Добре дошли в третата – и последна – част от тази серия от блогове, изследваща как производителността на PostgreSQL еволюира през годините. Първата част разглежда натоварванията на OLTP, представени от pgbench тестове. Втората част разглежда аналитични/BI заявки, използвайки подмножество от традиционния бенчмарк TPC-H (по същество част от теста за мощност).
И тази последна част разглежда пълнотекстово търсене, т.е. способността за индексиране и търсене в големи количества текстови данни. Същата инфраструктура (особено индексите) може да бъде полезна за индексиране на полуструктурирани данни като JSONB документи и т.н., но не това е, върху което е фокусиран този показател.
Но първо, нека да разгледаме историята на пълнотекстово търсене в PostgreSQL, което може да изглежда като странна функция за добавяне към RDBMS, традиционно предназначена за съхраняване на структурирани данни в редове и колони.
История на пълнотекстово търсене
Когато Postgres беше с отворен код през 1996 г., той нямаше нищо, което бихме могли да наречем пълнотекстово търсене. Но хората, които започнаха да използват Postgres, искаха да правят интелигентни търсения в текстови документи, а заявките LIKE не бяха достатъчно добри. Те искаха да могат да лемматизират термините с помощта на речници, да игнорират стоп думите, да сортират съответстващите документи по релевантност, да използват индекси за изпълнение на тези заявки и много други неща. Неща, които разумно не можете да правите с традиционните SQL оператори.
За щастие някои от тези хора също бяха разработчици, така че започнаха да работят върху това – и можеха, благодарение на това, че PostgreSQL беше достъпен като отворен код по целия свят. През годините има много сътрудници в търсенето на пълен текст, но първоначално това усилие се ръководи от Олег Бартунов и Теодор Сигаев, показани на следващата снимка. И двамата все още са основни сътрудници на PostgreSQL, работещи върху пълнотекстово търсене, индексиране, поддръжка на JSON и много други функции.

Теодор Сигаев и Олег Бартунов
Първоначално функционалността беше разработена като външен модул „contrib“ (в днешно време бихме казали, че е разширение), наречен „tsearch“, пуснат през 2002 г. По-късно това беше остаряло от tsearch2, значително подобрявайки функцията по много начини и в PostgreSQL 8.3 (издадена през 2008 г.) това беше напълно интегрирано в ядрото на PostgreSQL (т.е. без да е необходимо изобщо да се инсталира разширение, въпреки че разширенията все още бяха предоставени за обратна съвместимост).
Оттогава имаше много подобрения (и работата продължава, например за поддръжка на типове данни като JSONB, запитване с помощта на jsonpath и т.н.). но тези плъгини въведоха по-голямата част от функционалността на пълен текст, която имаме в PostgreSQL сега – речници, възможности за индексиране на пълен текст и заявки и т.н.
Еталон
За разлика от OLTP / TPC-H бенчмарковете, не ми е известен бенчмарк за пълен текст, който би могъл да се счита за „индустриален стандарт“ или предназначен за множество системи за бази данни. Повечето от бенчмарковете, за които познавам, са предназначени да се използват с една база данни/продукт и е трудно да ги пренасям смислено, така че трябваше да поема различен път и да напиша свой собствен бенчмарк за пълен текст.
Преди години написах archie – няколко скрипта на python, които позволяват изтегляне на архиви на PostgreSQL пощенски списъци и зареждат анализираните съобщения в PostgreSQL база данни, която след това може да бъде индексирана и търсена. Текущата моментна снимка на всички архиви има ~1M реда и след зареждането й в база данни таблицата е около 9,5GB (без да се броят индексите).
Що се отнася до заявките, вероятно бих могъл да генерирам някои произволни, но не съм сигурен колко реалистично би било това. За щастие, преди няколко години получих извадка от 33 000 действителни търсения от уебсайта на PostgreSQL (т.е. неща, които хората действително търсеха в архивите на общността). Малко вероятно е да получа нещо по-реалистично/представително.
Комбинацията от тези две части (набор от данни + заявки) изглежда като добър еталон. Можем просто да заредим данните и да стартираме търсенията с различни типове пълнотекстови заявки с различни типове индекси.
Запитвания
Има различни форми на пълнотекстови заявки – заявката може просто да избере всички съвпадащи редове, може да класира резултатите (сортира ги по уместност), да върне само малък брой или най-подходящите резултати и т.н. Изпълних бенчмарк с различни типове заявки, но в тази публикация ще представя резултати за две прости заявки, които според мен представят цялостното поведение доста добре.
- ИЗБЕРЕТЕ идентификатор, тема ОТ съобщения WHERE body_tsvector @@ $1
- ИЗБЕРЕТЕ идентификатор, тема ОТ съобщения WHERE body_tsvector @@ $1
ПОРЪЧАЙТЕ ПО ts_rank(body_tsvector, $1) DESC LIMIT 100
Първата заявка просто връща всички съвпадащи редове, докато втората връща 100-те най-подходящи резултата (това е нещо, което вероятно ще използвате за потребителски търсения).
Експериментирах с различни други типове заявки, но в крайна сметка всички те се държаха по начин, подобен на един от тези два типа заявки.
Индекси
Всяко съобщение има две основни части, в които можем да търсим – тема и тяло. Всеки от тях има отделна колона tsvector и се индексира отделно. Темите на съобщенията са много по-къси от телата, така че индексите естествено са по-малки.
PostgreSQL има два типа индекси, полезни за пълнотекстово търсене – GIN и GiST. Основните разлики са обяснени в документите, но накратко:
- GIN индексите са по-бързи за търсене
- GiST индексите са със загуба, т.е. изискват повторна проверка по време на търсене (и затова са по-бавни)
Твърдихме, че GiST индексите са по-евтини за актуализиране (особено при много едновременни сесии), но това беше премахнато от документацията преди време поради подобрения в кода за индексиране.
Този бенчмарк не тества поведението с актуализации – той просто зарежда таблицата без пълнотекстови индекси, изгражда ги наведнъж и след това изпълнява 33k заявки за данните. Това означава, че не мога да направя никакви изявления за това как тези типове индекси обработват едновременни актуализации въз основа на този сравнителен анализ, но вярвам, че промените в документацията отразяват различни скорошни подобрения на GIN.
Това също трябва да съвпада доста добре със случая на използване на архива на пощенския списък, където бихме добавяли нови имейли само от време на време (няколко актуализации, почти никакво едновременно записване). Но ако приложението ви прави много едновременни актуализации, ще трябва да го сравните сами.
Хардуерът
Направих бенчмарка на същите две машини както преди, но резултатите/заключенията са почти идентични, така че ще представя само числата от по-малката, т.е.
- CPU i5-2500K (4 ядра/нишки)
- 8 GB RAM
- 6 x 100GB SSD RAID0
- ядро 5.6.15, файлова система ext4
По-рано споменах, че наборът от данни има почти 10 GB при зареждане, така че е по-голям от RAM. Но индексите все още са по-малки от RAM, което е от значение за бенчмарка.
Резултати
Добре, време е за няколко числа и графики. Ще представя резултати както за зареждане на данни, така и за заявки, първо с GIN и след това с индекси GiST.
GIN/зареждане на данни
Натоварването не е особено интересно според мен. Първо, по-голямата част от него (синята част) няма нищо общо с пълния текст, защото се случва преди да бъдат създадени двата индекса. По-голямата част от това време се прекарва в анализиране на съобщенията, повторно изграждане на пощенските нишки, поддържане на списъка с отговори и т.н. Част от този код е внедрен в тригери PL/pgSQL, част от него се реализира извън базата данни. Едната част, която потенциално има отношение към пълния текст, е изграждането на векторите, но е невъзможно да се изолира времето, прекарано в това.
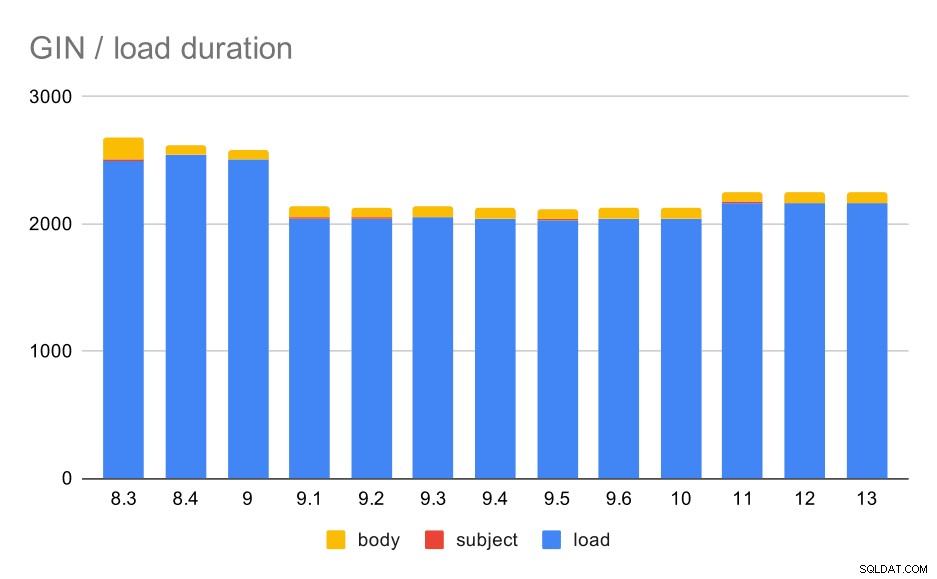
Операции за зареждане на данни с таблица и GIN индекси.
Следващата таблица показва изходните данни за тази диаграма – стойностите са продължителност в секунди. LOAD включва разбор на архивите на mbox (от скрипт на Python), вмъкване в таблица и различни допълнителни задачи (преизграждане на нишки за електронна поща и т.н.). SUBJECT/BODY INDEX се отнася до създаването на пълен текст GIN индекс в колоните тема/тяло след зареждане на данните.
| ЗАРЕЖДАНЕ | SUBJECT INDEX | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Ясно е, че производителността е доста стабилна – има доста значително подобрение (приблизително 20%) между 9.0 и 9.1. Не съм съвсем сигурен коя промяна може да е отговорна за това подобрение - нищо в бележките към версията 9.1 не изглежда ясно уместно. Има и ясно подобрение в изграждането на GIN индексите в 8.4, което съкращава времето приблизително наполовина. Което е хубаво, разбира се. Интересното е, че и за това не виждам никакви очевидно свързани бележки към изданието.
Какво ще кажете за размерите на GIN индексите обаче? Има много повече променливост, поне до 9.4, в който момент размерът на индексите пада от ~1GB до само около 670MB (приблизително 30%).
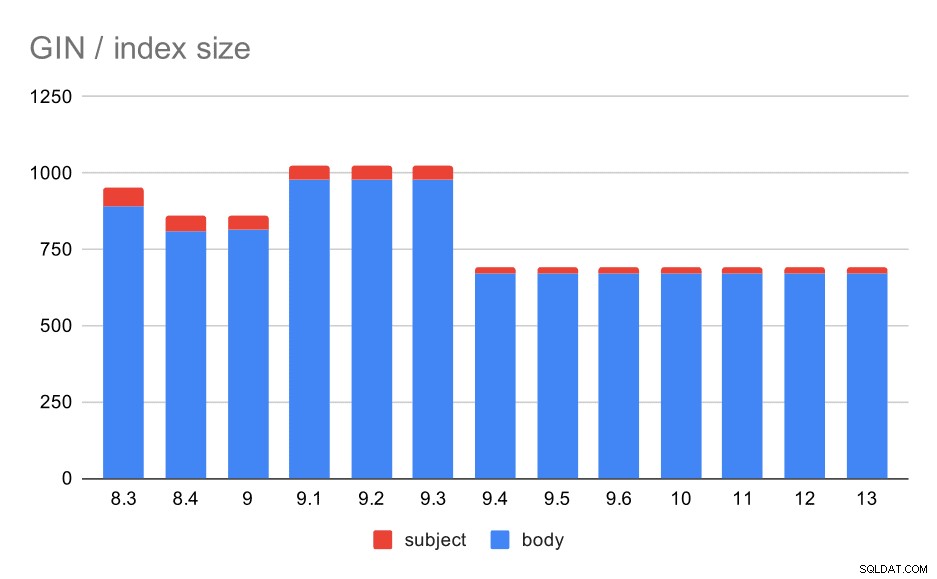
Размер на GIN индексите на тема/тело на съобщението. Стойностите са мегабайти.
Следващата таблица показва размерите на GIN индексите по тялото и темата на съобщението. Стойностите са в мегабайти.
| BODY | SUBJECT | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
В този случай мисля, че можем спокойно да предположим, че това ускоряване е свързано с този елемент в бележките за версия 9.4:
- Намалете размера на GIN индекса (Александър Коротков, Хейки Линакангас)
Променливостта на размера между 8.3 и 9.1 изглежда се дължи на промените в лемматизацията (как думите се трансформират в „основната“ форма). Освен разликите в размера, например заявките за тези версии връщат малко по-различен брой резултати.
GIN / заявки
Сега основната част от този бенчмарк е производителността на заявките. Всички представени тук числа са за един клиент – вече обсъдихме мащабируемостта на клиента в частта, свързана с производителността на OLTP, констатациите се отнасят и за тези заявки. (Освен това, тази конкретна машина има само 4 ядра, така че така или иначе няма да стигнем много далеч по отношение на тестване за мащабируемост.)
ИЗБЕРЕТЕ идентификатор, тема ОТ съобщения WHERE tsvector @@ $1
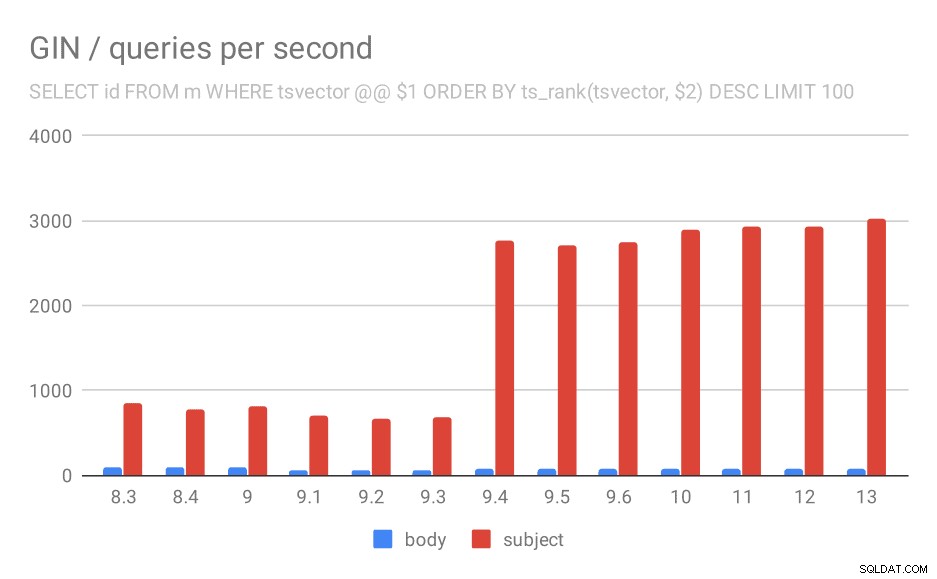
Първо, заявката за търсене на всички съвпадащи документи. За търсения в колоната „тема“ можем да правим около 800 заявки в секунда (и всъщност пада малко в 9.1), но в 9.4 изведнъж изстрелва до 3000 заявки в секунда. За колоната „тяло“ това е основно същата история – първоначално 160 заявки, спад до ~90 заявки в 9.1 и след това увеличение до 300 в 9.4.
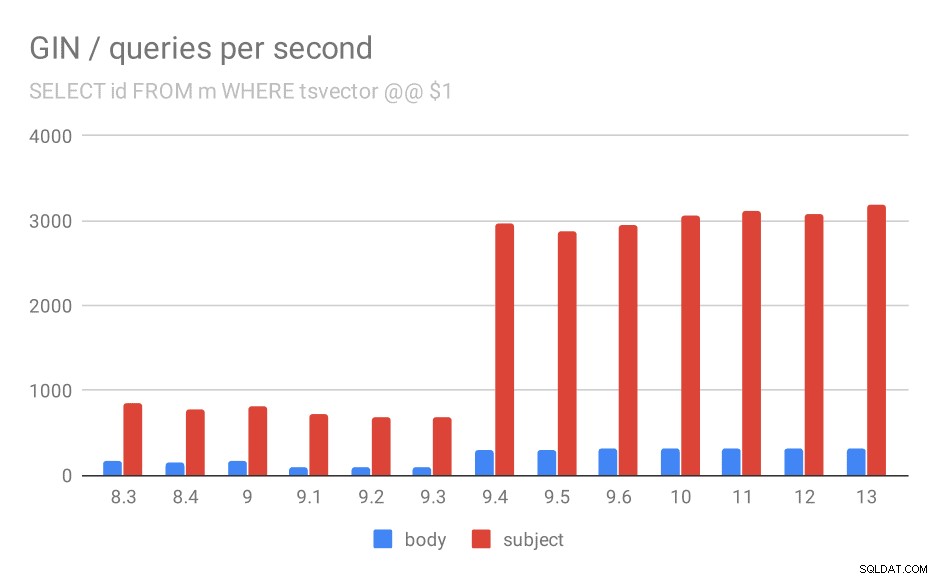
Брой заявки в секунда за първата заявка (извличане на всички съвпадащи редове).
И отново изходните данни – числата са пропускателна способност (заявки в секунда).
| BODY | SUBJECT | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Мисля, че можем спокойно да предположим, че подобрението в 9.4 е свързано с този елемент в бележките към версията:
- Подобрете скоростта на GIN търсене с няколко клавиша (Александър Коротков, Хейки Линакангас)
И така, още едно подобрение на GIN 9.4 от същите двама разработчици – очевидно Александър и Хейки свършиха много добра работа по GIN индексите в версията 9.4 😉
ИЗБЕРЕТЕ идентификатор, тема ОТ съобщения WHERE tsvector @@ $1
ПОРЪЧАЙТЕ ПО ts_rank(tsvector, $2) DESC LIMIT 100
За заявката, класираща резултатите по уместност, използвайки ts_rank и LIMIT, цялостното поведение е почти същото, не е необходимо да се описва подробно диаграмата, мисля.
Брой заявки в секунда за втората заявка (извличане на най-подходящите редове).
| BODY | SUBJECT | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Има обаче един въпрос – защо производителността падна между 9.0 и 9.1? Изглежда има доста значителен спад в пропускателната способност – с около 50% за телесните търсения и 20% за търсенията в теми на съобщения. Нямам ясно обяснение какво се е случило, но имам две наблюдения...
Първо, размерът на индекса се промени – ако погледнете първата диаграма „GIN / размер на индекса“ и таблицата, ще видите, че индексът на телата на съобщенията е нараснал от 813MB на около 977MB. Това е значително увеличение и може да обясни част от забавянето. Проблемът обаче е, че индексът по теми изобщо не нарасна, но и заявките също се забавиха.
Второ, можем да разгледаме колко резултата са върнали заявките. Индексираният набор от данни е абсолютно същият, така че изглежда разумно да се очаква еднакъв брой резултати във всички версии на PostgreSQL, нали? Е, на практика изглежда така:
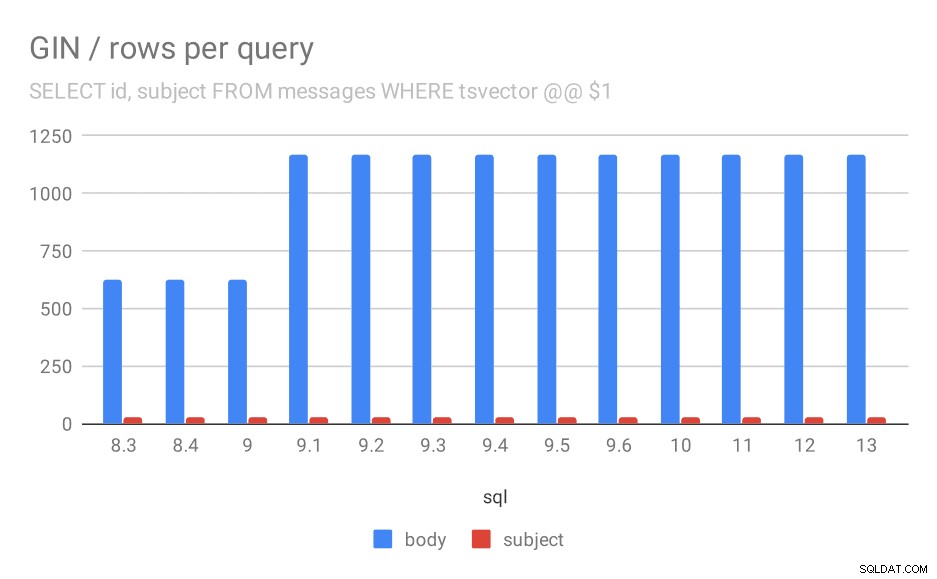
Среден брой върнати редове за заявка.
| BODY | SUBJECT | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Ясно е, че в 9.1 средният брой резултати за търсене в телата на съобщения внезапно се удвоява, което е почти напълно пропорционално на забавянето. Въпреки това броят на резултатите за търсене по тема остава същият. Нямам много добро обяснение за това, освен че индексирането се промени по начин, който позволява съвпадение на повече съобщения, но го прави малко по-бавно. Ако имате по-добри обяснения, бих искал да ги чуя!
GiST/зареждане на данни
Сега, другият тип пълнотекстови индекси – GiST. Тези индекси са със загуба, тоест изискват повторна проверка на резултатите, като се използват стойности от таблицата. Така че можем да очакваме по-ниска производителност в сравнение с индексите GIN, но в противен случай е разумно да очакваме приблизително същия модел.
Времената за зареждане наистина съвпадат с GIN почти перфектно – времената за създаване на индекса са различни, но общият модел е същият. Ускоряване в 9.1, малко забавяне в 11.
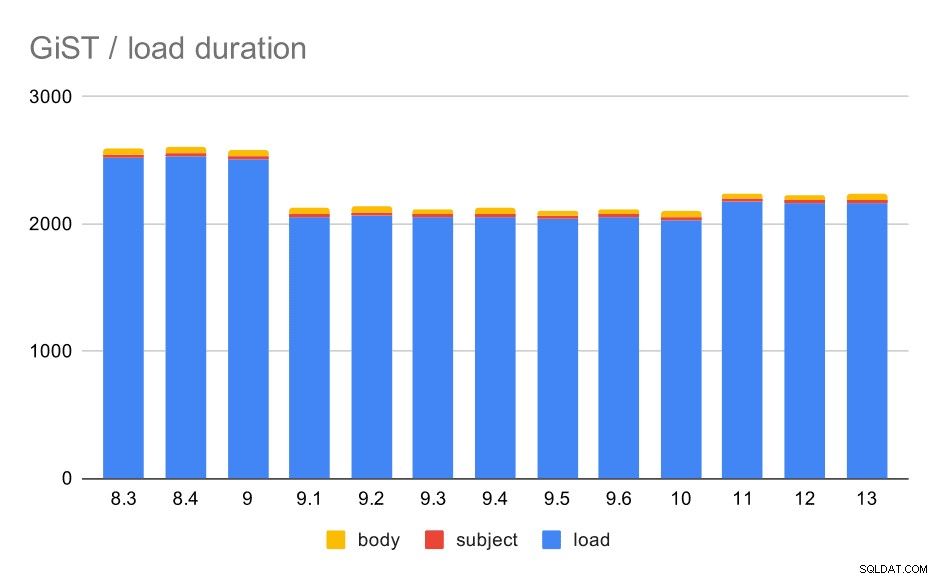
Операции за зареждане на данни с таблица и GiST индекси.
| ЗАРЕЖДАНЕ | SUBJECT | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Размерът на индекса обаче остана почти постоянен – нямаше подобрения в GiST, подобни на GIN в 9.4, което намали размера с ~30%. Има увеличение в 9.1, което е друг знак, че индексирането на пълен текст се е променило в тази версия, за да индексира повече думи.
Това е допълнително подкрепено от средния брой резултати, като GiST е точно същият като за GIN (с увеличение от 9.1).
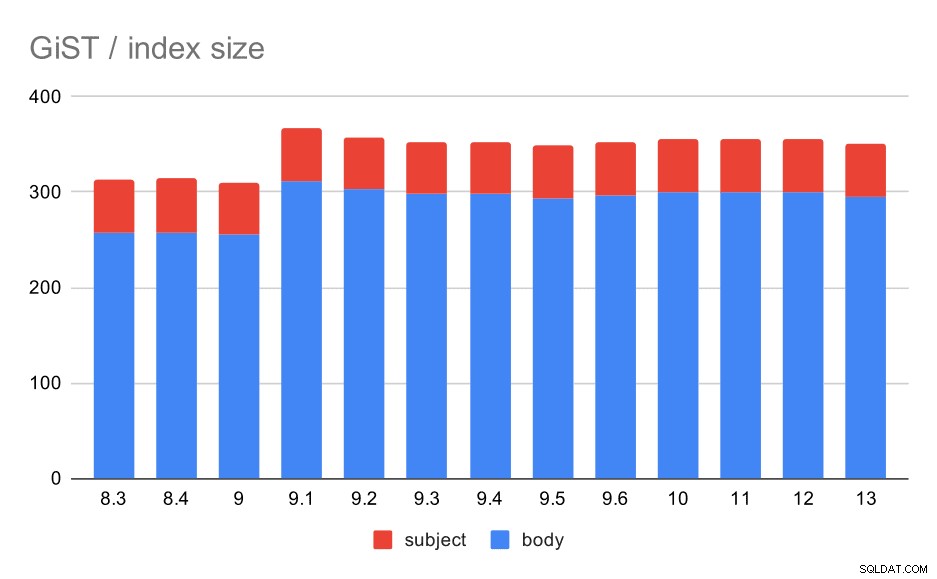
Размер на индексите на GiST по тема/тяло на съобщението. Стойностите са мегабайти.
| BODY | SUBJECT | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
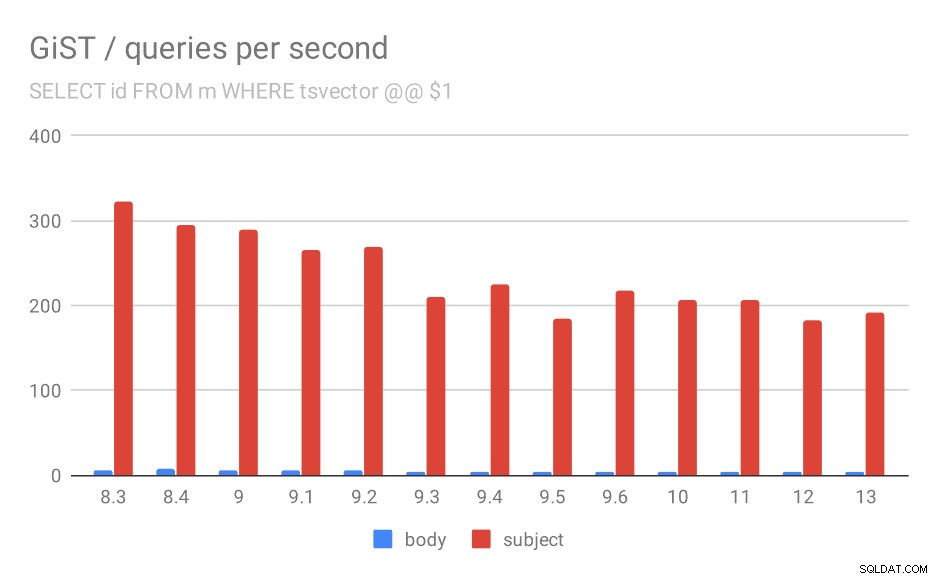
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
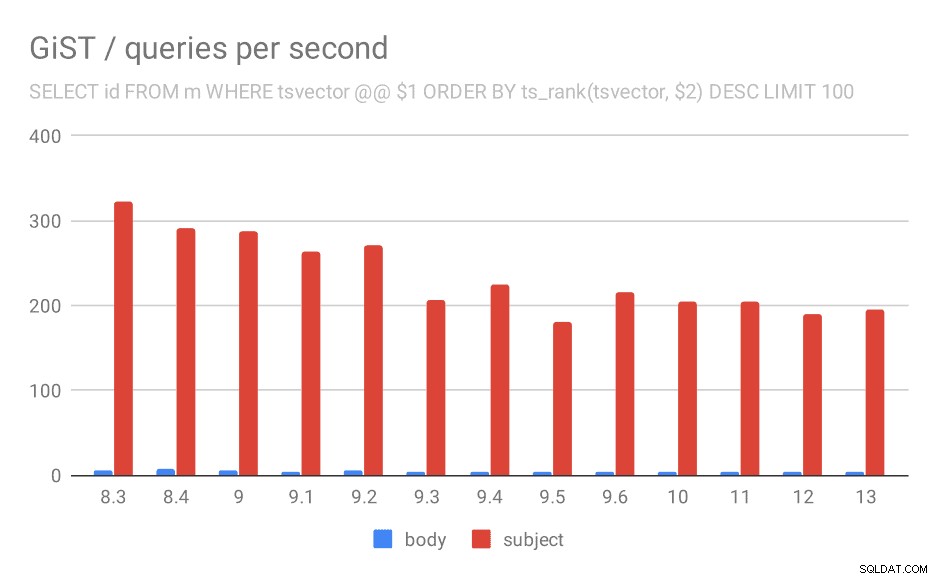
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).