Един от ключовите аспекти на високата наличност е способността за бърза реакция при неуспехи. Не е необичайно да управлявате ръчно бази данни и да имате софтуер за наблюдение, който следи здравето на базата данни. В случай на повреда, софтуерът за наблюдение изпраща сигнал до дежурния персонал. Това означава, че някой потенциално може да се наложи да се събуди, да стигне до компютър и да влезе в системите и да прегледа регистрационните файлове - тоест има доста време, преди да започне възстановяването. В идеалния случай целият процес трябва да бъде автоматизиран.
В този блог ще разгледаме как да внедрим напълно автоматизирана система, която открива кога основната база данни се повреди и инициира процедури за преминаване при отказ чрез популяризиране на вторична база данни. Ще използваме ClusterControl, за да извършим автоматично превключване при отказ на базата данни Moodle PostgreSQL.
Предимство на автоматичното превключване при отказ
- По-малко време за възстановяване на услугата за база данни
- По-високо време на работа на системата
- По-малко разчитане на DBA или администратора, който е настроил висока наличност за базата данни
Архитектура
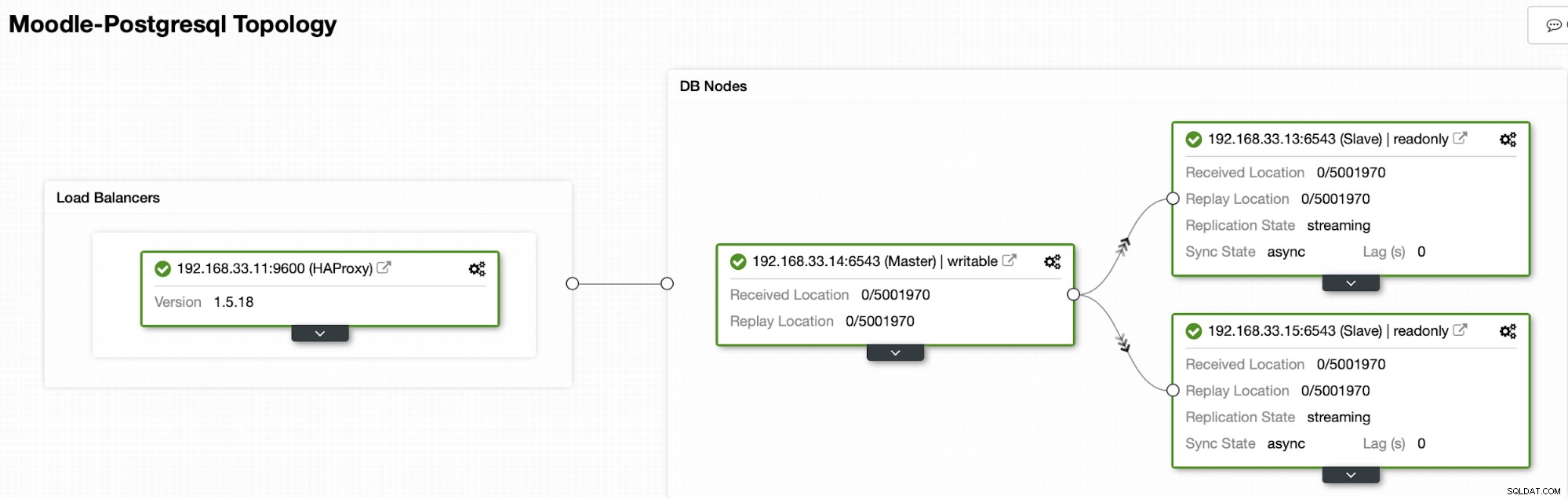
В момента имаме един първичен сървър на Postgres и два вторични сървъра под HAProxy балансиране на натоварването който изпраща трафика на Moodle към основния възел на PostgreSQL. Възстановяването на клъстер и автоматичното възстановяване на възел в ClusterControl са важните настройки за извършване на процеса на автоматичен отказ.

Контролиране на кой сървър да премине при отказ
ClusterControl предлага бели и черни списъци на набор от сървъри, които искате да участвате в преодоляването на отказ или да изключите като кандидат.
Има две променливи, които можете да зададете в конфигурацията на cmon,
- replication_failover_whitelist :съдържа списък с IP адреси или имена на хостове на вторични сървъри, които трябва да се използват като потенциални първични кандидати. Ако тази променлива е зададена, ще бъдат взети предвид само тези хостове.
- replication_failover_blacklist :съдържа списък с хостове, които никога няма да се считат за основен кандидат. Можете да го използвате за изброяване на вторични сървъри, които се използват за архивиране или аналитични заявки. Ако хардуерът варира между вторичните сървъри, може да искате да поставите тук сървърите, които използват по-бавен хардуер.
Автоматичен процес на отказ
Стъпка 1
Започнахме зареждането на данни на основния сървър (192.168.33.14) с помощта на инструмента sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Стъпка 2
Ще спрем основния сървър на Postgres (192.168.33.14). В ClusterControl параметърът (enable_cluster_autorecovery) е активиран, така че ще популяризира следващия подходящ първичен.
# service postgresql-12 stopСтъпка 3
ClusterControl открива неизправности в първичния и популяризира вторичен с най-актуалните данни като нов първичен. Работи и на останалите вторични сървъри, за да ги накара да се репликират от новия основен.

В нашия случай (192.168.33.13) е нов основен сървър и вторичните сървъри вече се репликират от този нов първичен сървър. Сега HAProxy насочва трафика на базата данни от сървърите на Moodle към последния първичен сървър.
От (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)От (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Текуща топология
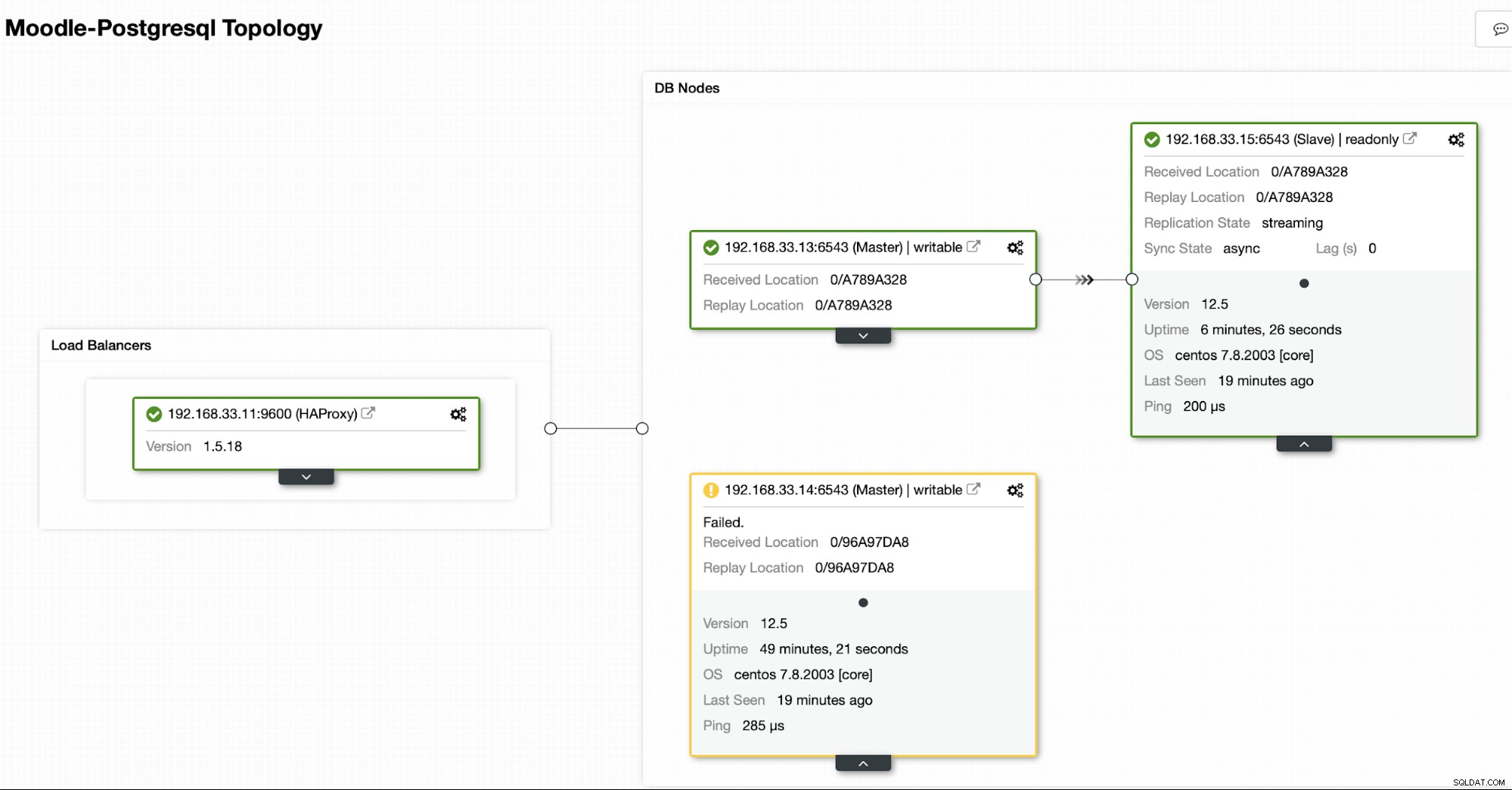
Когато HAProxy открие, че един от нашите възли, първичен или реплика, е не е достъпен, автоматично го маркира като офлайн. HAProxy няма да изпраща никакъв трафик от приложението Moodle към него. Тази проверка се извършва от скриптове за проверка на състоянието, които са конфигурирани от ClusterControl по време на внедряването.
След като ClusterControl промотира реплики сървър в основен, нашият HAProxy маркира стария първичен като офлайн и поставя популяризирания възел онлайн.
След като старият основен сървър е отново онлайн, той няма да се синхронизира автоматично с новия основен сървър. Трябва да го пуснем обратно в топологията и това може да стане чрез интерфейса на ClusterControl. Това ще избегне възможността за загуба на данни или непоследователност, в случай че искаме да проучим защо този сървър се е провалил на първо място.
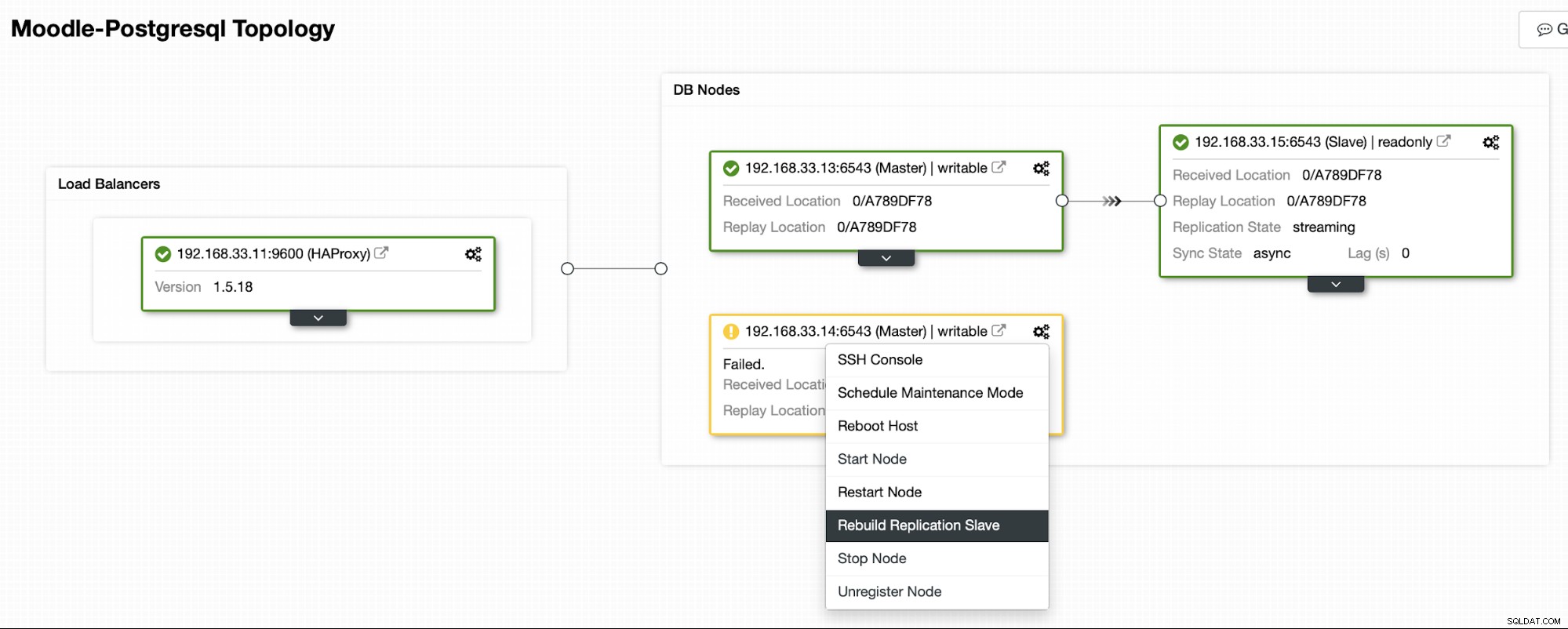
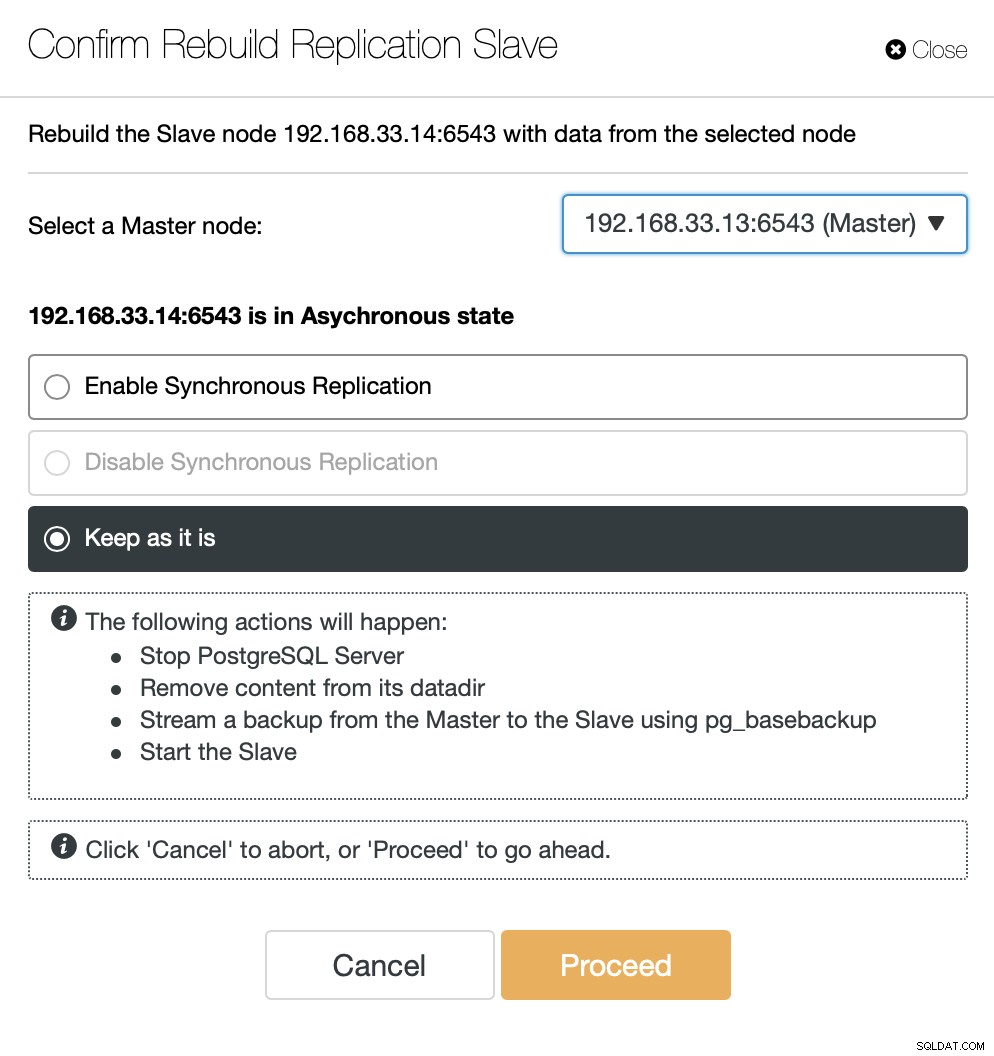
ClusterControl ще предава поточно архивиране от новия основен сървър и ще конфигурира репликацията.
Заключение
Автоматичното преминаване на отказ е важна част от всяка производствена база данни на Moodle. Той може да намали времето за престой, когато сървърът изпадне, но също и при изпълнение на общи задачи по поддръжка или миграции. Важно е да го направите правилно, тъй като е важно софтуерът за отказване да вземе правилните решения.