Бенджамин Неварез е независим консултант със седалище в Лос Анджелис, Калифорния, който е специализиран в настройката и оптимизацията на заявки на SQL Server. Той е автор на „SQL Server 2014 Query Tuning &Optimization“ и „Inside the SQL Server Query Optimizer“ и съавтор на „SQL Server 2012 Internals“. С повече от 20 години опит в релационни бази данни, Бенджамин е бил и лектор на много конференции на SQL Server, включително PASS Summit, SQL Server Connections и SQLBits. Блогът на Бенджамин може да бъде намерен на адрес https://www.benjaminnevarez.com и той може да бъде достигнат и по имейл на admin на benjaminnevarez dot com и в Twitter на @BenjaminNevarez.
Докато по-голямата част от информацията, блоговете и документацията за SQL Server 2014 са фокусирани върху Hekaton и други нови функции, не са предоставени много подробности за новия оценител на мощността. Понастоящем BOL само индиректно говори за това в секцията Какво е новото (Database Engine), като казва, че SQL Server 2014 „включва съществени подобрения на компонента, който създава и оптимизира планове за заявки,“ и ALTER DATABASE изявление показва как да активирате или деактивирате неговото поведение. За щастие можем да получим допълнителна информация, като прочетем изследователската статия Тестване на модели за оценка на кардиналността в SQL Server от Campbell Fraser et al. Въпреки че фокусът на документа е процесът на осигуряване на качеството на новия модел за оценка, той също така предлага основно въведение в новия оценител на мощността и мотивацията на неговия нов дизайн.
И така, какво е оценка на мощността? Оценителят на мощността е компонентът на процесора на заявки, чиято задача е да оцени броя на редовете, върнати от релационни операции в заявка. Тази информация, заедно с някои други данни, се използва от оптимизатора на заявки за избор на ефективен план за изпълнение. Оценката на кардиналността по своята същност е неточна, тъй като е математически модел, който разчита на статистическа информация. Също така се основава на няколко предположения, които, макар и да не са документирани, са били известни през годините – някои от тях включват предположения за еднообразие, независимост, ограничаване и включване. Следва кратко описание на тези предположения.
- Еднородност . Използва се, когато разпределението за даден атрибут е неизвестно, например вътре в редовете на диапазона в стъпка на хистограма или когато хистограмата не е налична.
- Независимост . Използва се, когато атрибутите в една връзка са независими, освен ако не е известна корелация между тях.
- Задържане . Използва се, когато два атрибута може да са еднакви, се приема, че са еднакви.
- Включване . Използва се при сравняване на атрибут с константа, предполага се, че винаги има съвпадение.
Интересно е, че съвсем наскоро говорих за някои от ограниченията на тези предположения в последния си разговор на срещата PASS, наречен Преодоляване на ограниченията на оптимизатора на заявки. И все пак бях изненадан да прочета в статията, че авторите признават, че според техния практически опит тези предположения „често са неверни.
Настоящият оценител на мощността е написан заедно с целия процесор на заявки за SQL Server 7.0, който беше пуснат през декември 1998 г. Очевидно този компонент е претърпял множество промени през няколко години и множество версии на SQL Server, включително поправки, корекции и разширения за приспособяване на оценка на мощността за нови T-SQL функции. Така че може би си мислите защо да сменяте компонент, който се използва успешно от около 15 години?
Защо нов оценител на мощността
Документът обяснява някои от причините за редизайна, включително:
- За да приспособи оценителя на мощността към нови модели на работно натоварване.
- Промените, направени в оценителя на мощността през годините, направиха компонента труден за „отстраняване на грешки, прогнозиране и разбиране“.
- Опитът за подобряване на текущия модел беше труден с помощта на текущата архитектура, така че беше създаден нов дизайн, фокусиран върху разделянето на задачите на (а) решаване как да се изчисли конкретна оценка и (б) действително извършване на изчислението .
Не съм сигурен дали Microsoft ще публикува повече подробности за новия оценител на мощността. В края на краищата, не са били публикувани толкова много подробности за стария кардинален оценител за 15 години; например как се изчислява някаква специфична оценка на мощността. От друга страна, има нови разширени събития, които можем да използваме за отстраняване на проблеми с оценката на мощността или просто за да проучим как работи. Тези събития включват query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors и query_rpc_set_cardinality .
Планирайте регресиите
Основен проблем, който идва на ум при такава огромна промяна в оптимизатора на заявки, е регресията на плана. Страхът от регресия на плана се счита за най-голямата пречка пред подобренията на оптимизатора на заявки. Регресиите са проблеми, въведени след прилагане на корекция към оптимизатора на заявки и понякога наричани класическото „две грешки правят правилно“. Това може да се случи, когато две лоши оценки, например едната, която надценява стойност, а втората я подценява, се компенсират взаимно, за щастие давайки добра оценка. Коригирането само на една от тези стойности вече може да доведе до лоша оценка, която може да повлияе негативно на избора на избор на план, причинявайки регресия.
За да се избегнат регресии, свързани с новия оценител на мощността, SQL Server предоставя начин да го активирате или деактивирате, тъй като зависи от нивото на съвместимост на базата данни. Това може да се промени с помощта на ALTER DATABASE изявление, както беше посочено по-рано. Задаването на база данни на ниво на съвместимост 120 ще използва новия оценител на мощността, докато ниво на съвместимост по-малко от 120 ще използва стария оценител на мощността. Освен това, след като използвате специфичен оценител на мощността, има два флага за проследяване, които можете да използвате, за да промените към другия. Въпреки че в момента не виждам никъде документирани флагове за проследяване, те са споменати като част от описанието на query_optimizer_force_both_cardinality_estimation_behaviors разширено събитие. Флагът за проследяване 2312 може да се използва за активиране на новия оценител на мощността, докато флагът за проследяване 9481 може да се използва за деактивирането му. Можете дори да използвате флаговете за проследяване за конкретна заявка, като използвате QUERYTRACEON намек (въпреки че все още не е документирано дали и това ще се поддържа).
Примери
И накрая, документът споменава и някои тествани сценарии като пренаселения първичен ключ, простото присъединяване или проблема с възходящия ключ. Той също така показва как авторите експериментират с множество сценарии (или вариации на модела) и в някои случаи „отпускат“ някои от предположенията, направени от оценителя на мощността, например в случая на допускането за независимост, преминавайки от пълна независимост към пълна корелация и нещо между тях, докато се намерят добри резултати.
Въпреки че в документа не са предоставени подробности, решавам да започна да тествам някои от тези сценарии, за да се опитам да разбера как работи новият оценител на мощността. За сега ще ви покажа пример с помощта на предположението за независимост и възходящите ключове. Тествах и предположението за еднородност, но досега не успях да намеря разлика в оценката.
Нека започнем с примера за предположение за независимост. Първо нека видим текущото поведение. За това се уверете, че използвате стария оценител на мощността, като изпълните следното изявление в базата данни AdventureWorks2012:
ПРОМЕНЯ БАЗА ДАННИ AdventureWorks2012 ЗАДАЙТЕ COMPATIBILITY_LEVEL =110;
След това стартирайте:
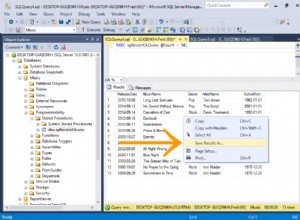
SELECT * FROM Person.Address WHERE Град ='Burbank';
Получаваме приблизително 196 записа, както е показано по-долу:

По подобен начин следното твърдение ще получи оценка от 194:
ИЗБЕРЕТЕ * ОТ Личност. Адрес КЪДЕ Пощенски код ='91502';
Ако използваме и двата предиката, имаме следната заявка, която ще има приблизителен брой редове от 1,93862 (закръглено до 2 реда, ако използвате SQL Sentry Plan Explorer):
ИЗБЕРЕТЕ * ОТ Личност. Адрес WHERE Град ='Бърбанк' И Пощенски код ='91502';
Тази стойност се изчислява, като се приеме пълната независимост на двата предиката, която използва формулата (196 * 194) / 19614.0 (където 19614 е общият брой редове в таблицата). Използването на обща корелация би трябвало да ни даде оценка от 194, тъй като всички записи с пощенски код 91502 принадлежат на Бърбанк. Новият оценител на мощността оценява стойност, която не предполага пълна независимост или пълна корелация. Променете към новия оценител на мощността, като използвате следното изявление:
ПРОМЕНИ БАЗА ДАННИ AdventureWorks2012 ЗАДАЙТЕ СЪВМЕСТИМОСТ_НИВО =120; ИЗБЕРЕТЕ ИЗБЕРЕТЕ * ОТ Личност. Адрес КЪДЕ Град ='Бърбанк' И Пощенски код ='91502';
Изпълнението на същото изявление отново ще даде оценка от 19,3931 реда, което можете да видите, че е стойност между приемането на пълна независимост и пълната корелация (закръглена до 19 реда в Plan Explorer). Използваната формула е селективност на най-селективния филтър * SQRT (селективност на следващия най-селективен филтър) или (194/19614.0) * SQRT(196/19614.0) * 19614, което дава 19,393:

Ако сте активирали новия оценител на мощността на ниво база данни buy искате да го деактивирате за конкретна заявка, за да избегнете регресия на плана, можете да използвате флаг за проследяване 9481, както беше обяснено по-рано:
ПРОМЕНИ БАЗА ДАННИ AdventureWorks2012 ЗАДАЙТЕ СЪВМЕСТИМОСТ_НИВО =120; ИЗБЕРЕТЕ ИЗБЕРЕТЕ * ОТ Личност. Адрес КЪДЕ Град ='Burbank' И Пощенски код ='91502' ОПЦИЯ (QUERYTRACEON 9481);
Забележка:Подсказката за заявка QUERYTRACEON се използва за прилагане на флаг за проследяване на ниво заявка и в момента се поддържа само в ограничен брой сценарии. За повече информация относно съвета за заявка QUERYTRACEON можете да разгледате https://support.microsoft.com/kb/2801413.
Сега нека разгледаме проблема с възходящия ключ, тема, която обясних по-подробно в тази публикация. Традиционната препоръка от Microsoft за отстраняване на този проблем е ръчно актуализиране на статистиката след зареждане на данни, както е обяснено тук – което описва проблема по следния начин:
Статистическите данни за възходящи или низходящи ключови колони, като IDENTITY или колони с времеви отпечатъци в реално време, може да изискват по-чести актуализации на статистиката, отколкото оптимизаторът на заявки извършва. Операциите за вмъкване добавят нови стойности към възходящи или низходящи колони. Броят на добавените редове може да е твърде малък, за да задейства актуализация на статистическите данни. Ако статистическите данни не са актуални и заявките избират от най-скоро добавените редове, текущите статистически данни няма да имат оценки за кардиналност за тези нови стойности. Това може да доведе до неточни оценки за мощността и бавна производителност на заявката. Например, заявка, която избира от най-новите дати на поръчки за продажба, ще има неточни оценки за кардиналност, ако статистическите данни не се актуализират, за да включват оценки за мощността за най-новите дати на поръчки за продажба.
Препоръката в моята статия беше да се използват флагове за проследяване 2389 и 2390, които бяха публикувани за първи път от Иън Хосе в неговата статия Ascending Keys и Auto Quick Corrected Statistics. Можете да прочетете моята статия за обяснение и пример как да използвате тези флагове за проследяване, за да избегнете този проблем. Тези флагове за проследяване все още работят на SQL Server 2014 CTP2. Но още по-добре, те вече не са необходими, ако използвате новия оценител на мощността.
Използвайки същия пример в моята публикация:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.SalesOrderHeader ( SalesOrderID int NOT NULL, RevisionNumber tinyint NOT NULL, OrderDate datetime NOT NULL, DueDate datetime NOT NULL, ShipDate datetime NULL, Status tinyint NOT NULL, NOT NULL, NOT NULL, NOT NULL, NOT NULL, NOT NULL. NOT NULL, PurchaseOrderNumber dbo.OrderNumber NULL, AccountNumber dbo.AccountNumber NULL, CustomerID int NOT NULL, SalesPersonID int NULL, TerritoryID int NULL, BillToAddressID int NOT NULL, ShipToAddressID int NOT NULL, ShipToAddressID int NOT NULL, ShipToAddressID int NOT NULL, ShipToAddressID int NOT NULL, ShipTopcharNuard in ShipTopchar NUARD in ShipTopchar NUARD 15) NULL, CurrencyRateID int NULL, SubTotal money NOT NULL, TaxAmt money NOT NULL, Freight money NOT NULL, TotalDue money NOT NULL, Comment nvarchar(128) NULL, rowguid uniqueidentifier NOT NULL, NOTDate date);Вмъкнете някои данни:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < „2008-07-20 00:00:00,000“; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);Тъй като създадохме индекс, ние просто имаме нова статистика. Изпълнението на следната заявка ще създаде добра оценка от 35 реда:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate ='2008-07-19 00:00:00.000';Ако вмъкнем нови данни:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate ='2008-07-20 00:00:00.000';Можете да видите оценката със стария оценител на мощността, както е показано по-долу:
ПРОМЕНИ БАЗА ДАННИ AdventureWorks2012 ЗАДАЙТЕ COMPATIBILITY_LEVEL =110;GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate ='2008-07-20 00:00:00.000';
Тъй като малкият брой вмъкнати записи не е достатъчен, за да задейства автоматична актуализация на статистическия обект, текущата хистограма не знае за добавените нови записи и оптимизаторът на заявки използва приблизително 1 ред. По избор можете да използвате флагове за проследяване 2389 и 2390, за да помогнете за получаване на по-добра оценка. Но ако опитате същата заявка с новия оценител на мощността, ще получите следната оценка:
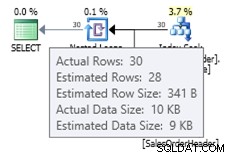
ПРОМЕНИ БАЗА ДАННИ AdventureWorks2012 ЗАДАЙТЕ COMPATIBILITY_LEVEL =120;GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate ='2008-07-20 00:00:00.000';
В този случай получаваме по-добра оценка от стария оценител на мощността (или получаваме същата оценка като използването на флагове за проследяване 2389 или 2390). Приблизителната стойност от 27,9631 (отново закръглена до 28 от Plan Explorer) се изчислява с помощта на информацията за плътността на статистическия обект, умножена по броя на редовете в таблицата; тоест 0,0008992806 * 31095. Стойността на плътността може да бъде получена с помощта на:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate');И накрая, имайте предвид, че нищо споменато в тази статия не е документирано и това е поведението, което наблюдавах досега в SQL Server 2014 CTP2. Всичко от това може да се промени в по-късна CTP или RTM версия на продукта.