Това е втората част от серия от две части за repmgr на 2ndQuadrant, инструмент с висока достъпност с отворен код за PostgreSQL.
В първата част настроихме PostgreSQL 12 клъстер с три възела заедно с възел „свидетел“. Клъстерът се състоеше от първичен възел и два резервни възела. Клъстерът и свидетелският възел бяха хоствани във виртуален частен облак на Amazon Web Service (VPC). Сървърите EC2, хостващи екземплярите на Postgres, бяха поставени в подмрежи в различни зони за достъпност (AZ), както е показано по-долу:
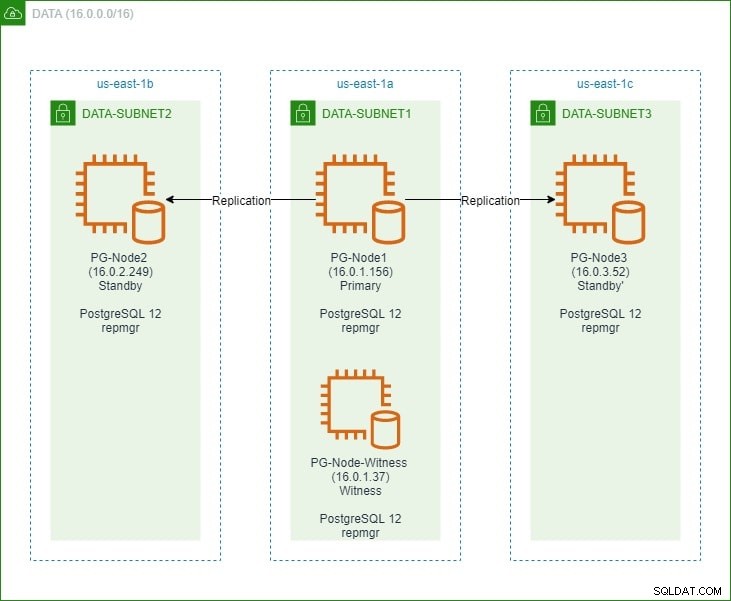
Ще направим обширни препратки към имената на възлите и техните IP адреси, така че ето отново таблицата с подробности за възлите:
| Име на възел | IP адрес | Роля | Изпълнение на приложения |
| PG-възел1 | 16.0.1.156 | Основно | PostgreSQL 12 и repmgr |
| PG-Node2 | 16.0.2.249 | Режим на готовност 1 | PostgreSQL 12 и repmgr |
| PG-Node3 | 16.0.3.52 | Режим на готовност 2 | PostgreSQL 12 и repmgr |
| PG-Node-Witness | 16.0.1.37 | Свидетел | PostgreSQL 12 и repmgr |
Инсталирахме repmgr в основния и резервния възел и след това регистрирахме първичния възел с repmgr. След това клонирахме и двата резервни възела от първичния и ги стартирахме. И двата резервни възела също бяха регистрирани с repmgr. Командата „repmgr cluster show“ ни показа, че всичко работи според очакванията:

Текущ проблем
Настройването на стрийминг репликация с repmgr е много лесно. Това, което трябва да направим по-нататък, е да гарантираме, че клъстерът ще функционира дори когато основният стане недостъпен. Това ще разгледаме в тази статия.
При репликация на PostgreSQL първичният може да стане недостъпен по няколко причини. Например:
- Операционната система на основния възел може да се срине или да не реагира
- Основният възел може да загуби мрежовата си връзка
- Услугата PostgreSQL в основния възел може да се срине, да спре или да стане недостъпна неочаквано
- Услугата PostgreSQL в основния възел може да бъде спряна умишлено или случайно
Всеки път, когато основното стане недостъпно, режимът на готовност не автоматично се издига до основната роля. Резервният режим все още продължава да обслужва заявки само за четене – въпреки че данните ще бъдат актуални до последния LSN, получен от основния. Всеки опит за операция на запис ще бъде неуспешен.
Има два начина да смекчите това:
- Режимът на готовност е ръчен надстроен до основна роля. Това обикновено е така при планирано преминаване на отказ или „превключване“
- Режимът на готовност е автоматично повишен в основна роля. Такъв е случаят с инструменти, които не са местни, които непрекъснато наблюдават репликацията и предприемат действия за възстановяване, когато основният не е наличен. repmgr е един такъв инструмент.
Тук ще разгледаме втория сценарий. Тази ситуация обаче има някои допълнителни предизвикателства:
- Ако има повече от един режим на готовност, как инструментът (или режимите на готовност) решава кой от тях да бъде повишен като основен? Как функционират кворумът и процесът на повишаване?
- За множество режими на готовност, ако единият е основен, как другите възли започват да го „следват“ като нов основен?
- Какво се случва, ако основният функционира, но по някаква причина временно е отделен от мрежата? Ако един от режимите на готовност бъде повишен в първичен и след това първоначалният първичен се върне онлайн, как може да се избегне ситуацията на „разцепен мозък“?
Отговорът на remgr:Witness Node и repmgr Daemon
За да отговори на тези въпроси, repmgr използва нещо, наречено свидетелски възел . Когато първичният е недостъпен – задача на възел-свидетел е да помогне на резервните да достигнат кворум, ако някой от тях трябва да бъде повишен на основна роля. Резервите достигат този кворум, като определят дали основният възел действително е офлайн или само временно недостъпен. Свидетелският възел трябва да се намира в същия център за данни/мрежов сегмент/подмрежа като основния възел, но НИКОГА не трябва да работи на същия физически хост като основния възел.
Не забравяйте, че в първата част от тази поредица пуснахме свидетелски възел в същата зона на наличност и подмрежа като основния възел. Нарекохме го PG-Node-Witness и инсталирахме там екземпляр на PostgreSQL 12. В тази публикация ще инсталираме repmgr и там, но повече за това по-късно.
Вторият компонент на решението е демонът repmgr (repmgrd) работи във всички възли на клъстера и свидетелския възел. Отново, ние не стартирахме този демон в първата част от тази серия, но ще го направим тук. Демонът идва като част от пакета repmgr – когато е активиран, той работи като редовна услуга и непрекъснато следи здравето на клъстера. Той инициира отказ, когато се достигне кворум, че първичният е офлайн. Не само може автоматично да насърчава режим на готовност, но може също така да инициира отново други режими на готовност в клъстер с множество възли, за да следва новия първичен .
Процесът на кворума
Когато даден режим на готовност осъзнае, че не вижда основния, той се консултира с други режими на готовност. Всички режими на готовност, работещи в клъстера, достигат до кворум за избор на нов първичен чрез серия от проверки:
- Всеки режим на готовност разпитва други режими на готовност за момента, в който за последно е „виждал“ основния. Ако последния репликиран LSN в режим на готовност или времето на последната комуникация с основния е по-скоро от последния репликиран LSN на текущия възел или времето на последната комуникация, възелът не прави нищо и чака комуникацията с основния да бъде възстановена
- Ако никой от дежурните не може да види основния, те проверяват дали наблюдаващият възел е наличен. Ако не може да се достигне и до свидетелския възел, резервите приемат, че има прекъсване на мрежата от основната страна и не пристъпват към избор на нов първичен
- Ако свидетелят може да бъде достигнат, в режим на готовност приемат, че основният е изключен и продължават да избират основен
- Възелът, който е конфигуриран като „предпочитан“ основен, ще бъде повишен. Всеки режим на готовност ще бъде повторно инициализиран за репликация, за да следва новия първичен.
Конфигуриране на клъстера за автоматично отказване
Сега ще конфигурираме клъстера и наблюдателния възел за автоматично преминаване при отказ.
Стъпка 1:Инсталирайте и конфигурирайте repmgr в Witness
Вече видяхме как да инсталираме пакета repmgr в последната ни статия. Правим това и в свидетелския възел:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
И след това:
# yum install repmgr12 -y
След това добавяме следните редове във файла postgresql.conf на възел-свидетел:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
Ние също така добавяме следните редове във файла pg_hba.conf в свидетелския възел. Обърнете внимание как използваме CIDR диапазона на клъстера, вместо да указваме отделни IP адреси.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
Забележка
[Стъпките, описани тук, са само за демонстрационни цели. Нашият пример тук използва външно достъпни IP адреси за възлите. Използването на listen_address =‘*’ заедно с механизма за сигурност „доверие“ на pg_hba представлява риск за сигурността и НЕ трябва да се използва в производствени сценарии. В производствена система всички възли ще бъдат в една или повече частни подмрежи, достъпни чрез частни IP адреси от jumphosts.]
С направени промени в postgresql.conf и pg_hba.conf, създаваме потребителя repmgr и базата данни repmgr в свидетеля и променяме пътя за търсене по подразбиране на потребителя repmgr:
[example@sqldat.comitness ~]$ createuser --superuser repmgr [example@sqldat.com ~]$ createdb --owner=repmgr repmgr [example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Накрая добавяме следните редове към файла repmgr.conf, намиращ се под /etc/repmgr/12/
node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
След като конфигурационните параметри са зададени, рестартираме услугата PostgreSQL в свидетелския възел:
# systemctl restart postgresql-12.service
За да тестваме свързаността с repmgr на възел-свидетел, можем да изпълним тази команда от основния възел:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
След това регистрираме свидетелския възел с repmgr, като изпълним командата „repmgr register register“ като потребител на postgres. Обърнете внимание как използваме адреса на основния възел, а НЕ възел-свидетел в командата по-долу:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
Това е така, защото командата „repmgr свидетелски регистър“ добавя метаданните на свидетелския възел към базата данни repmgr на основния възел и, ако е необходимо, инициализира свидетелския възел, като инсталира разширението repmgr и копира метаданните repmgr в свидетелския възел.
Резултатът ще изглежда така:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Накрая проверяваме състоянието на цялостната настройка от всеки възел:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
Резултатът изглежда така:

Стъпка 2:Промяна на sudoers файла
Когато клъстерът и свидетелят работят, ние добавяме следните редове във файла sudoers във всеки възел на клъстера и свидетелския възел:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Стъпка 3:Конфигуриране на параметри на repmgrd
Вече добавихме четири параметъра във файла repmgr.conf във всеки възел. Добавените параметри са основните, необходими за операцията repmgr. За да активирате демона repmgr и автоматичното преминаване при отказ, трябва да бъдат активирани/добавени редица други параметри. В следващите подраздели ще опишем всеки параметър и стойността, на която ще бъдат зададени във всеки възел.
отказ при отказ
Параметърът за преодоляване на срив е един от задължителните параметри за демона repmgr. Този параметър казва на демона дали трябва да инициира автоматично преминаване при отказ, когато бъде открита ситуация на отказ. Може да има една от двете стойности:„ръчно“ или „автоматично“. Ще зададем това на автоматично във всеки възел:
failover='automatic'
команда за промоция
Това е друг задължителен параметър за демона repmgr. Този параметър казва на демона repmgr каква команда трябва да изпълни, за да промотира режим на готовност. Стойността на този параметър обикновено ще бъде командата „repmgr standby promote“ или пътят към шел скрипт, който извиква командата. За нашия случай на използване ние задаваме това на следното във всеки възел:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
следване_команда
Това е третият задължителен параметър за демона repmgr. Този параметър казва на възел в готовност да следва новия първичен. Демонът repmgr заменя заместващия %n с идентификатора на възела на новия първичен по време на изпълнение:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
приоритет
Параметърът приоритет добавя тежест към допустимостта на възела да стане основен. Задаването на този параметър на по-висока стойност дава на възела по-голяма допустимост да стане основен възел. Също така, задаване на тази стойност на нула за възел ще гарантира, че възелът никога не се повишава като основен.
В нашия случай на използване имаме два режима на готовност:PG-Node2 и PG-Node3. Искаме да популяризираме PG-Node2 като нов първичен, когато PG-Node1 излезе офлайн, а PG-Node3 да следва PG-Node2 като негов нов основен. Задаваме параметъра на следните стойности в двата възела в режим на готовност:
| Име на възел | Настройка на параметри |
| PG-Node2 | приоритет =60 |
| PG-Node3 | приоритет =40 |
monitor_interval_secs
Този параметър казва на демона repmgr колко често (в брой секунди) трябва да проверява наличността на възходящия възел. В нашия случай има само един възел нагоре по веригата:основният възел. Стойността по подразбиране е 2 секунди, но ние изрично ще зададем това във всеки възел:
monitor_interval_secs=2
тип_проверка на връзката
Параметърът connection_check_type диктува протокола, който демонът repmgr ще използва, за да достигне до възходящия възел. Този параметър може да приема три стойности:
- пинг :repmgr използва метода PQPing()
- връзка :repmgr се опитва да създаде нова връзка с възходящия възел
- заявка :repmgr се опитва да изпълни SQL заявка на възел нагоре по веригата, използвайки съществуващата връзка
Отново ще зададем този параметър на стойността по подразбиране на ping във всеки възел:
connection_check_type='ping'
reconnect_attempts и reconnect_interval
Когато първичният стане недостъпен, демонът repmgr в възлите в режим на готовност ще се опита да се свърже отново с основния за времена reconnect_attempts. Стойността по подразбиране за този параметър е 6. Между всеки опит за повторно свързване той ще изчака секунди reconnect_interval, който има стойност по подразбиране 10. За демонстрационни цели ще използваме кратък интервал и по-малко опити за повторно свързване. Ние задаваме този параметър във всеки възел:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
Когато първичният стане недостъпен в клъстер с множество възли, резервните могат да се консултират помежду си, за да изградят кворум за отказ. Това се прави, като се пита всеки режим на готовност за времето, когато за последно е видял първичния. Ако последната комуникация на даден възел е била много скорошна и по-късно от момента, в който локалният възел е видял основния, локалният възел приема, че основният все още е наличен и не предприема решение за отказ.
За да активирате този модел на консенсус, параметърът primary_visibility_consensus трябва да бъде настроен на „true“ във всеки възел – включително свидетелят:
primary_visibility_consensus=true
standby_disconnect_on_failover
Когато параметърът standby_disconnect_on_failover е настроен на „true“ в възел в режим на готовност, демонът repmgr ще гарантира, че неговият WAL приемник е изключен от основния и няма да получава никакви WAL сегменти. Той също така ще изчака WAL приемниците на други резервни възли да спрат, преди да вземе решение за отказ. Този параметър трябва да бъде настроен на една и съща стойност във всеки възел. Настройваме това на „true“.
standby_disconnect_on_failover=true
Задаването на този параметър на true означава, че всеки възел в режим на готовност е спрял да получава данни от основния, когато се случи отказът. Процесът ще има закъснение от 5 секунди плюс времето, необходимо на WAL приемника да спре, преди да се вземе решение за отказ. По подразбиране демонът repmgr ще изчака 30 секунди, за да потвърди, че всички братски и сестри възли са спрели да получават WAL сегменти, преди да се случи отказът.
repmgrd_service_start_command и repmgrd_service_stop_command
Тези два параметъра определят как да стартирате и спрете демона repmgr с помощта на командите „repmgr daemon start“ и „repmgr daemon stop“.
По принцип тези две команди са обвивки около командите на операционната система за стартиране/спиране на услугата. Двете стойности на параметъра съпоставят тези команди с техните специфични за ОС версии. Ние задаваме тези параметри на следните стойности във всеки възел:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
Команди за стартиране/стоп/рестартиране на PostgreSQL услуга
Като част от работата си, демонът repmgr често ще трябва да спре, стартира или рестартира услугата PostgreSQL. За да сте сигурни, че това се случва гладко, най-добре е да посочите съответните команди на операционната система като стойности на параметри във файла repmgr.conf. За тази цел ще зададем четири параметъра във всеки възел:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
мониторингова_история
Задаването на параметъра monitoring_history на „yes“ ще гарантира, че repmgr запазва своите данни за мониторинг на клъстера. Задаваме това на „да“ във всеки възел:
monitoring_history=yes
log_status_interval
Задаваме параметъра във всеки възел, за да посочим колко често демонът repmgr ще регистрира съобщение за състояние. В този случай задаваме това на всеки 60 секунди:
log_status_interval=60
Стъпка 4:Стартиране на демона repmgr
С параметрите, които сега са зададени в клъстера и свидетелския възел, ние изпълняваме сухо изпълнение на командата, за да стартираме демона repmgr. Тестваме това първо в първичния възел, а след това в двата резервни възела, последвани от свидетелския възел. Командата трябва да се изпълни като потребител на postgres:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
Резултатът трябва да изглежда така:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
След това стартираме демона във всичките четири възела:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Резултатът във всеки възел трябва да показва, че демонът е стартирал:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
Можем също да проверим събитието при стартиране на услугата от първичните или резервните възли:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
Резултатът трябва да покаже, че демонът наблюдава връзките:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
И накрая, можем да проверим изхода на демона от системния журнал във всеки от режимите на готовност:
# cat /var/log/messages | grep repmgr | less
Ето изхода от PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Проверката на системния журнал в основния възел показва различен тип изход:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Стъпка 5:Симулация на неуспешен първичен
Сега ще симулираме неуспешен първичен, като спрем основния възел (PG-Node1). От подканата на обвивката на възела изпълняваме следната команда:
# systemctl stop postgresql-12.service
Процесът на отказ
След като процесът спре, изчакваме около минута или две и след това проверяваме syslog файла на PG-Node2. Показват се следните съобщения. За яснота и простота имаме цветно кодирани групи съобщения и добавени празни интервали между редовете:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
Тук има много информация, но нека да разберем как са се развили събитията. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
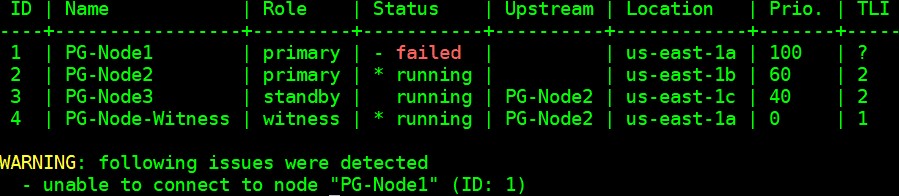
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Заключение
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1