В предишната публикация в блога накратко обясних как получихме числата за ефективност, публикувани в pglogical съобщение. В тази публикация в блога бих искал да обсъдя ограниченията на производителността на решенията за логическа репликация като цяло, както и как те се прилагат към pglogical.
физическа репликация
Първо, нека видим как работи физическата репликация (вградена в PostgreSQL от версия 9.0). Донякъде опростена фигура с два само два възела изглежда така:
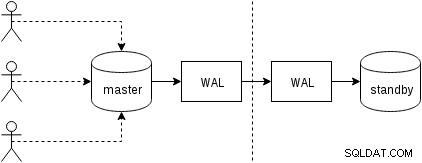
Клиентите изпълняват заявки на главния възел, промените се записват в дневника на транзакциите (WAL) и се копират по мрежа в WAL на възел в режим на готовност. Процесът на възстановяване в режим на готовност в режим на готовност след това чете промените от WAL и ги прилага към файловете с данни точно както по време на възстановяване. Ако режимът на готовност е в режим „hot_standby“, клиентите могат да издават заявки само за четене на възела, докато това се случва.
Това е много ефективно, тъй като има много малко допълнителна обработка – промените се прехвърлят и записват в режим на готовност като непрозрачен двоичен blob. Разбира се, възстановяването не е безплатно (както по отношение на процесора, така и по отношение на I/O), но е трудно да станете по-ефективни от това.
Очевидните потенциални пречки при физическото репликация са мрежовата честотна лента (прехвърляне на WAL от главен към режим на готовност), както и I/O в режим на готовност, които могат да бъдат наситени от процеса на възстановяване, който често издава много произволни I/O заявки ( в някои случаи повече от майстора, но нека не навлизаме в това).
логическа репликация
Логическата репликация е малко по-сложна, тъй като не се занимава с непрозрачен двоичен WAL поток, а с поток от „логически“ промени (представете си INSERT, UPDATE или DELETE оператори, въпреки че това не е напълно правилно, тъй като имаме работа със структурирано представяне на информацията). Наличието на логически промени ви позволява да правите интересни неща като разрешаване на конфликти, репликиране само на избрани таблици, в различна схема или между различни версии (или дори различни бази данни).
Има различни начини за получаване на промените – традиционният подход е чрез използване на тригери, записващи промените в таблица, и позволяване на персонализиран процес непрекъснато да чете тези промени и да ги прилага в режим на готовност чрез изпълнение на SQL заявки. И всичко това се задвижва от външен демон процес (или евентуално множество процеси, работещи на двата възела), както е показано на следващата фигура

Това правят slony или londiste и макар да работи доста добре, това означава много режийни разходи – например изисква улавяне на промените в данните и записване на данните многократно (в оригиналната таблица и в таблица с „регистрационни файлове“ и също към WAL и за двете таблици). По-късно ще обсъдим други източници на режийни разходи. Въпреки че pglogical трябва да постигне едни и същи цели, той ги постига по различен начин, благодарение на няколко функции, добавени към последните версии на PostgreSQL (по този начин не са налични при прилагането на другите инструменти):

Тоест, вместо да поддържа отделен регистър на промените, pglogical разчита на WAL – това е възможно благодарение на логическото декодиране, налично в PostgreSQL 9.4, което позволява извличане на логически промени от WAL log. Благодарение на това pglogical не се нуждае от никакви скъпи тригери и обикновено може да избегне записването на данните два пъти на главния (с изключение на големи транзакции, които могат да се разлеят на диск).
След декодиране на всяка транзакция, тя се прехвърля в режим на готовност и процесът на прилагане прилага промените си към резервната база данни. pglogical не прилага промените, като изпълнява редовни SQL заявки, а на по-ниско ниво, заобикаляйки допълнителните разходи, свързани с анализа и планирането на SQL заявки. Това дава на pglogical значително предимство пред съществуващите решения, които всички преминават през SQL слоя (като по този начин заплащат анализа и планирането).
потенциални пречки
Ясно е, че логическата репликация е податлива на същите тесни места като физическата репликация, т.е. възможно е да се насити мрежата при прехвърляне на промените и I/O в режим на готовност, когато се прилагат в режим на готовност. Освен това има доста режийни разходи поради допълнителни стъпки, които не присъстват във физическа репликация.
Трябва по някакъв начин да съберем логическите промени, докато физическата репликация просто препраща WAL като поток от байтове. Както вече споменахме, съществуващите решения обикновено разчитат на тригери, записващи промените в „регистрационна“ таблица. pglogical вместо това разчита на дневника за предварителна запис (WAL) и логическото декодиране, за да постигне едно и също нещо, което е по-евтино от тригерите и също така не е необходимо да записва данните два пъти в повечето случаи (с допълнителния бонус, че автоматично прилагаме промените в ред на извършване).
Това не означава, че няма възможности за допълнително подобрение – например декодирането в момента се случва само след като транзакцията бъде ангажирана, така че при големи транзакции това може да увеличи забавянето на репликацията. Физическата репликация просто предава поточно промените в WAL към другия възел и по този начин няма това ограничение. Големите транзакции също могат да се разлеят на диска, причинявайки дублирани записи, тъй като горният поток трябва да ги съхранява, докато не се ангажират и те могат да бъдат изпратени надолу по веригата.
Планирана е бъдещата работа, която да позволи на pglogical да започне да предава поточно големи транзакции, докато те все още са в ход на възходящата верига, намалявайки латентността между записване нагоре и надолу по веригата и намалявайки усилването на записа нагоре по веригата.
След като промените бъдат прехвърлени в режим на готовност, процесът на прилагане трябва действително да ги приложи по някакъв начин. Както беше споменато в предишния раздел, съществуващите решения направиха това чрез конструиране и изпълнение на SQL команди, докато pglogical заобикаля изцяло SQL слоя и свързаните режийни разходи.
Все пак това не прави приложението напълно безплатно, тъй като все още трябва да извършва неща като търсене на първичен ключ, актуализиране на индекси, изпълнение на тригери и различни други проверки. Но това е значително по-евтино от подхода, базиран на SQL. В известен смисъл работи много като COPY и е особено бърз на прости таблици без тригери, външни ключове и т.н.
Във всички решения за логическа репликация всяка от тези стъпки (декодиране и прилагане) се случва в един процес, така че има доста ограничено време на процесора. Това вероятно е най-належащото препятствие във всички съществуващи решения, защото може да имате доста мощна машина с десетки или дори стотици клиенти, изпълняващи заявки паралелно, но всичко това трябва да премине през един-единствен процес, декодиращ тези промени (на master) и един процес, прилагащ тези промени (в режим на готовност).
Ограничението "един процес" може да бъде малко облекчено чрез използване на отделни бази данни, тъй като всяка база данни се обработва от отделен процес. Когато става въпрос за единна база данни, бъдещата работа е планирана за паралелизиране на прилагането чрез група от фонови работници, за да се облекчи това тесно място.