Темата за кеширането се появи в PostgreSQL още преди 22 години и по това време фокусът беше върху надеждността на базата данни.
Бързо напред до 2020 г., дисковите плочи са скрити още по-дълбоко във виртуализирани среди, хипервизори и свързани устройства за съхранение. Освен това, взаимосвързаните, разпределени приложения, работещи в глобален мащаб, крещят за връзки с ниска латентност и внезапно настройват кешовете на сървъра, а SQL заявките се конкурират с гарантирането, че резултатите се връщат на клиентите в рамките на милисекунди. Раждат се кешове на ниво приложение и в паметта, а заявките за четене вече се записват близо до сървърите на приложения. В резултат на това I/O операциите са намалени само до запис, а латентността на мрежата е драстично подобрена. С един улов. Реализациите са отговорни за управлението на собствения кеш, което понякога води до влошаване на производителността.
Кеширането на запис е много по-сложен въпрос, както е обяснено в уикито на PostgreSQL.
Този блог е преглед на кеша на заявки в паметта и балансировчиците на натоварване, които се използват с PostgreSQL.
Балансиране на натоварването на PostgreSQL
Идеята за балансиране на натоварването е възникнала едновременно с кеширането през 1999 г., когато Брус Момджиам пише:
[...] възможно е да бъдем _много_ популярни в близко бъдеще.
Основата за внедряване на балансиране на натоварването в PostgreSQL се осигурява от вградената функция Hot Standby. Единственото изискване е приложението да се справи с преодоляването на отказ и тук идват решенията на трети страни. Ще разгледаме някои от тези решения в следващите раздели.
Заявките с балансирано натоварване могат да връщат последователни резултати само докато забавянето на синхронната репликация се поддържа ниско. На практика дори най-съвременната мрежова инфраструктура като AWS може да показва закъснения от десетки милисекунди:
Обикновено наблюдаваме времена на забавяне в 10-те милисекунди. [...] Въпреки това, при типични условия, забавянето на репликацията под една минута е често срещано. [...]
Многорегионалните реплики, използващи логическа репликация, ще бъдат повлияни от скоростта на промяна/прилагане и закъсненията в мрежовата комуникация между избраните конкретни региони. Репликата в различни региони, използващи Aurora Global Database, ще имат типично забавяне от под секунда.
Както беше посочено по-рано, решенията на трети страни разчитат на основните функции на PostgreSQL. Например, балансирането на натоварването на заявките за четене се постига с помощта на множество синхронни режими на готовност.
Решения
pgpool-II
pgpool-II е богат на функции продукт, който осигурява както балансиране на натоварването, така и кеширане на заявки в паметта. Това е подмяна, не са необходими промени от страната на приложението.
Като средство за балансиране на натоварването pgpool-II разглежда всяка SQL заявка — за да бъдат балансирани на натоварването, заявките SELECT трябва да отговарят на няколко условия.
Настройката може да бъде толкова проста, колкото един възел, показан по-долу е клъстер с два възела:
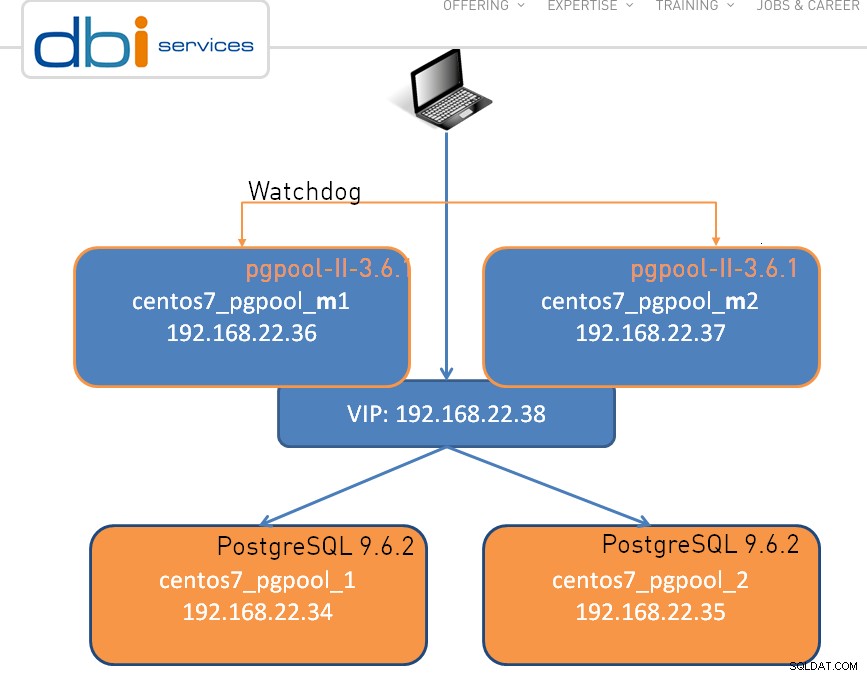
Както е в случая с всеки страхотен софтуер, има определени ограничения , и pgpool-II не прави изключение:
- Не обработва заявки с множество изрази.
- SELECT заявките към временни таблици изискват SQL коментара /*NO LOAD BALANCE*/.
Приложенията, работещи във високопроизводителни среди, ще се възползват от смесена конфигурация, при която pgBouncer е пул за свързване, а pgpool-II обработва балансиране на натоварването и кеширане. Резултатът е впечатляващо 4 пъти увеличение на пропускателната способност и 40% намаляване на латентността:
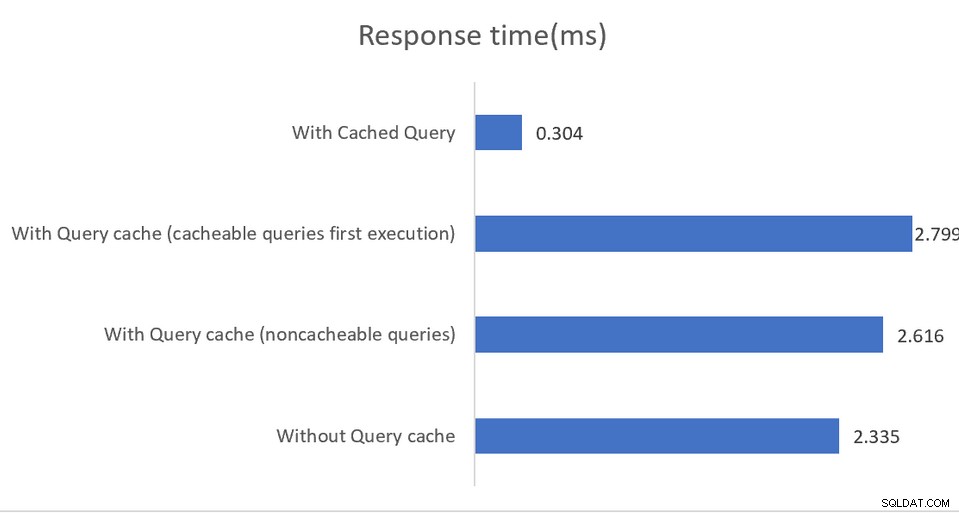
Кеширането в паметта отново работи само при заявки за четене, с кеширане данните се записват или в споделената памет, или във външна мемкеширана инсталация. Въпреки че документацията е доста добра в обяснението на различните опции за конфигурация, тя косвено подсказва, че реализациите трябва да наблюдават изхода на SHOW POOL CACHE, за да предупреждават при коефициенти на попадане, падащи под 70%, в който момент се губи печалбата на производителността, осигурена от кеширането.
Букардо
Bucardo е инструмент за репликация на PostgreSQL, написан на Perl и PL/Perl.
Споменах Bucardo, тъй като балансирането на натоварването е една от неговите характеристики, според PostgreSQL wiki, обаче търсенето в интернет не дава подходящи резултати. За да изясня се насочих към официалната документация, която включва подробности за това как всъщност работи софтуерът:

Това е доста ясно, че Bucardo не е балансьор на натоварване, точно както беше посочен от хората в Database Soup.
HAProxy
HAProxy е инструмент за балансиране на натоварването с общо предназначение, което работи на ниво TCP (за целите на връзките към базата данни). Проверките на състоянието гарантират, че заявките се изпращат само до живи възли.
В сравнение с pgpool-II, приложенията, използващи HAProxy като балансьор на натоварването, трябва да бъдат информирани за заявките за изпращане на крайната точка към възлите за четене.
Apache Ignite
Apache Ignite е кеш от второ ниво, който разбира ANSI-99 SQL и осигурява поддръжка за ACID транзакции. Apache Ignite не разбира PostgreSQL Frontend/Backend Protocol и следователно приложенията трябва да използват или постоянен слой, като Hibernate ORM. Като алтернатива на модифицирането на приложения, Apache Ignite предоставя `memcached интеграция`_, която изисква разширението memcached PostgreSQL. За съжаление, тази последна опция не е съвместима с последните версии на PostgreSQL, тъй като разширението pgmemcache е актуализирано последно през 2017 г.
Данни на Heimdall
Като търговски продукт, Heimdall Data поставя отметки в двете квадратчета:балансиране на натоварването и кеширане. Това е зрял продукт, който беше демонстриран на конференции на PostgreSQL още през PGCon 2017:

Повече подробности и демонстрация на продукта можете да намерите в блога на Azure за PostgreSQL .
Заключение
В днешните разпределени изчисления кеширането на заявки и балансирането на натоварването са също толкова важни за настройката на производителността на PostgreSQL, колкото добре познатите GUC, ядрото на ОС, съхранението и оптимизирането на заявките. Докато pgpool-II и Heimdall Data са с отворен код и съответно предпочитаните от търговската мрежа решения, има случаи, когато нарочно направените инструменти могат да се използват като градивни елементи за постигане на подобни резултати.