Когато работите по проект, който се състои от много микроуслуги, той вероятно ще включва и множество бази данни.
Например, може да имате база данни MySQL и база данни PostgreSQL, като и двете работят на отделни сървъри.
Обикновено, за да обедините данните от двете бази данни, ще трябва да въведете нова микроуслуга, която ще обедини данните заедно. Но това би увеличило сложността на системата.
В този урок ще използваме Materialize, за да се присъединим към MySQL и Postgres в материализиран изглед на живо. След това ще можем да го направим директно и да получим резултати от двете бази данни в реално време, използвайки стандартен SQL.
Materialize е достъпна за източник база данни за поточно предаване, написана на Rust, която поддържа резултатите от SQL заявка (материализиран изглед) в паметта при промяна на данните.
Урокът включва демонстрационен проект, който можете да започнете с docker-compose .
Демо проектът, който ще използваме, ще наблюдава поръчките на нашия фалшив уебсайт. Той ще генерира събития, които по-късно могат да се използват за изпращане на известия, когато количката е била изоставена за дълго време.
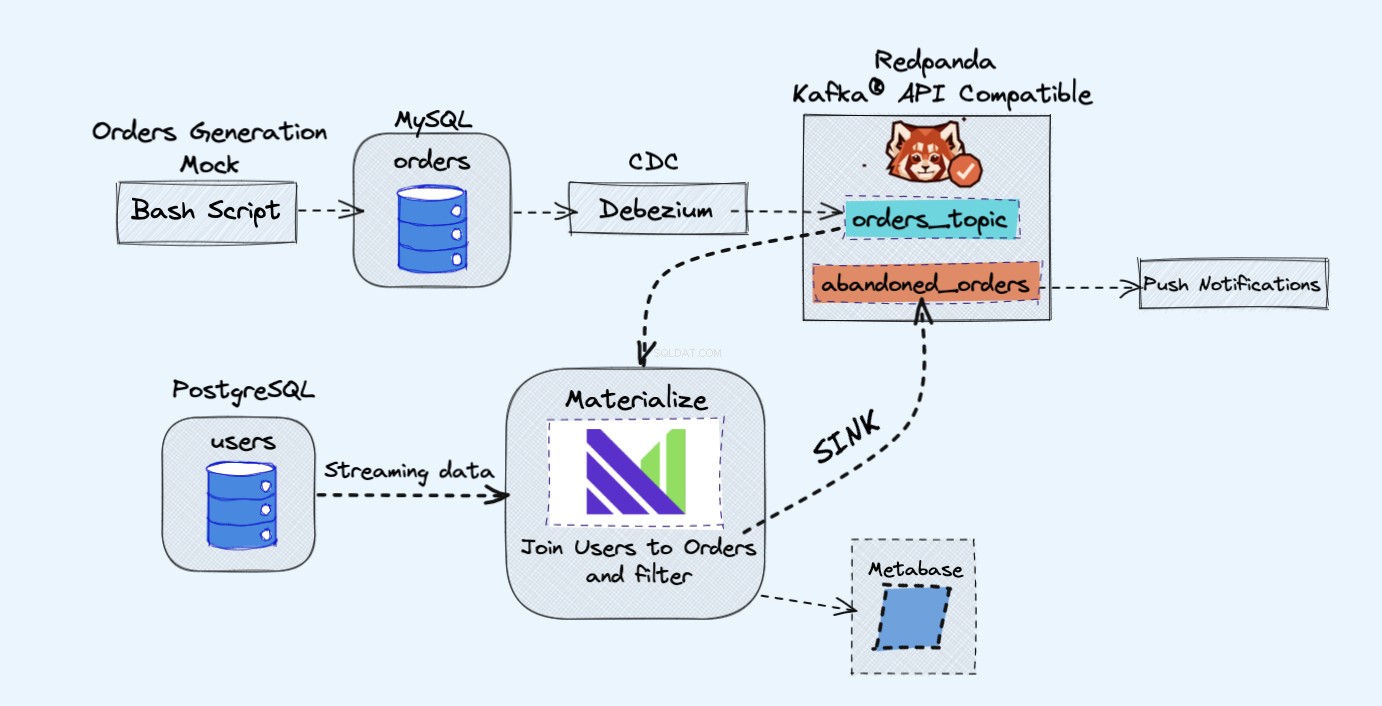
Архитектурата на демонстрационния проект е следната:
Предварителни условия
Всички услуги, които ще използваме в демонстрацията, ще работят в Docker контейнери, така че няма да се налага да инсталирате никакви допълнителни услуги на вашия лаптоп или сървър, вместо Docker и Docker Compose.
В случай, че нямате вече инсталирани Docker и Docker Compose, можете да следвате официалните инструкции как да направите това тук:
- Инсталирайте Docker
- Инсталирайте Docker Compose
Общ преглед
Както е показано на диаграмата по-горе, ще имаме следните компоненти:
- Фактна услуга за непрекъснато генериране на поръчки.
- Поръчките ще се съхраняват в база данни на MySQL .
- При извършване на записите в базата данни, Debezium прехвърля промените от MySQL към Redpanda тема.
- Ще имаме и Postgres база данни, където можем да намерим нашите потребители.
- След това ще включим тази тема на Redpanda в Materialize директно заедно с потребителите от базата данни Postgres.
- В Materialize ще обединим нашите поръчки и потребители, ще направим малко филтриране и ще създадем материализиран изглед, който показва информацията за изоставената количка.
- След това ще създадем приемник, за да изпратим данните за изоставената количка към нова тема на Redpanda.
- Накрая ще използваме Metabase за да визуализирате данните.
- По-късно можете да използвате информацията от тази нова тема, за да изпращате известия до потребителите си и да им напомняте, че имат изоставена количка.
Като странична бележка тук би било напълно добре да използвате Kafka вместо Redpanda. Просто ми харесва простотата, която Redpanda внася на масата, тъй като можете да стартирате един екземпляр на Redpanda вместо всички компоненти на Kafka.
Как да стартирате демонстрацията
Първо, започнете с клониране на хранилището:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
След това можете да получите достъп до директорията:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Нека започнем, като първо стартираме контейнера Redpanda:
docker-compose up -d redpanda
Изградете изображенията:
docker-compose build
Накрая стартирайте всички услуги:
docker-compose up -d
За да стартирате Materialize CLI, можете да изпълните следната команда:
docker-compose run mzcli
Това е просто пряк път към Docker контейнер с postgres-client предварително инсталиран. Ако вече имате psql можете да стартирате psql -U materialize -h localhost -p 6875 materialize вместо това.
Как да създадете материализиращ източник на Kafka
Сега, когато сте в Materialize CLI, нека дефинираме orders таблици в mysql.shop база данни като източници на Redpanda:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Ако трябва да проверите наличните колони от orders източник, като изпълните следния оператор:
SHOW COLUMNS FROM orders;
Ще можете да видите, че тъй като Materialize извлича данните за схемата на съобщенията от регистъра Redpanda, той знае типовете колони, които да използва за всеки атрибут:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Как да създавате материализирани изгледи
След това ще създадем първия си материализиран изглед, за да получим всички данни от orders Източник на Redpanda:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Вече можете да използвате SELECT * FROM abandoned_orders; за да видите резултатите:
SELECT * FROM abandoned_orders;
За повече информация относно създаването на материализирани изгледи, вижте раздела Материализирани изгледи в документацията на Materialize.
Как да създадете източник на Postgres
Има два начина да създадете източник на Postgres в Materialize:
- Използване на Debezium точно както направихме с MySQL източника.
- Използване на Postgres Materialize Source, който ви позволява да свържете Materialize директно към Postgres, така че да не се налага да използвате Debezium.
За тази демонстрация ще използваме Postgres Materialize Source само като демонстрация как да го използваме, но не се колебайте да използвате Debezium вместо това.
За да създадете Postgres Materialize Source, изпълнете следния оператор:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Бърз преглед на горното изявление:
MATERIALIZED:Материализира данните на източника на PostgreSQL. Всички данни се запазват в паметта и прави източниците директно избираеми.mz_source:Името на източника на PostgreSQL.CONNECTION:Параметрите на връзката на PostgreSQL.PUBLICATION:Публикацията на PostgreSQL, съдържаща таблиците, които трябва да се предават на Materialize.
След като създадем източника на PostgreSQL, за да можем да правим заявки за PostgreSQL таблиците, ще трябва да създадем изгледи, които представляват оригиналните таблици на публикацията нагоре по веригата.
В нашия случай имаме само една таблица, наречена users така че изявлението, което трябва да изпълним е:
CREATE VIEWS FROM SOURCE mz_source (users);
За да видите наличните изгледи, изпълнете следния оператор:
SHOW FULL VIEWS;
След като това е направено, можете да направите заявка за новите изгледи директно:
SELECT * FROM users;
След това нека да продължим и да създадем още няколко изгледа.
Как да създадете мивка Kafka
Мивките ви позволяват да изпращате данни от Materialize към външен източник.
За тази демонстрация ще използваме Redpanda.
Redpanda е съвместим с API на Kafka и Materialize може да обработва данни от него точно както би обработвал данни от източник на Kafka.
Нека създадем материализиран изглед, който ще съдържа всички неплатени поръчки с голям обем:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Както можете да видите, тук всъщност се присъединяваме към users изглед, който поглъща данните директно от нашия източник на Postgres и abandond_orders преглед, който поглъща заедно данните от темата Redpanda.
Нека създадем мивка, където ще изпратим данните от горния материализиран изглед:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Сега, ако трябва да се свържете с контейнера Redpanda и да използвате rpk topic consume команда, ще можете да четете записите от темата.
Въпреки това, към момента няма да можем да визуализираме резултатите с rpk защото е форматиран AVRO. Redpanda най-вероятно ще приложи това в бъдеще, но за момента всъщност можем да прехвърлим темата обратно в Materialize, за да потвърдим формата.
Първо, вземете името на темата, която е генерирана автоматично:
SELECT topic FROM mz_kafka_sinks;
Изход:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
За повече информация как се генерират имената на темите, вижте документацията тук.
След това създайте нов материализиран източник от тази тема на Redpanda:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Не забравяйте да промените съответно името на темата!
Накрая подайте заявка към този нов материализиран изглед:
SELECT * FROM high_volume_orders_test LIMIT 2;
Сега, когато имате данните в темата, можете да накарате други услуги да се свържат с нея и да ги консумират и след това да задействат имейли или сигнали например.
Как да свържете Metabase
За да получите достъп до екземпляра на Metabase, посетете https://localhost:3030 ако изпълнявате демонстрацията локално или https://your_server_ip:3030 ако изпълнявате демонстрацията на сървър. След това следвайте стъпките, за да завършите настройката на Metabase.
Уверете се, че сте избрали Materialize като източник на данните.
След като сте готови, ще можете да визуализирате данните си точно както бихте направили със стандартна PostgreSQL база данни.
Как да спрем демонстрацията
За да спрете всички услуги, изпълнете следната команда:
docker-compose down
Заключение
Както можете да видите, това е много прост пример за това как да използвате Materialize. Можете да използвате Materialize, за да приемате данни от различни източници и след това да ги предавате поточно до различни дестинации.
Полезни ресурси:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT