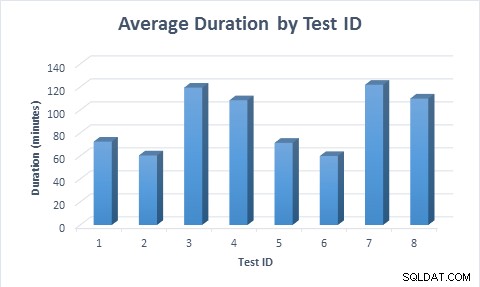 Средна продължителност за всеки тестов сценарий
Средна продължителност за всеки тестов сценарий
Изчакайте статистика
| Идент. № на теста | Среден процент | Средно изчакване (секунди) |
|---|---|---|
| 1 | 16.47 | 0,0001 |
| 2 | 14.00 | 0,0001 |
| 3 | 16,65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12,80 | 0,0001 |
| 6 | 13,99 | 0,0001 |
| 7 | 14,85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Статистиката за чакане беше последователна за всички тестове и не могат да се направят заключения въз основа на тези данни. Хардуерът отговаряше в достатъчна степен на изискванията за ресурси във всички тестови случаи.
Файлова статистика
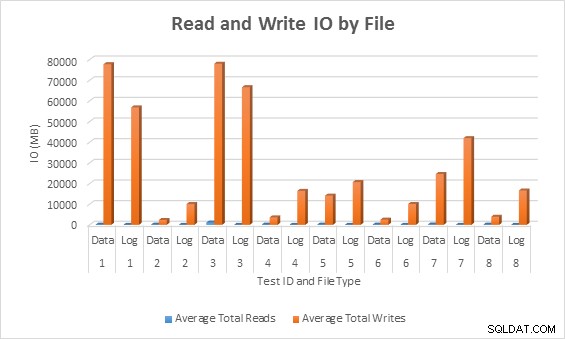 Средно IO (четене и запис) на файл с база данни
Средно IO (четене и запис) на файл с база данни
Във всички случаи тестовете с разредени колони генерираха по-малко IO (особено записвания) в сравнение с колоните, които не са разредени.
Индексни физически статистически данни
| Тестов случай | Брой редове | Общ брой страници (клъстериран индекс) | Общо пространство (GB) | Средно пространство, използвано за листни страници в CI (%) | Среден размер на записа (байтове) |
|---|---|---|---|---|---|
| 1 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4 184,49 |
| 2 | 10 000 000 | 301 429 | 2 | 98,51 | 237,50 |
| 3 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4 184,50 |
| 4 | 10 000 000 | 460 960 | 3 | 64.41 | 237,50 |
| 5 | 10 000 000 | 1 823 083 | 13 | 90,31 | 1326,08 |
| 6 | 10 000 000 | 324 162 | 2 | 98,40 | 255.28 |
| 7 | 10 000 000 | 3 161 224 | 24 | 52.09 | 1326,39 |
| 8 | 10 000 000 | 503 592 | 3 | 63.33 | 255.28 |
Съществуват значителни разлики в използването на пространството между неразредените и разредените таблици. Това е най-забележимо, когато се разглеждат тестови случаи 1 и 3, където е използван тип данни с фиксирана дължина (INT), в сравнение с тестови случаи 5 и 7, където е използван тип данни с променлива дължина (VARCHAR(255)). Целочислените колони консумират дисково пространство дори когато са NULL. Колоните с променлива дължина заемат по-малко дисково пространство, тъй като само два байта се използват в офсетния масив за NULL колони и никакви байтове за тези NULL колони, които са след последната попълнена колона в реда.
Освен това процесът на вмъкване на ред и след това актуализирането му причинява фрагментация за теста с колона с променлива дължина (случай 7), в сравнение с простото вмъкване на реда (случай 5). Размерът на таблицата почти се удвоява, когато вмъкването е последвано от актуализацията, поради разделянето на страниците, което възниква при актуализиране на редовете, което оставя страниците наполовина пълни (срещу 90% пълни).
Резюме
В заключение виждаме значително намаляване на дисковото пространство и IO, когато се използват редки колони и те се представят малко по-добре от нередките колони в нашите прости тестове за модификация на данни (обърнете внимание, че производителността на извличане също трябва да се има предвид; може би предмет на друг пост).
Редките колони имат много специфичен сценарий на използване и е важно да се проучи количеството спестено дисково пространство въз основа на типа данни за колоната и броя на колоните, които обикновено ще се попълват в таблицата. В нашия пример имахме 997 редки колони и попълнихме само 10 от тях. Най-много в случай, че използвания тип данни е цяло число, ред на ниво лист на клъстерирания индекс ще консумира 188 байта (4 байта за идентификатора, 100 байта максимум за името, 4 байта за типа и след това 80 байта за 10 колони). Когато 997 колони не са били разредени, тогава за всяка колона са били разпределени 4 байта, дори когато е NULL, така че всеки ред е бил поне 4000 байта на ниво лист. В нашия сценарий редките колони са абсолютно приемливи. Но ако попълним 500 или повече редки колони със стойности за колона INT, тогава спестяването на място се губи и производителността на модификацията може вече да не е по-добра.
В зависимост от типа данни за вашите колони и очаквания брой колони, които трябва да бъдат попълнени от общия брой, може да искате да извършите подобно тестване, за да се уверите, че когато използвате редки колони, производителността и съхранението на вмъкване са сравними или по-добри, отколкото при използване на не -редки колони. За случаите, когато не всички колони са попълнени, редките колони определено си струва да се обмислят.