Първоначално публикувано в Serverless на 2 юли 2019 г.

Излагането на проста база данни чрез GraphQL API изисква много персонализиран код и инфраструктура:вярно или невярно?
За тези, които са отговорили „вярно“, ние сме тук, за да ви покажем, че изграждането на GraphQL API всъщност е доста лесно, с някои конкретни примери, които да илюстрират защо и как.
(Ако вече знаете колко лесно е да се изградят приложни програмни интерфейси на GraphQL без сървъри, в тази статия също има много за вас.)
GraphQL е език за заявки за уеб API. Има ключова разлика между конвенционалния REST API и API, базирани на GraphQL:с GraphQL можете да използвате една заявка за извличане на множество обекти наведнъж. Това води до по-бързо зареждане на страниците и дава възможност за по-опростена структура за вашите интерфейсни приложения, което води до по-добро уеб изживяване за всички. Ако никога досега не сте използвали GraphQL, ви предлагаме да разгледате този урок за GraphQL за кратко въведение.
Безсървърната рамка е чудесно подходяща за API на GraphQL:с безсървърна, не е нужно да се притеснявате за стартиране, управление и мащабиране на вашите собствени API сървъри в облака и няма да е необходимо да пишете никакви скриптове за автоматизация на инфраструктурата. Научете повече за Serverless тук. В допълнение, Serverless предоставя отлично изживяване за разработчици, независими от доставчиците, и стабилна общност, която да ви помогне при изграждането на вашите GraphQL приложения.
Много приложения в ежедневния ни опит съдържат функции за социални мрежи и този вид функционалност може наистина да се възползва от внедряването на GraphQL вместо модела REST, където е трудно да се излагат структури с вложени обекти, като потребители и техните публикации в Twitter. С GraphQL можете да изградите унифицирана крайна точка на API, която ви позволява да заявявате, пишете и редактирате всички необходими обекти, като използвате една заявка за API.
В тази статия разглеждаме как да изградим прост GraphQL API с помощта на безсървърната рамка, Node.js и някое от няколкото хоствани решения за бази данни, достъпни чрез Amazon RDS:MySQL, PostgreSQL и MySQL, подобен на Amazon Aurora.
Следвайте това примерно хранилище в GitHub и нека се потопим!
Създаване на GraphQL API с релационен бекенд на DB
В нашия примерен проект решихме да използваме и трите бази данни (MySQL, PostgreSQL и Aurora) в една и съща кодова база. Знаем, че това е излишно дори за производствено приложение, но искахме да ви поразим с това как изграждаме уеб мащаб. 😉
Но сериозно, ние препълнихме проекта, само за да сме сигурни, че ще намерите подходящ пример, който се отнася за любимата ви база данни. Ако искате да видите примери с други бази данни, моля, уведомете ни в коментарите.
Дефиниране на схемата GraphQL
Нека започнем с дефиниране на схемата на GraphQL API, който искаме да създадем, което правим във файла schema.gql в основата на нашия проект, използвайки синтаксиса на GraphQL. Ако не сте запознати с този синтаксис, разгледайте примерите на тази страница с документация на GraphQL.
За начало добавяме първите два елемента към схемата:обект на потребител и обект на публикация, като ги дефинираме по следния начин, така че всеки потребител да може да има множество обекти на публикация, свързани с него:
тип потребител {
UUID:низ
Име:низ
Публикации:[Публикация]
}
въведете Публикация {
UUID:низ
Текст:низ
}
Вече можем да видим как изглеждат обектите User и Post. По-късно ще се уверим, че тези полета могат да се съхраняват директно в нашите бази данни.
След това нека дефинираме как потребителите на API ще отправят заявки към тези обекти. Въпреки че бихме могли да използваме двата типа GraphQL User и Post директно в нашите GraphQL заявки, най-добрата практика е вместо това да създаваме входни типове, за да поддържаме схемата проста. Така че продължаваме и добавяме два от тези типове въвеждане, един за публикациите и един за потребителите:
въведете UserInput {
Име:низ
Публикации:[PostInput]
}
вход PostInput {
Текст:низ
}
Сега нека дефинираме мутациите - операциите, които променят данните, съхранявани в нашите бази данни чрез нашия GraphQL API. За това създаваме тип Mutation. Единствената мутация, която ще използваме засега, е createUser. Тъй като използваме три различни бази данни, ние добавяме мутация за всеки тип база данни. Всяка от мутациите приема входния UserInput и връща потребителски обект:
Ние също така искаме да предоставим начин за запитване на потребителите, така че създаваме тип заявка с една заявка за тип база данни. Всяка заявка приема низ, който е UUID на потребителя, връщайки потребителския обект, който съдържа неговото име, UUID и колекция от всеки асоцииран Pos``t:
Накрая дефинираме схемата и насочваме към типовете Заявка и Мутация:
schema { query: Query mutation: Mutation }
Вече имаме пълно описание за нашия нов GraphQL API! Можете да видите целия файл тук.
Дефиниране на манипулатори за GraphQL API
Сега, когато имаме описание на нашия GraphQL API, можем да напишем кода, от който се нуждаем за всяка заявка и мутация. Започваме със създаване на файл handler.js в корена на проекта, точно до файла schema.gql, който създадохме по-рано.
Първата работа на handler.js е да прочете схемата:
Константата typeDefs вече съдържа дефинициите за нашите GraphQL обекти. След това указваме къде ще живее кодът за нашите функции. За да запазим нещата ясни, ще създадем отделен файл за всяка заявка и мутация:
Константата resolvers вече съдържа дефинициите за всички функции на нашия API. Следващата ни стъпка е да създадем GraphQL сървъра. Помните ли библиотеката graphql-yoga, която изисквахме по-горе? Ще използваме тази библиотека тук, за да създадем работещ GraphQL сървър лесно и бързо:
И накрая, ние експортираме манипулатора GraphQL заедно с манипулатора GraphQL Playground (което ще ни позволи да изпробваме нашия GraphQL API в уеб браузър):
Добре, засега приключихме с файла handler.js. Следва:писане на код за всички функции, които имат достъп до базите данни.
Писане на код за заявките и мутациите
Сега имаме нужда от код за достъп до базите данни и за захранване на нашия GraphQL API. В основата на нашия проект създаваме следната структура за нашите функции за преобразуване на MySQL, като другите бази данни следват:
Чести заявки
В папката Common попълваме файла mysql.js с това, което ще ни е необходимо за мутацията createUser и заявката getUser:инициална заявка, за да създадем таблици за потребители и публикации, ако те все още не съществуват; и потребителска заявка за връщане на потребителски данни при създаване и запитване за потребител. Ще използваме това както в мутацията, така и в заявката.
Заявката init създава както таблиците Users, така и Posts, както следва:
Заявката getUser връща потребителя и неговите публикации:
И двете от тези функции се експортират; след това можем да получим достъп до тях във файла handler.js.
Написване на мутацията
Време е да напишете кода за мутацията createUser, която трябва да приеме името на новия потребител, както и списък с всички публикации, които му принадлежат. За да направим това, създаваме файла resolver/Mutation/mysql_createUser.js с една експортирана функция func за мутацията:
Функцията за мутации трябва да направи следните неща, за да:
-
Свържете се с базата данни, като използвате идентификационните данни в променливите на средата на приложението.
-
Вмъкнете потребителя в базата данни, като използвате потребителското име, предоставено като вход за мутацията.
-
Също така вмъкнете всички публикации, свързани с потребителя, предоставени като вход за мутацията.
-
Върнете създадените потребителски данни.
Ето как постигаме това в код:
Можете да видите пълния файл, който дефинира мутацията тук.
Писане на заявката
Заявката getUser има структура, подобна на мутацията, която току-що написахме, но тази е още по-проста. Сега, когато функцията getUser е в Common пространство от имена, вече не се нуждаем от персонализиран SQL в заявката. И така, ние създаваме файла resolver/Query/mysql_getUser.js, както следва:
Можете да видите пълната заявка в този файл.
Обединяване на всичко във файла serverless.yml
Да направим крачка назад. В момента имаме следното:
-
Схема на API на GraphQL.
-
Файл handler.js.
-
Файл за често срещани заявки за база данни.
-
Файл за всяка мутация и заявка.
Последната стъпка е да свържете всичко това заедно чрез файла serverless.yml. Създаваме празен serverless.yml в основата на проекта и започваме с дефиниране на доставчика, региона и времето за изпълнение. Ние също така прилагаме ролята на LambdaRole IAM (която дефинираме по-късно тук) към нашия проект:
След това дефинираме променливите на средата за идентификационните данни на базата данни:
Забележете, че всички променливи препращат към персонализираната секция, която идва след това и съдържа действителните стойности за променливите. Имайте предвид, че паролата е ужасна парола за вашата база данни и трябва да бъде променена на нещо по-сигурно (може би p@ssw0rd 😃):
Какви са тези препратки след Fn::GettAtt, питате? Те се отнасят до ресурсите на базата данни:
Файлът resource/MySqlRDSInstance.yml дефинира всички атрибути на екземпляра на MySQL. Пълното му съдържание можете да намерите тук.
И накрая, във файла serverless.yml ние дефинираме две функции, graphql и playground. Функцията graphql ще обработва всички заявки за API, а крайната точка на playground ще създаде екземпляр на GraphQL Playground за нас, което е чудесен начин да изпробвате нашия GraphQL API в уеб браузър:
Сега поддръжката на MySQL за нашето приложение е завършена!
Можете да намерите пълното съдържание на файла serverless.yml тук.
Добавяне на поддръжка на Aurora и PostgreSQL
Вече създадохме цялата структура, която ни е необходима, за да поддържаме други бази данни в този проект. За да добавим поддръжка за Aurora и Postgres, трябва само да дефинираме кода за техните мутации и заявки, което правим по следния начин:
-
Добавете файл с общи заявки за Aurora и за Postgres.
-
Добавете мутацията createUser и за двете бази данни.
-
Добавете заявката getUser и за двете бази данни.
-
Добавете конфигурация във файла serverless.yml за всички променливи на средата и ресурси, необходими за двете бази данни.
На този етап имаме всичко необходимо, за да разгърнем нашия GraphQL API, захранван от MySQL, Aurora и PostgreSQL.
Внедряване и тестване на GraphQL API
Внедряването на нашия GraphQL API е лесно.
-
Първо стартираме npm install, за да поставим нашите зависимости на място.
-
След това стартираме npm run deploy, който настройва всички променливи на нашата среда и изпълнява разгръщането.
-
Под капака тази команда изпълнява разгръщане без сървър, използвайки правилната среда.
Това е! В изхода на стъпката за разгръщане ще видим крайната точка на URL за нашето разгърнато приложение. Можем да издадем POST заявки към нашия GraphQL API, използвайки този URL, а нашата Playground (с която ще играем след секунда) е достъпна чрез GET срещу същия URL.
Изпробване на API в GraphQL Playground
GraphQL Playground, което виждате, когато посещавате този URL адрес в браузъра, е чудесен начин да изпробвате нашия API.
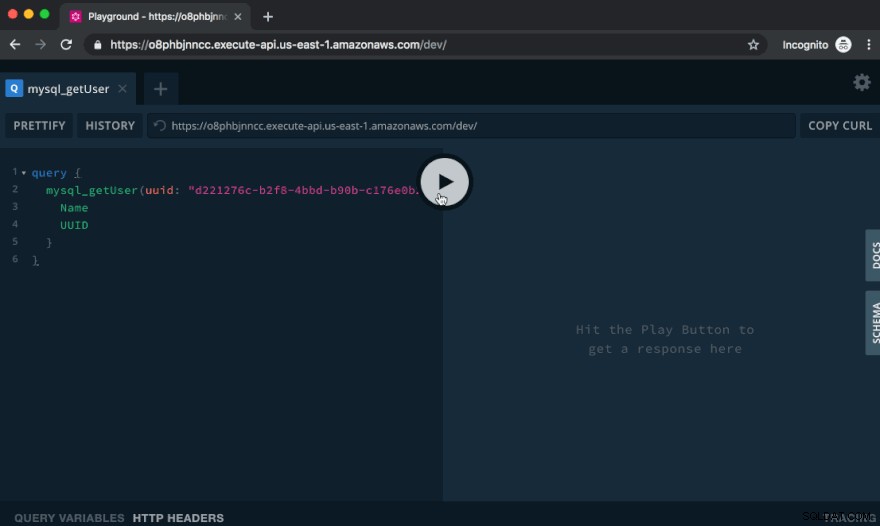
Нека създадем потребител, като изпълним следната мутация:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
При тази мутация ние извикваме mysql_createUser API, предоставяме текста на публикациите на новия потребител и показваме, че искаме да получим обратно името на потребителя и UUID като отговор.
Поставете горния текст в лявата част на Playground и щракнете върху бутона Игра. Вдясно ще видите изхода на заявката:
Сега нека да запитаме за този потребител:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
Това ни връща името и UUID на потребителя, който току-що създадохме. Кокетно!
Можем да направим същото с другите бекендове, PostgreSQL и Aurora. За това просто трябва да заменим имената на мутацията с postgres_createUser или aurora_createUser, а заявките с postgres_getUser или aurora_getUser. Опитайте го сами! (Имайте предвид, че потребителите не се синхронизират между базите данни, така че ще можете да правите заявки само за потребители, които сте създали във всяка конкретна база данни.)
Сравняване на реализациите на MySQL, PostgreSQL и Aurora
Като начало, мутациите и заявките изглеждат абсолютно еднакви в Aurora и MySQL, тъй като Aurora е съвместима с MySQL. И има само минимални разлики в кода между тези две и реализацията на Postgres.
Всъщност, за прости случаи на използване, най-голямата разлика между нашите три бази данни е, че Aurora е достъпна само като клъстер. Най-малката налична конфигурация на Aurora все още включва една реплика само за четене и една реплика за запис, така че имаме нужда от клъстерна конфигурация дори за това основно внедряване на Aurora.
Aurora предлага по-бърза производителност от MySQL и PostgreSQL, което се дължи главно на SSD оптимизациите, направени от Amazon към двигателя на базата данни. С разрастването на вашия проект вероятно ще откриете, че Aurora предлага подобрена мащабируемост на базата данни, по-лесна поддръжка и по-добра надеждност в сравнение с конфигурациите по подразбиране на MySQL и PostgreSQL. Но можете да направите някои от тези подобрения и в MySQL и PostgreSQL, ако настроите базите си и добавите репликация.
За тестови проекти и детски площадки препоръчваме MySQL или PostgreSQL. Те могат да работят на db.t2.micro RDS екземпляри, които са част от безплатното ниво на AWS. Aurora в момента не предлага db.t2.micro екземпляри, така че ще платите малко повече, за да използвате Aurora за този тестов проект.
Последна важна бележка
Не забравяйте да премахнете внедряването си без сървър след като приключите с изпробването на GraphQL API, така че да не продължавате да плащате за ресурси на базата данни, които вече не използвате.
Можете да премахнете стека, създаден в този пример, като изпълните npm run remove в корена на проекта.
Приятно експериментиране!
Резюме
В тази статия ви преведехме през създаването на прост GraphQL API, използвайки три различни бази данни наведнъж; въпреки че това не е нещо, което някога бихте направили в действителност, това ни позволи да сравним прости реализации на базите данни Aurora, MySQL и PostgreSQL. Видяхме, че реализацията и за трите бази данни е приблизително еднаква в нашия прост случай, с изключение на малки разлики в синтаксиса и конфигурациите за внедряване.
Можете да намерите пълния примерен проект, който използвахме в това репо на GitHub. Най-лесният начин да експериментирате с проекта е да клонирате репото и да го разположите от вашата машина с помощта на npm run deploy.
За повече примери за GraphQL API, използващи без сървър, вижте репото без сървър-graphql.
Ако искате да научите повече за стартирането на безсървърни GraphQL API в мащаб, може да се насладите на нашата поредица от статии „Изпълнение на мащабируема и надеждна крайна точка на GraphQL с безсървърна“
Може би GraphQL просто не е вашият проблем и предпочитате да внедрите REST API? Разбрахме ви:разгледайте тази публикация в блога за някои примери.
Въпроси? Коментирайте тази публикация или създайте дискусия в нашия форум.
Публикувано първоначално на https://www.serverless.com.