Тази статия дава ръководство стъпка по стъпка за използване на възможностите за машинно обучение с 2UDA. В статията ще използваме пример за животни, за да предвидим дали са бозайници, птици, риби или насекоми.
Версии на софтуер
Ще използваме 2UDA версия 11.6-1 за внедряване на модела за машинно обучение. 2UDA версия 11.6-1 комбинира:
- PostgreSQL 11.6
- Orange 3.23.0
Можете да намерите най-новата версия на 2UDA тук.
Стъпка 1:Заредете набор от данни за обучение в PostgreSQL
Примерният набор от данни, който се използва за обучение на нашия модел, е достъпен в официалното хранилище на Orange GitHub тук.
Следвайте тези стъпки, за да заредите данните за обучение в PostgreSQL таблици:
- Свържете се с PostgreSQL чрез psql, OmniDB или друг инструмент, с който сте запознати.
- Създайте таблица, за да съхранявате нашите данни за обучение . Тук е именуван като training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Вмъкнете данни за обучение в таблицата чрез заявка COPY. Преди да изпълните заявката COPY, уверете се, че PostgreSQL има необходими разрешения за четене на файла с данни, в противен случай операцията COPY няма да успее.
ЗАБЕЛЕЖКА: Моля, не забравяйте да въведете табулация интервал между единични кавички след разделителя ключова дума.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Моля, намерете екранната снимка на набора от данни за обучение по-долу
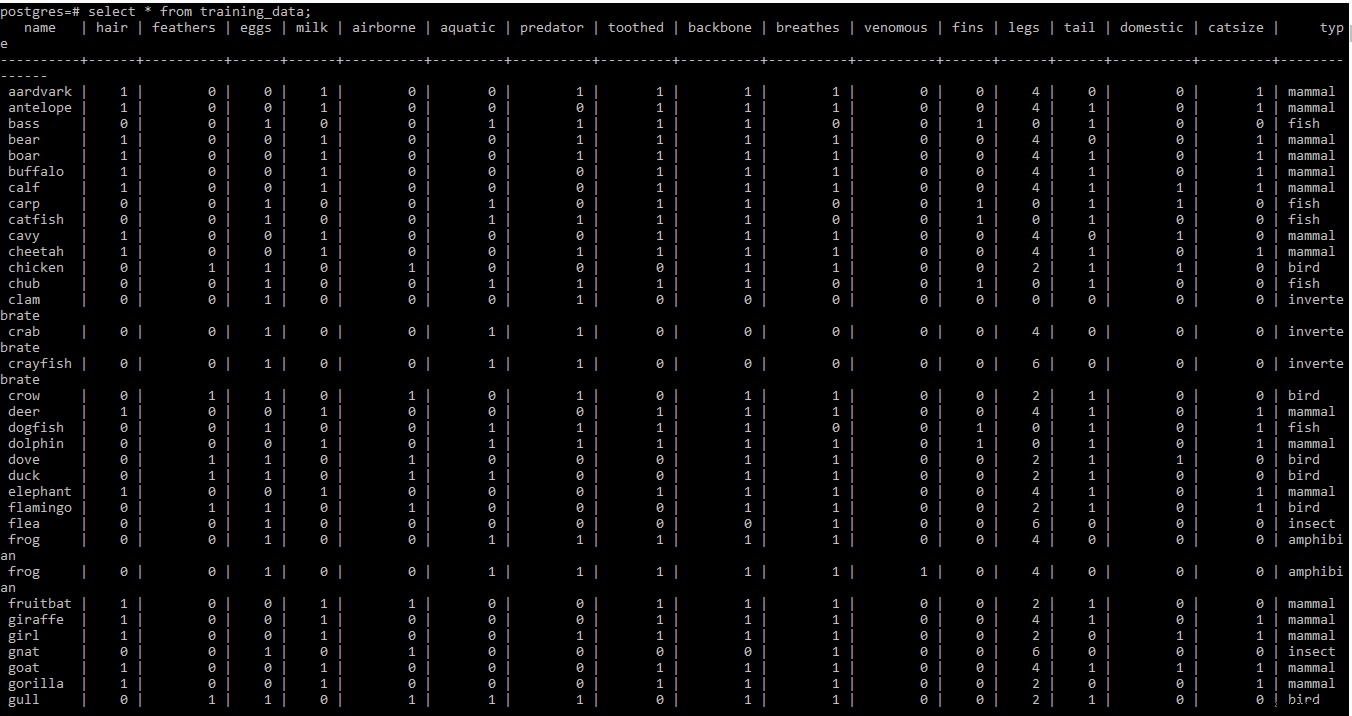
ЗАБЕЛЕЖКА: Редове втори и трети от набора от данни за обучение в .tab файл съдържа известна мета информация. Тъй като не е необходим на този етап, той е премахнат от файла.
Стъпка 2:Създайте работен процес с Orange
- Отидете на работния плот и щракнете двукратно върху оранжевата икона.
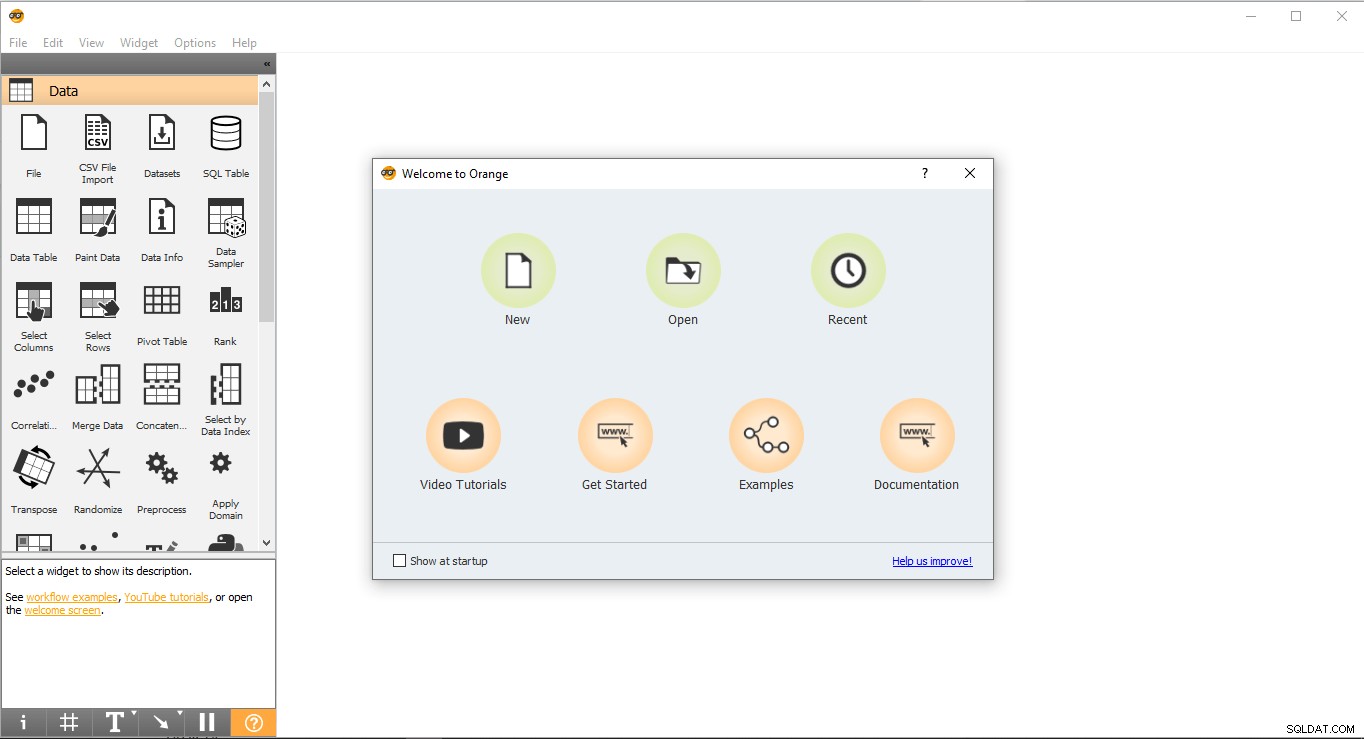
- Така изглежда началната страница. Изберете Ново опция и ще създаде празен проект.

Сега сте готови да приложите модела на машинното обучение към набора от данни.
Стъпка 3:Изберете модел на машинно обучение, за да обучите данните
За тази статия, k-nearest съседи (KNN) Моделът на машинно обучение се използва за обучение на данните. След като процесът на обучение за данни приключи, в следващата стъпка тестовите данни се предават на Предсказанието джаджа за проверка на точността на прогнозите.
Стъпка 4:Импортирайте данни за обучение от PostgreSQL в Orange
Този набор от данни за обучение ще се използва за обучение на модела за машинно обучение.
- Плъзнете и пуснете SQL таблица джаджа от Данни меню.
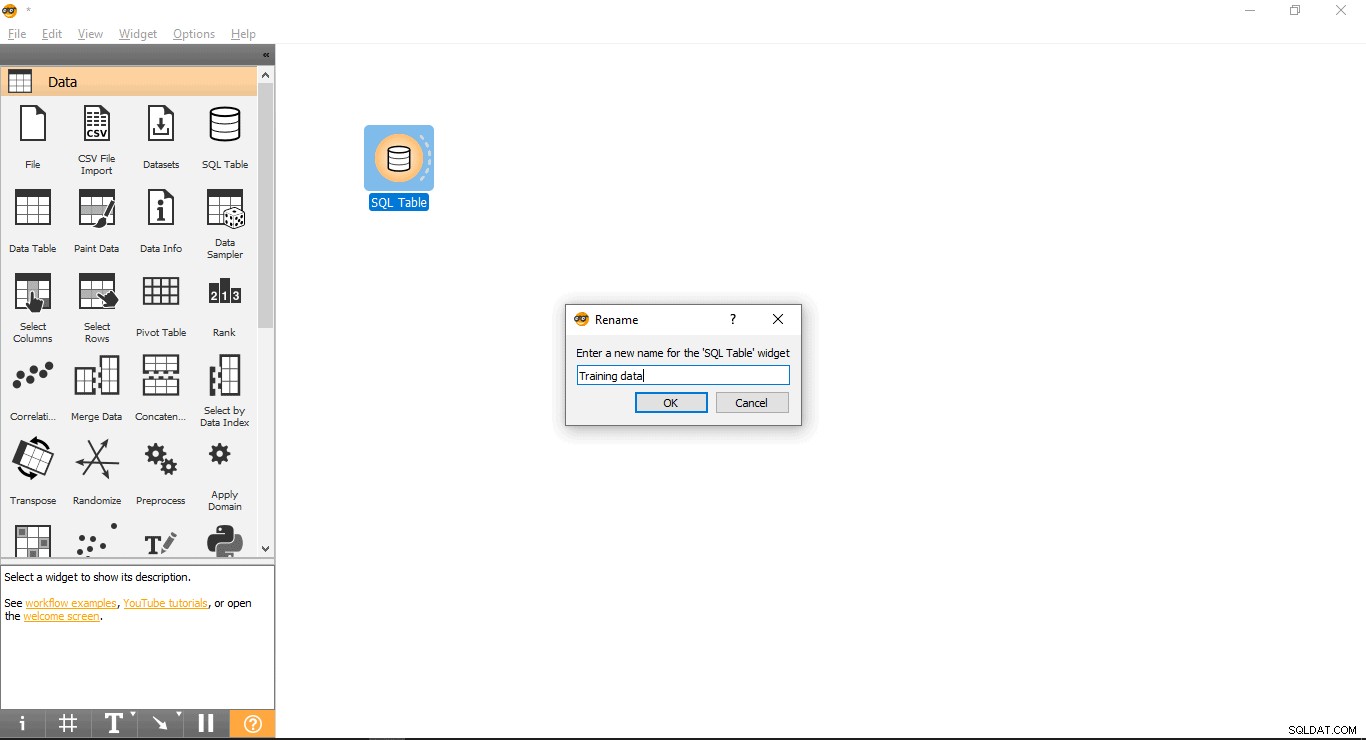
- Преименуване на джаджа (по избор)
- Щракнете с десния бутон върху SQL таблицата джаджа.
- Изберете Преименуване .
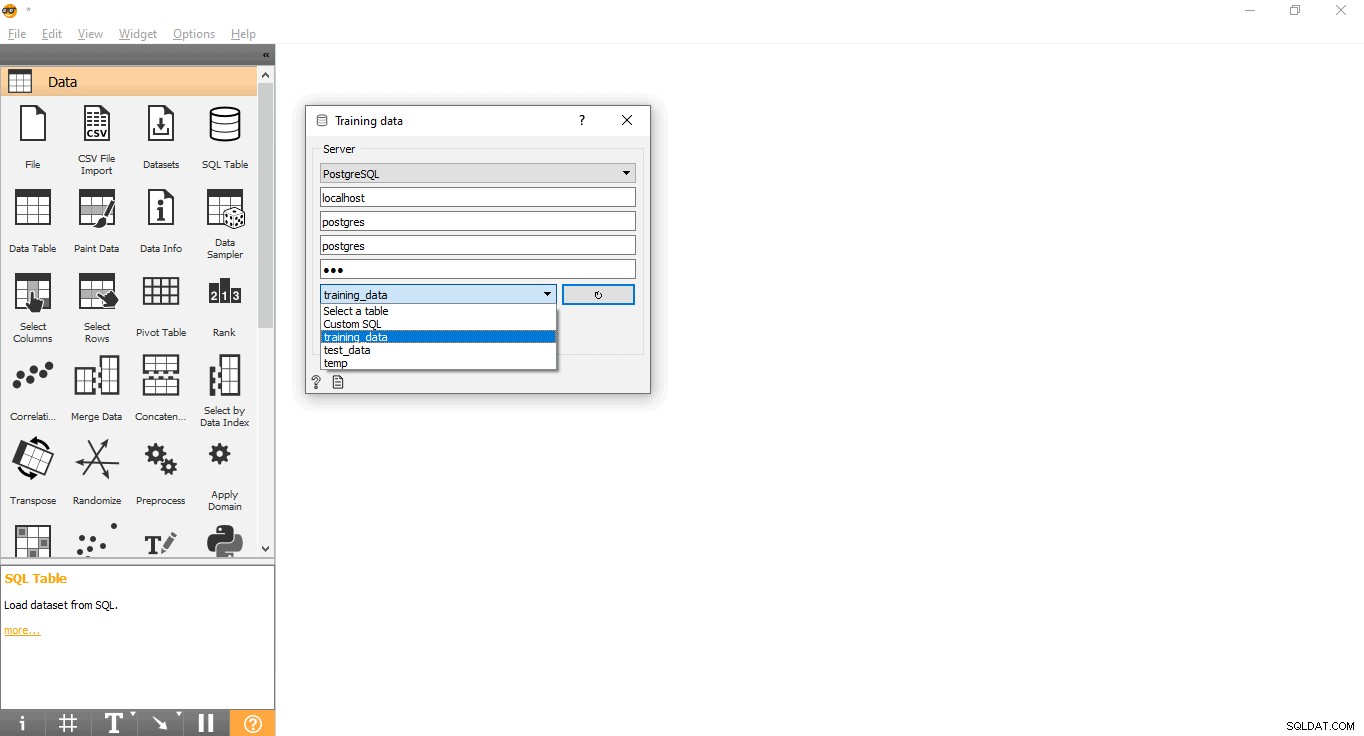
- Свържете се с PostgreSQL, за да заредите набора от данни за обучение:
- Щракнете двукратно върху Данни за обучение джаджа.
- Въведете идентификационни данни, за да се свържете с базата данни PostgreSQL.
- Натиснете бутона за презареждане, за да заредите всички налични таблици от дадена база данни.
- Изберете таблица training_data от падащото меню и затворете изскачащия прозорец.
Стъпка 5:Добавете целева колона
Тази стъпка е важна, тъй като моделът на машинното обучение ще се опита да предвиди данните за тази целева променлива/колона:
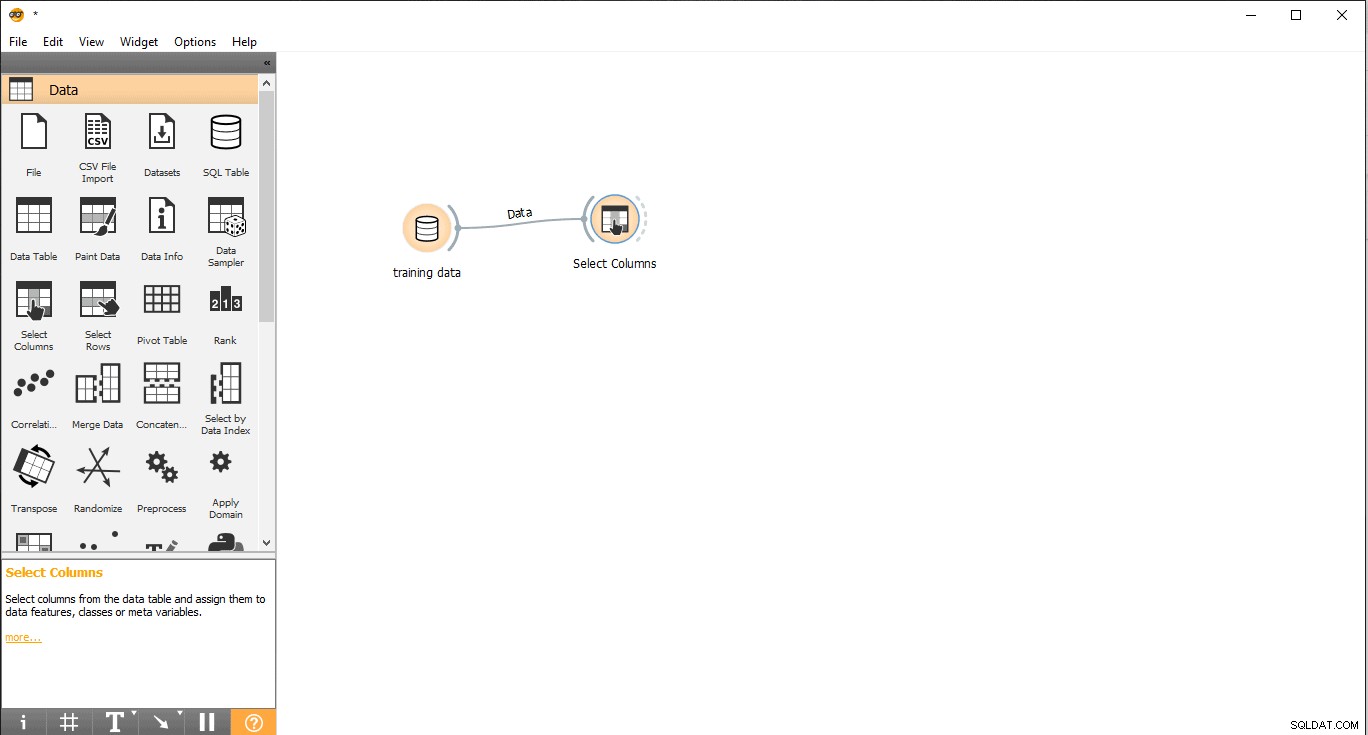
- Плъзнете и пуснете Изберете колони джаджа от данните меню.
- Щракнете двукратно върху Избор на колони джаджа.
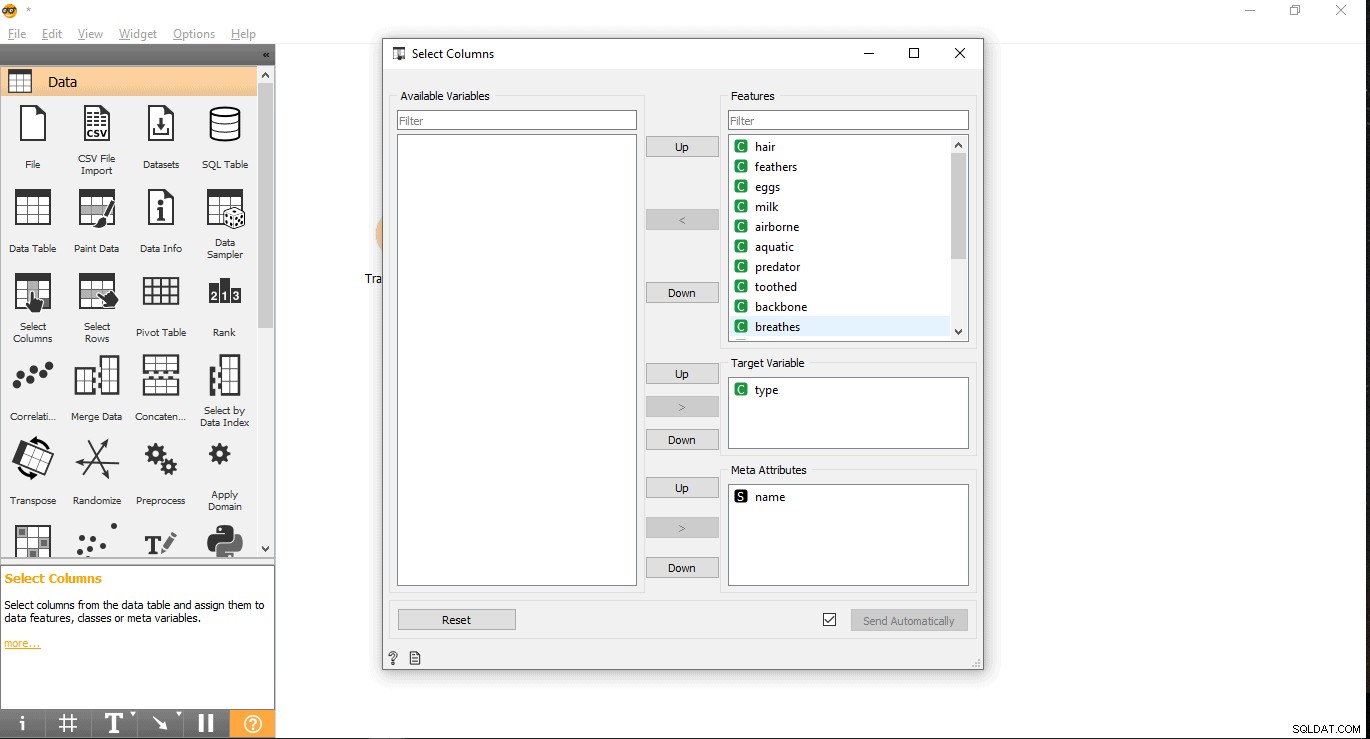
- Потърсете целевата си колона под етикета „Функции“. Тук се използва тип като целева променлива, защото трябва да видим какъв тип е дадено животно.
- Плъзнете го и го пуснете под Целева променлива поле и затворете изскачащия прозорец.
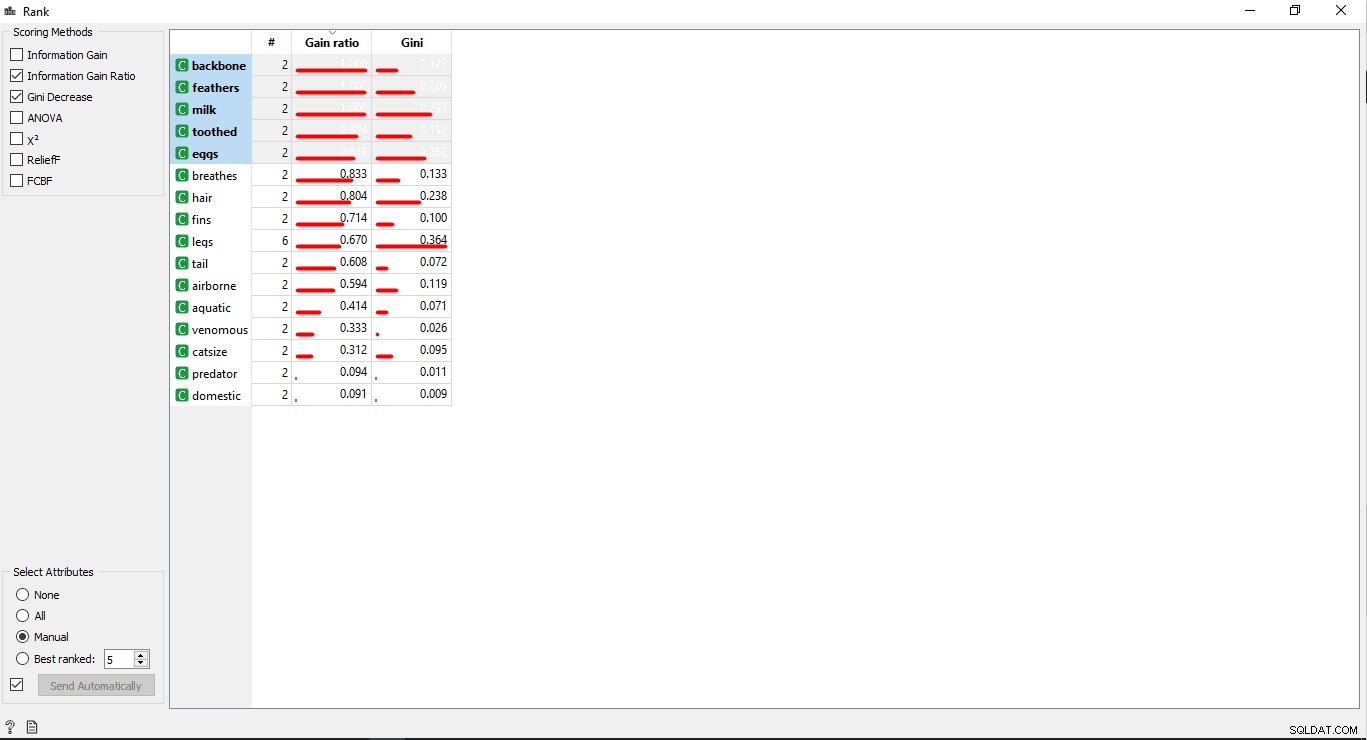
Стъпка 6:Класиране на колоните
Можете да класирате или оценявате тренировъчната променлива/колони според тяхната корелация с целевата колона.
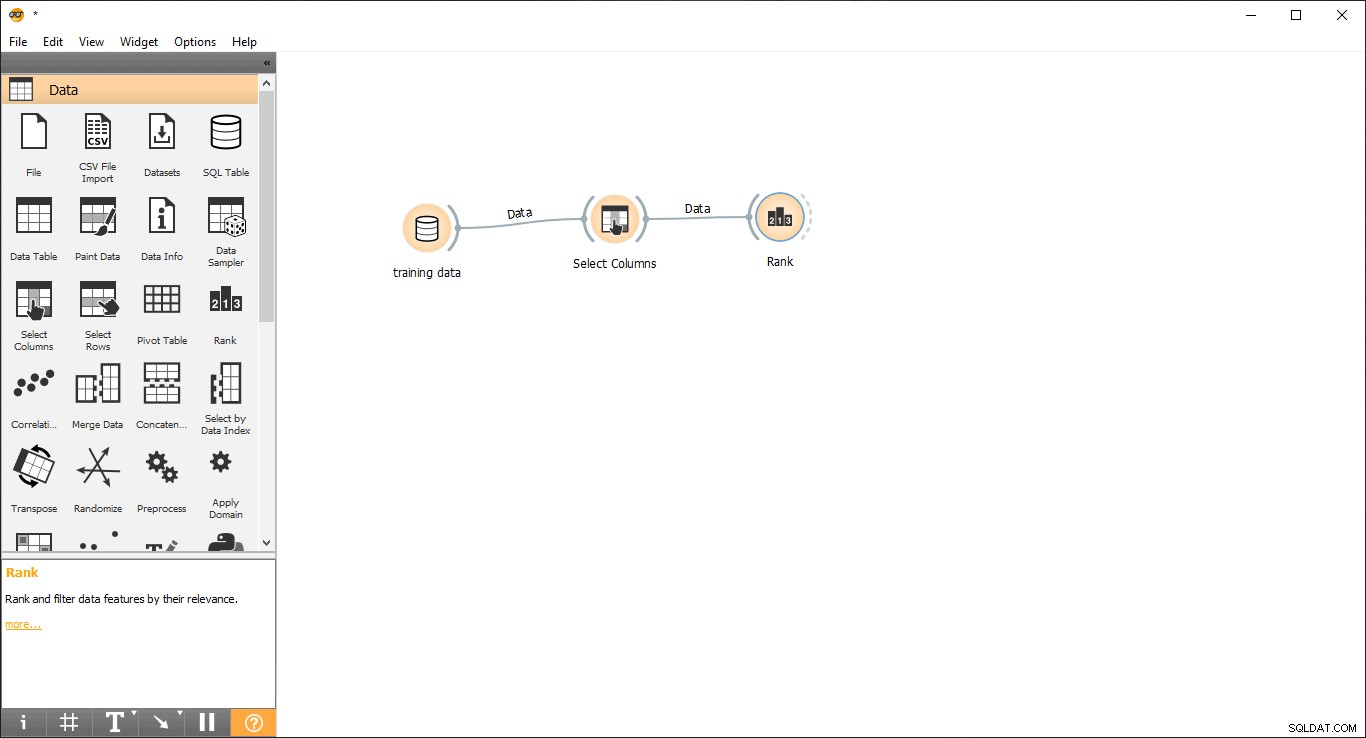
- Плъзнете и пуснете Ранг джаджа от данните меню.
- Начертайте линия на връзка от Избор на колони джаджа за Ранг джаджа .
- Щракнете двукратно върху Ранг джаджа, за да видите най-свързаните колони в таблицата с данни за обучение. По подразбиране ще избира първите 5 колони.
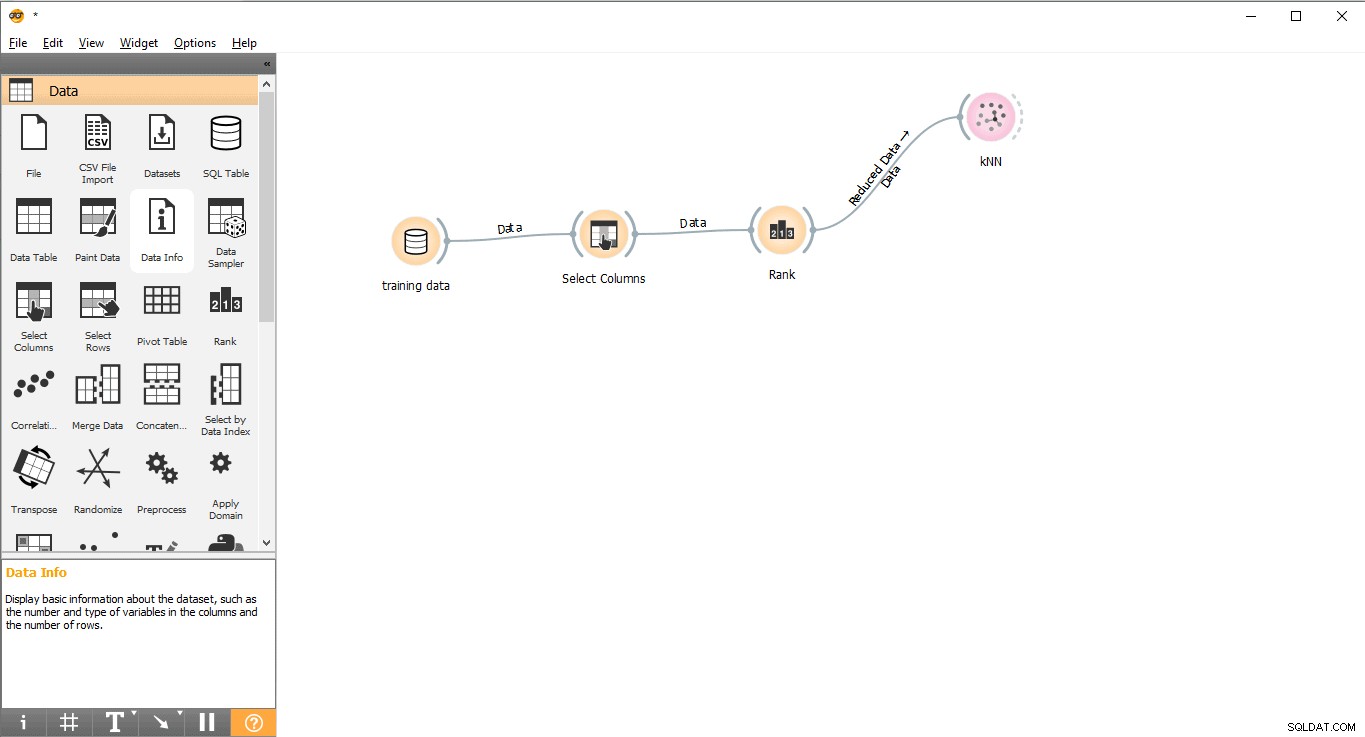
Стъпка 7:Обучение за данни
В тази стъпка моделът за машинно обучение (KNN) ще бъде обучен с набора от данни за обучение. Моля, следвайте следните стъпки:
- Плъзнете и пуснете KNN джаджа от Модела меню.
- Начертайте линия на връзка от Ранг джаджа за KNN джаджа.
Стъпка 8:Заредете тестов набор от данни в PostgreSQL
Създава се отделен набор от тестови данни за извършване на прогнози. Моля, следвайте стъпките, за да заредите тестов набор от данни в PostgreSQL таблица.
- Създайте таблица, за да съхранявате нашите тестови данни . Тук е именуван като test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Вмъкнете тестови данни в тестовата таблица чрез COPY запитване. Преди да изпълните COPY заявка, моля, уверете се, че PostgreSQL има изисквани разрешения за четене на файла с данни, в противен случай операцията COPY няма да бъде успешна.
ЗАБЕЛЕЖКА: Моля, не забравяйте да въведете табулация интервал между единични кавички след разделителя ключова дума. Втипа умишлено е поставен въпросителен знак колона от тестовия набор от данни, защото трябва да разберем вида на дадено животно с нашия модел за машинно обучение.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Моля, намерете екранната снимка на набора от тестови данни по-долу

Стъпка 9:Импортирайте тестовите данни от PostgreSQL в Orange
Моля, следвайте следните стъпки, за да приложите предвижданията.
- Плъзнете и пуснете SQL таблица джаджа от данните меню.
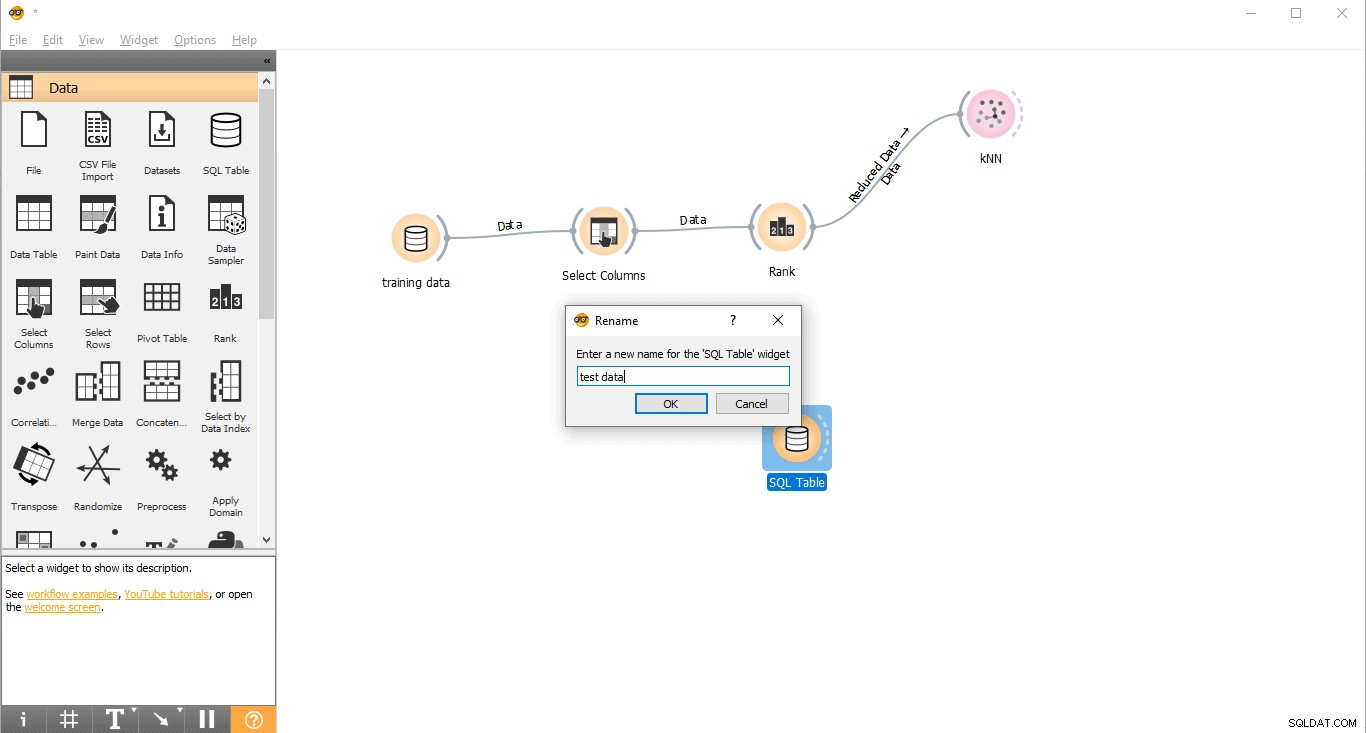
- Преименуване на джаджа (По избор)
- Щракнете с десния бутон върху SQL таблицата джаджа.
- Изберете Преименуване .
- Свържете се с PostgreSQL, за да заредите тестови данни.
- Щракнете двукратно върху Тестови данни джаджа.
- Свържете го с Тестови данни таблица от PostgreSQL.
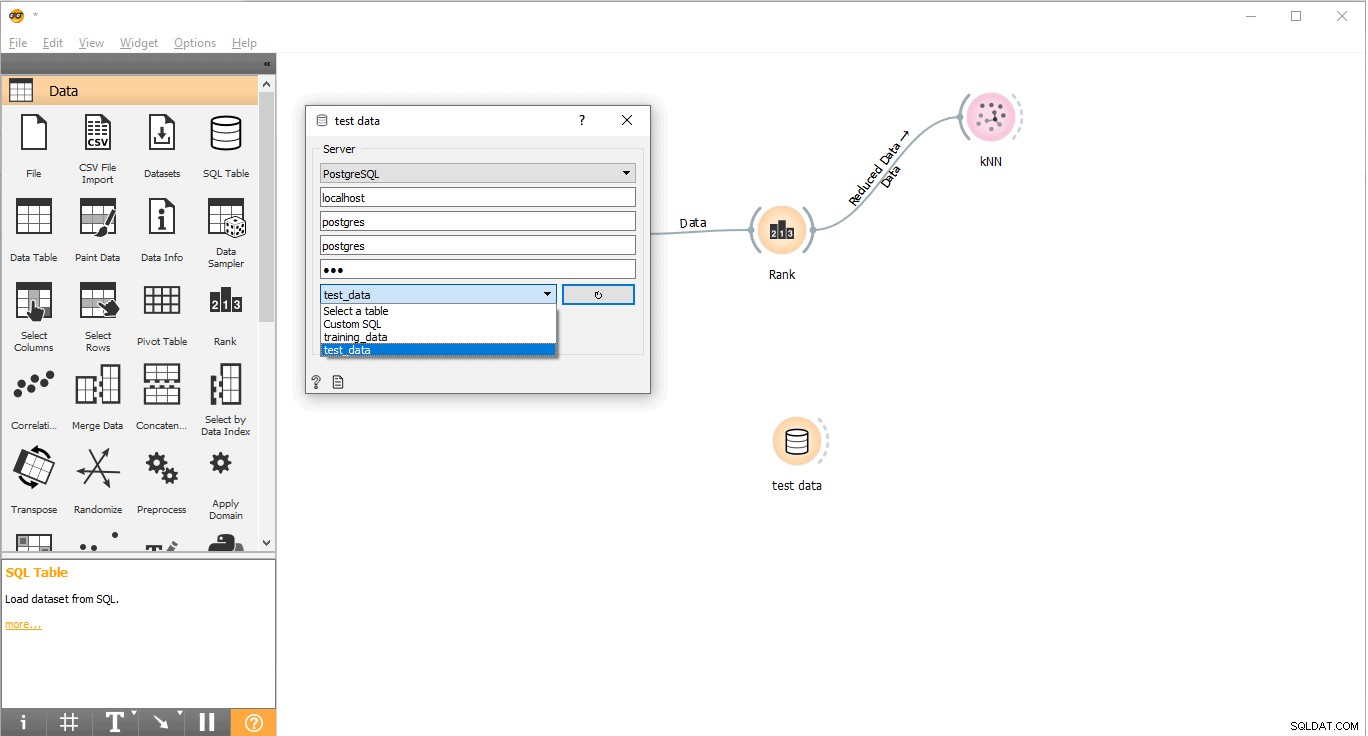
Сега сме готови да изпълняваме прогнози.
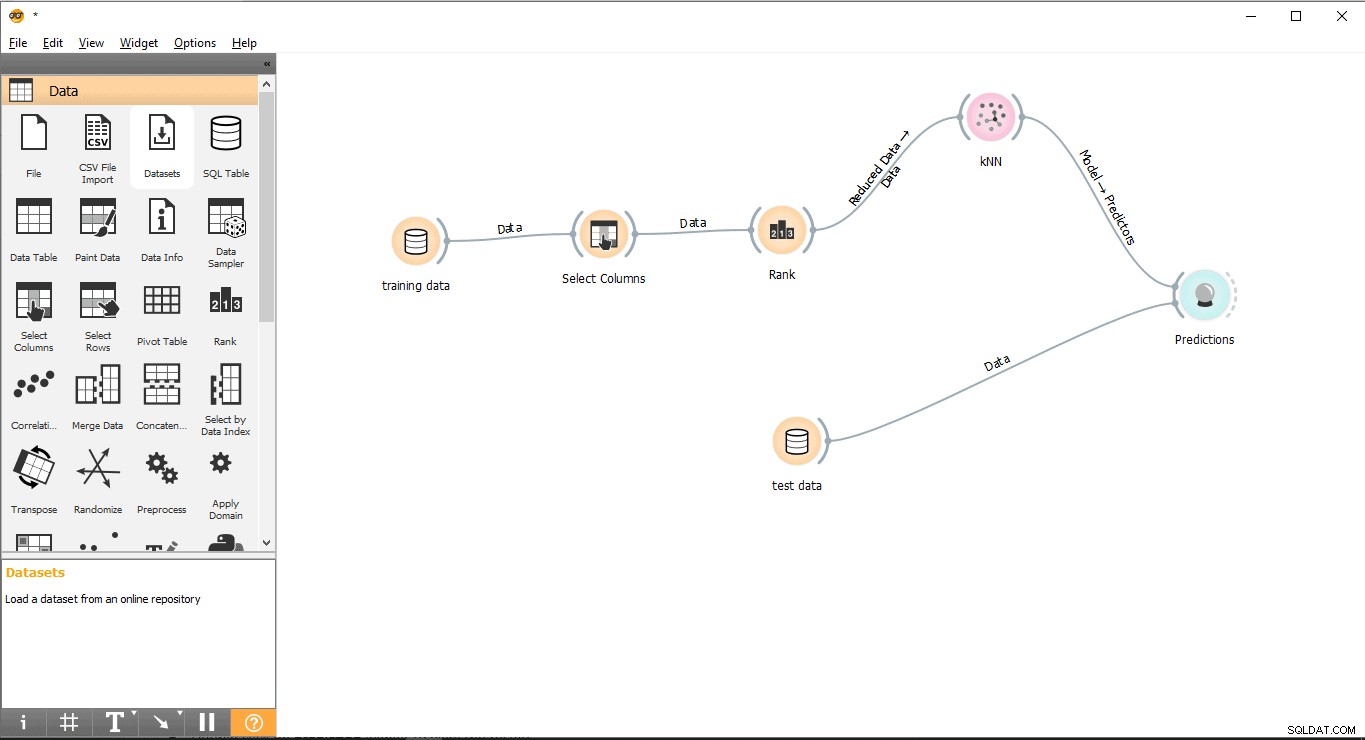
Стъпка 10:Прогнози
Прогноза джаджа ще се опита да предвиди тестовите данни въз основа на данни за обучение от KNN .
- Плъзнете и пуснете Прогнозиране джаджа от Оценяване меню.
- Начертайте линия с връзка Тестови данни джаджа за Предсказание джаджа.
- Начертайте линия на връзка от KNN джаджа за Предсказание джаджа.
Стъпка 11:Резултати
Щракнете двукратно върху Прогноза джаджа за преглед на резултатите.
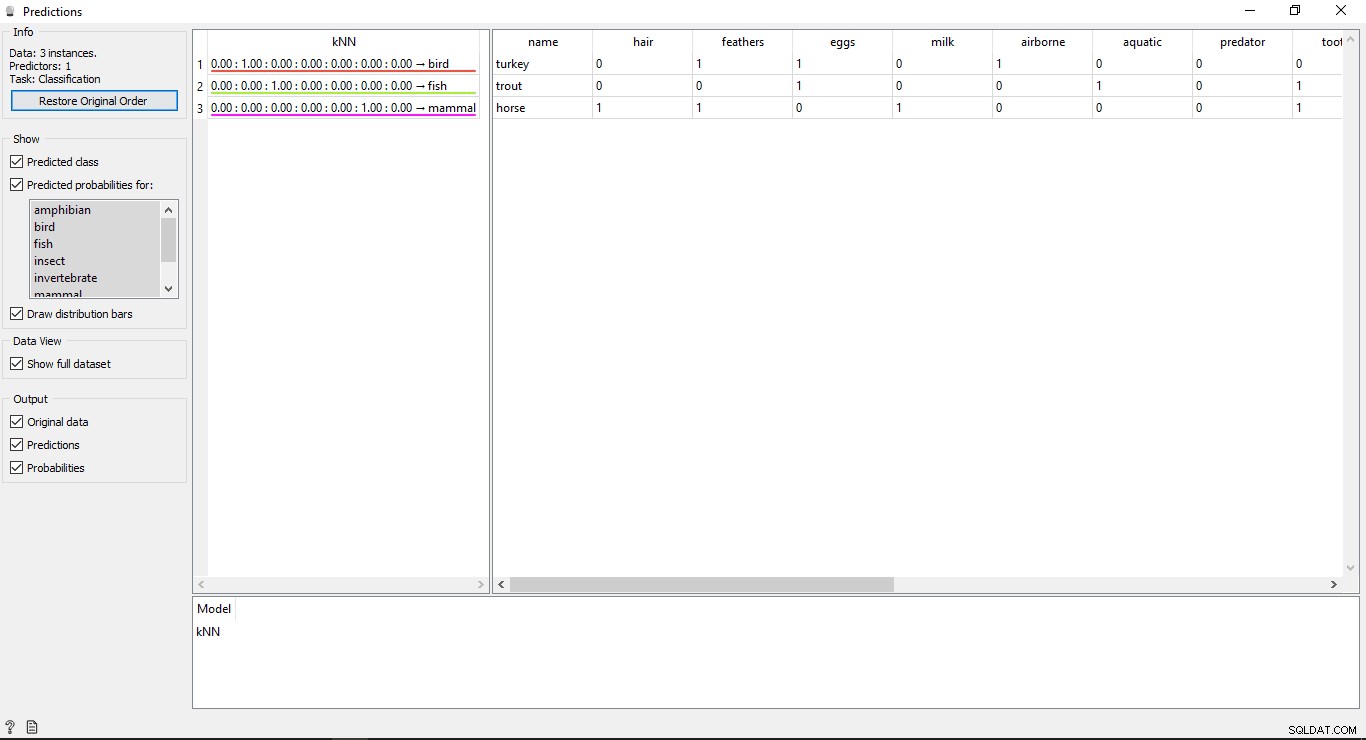
Разбиране на резултатите
Ще видите 2 основни таблици в прозореца за прогнозиране. Таблицата от лявата страна показва прогнозираните резултати, докато таблицата отдясно показва оригиналните тестови данни, предоставени за прогнози.
ОтKNN моделът е използван за обучение на данни, така че ще видите една колона с име KNN който изброява резултатите.
Както знаем:
- Кон е бозайник
- Пъстърва е Риба
- Турция е птица
Така KNN е в състояние да определи всички типове правилно.
Точност на прогнозите
Ако видите таблицата от лявата страна в изхода на приспособлението за прогнозиране, тя има някои числа преди предвидения тип, т.е. 1.00. 0,00 Тези числа показват точността на предвидения тип.
Използвахме 7 вида животни в набора от данни за обучение, така че той показва общ брой от 7 колони със стойности за точност, всяка колона ще представлява 1 тип животно. Можете да проверите коя колона представлява какъв тип животно, като погледнете списъка, който е наличен в лявата част на екрана ви под Предвидени вероятности за етикет. Ако погледнете първия ред, който казва Турция е птица . Виждаме, че точността му е 1.00 (100% от 2-ра колона). Същото важи и за други примери Пъстърва е Риба и точността му е 1.00 (100% от 3-та колона).
В тази статия използвахме алгоритъма на k-най-близките съседи (KNN), за да приложим модела на машинно обучение. В следващия блог ще използваме Support Vector Machine (SVM) модел.
За всякакви въпроси или коментари, моля, свържете се с помощта на формата за контакт тук.



