Преди няколко години (на pgconf.eu 2014 в Мадрид) представих беседа, наречена „Археология на производителността“, която показа как се промени производителността в последните версии на PostgreSQL. Направих този разговор, тъй като смятам, че дългосрочната гледна точка е интересна и може да ни даде прозрения, които може да са много ценни. За хора, които действително работят върху PostgreSQL код като мен, това е полезно ръководство за бъдеща разработка, а за потребителите на PostgreSQL може да помогне при оценката на надстройките.
Затова реших да повторя това упражнение и да напиша няколко публикации в блога, анализиращи производителността за редица версии на PostgreSQL. В разговора от 2014 г. започнах с PostgreSQL 7.4, който към този момент беше на около 10 години (пуснат през 2003 г.). Този път ще започна с PostgreSQL 8.3, който е на около 12 години.
Защо не започнете отново с PostgreSQL 7.4? Има около три основни причини, поради които реших да започна с PostgreSQL 8.3. Първо, общ мързел. Колкото по-стара е версията, толкова по-трудно може да се изгради с помощта на текущите версии на компилатора и т.н. Второ, отнема време за провеждане на правилни сравнителни показатели, особено с по-големи количества данни, така че добавянето на една основна версия може лесно да добави няколко дни машинно време. Просто не си струваше. И накрая, 8.3 въведе редица важни промени – подобрения на автоматично вакуумиране (разрешено по подразбиране, едновременни работни процеси,...), пълнотекстово търсене, интегрирано в ядрото, разпределени контролни точки и т.н. Така че мисля, че е напълно логично да започнем с PostgreSQL 8.3. Което беше пуснато преди около 12 години, така че това сравнение всъщност ще обхване по-дълъг период от време.
Реших да измеря три основни типа натоварване – OLTP, анализ и пълнотекстово търсене. Мисля, че OLTP и анализите са доста очевиден избор, тъй като повечето приложения са някаква смесица от тези два основни типа. Търсенето в пълен текст ми позволява да демонстрирам подобрения в специални типове индекси, които също се използват за индексиране на популярни типове данни като JSONB, типове, използвани от PostGIS и др.
Защо изобщо да правим това?
Наистина ли си струва усилията? В крайна сметка ние правим бенчмаркове по време на разработката през цялото време, за да покажем, че пластирът помага и/или че не причинява регресия, нали? Проблемът е, че това обикновено са само „частични“ бенчмаркове, сравняващи два конкретни комита и обикновено с доста ограничен избор от натоварвания, които смятаме, че може да са подходящи. Което е напълно логично – просто не можете да изпълнявате пълна батерия от работни натоварвания за всеки комит.
От време на време (обикновено малко след пускането на нова основна версия на PostgreSQL) хората провеждат тестове, сравнявайки новата версия с предходната, което е хубаво и ви насърчавам да изпълнявате такива бенчмаркове (било то някакъв стандартен бенчмарк, или нещо специфично за вашето приложение). Но е трудно да се комбинират тези резултати в по-дългосрочен изглед, тъй като тези тестове използват различни конфигурации и хардуер (обикновено по-нов за по-новата версия) и т.н. Така че е трудно да се правят ясни преценки за промените като цяло.
Същото важи и за производителността на приложението, което, разбира се, е „крайният еталон“. Но хората може да не надграждат до всяка основна версия (понякога може да пропуснат няколко версии, например от 9.5 до 12). И когато надграждат, това често се комбинира с надстройки на хардуер и т.н. Да не говорим, че приложенията се развиват с течение на времето (нови функции, допълнителна сложност), нарастват количествата данни и броят на едновременните потребители и т.н.
Това се опитва да покаже тази серия от блогове – дългосрочни тенденции в производителността на PostgreSQL за някои основни натоварвания, така че ние – разработчиците – да получим някакво топло и размито усещане за добрата работа през годините. И да покажа на потребителите, че въпреки че PostgreSQL е зрял продукт към този момент, все още има значителни подобрения във всяка нова основна версия.
Не е целта ми да използвам тези показатели за сравнение с други продукти за бази данни или да давам резултати, за да отговарям на каквато и да е официална класация (като TPC-H). Целта ми е просто да се образова като разработчик на PostgreSQL, може би да идентифицирам и изследвам някои проблеми и да споделям констатациите с други.
Честно сравнение?
Не мисля, че подобни сравнения на версии, пуснати в продължение на 12 години, не могат да бъдат напълно справедливи, тъй като всеки софтуер е разработен в определен контекст – хардуерът е добър пример за система от база данни. Ако погледнете машините, които сте използвали преди 12 години, колко ядра имаха, колко RAM? Какъв тип хранилище са използвали?
Типичен сървър от среден клас през 2008 г. имаше може би 8-12 ядра, 16 GB RAM и RAID с няколко SAS устройства. Типичен сървър от среден клас днес може да има няколко десетки ядра, стотици GB RAM и SSD съхранение.
Разработването на софтуер е организирано по приоритет – винаги има повече потенциални задачи, отколкото имате време, така че трябва да изберете задачи с най-доброто съотношение цена/полза за вашите потребители (особено тези, които финансират проекта, пряко или косвено). И през 2008 г. някои оптимизации вероятно все още не са били подходящи – повечето машини не са имали екстремни количества RAM, така че оптимизирането за големи споделени буфери все още не си струваше, например. И много от тесните места на процесора бяха засенчени от I/O, защото повечето машини имаха хранилище за „въртяща се ръжда“.
Забележка:Разбира се, имаше клиенти, използващи доста големи машини дори тогава. Някои използваха общностен Postgres с различни настройки, други решиха да работят с една от различните разклонения на Postgres с допълнителни възможности (например масивен паралелизъм, разпределени заявки, използване на FPGA и т.н.). И това повлия и на развитието на общността, разбира се.
Тъй като по-големите машини ставаха все по-разпространени през годините, все повече хора можеха да си позволят машини с големи количества RAM и голям брой ядра, променяйки съотношението цена/полза. Тесните места бяха проучени и отстранени, което позволи на по-новите версии да работят по-добре.
Това означава, че бенчмарк като този винаги е малко несправедлив – ще предпочита по-старата или по-нова версия, в зависимост от настройката (хардуер, конфигурация). Опитах се обаче да избера хардуерни и конфигурационни параметри, така че да не е много лошо за по-старите версии.
Това, което се опитвам да кажа, е, че това не означава, че по-старите версии на PostgreSQL са били глупости – така работи разработката на софтуер. Вие се справяте с тесните места, които е вероятно да срещнат вашите потребители, а не с тесните места, които биха могли да срещнат след 10 години.
Хардуер
Предпочитам да правя бенчмаркове на физически хардуер, до който имам директен достъп, защото това ми позволява да контролирам всички детайли, имам достъп до всички подробности и т.н. Така че използвах машината, която имам в нашия офис – нищо фантастично, но се надявам, че е достатъчно добра за тази цел.
- 2x E5-2620 v4 (16 ядра, 32 нишки)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (данни)
- 3 x 7,2k SATA RAID0 (временно пространство за таблици)
- ядро 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Използвах и втора – много по-малка – машина, само с 4 ядра и 8 GB RAM, която обикновено показва същите подобрения/регресии, само по-слабо изразени.
pgbench
Като инструмент за сравнителен анализ използвах добре познатия pgbench, използвайки най-новата версия (от PostgreSQL 13), за да тествам всички версии. Това елиминира възможните отклонения, дължащи се на оптимизации, направени в pgbench с течение на времето, което прави резултатите по-сравними.
Бенчмаркът тества редица различни случаи, вариращи по редица параметри, а именно:
мащаб
- малък – данните се вписват в споделени буфери, показват проблеми със заключване и т.н.
- средно – данните са по-големи от споделените буфери, но се вписват в RAM, обикновено свързани с процесора (или евентуално I/O за работни натоварвания четене-запис)
- голям – данни, по-големи от RAM, предимно I/O обвързани
режими
- само за четене – pgbench -S
- четене-запис – pgbench -N
брои клиенти
- 1, 4, 8, 16, 32, 64, 128, 256
- броят на pgbench нишки (-j) се настройва съответно
Резултати
Добре, нека разгледаме резултатите. Първо ще представя резултатите от NVMe хранилището, след което ще покажа някои интересни резултати, използвайки SATA RAID хранилището.
NVMe SSD / само за четене
За малкия набор от данни (който се вписва напълно в споделените буфери) резултатите само за четене изглеждат така:
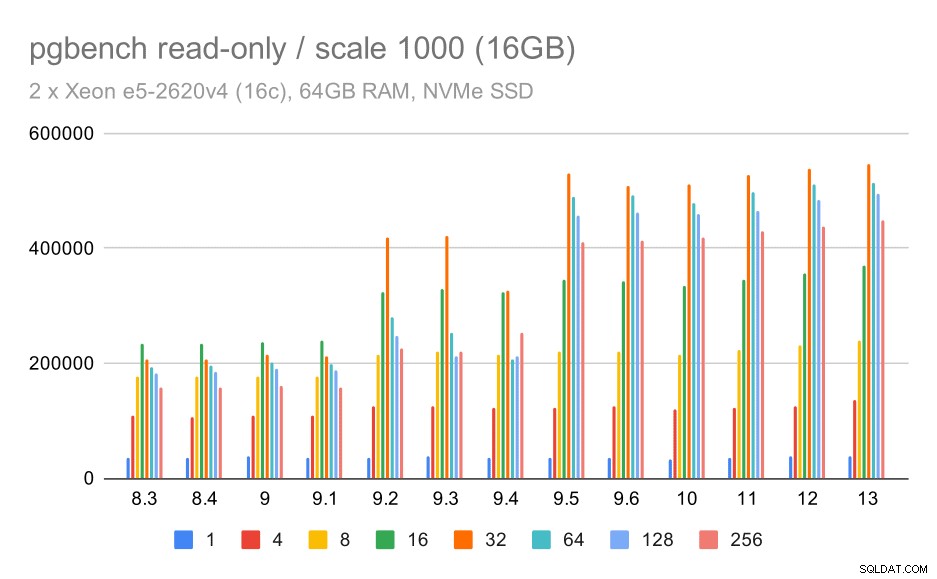
pgbench резултати / само за четене на малък набор от данни (мащаб 100, т.е. 1,6 GB)
Ясно е, че имаше значително увеличение на пропускателната способност в 9.2, който съдържаше редица подобрения в производителността, например бърз път за заключване. Пропускателната способност за един клиент всъщност пада малко – от 47k tps до само около 42k tps. Но за по-висок брой клиенти подобрението в 9.2 е доста ясно.
pgbench резултати / само за четене на среден набор от данни (скала 1000, т.е. 16 GB)
За средния набор от данни (който е по-голям от споделените буфери, но все пак се вписва в RAM) изглежда също има известно подобрение в 9.2, макар и не толкова ясно, както по-горе, последвано от много по-ясно подобрение в 9.5, най-вероятно благодарение на подобренията на мащабируемостта на заключване .
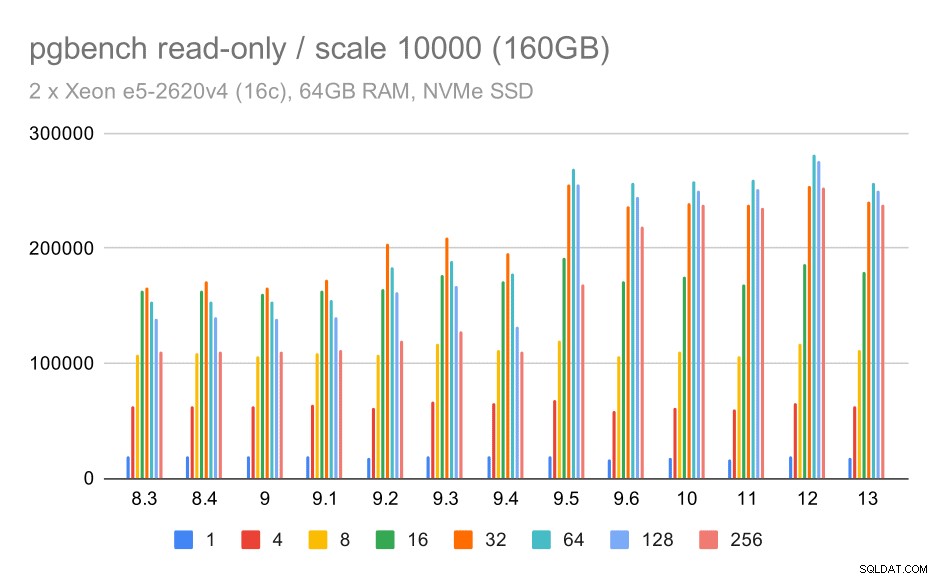
pgbench резултати / само за четене на голям набор от данни (мащаб 10000, т.е. 160 GB)
В най-големия набор от данни, който се отнася най-вече за способността за ефективно използване на хранилището, също има известно ускорение – най-вероятно благодарение на подобренията от 9.5.
NVMe SSD / четене-запис
Резултатите за четене и запис също показват някои подобрения, макар и не толкова изразени. На малкия набор от данни резултатите изглеждат така:
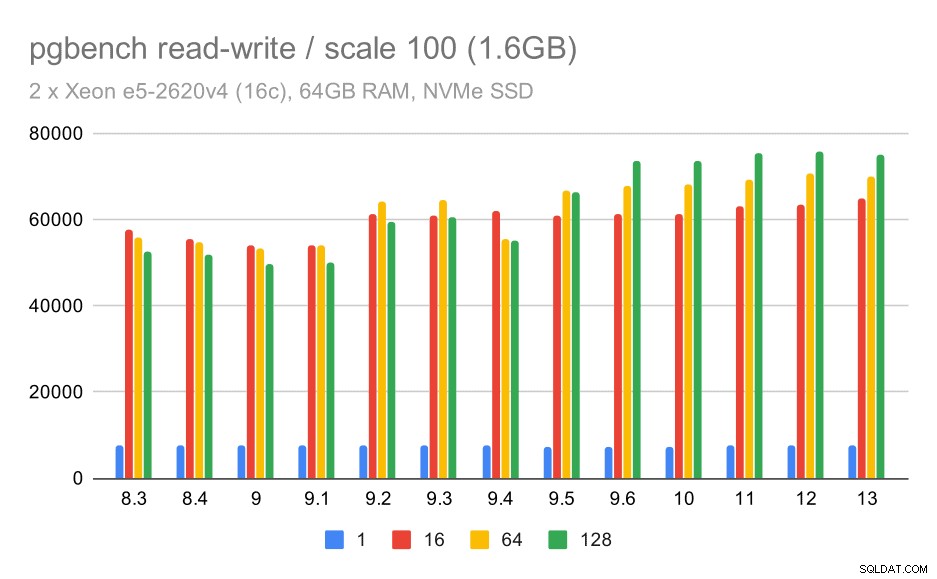
pgbench резултати / четене-запис на малък набор от данни (мащаб 100, т.е. 1,6 GB)
Така че скромно подобрение от около 52k на 75k tps при достатъчен брой клиенти.
За средния набор от данни подобрението е много по-ясно – от около 27k до 63k tps, т.е. пропускателната способност се удвоява повече от два пъти.
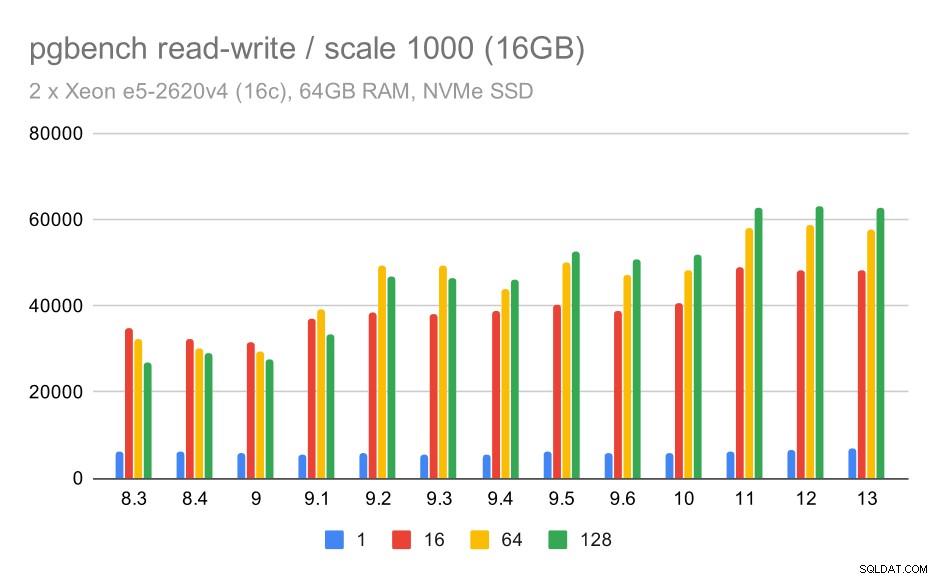
pgbench резултати / четене-запис на среден набор от данни (скала 1000, т.е. 16 GB)
За най-големия набор от данни виждаме подобно цялостно подобрение, но изглежда има известна регресия между 9,5 и 11.
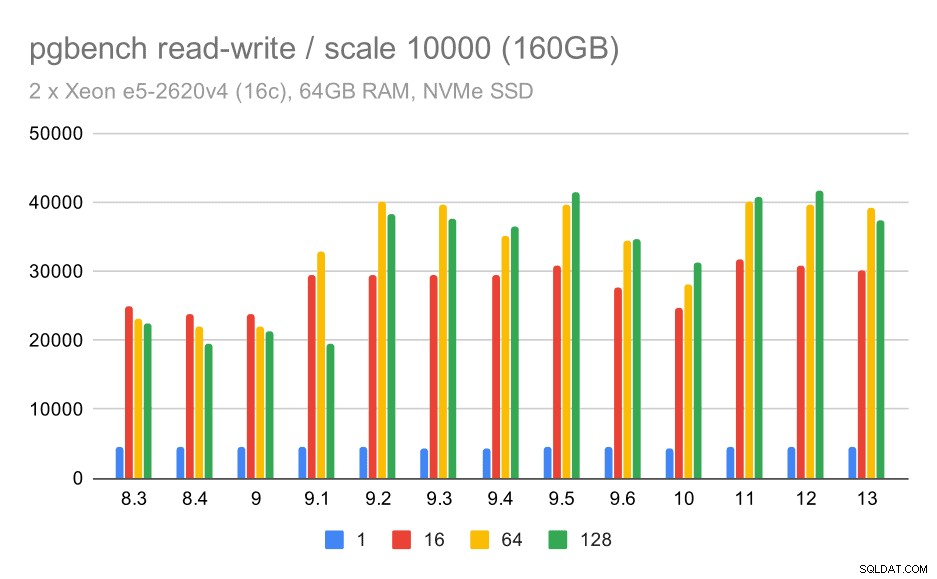
pgbench резултати/четене-запис на голям набор от данни (мащаб 10000, т.е. 160GB)
SATA RAID / само за четене
За съхранението на SATA RAID резултатите само за четене не са толкова приятни. Можем да пренебрегнем малките и средните набори от данни, за които системата за съхранение е без значение. За големия набор от данни пропускателната способност е малко шумна, но изглежда всъщност намалява с времето – особено след PostgreSQL 9.6. Не знам каква е причината за това (нищо в бележките към версията 9.6 не се откроява като ясен кандидат), но изглежда като някакъв вид регресия.
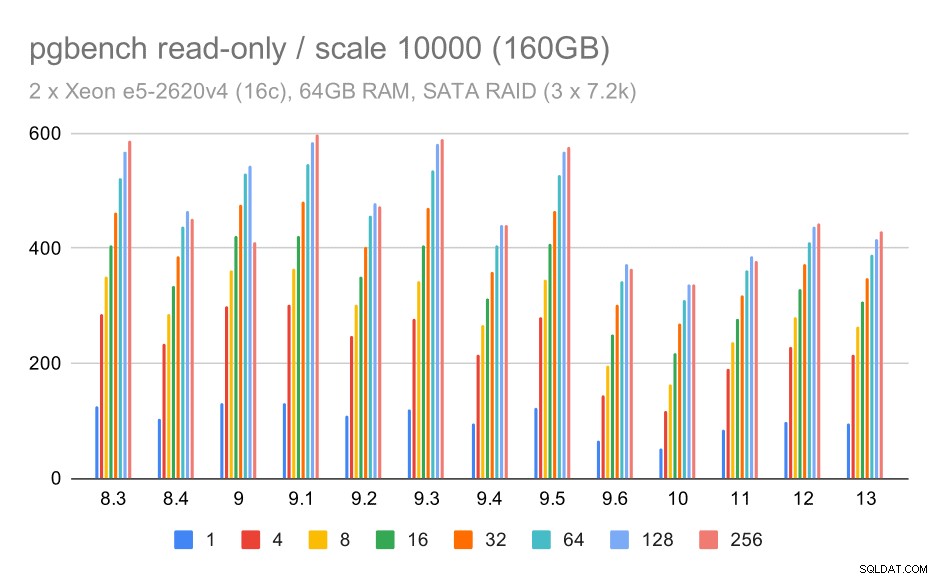
pgbench резултати на SATA RAID / само за четене на голям набор от данни (мащаб 10000, т.е. 160 GB)
SATA RAID/четене-запис
Поведението за четене и запис обаче изглежда много по-приятно. При малкия набор от данни пропускателната способност се увеличава от около 600 tps до повече от 6000 tps. Обзалагам се, че това е благодарение на подобренията на груповия ангажимент в 9.1 и 9.2.
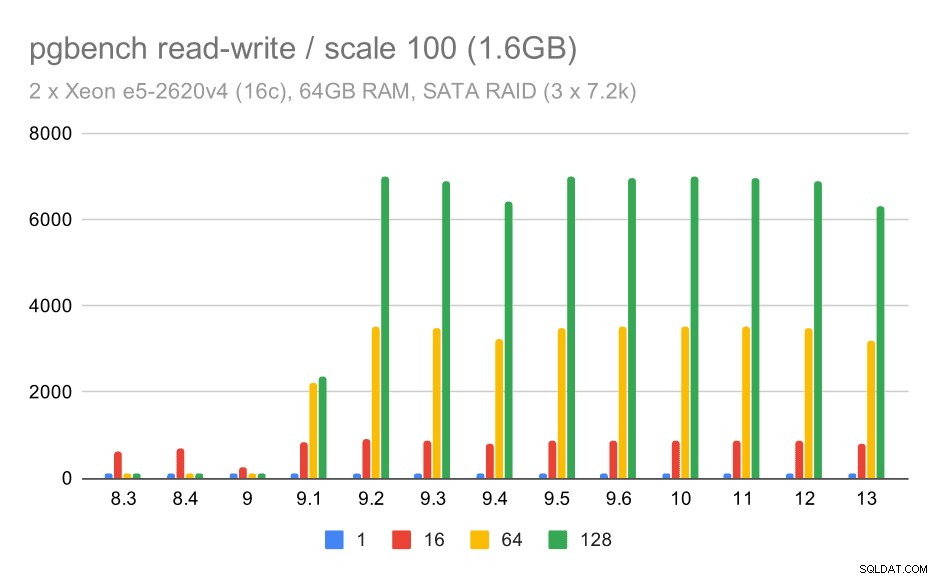
pgbench резултати при SATA RAID / четене-запис на малък набор от данни (мащаб 100, т.е. 1,6 GB)
За средните и големи мащаби можем да видим подобно – но по-малко – подобрение, тъй като хранилището също трябва да обработва I/O заявките, за да чете и записва блоковете данни. За средния мащаб трябва само да извършим записите (тъй като данните се побират в RAM), за големия мащаб също трябва да извършим четене – така че максималната пропускателна способност е още по-ниска.
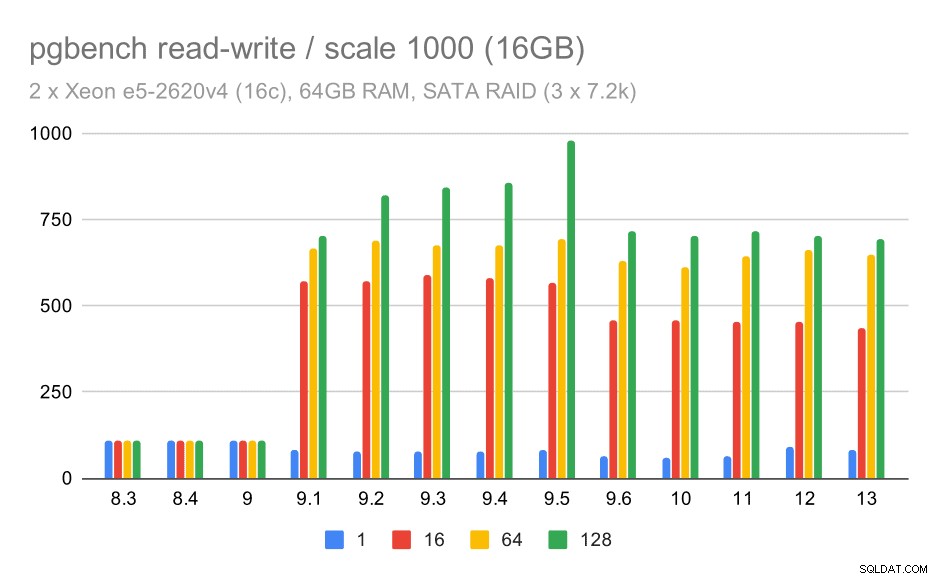
pgbench резултати на SATA RAID / четене-запис на среден набор от данни (скала 1000, т.е. 16 GB)
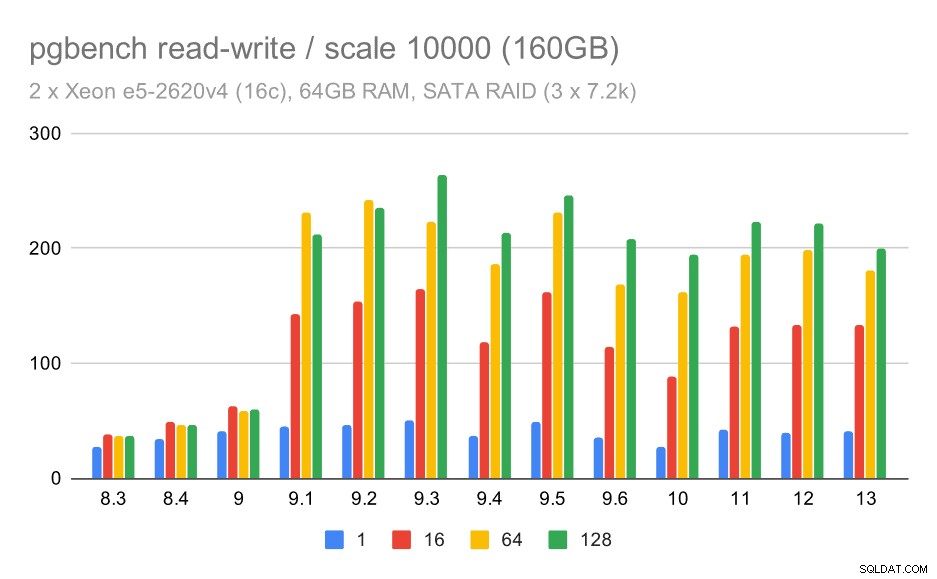
pgbench резултати на SATA RAID / четене-запис на голям набор от данни (мащаб 10000, т.е. 160 GB)
Обобщение и бъдеще
За да обобщим това, за настройката на NVMe заключенията изглеждат доста положителни. За работното натоварване само за четене има умерено ускорение в 9.2 и значително ускорение в 9.5, благодарение на оптимизациите за мащабируемост, докато за натоварването за четене и запис производителността се подобрява с около 2 пъти с течение на времето, в множество версии / стъпки.
С настройката на SATA RAID обаче заключенията са донякъде смесени. В случай на натоварване само за четене има много променливост/шум и възможна регресия в 9.6. За натоварването за четене и запис има огромно ускорение в 9.1, където пропускателната способност внезапно се увеличи от 100 tps на около 600 tps.
Какво ще кажете за подобренията в бъдещите версии на PostgreSQL? Нямам много ясна представа какво ще бъде следващото голямо подобрение – сигурен съм обаче, че други хакери на PostgreSQL ще излязат с брилянтни идеи, които правят нещата по-ефективни или позволяват да се използват наличните хардуерни ресурси. Корекцията за подобряване на мащабируемостта с много връзки или корекцията за добавяне на поддръжка за енергонезависими WAL буфери са примери за такива подобрения. Може да видим някои радикални подобрения на съхранението на PostgreSQL (по-ефективен формат на диска, използване на директен вход/изход и др.), индексиране и т.н.