Трябва да има много мощни инструменти, налични като опция за архивиране и възстановяване за PostgreSQL като цяло; Barman, PgBackRest, BART са само няколко в този контекст. Това, което привлече вниманието ни, беше, че Barman е инструмент, който бързо наваксва внедряването на производството и пазарните тенденции.
Без значение дали става въпрос за внедряване, базирано на docker, необходимост от съхраняване на резервно копие в различно облачно хранилище или нужди от силно персонализирана архитектура за възстановяване след бедствие - Barman е много силен претендент във всички подобни случаи.
Този блог изследва Барман с няколко предположения относно внедряването, но в никакъв случай това не трябва да се счита само за възможен набор от функции. Barman е далеч отвъд това, което можем да уловим в този блог и трябва да бъде проучен допълнително, ако се вземе предвид „архивиране и възстановяване на екземпляр на PostgreSQL“.
Предположение за внедряване, готово за DR
RPO=0 обикновено идва на цена - синхронното внедряване на сървър в режим на готовност често би отговаряло на това, но след това се отразява доста често на TPS на основния сървър.
Подобно на PostgreSQL, Barman предоставя множество опции за внедряване, за да отговори на вашите нужди, когато става въпрос за RPO спрямо производителност. Помислете за простота на внедряване, RPO=0 или почти нулево въздействие върху производителността; Барман се вписва във всичко.
Обмислихме следното внедряване, за да създадем решение за възстановяване при бедствие за нашата архитектура за архивиране и възстановяване.
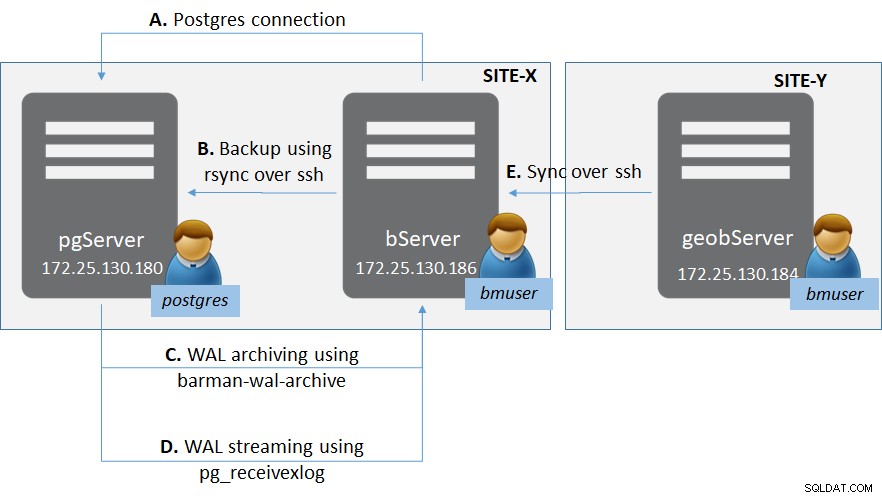 Фигура 1:Разгръщане на PostgreSQL с Barman
Фигура 1:Разгръщане на PostgreSQL с BarmanИма два сайта (както по принцип за сайтове за аварийно възстановяване) - Site-X и Site-Y.
В Site-X има:
- Един сървър „pgServer“, който хоства екземпляр на PostgreSQL сървър pgServer, и един потребител на ОС „postgres“
- екземпляр на PostgreSQL също да хоства роля на суперпотребител „bmuser“
- Един сървър „bServer“, който хоства двоичните файлове на Barman и потребител на ОС „bmuser“
В Site-Y има:
- Един сървър „geobServer“, който хоства двоичните файлове на Barman и потребител на ОС „bmuser“
В тази настройка има множество видове връзки.
- Между „bServer“ и „pgServer“:
- Свързаност на ниво на управление от Barman към екземпляра на PostgreSQL
- rsync свързаност, за да направите действително базово архивиране от Barman към екземпляра на PostgreSQL
- Архивиране на WAL с помощта на barman-wal-archive от екземпляра на PostgreSQL до Barman
- WAL стрийминг с помощта на pg_receivexlog в Barman
- Между „bServer“ и „geobserver“:
- Синхронизация между сървърите на Barman за осигуряване на георепликация
Свързването първо
Основната нужда от свързаност между сървърите е чрез ssh. За да го направите, се използват ssh-ключове без парола. Нека установим ssh ключовете и да ги разменим.
На pgServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"На bServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"На geobServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Конфигурация на екземпляр на PostgreSQL
Има две основни неща, от които се нуждаем, за да създадем отново екземпляр на postgres – базовата директория и регистрационните файлове на WAL/Transactions, генерирани след това. Барман сървър интелигентно ги следи. Това, от което се нуждаем, е да гарантираме, че са генерирани правилни емисии, за да може Барман да събира тези артефакти.
Добавете следните редове към postgresql.conf:
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'Командата за архивиране гарантира, че когато WAL трябва да бъде архивиран от postgres екземпляр, помощната програма barman-wal-archive го изпраща на сървъра на Barman. Трябва да се отбележи, че пакетът barman-cli следователно трябва да бъде достъпен на „pgServer“. Има и друга опция за използване на rsync, ако не искаме да използваме помощната програма barman-wal-archive.
Добавете следното към pg_hba.conf:
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5По принцип позволява репликация и нормална връзка от „bmserver“ към този postgres екземпляр.
Сега просто рестартирайте екземпляра и създайте роля на супер потребител, наречена bmuser:
example@sqldat.com$ pg_ctl restart
example@sqldat.com$ createuser -s -P bmuser Ако е необходимо, можем да избегнем използването на bmuser и като суперпотребител; които ще се нуждаят от привилегии, присвоени на този потребител. За горния пример използвахме и bmuser като парола. Но това е почти всичко, доколкото се изисква конфигурация на PostgreSQL екземпляр.
Конфигурация на барман
Barman има три основни компонента в своята конфигурация:
- Глобална конфигурация
- Конфигурация на ниво сървър
- Потребител, който ще управлява бармана
В нашия случай, тъй като Barman се инсталира чрез rpm, нашите глобални конфигурационни файлове са съхранени на:
/etc/barman.confИскахме да съхраняваме конфигурацията на ниво сървър в домашната директория на bmuser, следователно нашият глобален конфигурационен файл имаше следното съдържание:
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOКонфигурация на първичния барман сървър
При внедряването по-горе решихме да запазим основния сървър на Barman в същия център за данни/сайт, където се съхранява екземплярът на PostgreSQL. Предимството на същото е, че има по-малко забавяне и по-бързо възстановяване в случай, че е необходимо. Излишно е да казвам, че на сървъра на PostgreSQL също са необходими по-малко нужди от изчисления и/или мрежова честотна лента.
За да позволим на Barman да управлява екземпляра на PostgreSQL на pgServer, трябва да добавим конфигурационен файл (нарекли сме pgserver.conf) със следното съдържание:
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh example@sqldat.com
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoИ .pgpass файл, съдържащ идентификационните данни за bmuser в екземпляра на PostgreSQL:
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass За да разберете малко повече важните конфигурационни елементи:
- ssh_command :Използва се за установяване на връзка, през която ще се извърши rsync
- conninfo :Низ за връзка, за да позволи на Barman да установи връзка с postgres сървър
- reuse_backup :За да разрешите постепенно архивиране с по-малко място за съхранение
- резервен_метод :метод за архивиране на основната директория
- префикс_път :местоположение, където се съхраняват двоични файлове pg_receivexlog
- streaming_conninfo :Низ за връзка, използван за поточно предаване на WAL
- create_slot :За да се уверите, че слотове са създадени от екземпляр на postgres
Конфигурация на сървъра за пасивни бармани
Конфигурацията на сайт за географска репликация е доста проста. Всичко, от което се нуждае, е информация за ssh връзка, върху която този сайт на пасивен възел ще извърши репликацията.
Това, което е интересно е, че такъв пасивен възел може да работи в режим на смесване; с други думи - те могат да действат като активни сървъри на Barman, за да правят резервни копия за PostgreSQL сайтове и паралелно да действат като репликационен/каскаден сайт за други сървъри на Barman.
Тъй като в нашия случай този екземпляр на Barman (на Site-Y) трябва да бъде просто пасивен възел, всичко, от което се нуждаем, е да създадем файла /home/bmuser/barman.d/pgserver.conf със следната конфигурация:
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh example@sqldat.comС предположение, че ключовете са разменени и глобалната конфигурация на този възел е направена, както беше споменато по-горе - почти сме готови с конфигурацията.
И ето първото ни архивиране и възстановяване
На сървъра се уверете, че фоновият процес за получаване на WAL е задействан; и след това проверете конфигурацията на сървъра:
example@sqldat.com$ barman cron
example@sqldat.com$ barman check pgserverПроверката трябва да е ОК за всички подстъпки. Ако не, вижте /home/bmuser/barman.log.
Издайте команда за архивиране на Barman, за да сте сигурни, че има базови ДАННИ, върху които може да се приложи WAL:
example@sqldat.com$ barman backup pgserverНа „geobmserver“ се уверете, че репликацията се извършва, като изпълните следните команди:
example@sqldat.com$ barman cron
example@sqldat.com$ barman list-backup pgserverCron трябва да се вмъкне във файла crontab (ако не присъства). За простота не съм го показал тук. Последната команда ще покаже, че папката за архивиране е създадена и на geobmserver.
Сега в екземпляра на Postgres, нека създадем някои фиктивни данни:
example@sqldat.com$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
example@sqldat.com$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"Репликацията на WAL от екземпляра на PostgreSQL може да се види с помощта на командата по-долу:
example@sqldat.com$ psql -U postgres -c "SELECT * from pg_stat_replication ;”За да създадете повторно екземпляр на Site-Y, първо се уверете, че WAL записите се превключват. или този пример, за да създадете чисто възстановяване:
example@sqldat.com$ barman switch-xlog --force --archive pgserverНа Site-X, нека изведем самостоятелен екземпляр на PostgreSQL, за да проверим дали архивирането е разумно:
example@sqldat.com$ barman cron
barman recover --get-wal pgserver latest /tmp/dataСега редактирайте файловете postgresql.conf и postgresql.auto.conf според нуждите. Следва обяснение на направените промени за този пример:
- postgresql.conf :listen_addresses коментирани така, че по подразбиране да е localhost
- postgresql.auto.conf :премахнати sudo bmuser от restore_command
Изведете тези ДАННИ в /tmp/data и проверете съществуването на вашите записи.
Заключение
Това беше само върхът на айсберга. Barman е много по-дълбок от това поради функционалността, която предоставя - напр. действа като синхронизиран режим на готовност, кука скриптове и така нататък. Излишно е да казвам, че цялата документация трябва да бъде проучена, за да се конфигурира според нуждите на вашата производствена среда.