В първата част от тази поредица от блогове, представих няколко резултата от сравнителния анализ, показващи как се е променила производителността на PostgreSQL OLTP след 8.3, издадена през 2008 г. В тази част смятам да направя същото, но за аналитични/BI заявки, обработващи големи количества данни.
Има редица индустриални еталони за тестване на това работно натоварване, но вероятно най-често използваният е TPC-H, така че това ще използвам за тази публикация в блога. Има и TPC-DS, друг бенчмарк на TPC за тестване на системи за подкрепа на вземане на решения, който може да се разглежда като еволюция или замяна на TPC-H. Реших да се придържам към TPC-H по няколко причини.
Първо, TPC-DS е много по-сложен, както по отношение на схемата (повече таблици), така и по отношение на броя на заявките (22 срещу 99). Настройването на това правилно, особено когато се работи с множество версии на PostgreSQL, би било много по-трудно. Второ, някои от заявките на TPC-DS използват функции, които не се поддържат от по-старите версии на PostgreSQL (например групиране на набори), което прави тези заявки неуместни за някои версии. И накрая, бих казал, че хората са много по-запознати с TPC-H в сравнение с TPC-DS.
Целта на това е да не се позволи сравнение с други продукти за бази данни, а само да се предостави разумна дългосрочна характеристика за това как се е развила производителността на PostgreSQL след PostgreSQL 8.3.
Забележка :За един много интересен анализ на бенчмарка на TPC-H, силно препоръчвам документа „TPC-H Анализирани:скрити съобщения и поуки, извлечени от влиятелен еталон“ от Boncz, Neumann и Erling.
Хардуерът
Повечето от резултатите в тази публикация в блога идват от „по-голямата кутия“, която имам в нашия офис, която има следните параметри:
- 2x E5-2620 v4 (16 ядра, 32 нишки)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (данни)
- 3 x 7,2k SATA RAID0 (временно пространство за таблици)
- ядро 5.6.15, файлова система ext4
Сигурен съм, че можете да закупите значително по-добри машини, но вярвам, че това е достатъчно добро, за да ни даде подходящи данни. Имаше два варианта на конфигурация – единият с деактивиран паралелизъм, единият с активиран паралелизъм. Повечето от стойностите на параметрите са еднакви и в двата случая, настроени към наличните хардуерни ресурси (CPU, RAM, памет). Можете да намерите по-подробна информация за конфигурацията в края на тази публикация.
Еталон
Искам да уточня, че целта ми не е да прилагам валиден бенчмарк за TPC-H, който да отговаря на всички критерии, изисквани от TPC. Целта ми е да оценя как се е променила ефективността на различните аналитични заявки с течение на времето, а не да преследвам някаква абстрактна мярка за ефективност на долар или нещо подобно.
Така че реших да използвам само подмножество от TPC-H – по същество просто заредя данните и изпълнявам 22-те заявки (едни и същи параметри във всички версии). Няма обновяване на данни, наборът от данни е статичен след първоначалното зареждане. Избрах редица мащабни фактори, 1, 10 и 75, така че да имаме резултати за съвпадения в споделените буфери (1), съвпадения в паметта (10) и повече от памет (75) . Бих избрал 100, за да го направя „хубава последователност“, която в някои случаи няма да се побере в хранилището от 280 GB (благодарение на индекси, временни файлове и т.н.). Имайте предвид, че мащабният коефициент 75 дори не се разпознава от TPC-H като валиден мащабен коефициент.
Но има ли дори смисъл да се сравняват 1GB или 10GB набори от данни? Хората са склонни да се фокусират върху много по-големи бази данни, така че може да изглежда малко глупаво да се занимаваме с тестването им. Но не мисля, че това би било полезно – по-голямата част от базите данни в дивата природа са доста малки, според моя опит И дори когато цялата база данни е голяма, хората обикновено работят само с малка част от нея – скорошни данни, неразрешени поръчки и т.н. Така че смятам, че има смисъл да се тества дори с тези малки набори от данни.
Зареждане на данни
Първо, нека видим колко време отнема зареждането на данни в базата данни - без и с паралелизъм. Ще покажа само резултати от набора от 75 GB данни, тъй като цялостното поведение е почти същото за по-малките случаи.
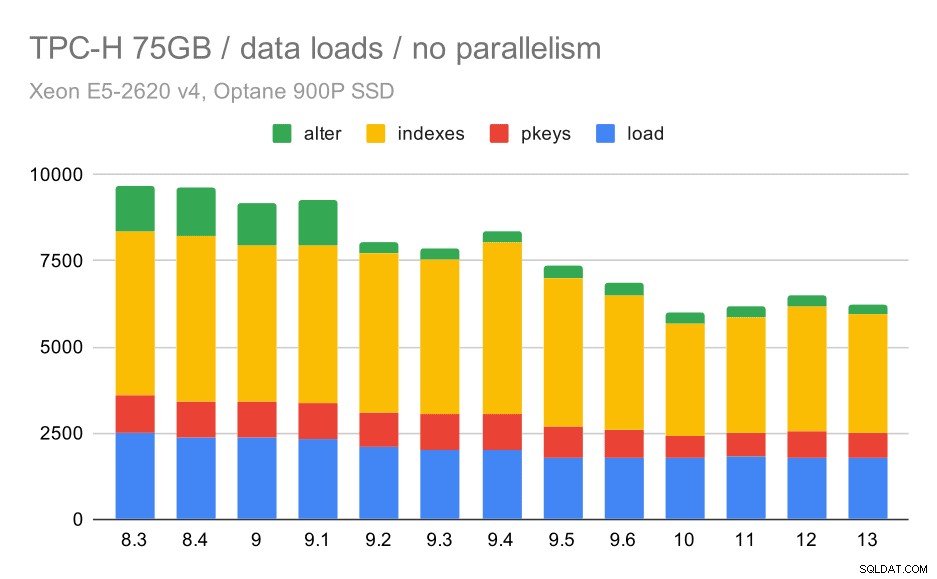
Продължителност на зареждане на данни TPC-H – мащаб 75GB, без паралелизъм
Можете ясно да видите, че има стабилна тенденция на подобрения, като се намаляват около 30% от продължителността само чрез подобряване на ефективността и в четирите стъпки – COPY, създаване на първични ключове и индекси и (особено) настройка на външни ключове. Подобрението „alter“ в 9.2 е особено ясно.
| COPY | PKEYS | ИНДЕКСИ | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Сега, нека видим как разрешаването на паралелизъм променя поведението. Следващата диаграма сравнява резултатите с активиран паралелизъм – маркирани с „(p)“ – с резултати с деактивиран паралелизъм.
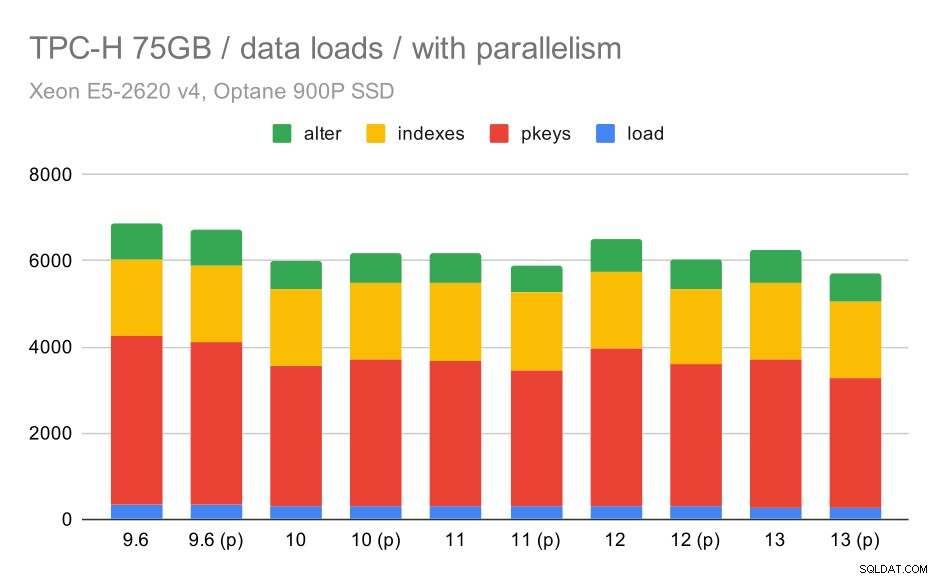
Продължителност на зареждане на данни TPC-H – мащаб 75 GB, паралелизъм е разрешен.
За съжаление, изглежда, че ефектът от паралелизма е много ограничен в този тест – помага малко, но разликите са сравнително малки. Така общото подобрение остава около 30%.
| COPY | PKEYS | ИНДЕКСИ | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Запитвания
Сега можем да разгледаме запитванията. TPC-H има 22 шаблона за заявки – генерирах един набор от действителни заявки и ги стартирах на всички версии два пъти – първо след изтриване на всички кешове и рестартиране на екземпляра, след това със загрят кеш. Всички числа, представени в диаграмите, са най-добрите от тези две серии (в повечето случаи това е второто, разбира се).
Без паралелизъм
Без паралелизъм резултатите за най-малкия набор от данни са доста ясни – всяка лента е разделена на множество части с различни цветове за всяка от 22-те заявки. Трудно е да се каже коя част съответства на коя точна заявка, но е достатъчна за идентифициране на случаите, когато една заявка се подобрява или се влошава много между две стартирания. Например в първата диаграма е много ясно, че Q21 е станал много по-бърз между 8.3 и 8.4.
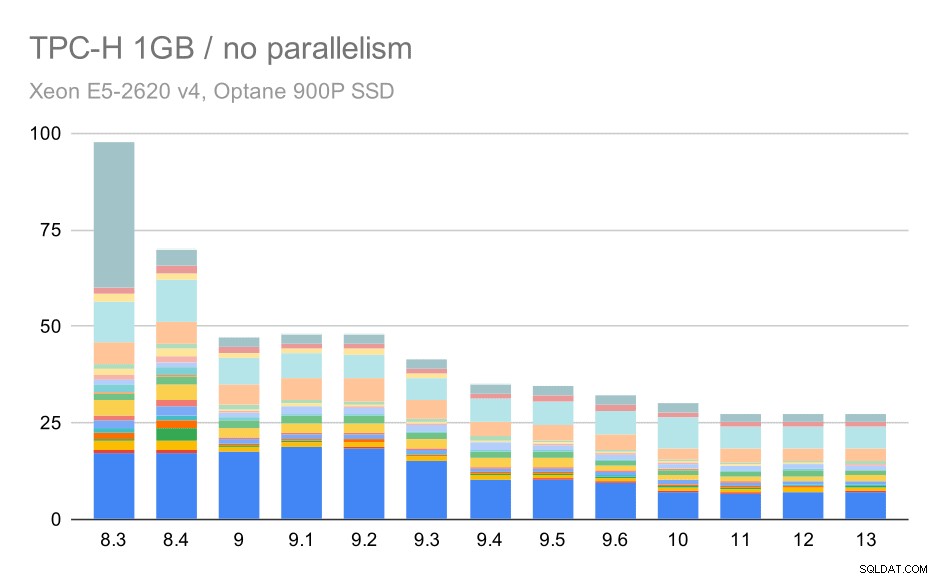
TPC-H заявки за малък набор от данни (1GB) – паралелизмът е деактивиран
За скалата от 10 GB резултатите са малко трудни за тълкуване, тъй като на 8.3 една от заявките (Q21) отнема толкова много време за изпълнение, че задминава всичко останало.
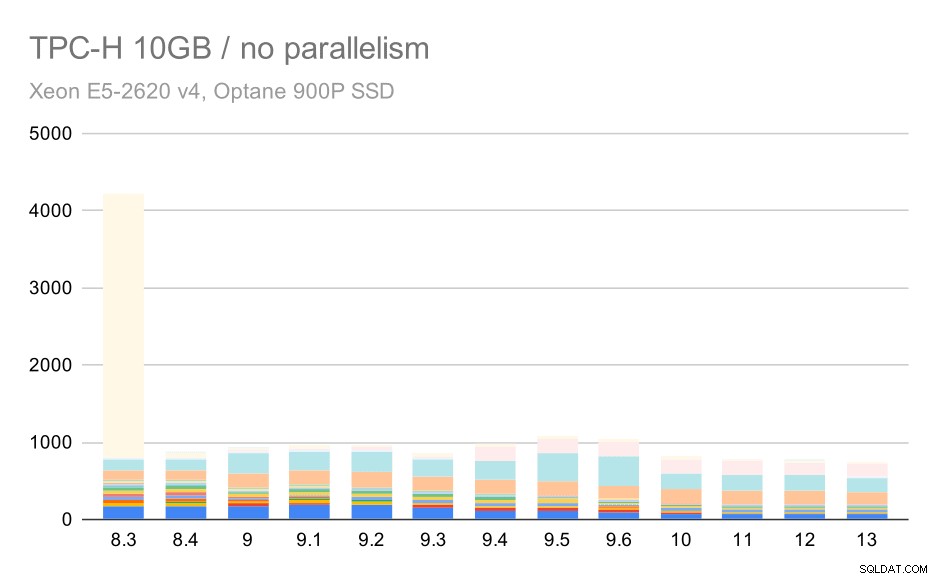
TPC-H заявки за среден набор от данни (10 GB) – паралелизмът е деактивиран
Така че нека видим как би изглеждала диаграмата без Q21:
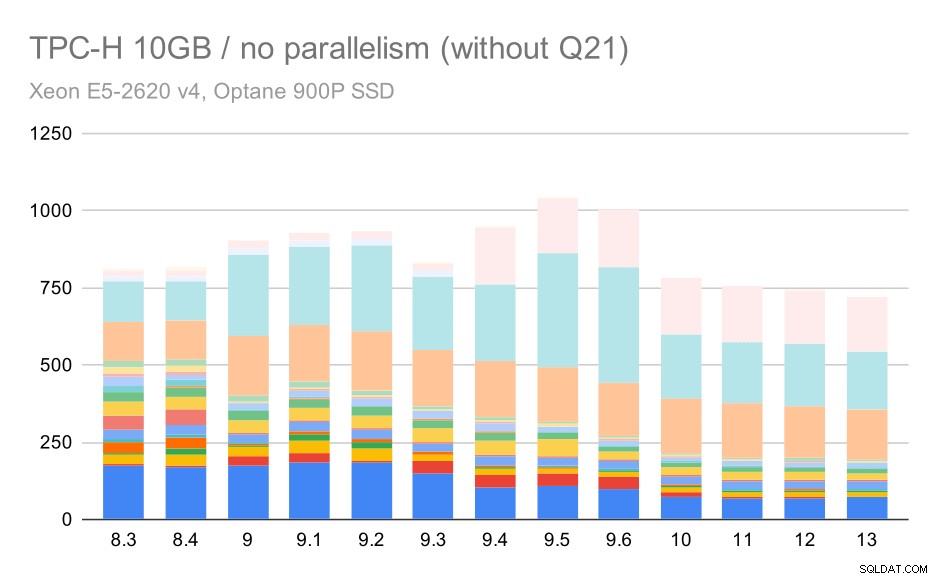
TPC-H заявки за среден набор от данни (10 GB) – паралелизмът е деактивиран, без проблемно Q2
Добре, това е по-лесно за четене. Ясно можем да видим, че повечето от заявките (до Q17) станаха по-бързи, но след това две от заявките (Q18 и Q20) станаха малко по-бавни. Ще видим подобен проблем в най-големия набор от данни, така че тогава ще обсъдя каква може да е основната причина.
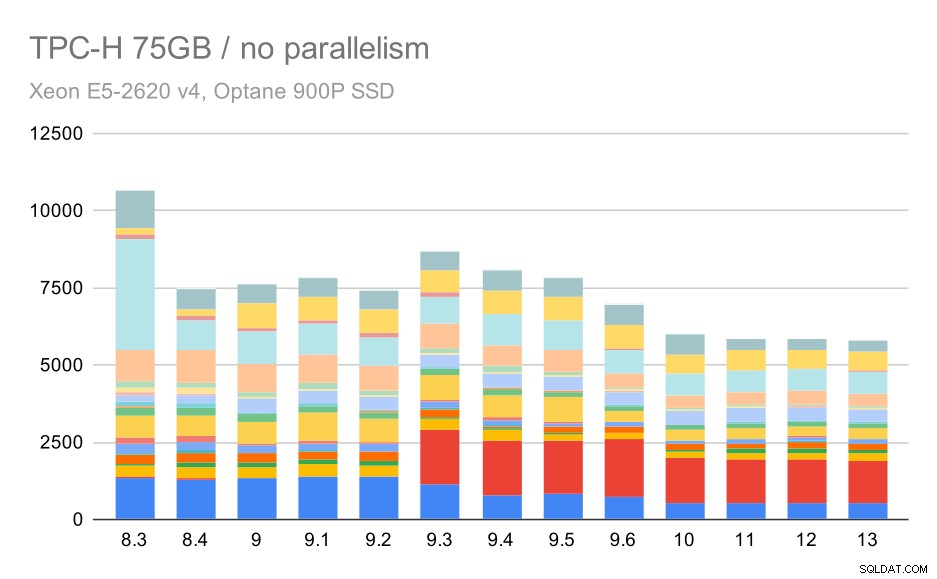
TPC-H заявки за голям набор от данни (75 GB) – паралелизмът е деактивиран
Отново виждаме внезапно увеличение за една от заявките в 9.3 – този път това е Q2, без което графиката изглежда така:
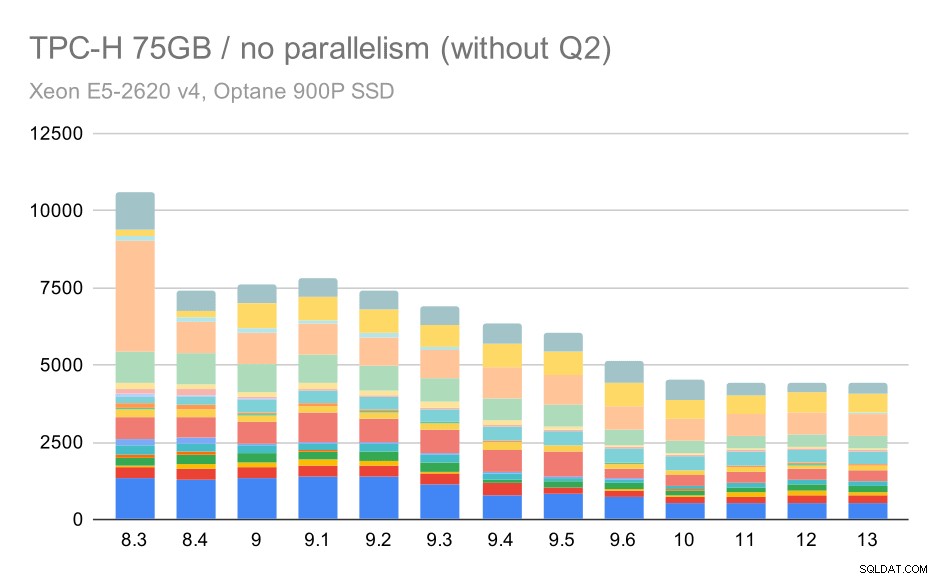
TPC-H заявки за голям набор от данни (75GB) – паралелизмът е деактивиран, без проблемно Q2
Това е доста приятно подобрение като цяло, ускорявайки цялото изпълнение от ~2,7 часа до само ~1,2h, просто като направи планировщика и оптимизатора по-интелигентен и като направи изпълнителя по-ефективен (не забравяйте, че паралелизмът беше деактивиран в тези изпълнения) .
И така, какъв може да е проблемът с Q2, правейки го по-бавен в 9.3? Простият отговор е, че всеки път, когато правите планировщика и оптимизатора по-интелигентен – било чрез конструиране на нови типове пътища/планове, или като го правите зависим от някои статистически данни, това също означава, че могат да бъдат направени нови грешки, когато статистическите данни или оценките са грешни. В Q2 клаузата WHERE препраща към обобщена подзаявка – опростената версия на заявката може да изглежда така:
Изберете 1 от части, където ps_supplycost =(изберете min (ps_supplycost) от partsupp, доставчик, нация, регион, където p_partkey =ps_partkey и s_suppkey =ps_suppkey и s_nationkey =n_nationkey и n_regionkey =r_regionkey и r_nameПроблемът е, че не знаем средната стойност по време на планиране, което прави невъзможно изчисляването на достатъчно добри оценки за условието WHERE. Действителното Q2 съдържа допълнителни връзки и планирането им основно зависи от добрите оценки на съединените връзки. В по-старите версии изглежда, че оптимизаторът е правил правилното нещо, но след това в 9.3 го направихме по-интелигентен по някакъв начин, но с лошата оценка той не успява да вземе правилното решение. С други думи, добрите планове в по-старите версии бяха просто късмет, благодарение на ограниченията на планировщика.
Обзалагам се, че регресиите на Q18 и Q20 на по-малкия набор от данни също са причинени от нещо подобно, въпреки че не съм ги изследвал подробно.
Вярвам, че някои от тези проблеми с оптимизатора може да бъдат отстранени чрез настройка на параметрите на разходите (например random_page_cost и т.н.), но не съм пробвал това поради ограничения във времето. Това обаче показва, че надстройките не подобряват автоматично всички заявки – понякога надстройката може да предизвика регресия, така че подходящото тестване на вашето приложение е добра идея.
Паралелизъм
Така че нека видим колко паралелизъм на заявките променя резултатите. Отново ще разгледаме само резултати от версии след 9.6, етикетиране на резултатите с „(p)“, където паралелната заявка е активирана.
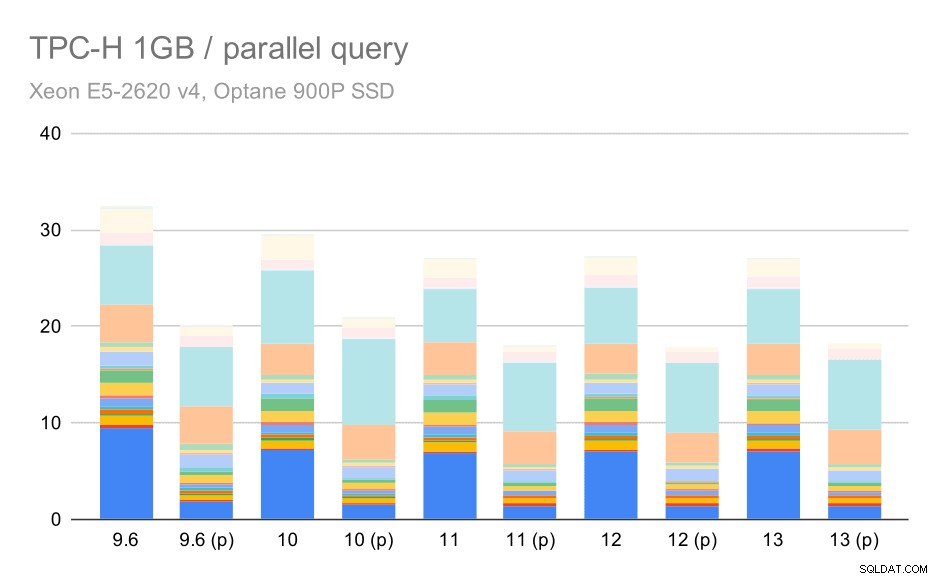
TPC-H заявки за малък набор от данни (1GB) – паралелизъм е активиран
Ясно е, че паралелизмът помага доста – той намалява около 30% дори при този малък набор от данни. При средния набор от данни няма голяма разлика между редовното и паралелното изпълнение:
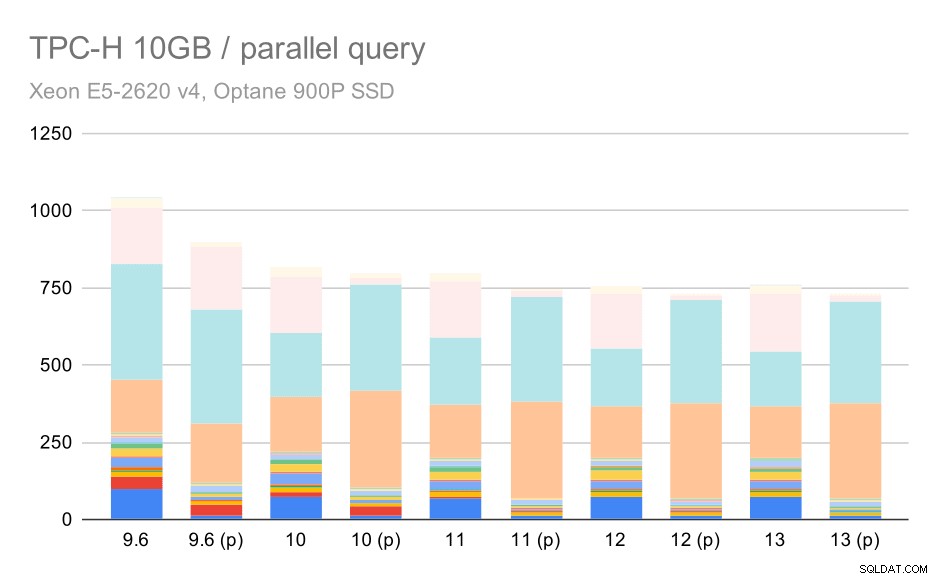
TPC-H заявки за среден набор от данни (10 GB) – паралелизъм е активиран
Това е още една демонстрация на вече обсъждания проблем – разрешаването на паралелизъм позволява да се обмислят допълнителни планове за заявки и очевидно прогнозите или разходите не съвпадат с реалността, което води до лош избор на план.
И накрая големият набор от данни, където пълните резултати изглеждат така:
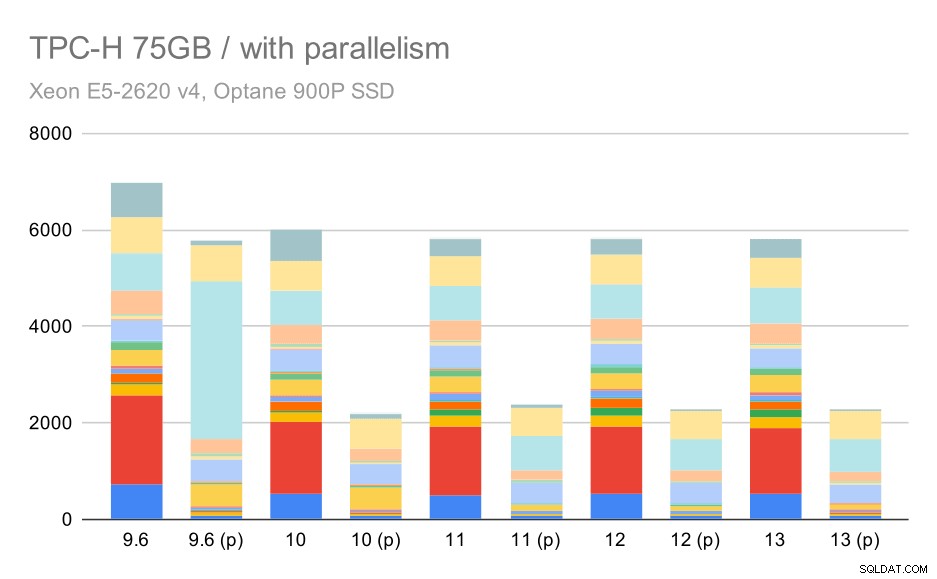
TPC-H заявки за голям набор от данни (75GB) – паралелизъм е активиран
Тук разрешаването на паралелизма работи в наша полза – оптимизаторът успява да изгради по-евтин паралелен план за Q2, отменяйки лошия избор на план, въведен в 9.3. Но само за пълнота, ето резултатите без Q2.
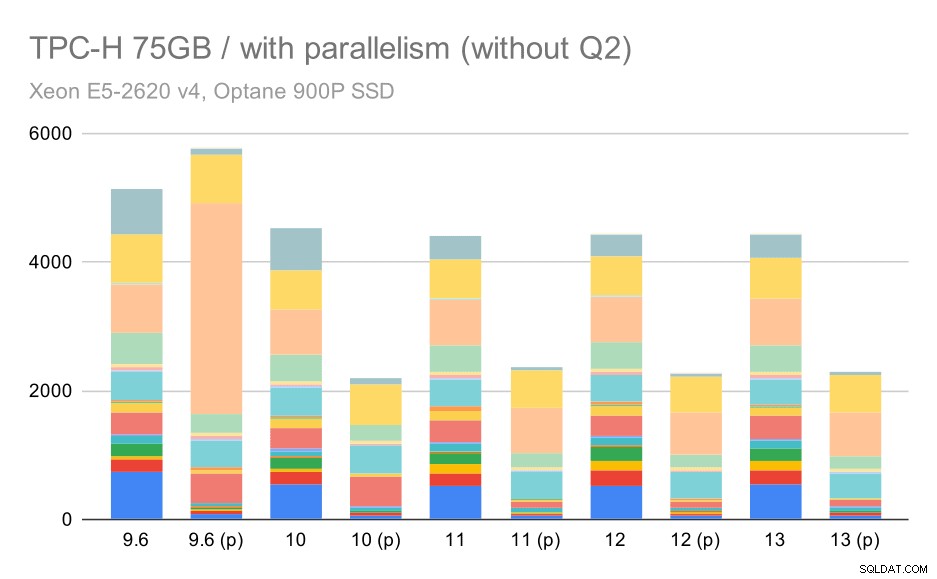
TPC-H заявки за голям набор от данни (75 GB) – паралелизъм е активиран, без проблемно Q2
Дори тук можете да забележите някои лоши избори на паралелен план – например паралелният план за Q9 е по-лош до 11, където става по-бърз – вероятно благодарение на 11 поддържащи допълнителни паралелни изпълнителни възли. От друга страна някои паралелни заявки (Q18, Q20) стават по-бавни на 11, така че не са само дъги и еднорози.
Обобщение и бъдеще
Мисля, че тези резултати добре демонстрират оптимизациите, прилагани след PostgreSQL 8.3. Тестовете с деактивиран паралелизъм илюстрират подобрения в ефективността (т.е. правене на повече със същото количество ресурси) – зареждането на данни стана с ~30% по-бързо и заявките станаха ~2 пъти по-бързи. Вярно е, че се сблъсках с някои проблеми с неефективни планове за заявки, но това е присъщ риск, когато правим планировщика на заявки по-интелигентен. Ние непрекъснато работим върху това да направим резултатите по-надеждни и съм сигурен, че бих могъл да смекча повечето от тези проблеми, като настроя малко конфигурацията.
Резултатите с активиран паралелизъм показват, че можем ефективно да използваме допълнителни ресурси (по-специално ядра на процесора). Изглежда, че натоварванията на данни нямат голяма полза от това – поне не в този сравнителен тест, но въздействието върху изпълнението на заявката е значително, което води до ~2x ускорение (въпреки че различните заявки се влияят по различен начин, разбира се).
Има много възможности за подобряване на това в бъдещи версии на PostgreSQL. Например има серия от пачове, внедряващи паралелизъм за COPY, ускорявайки зареждането на данни. Има различни кръпки, подобряващи изпълнението на аналитични заявки – от малки локализирани оптимизации до големи проекти като колонно съхранение и изпълнение, обобщено натискане надолу и т.н. Може да се спечели много и чрез използването на декларативно разделяне – функция, която най-често пренебрегвах, докато работех върху това бенчмарк, просто защото това би увеличило обхвата твърде много. И съм сигурен, че има много други възможности, които дори не мога да си представя, но по-умните хора в PostgreSQL общността вече работят върху тях.
Приложение:Конфигурация на PostgreSQL
Паралелизмът е деактивиран
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB
Паралелизмът е активиран
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# optimizerdefault_statistics_target =1000random_page_cost =60effective_cache_size =32GB