Докато настройвате postgresql.conf , може би сте забелязали, че има опция, наречена full_page_writes . Коментарът до него казва нещо за частично записване на страници и хората обикновено го оставят на on – което е хубаво нещо, както ще обясня по-късно в тази публикация. Полезно е обаче да разберете какво правят записите на цяла страница, защото въздействието върху производителността може да е доста значително.
За разлика от предишната ми публикация относно настройката на контролни точки, това не е ръководство как да настроите сървъра. Всъщност няма много неща, които можете да настроите, но ще ви покажа как някои решения на ниво приложение (например избор на типове данни) могат да взаимодействат с записите на цяла страница.
Частични записи/Разкъсани страници
И така, за какво пише цялата страница? Като коментар в postgresql.conf казва, че това е начин за възстановяване от частични записи на страници – PostgreSQL използва 8kB страници (по подразбиране), но други части от стека използват различни размери на парчета. Файловите системи на Linux обикновено използват 4kB страници (възможно е да се използват по-малки страници, но 4kB е максимумът за x86), а на хардуерно ниво старите дискове използват 512B сектори, докато новите устройства често записват данни на по-големи парчета (често 4kB или дори 8kB) .
Така че, когато PostgreSQL напише 8kB страницата, другите слоеве на стека за съхранение може да го разделят на по-малки парчета, управлявани отделно. Това представлява проблем по отношение на атомарността на записа. 8kB PostgreSQL страницата може да бъде разделена на две страници от 4kB файлова система и след това на 512B сектора. Сега, какво ще стане, ако сървърът се срине (срив в захранването, грешка в ядрото, ...)?
Дори ако сървърът използва система за съхранение, предназначена да се справи с такива повреди (SSD дискове с кондензатори, RAID контролери с батерии, ...), ядрото вече разделя данните на 4kB страници. Така че е възможно базата данни да е записала страница с данни от 8 kB, но само част от нея е била на диска преди срива.
В този момент вероятно си мислите, че точно това е причината да имаме дневник на транзакциите (WAL) и сте прави! Така че след стартиране на сървъра, базата данни ще прочете WAL (от последната завършена контролна точка) и ще приложи промените отново, за да се увери, че файловете с данни са завършени. Просто.
Но има уловка – възстановяването не прилага промените сляпо, често трябва да чете страниците с данни и т.н. Което предполага, че страницата не е вече блокирана по някакъв начин, например поради частично записване. Което изглежда малко противоречиво, защото за да коригираме повреда на данните, приемаме, че няма повреда на данните.
Записването на цяла страница е начин за заобикаляне на тази главоблъсканица – когато модифицирате страница за първи път след контролна точка, цялата страница се записва в WAL. Това гарантира, че по време на възстановяването първият WAL запис, докосващ страница, съдържа цялата страница, елиминирайки необходимостта от четене на – евентуално счупена – страница от файла с данни.
Усилване на запис
Разбира се, негативната последица от това е увеличеният размер на WAL – промяната на един байт на 8kB страница ще регистрира целия в WAL. Записването на цяла страница се случва само при първото записване след контролна точка, така че правенето на контролни точки по-рядко е един от начините за подобряване на ситуацията – обикновено има кратък „поредица“ от запис на цяла страница след контролна точка и след това относително малко записвания на цяла страница до края на контролен пункт.
UUID срещу BIGSERIAL ключове
Но има някои неочаквани взаимодействия с дизайнерските решения, взети на ниво приложение. Да предположим, че имаме проста таблица с първичен ключ, или BIGSERIAL или UUID и вмъкваме данни в него. Ще има ли разлика в количеството генериран WAL (ако приемем, че вмъкнем същия брой редове)?
Изглежда разумно да се очаква и двата случая да произвеждат приблизително еднакво количество WAL, но както илюстрират следващите диаграми, има огромна разлика на практика.
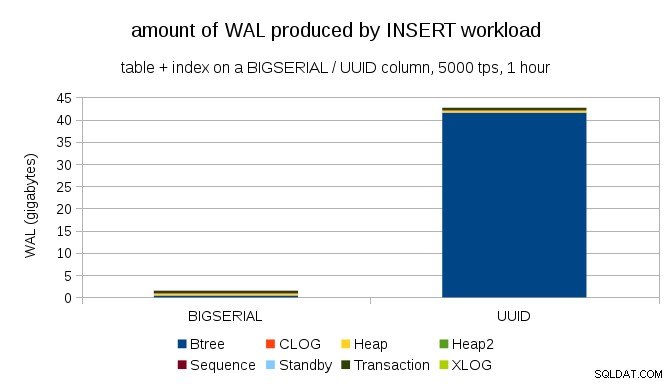
Това показва количеството WAL, произведено по време на бенчмарк за 1 час, намалено до 5000 вмъквания в секунда. С BIGSERIAL първичен ключ това произвежда ~2GB WAL, докато с UUID това е повече от 40GB. Това е доста значителна разлика и съвсем ясно по-голямата част от WAL е свързана с индекс, който поддържа първичния ключ. Нека разгледаме видовете WAL записи.
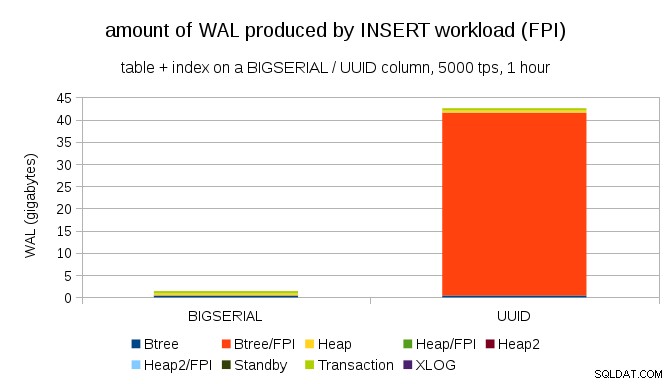
Ясно е, че огромното мнозинство от записите са изображения на цяла страница (FPI), т.е. резултат от запис на цяла страница. Но защо се случва това?
Разбира се, това се дължи на присъщия UUID случайност. С BIGSERIAL new са последователни и така се вмъкват в едни и същи листни страници в индекса btree. Тъй като само първата модификация на страница задейства записването на цяла страница, само малка част от записите на WAL са FPI. С UUID това е напълно различен случай, разбира се – стойностите изобщо не са последователни, всъщност всяко вмъкване е вероятно да докосне изцяло нова листна страница с индекс на листа (ако приемем, че индексът е достатъчно голям).
Базата данни не може да направи много – натоварването е просто произволно по природа, което задейства много записвания на цяла страница.
Не е трудно да получите подобно усилване при запис дори с BIGSERIAL ключове, разбира се. Изисква само различно работно натоварване – например с UPDATE натоварване, произволно актуализиране на записи с равномерно разпределение, диаграмата изглежда така:
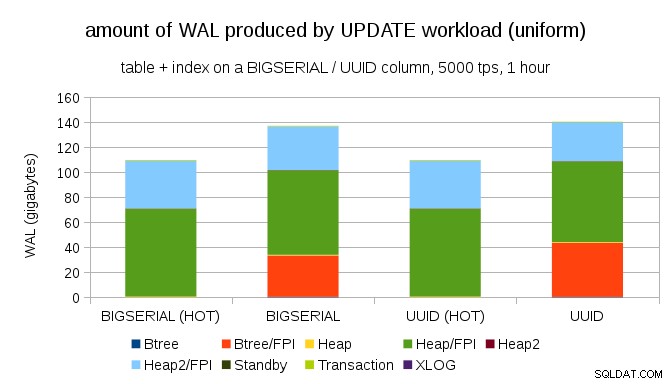
Изведнъж разликите между типовете данни изчезват – достъпът е случаен и в двата случая, което води до почти същото количество произведени WAL. Друга разлика е, че по-голямата част от WAL е свързана с „хийп“, т.е. таблици, а не индекси. Случаите „HOT“ са проектирани да позволят оптимизация HOT UPDATE (т.е. актуализиране, без да се налага докосване на индекс), което почти елиминира целия WAL трафик, свързан с индексите.
Но може да възразите, че повечето приложения не актуализират целия набор от данни. Обикновено само малка част от данни е „активна“ – хората имат достъп само до публикации от последните няколко дни в дискусионен форум, нерешени поръчки в електронен магазин и т.н. Как това променя резултатите?
За щастие, pgbench поддържа неравномерни разпределения и например с експоненциално разпределение, докосващо 1% подмножество от данни в ~25% от времето, диаграмата изглежда така:
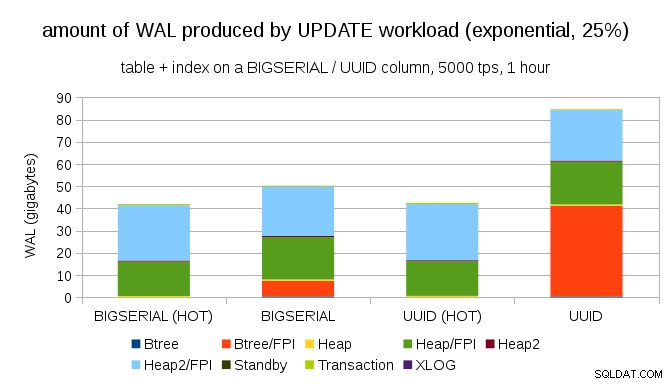
И след като направи разпределението още по-изкривено, докосвайки подмножеството от 1% в ~75% от времето:
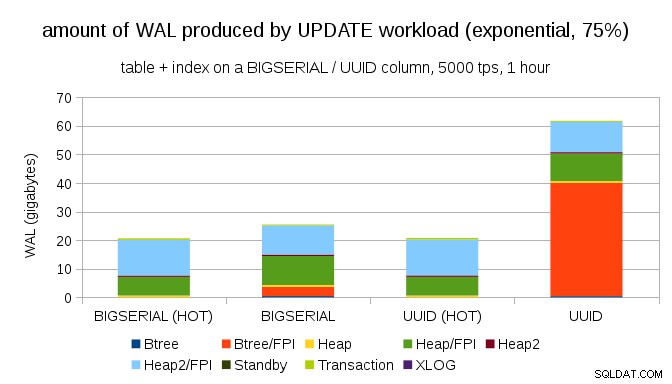
Това отново показва колко голяма разлика може да направи изборът на типове данни, както и важността на настройката за ГОРЕЩИ актуализации.
8kB и 4kB страници
Интересен въпрос е колко WAL трафик бихме могли да спестим, като използваме по-малки страници в PostgreSQL (което изисква компилиране на персонализиран пакет). В най-добрия случай може да спести до 50% WAL, благодарение на регистрирането само на 4kB вместо 8kB страници. За натоварването с равномерно разпределени актуализации изглежда така:
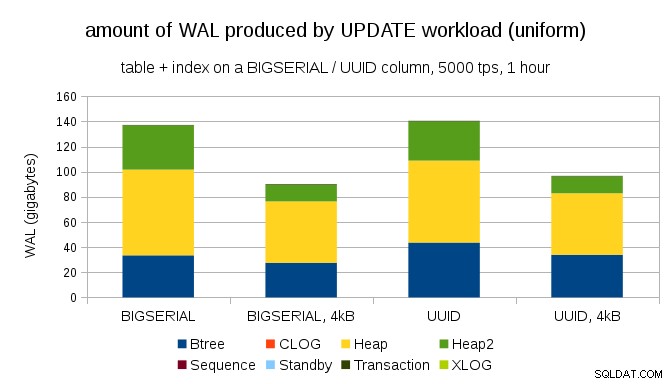
Така че спестяването не е точно 50%, но намаляването от ~140GB на ~90GB все още е доста значително.
Все още ли имаме нужда от запис на цяла страница?
Може да изглежда смешно, след като се обясни опасността от частични записи, но може би деактивирането на записите на цяла страница може да е жизнеспособна опция, поне в някои случаи.
Първо, чудя се дали съвременните файлови системи на Linux все още са уязвими за частични записи? Параметърът е въведен в PostgreSQL 8.1, издаден през 2005 г., така че може би някои от многото подобрения на файловата система, въведени оттогава, правят това непроблемно. Вероятно не е универсално за произволни натоварвания, но може би приемането на някакво допълнително условие (например използване на 4kB размер на страницата в PostgreSQL) би било достатъчно? Освен това PostgreSQL никога не презаписва само подмножество от 8kB страница – цялата страница винаги се изписва.
Наскоро направих много тестове, опитвайки се да задействам частично запис, и все още не съм успял да предизвикам нито един случай. Разбира се, това не е доказателство, че проблемът не съществува. Но дори ако все още е проблем, контролните суми на данните може да са достатъчна защита (няма да отстрани проблема, но поне ще ви уведоми, че има повредена страница).
На второ място, много системи в днешно време разчитат на стрийминг репликиращи реплики – вместо да чакат сървърът да се рестартира след хардуерен проблем (който може да отнеме доста време) и след това да отделят повече време за възстановяване, системите просто преминават към горещ режим на готовност. Ако базата данни на неуспешния първичен елемент бъде премахната (и след това клонирана от новата основна), частичните записи не са проблем.
Но предполагам, че ако започнем да препоръчваме това, тогава „Не знам как данните са се повредили, просто зададох full_page_writes=off на системите!“ ще се превърне в едно от най-често срещаните присъди точно преди смъртта за DBA (заедно с „Виждал съм тази змия в Reddit, не е отровна.“).
Резюме
Не можете да направите много, за да настроите директно записите на цяла страница. За повечето натоварвания повечето записвания на цяла страница се случват веднага след контролна точка и след това изчезват до следващата контролна точка. Затова е важно да настроите контролните точки, за да не се случват твърде често.
Някои решения на ниво приложение могат да увеличат произволността на записите в таблици и индекси – например стойностите на UUID са по своята същност произволни, превръщайки дори простото натоварване на INSERT в произволни актуализации на индекса. Схемата, използвана в примерите, беше доста тривиална – на практика ще има вторични индекси, външни ключове и т.н. Но използването на BIGSERIAL първични ключове вътрешно (и запазването на UUID като сурогатни ключове) поне би намалило усилването при запис.
Наистина се интересувам от дискусия относно необходимостта от писане на цяла страница в текущите ядра/файлови системи. За съжаление не намерих много ресурси, така че ако имате подходяща информация, уведомете ме.