Какво е оптимизация на заявки в SQL Server? Това е голяма тема. Всяка техника или проблем се нуждае от отделна статия, която да покрие основите. Но когато току-що започвате да изравнявате играта си със заявки, имате нужда от нещо по-просто, на което да разчитате. Това е целта на тази статия.
Може да кажете, че вашите заявки са оптимални, всичко работи добре и потребителите са доволни. Разбира се, производителността не е всичко. Резултатите също трябва да са правилни. Независимо дали става дума за присъединяване, подзаявка, синоним, CTE, изглед или каквото и да е, той трябва да работи приемливо.
И в края на деня можете да се приберете вкъщи с вашите потребители. Не искате да останете в офиса и да коригирате бавно изпълняващите се заявки за една нощ.
Преди да започнем, позволете ми да ви уверя, че пътуването няма да бъде трудно. Това ще бъде просто грунд. Ще имаме примери, които също няма да са ви чужди. И накрая, когато сте готови за по-задълбочено проучване, ще ви представим някои връзки, които можете да проверите.
Да започнем.
1. Оптимизацията на SQL заявки започва от дизайн и архитектура
Изненадан? Оптимизацията на SQL заявки не е закъсняла мисъл или лейкопласт, когато нещо се счупи. Вашата заявка се изпълнява толкова бързо, колкото позволява вашият дизайн. Говорим за нормализирани таблици, правилните типове данни, използването на индекси, архивиране на стари данни и всяка от най-добрите практики, за които можете да се сетите.
Добрият дизайн на базата данни работи в синергия с правилния хардуер и настройките на SQL Server. Проектирахте ли го така, че да работи гладко в продължение на няколко години и все още да се чувства нов? Това е голяма мечта, но имаме само определено (обикновено – кратко) време да помислим за това.
Няма да е перфектно в първия ден от производството, но трябваше да покрием основите. Ще сведем до минимум техническия дълг. Ако работите с екип, това е страхотно в сравнение с шоу за един човек. Можете да покриете голяма част от звънците и свирките.
И все пак, какво ще стане, ако базата данни работи на живо и ударите стената на производителността? Ето някои съвети и трикове за оптимизиране на SQL заявки.
2. Открийте проблемни заявки със стандартен отчет на SQL Server
Когато кодирате, е лесно да забележите дълга серия от код или съхранена процедура. Можете да го отстраните ред по ред. Редът, който изостава, е този, който трябва да се поправи.
Но какво ще стане, ако вашето бюро за помощ хвърли дузина билети, защото е бавно? Потребителите не могат да определят точното местоположение в кода, както и бюрото за помощ. Времето е най-големият ви враг.
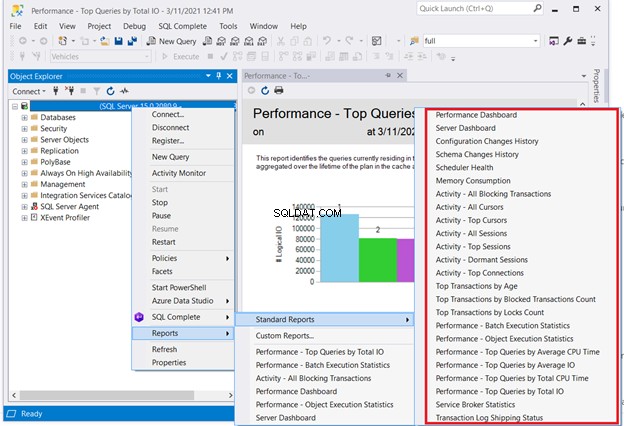
Едно решение, което няма да изисква кодиране, е проверката на стандартните отчети на SQL Server. Щракнете с десния бутон върху необходимия сървър в SQL Server Management Studio> Отчети> Стандартни отчети . Нашата точка на интерес може да бъде Табло за управление на производителността или Ефективност – Топ заявки по общ I/O . Изберете първата заявка, която се представя лошо. След това стартирайте оптимизацията на SQL заявки или настройката на производителността на SQL от там.
3. Настройка на SQL заявка със STATISTICS IO
След като определите въпросната заявка, можете да започнете да проверявате логически четения в STATISTICS IO. Това е един от инструментите за оптимизиране на SQL заявки.
Има няколко I/O точки, но трябва да се съсредоточите върху логическите четения. Колкото по-високи са логическите показания, толкова по-проблематична е производителността на заявката.
Като намалите следните 3 фактора, можете да ускорите заявките за настройка на производителността в SQL:
- високо логично четене,
- високи LOB логически четения,
- или високи логически четения на WorkTable/WorkFile.
За да получите информация относно логическите четения, включете STATISTICS IO в прозореца за заявка на SQL Server Management Studio.
ВКЛЮЧЕТЕ СТАТИСТИКА IO
Можете да получите изхода в раздела Съобщения, след като заявката приключи. Фигура 2 показва примерния изход:
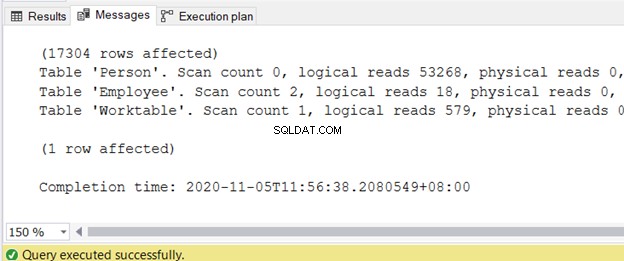
Написах отделна статия за намаляването на логическите четения в 3 неприятни I/O статистики, които изостават от производителността на SQL заявки. Обърнете се към него за точните стъпки и примерни кодове с високи логически показания и начини за намаляването им.
4. Настройка на SQL заявка с планове за изпълнение
Само логичното четене няма да ви даде цялата картина. Поредицата от стъпки, избрани от оптимизатора на заявки, ще разкаже историята на вашия набор от резултати. Как започва всичко, след като изпълните заявката?
Фигура 3 по-долу е диаграма на това, което се случва, след като задействате изпълнението до момента, в който получите набора от резултати.
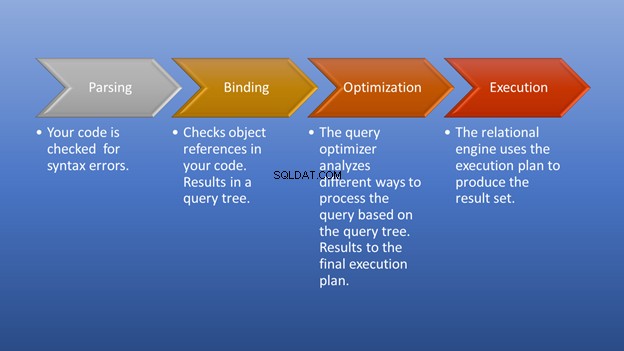
Разборът и обвързването ще се случат светкавично. Страхотната част е етапът на оптимизация, който е нашият фокус. На този етап оптимизаторът на заявки играе основна роля при избора на най-добрия възможен план за изпълнение. Въпреки че тази част се нуждае от някои ресурси, тя спестява много време, когато избира ефективен план за изпълнение. Това се случва динамично, тъй като базата данни се променя с течение на времето. По този начин програмистът може да се съсредоточи върху това как да оформи крайния резултат.
Всеки план, който оптимизаторът на заявки счита, има своята цена на заявката. Сред многото опции оптимизаторът ще избере плана с най-разумната цена. Забележка :Разумната цена не е равна на най-ниската цена. Той също така трябва да обмисли кой план ще даде най-бързи резултати. Планът с най-ниска цена не винаги е най-бързият. Например, оптимизаторът може да избере да използва няколко процесорни ядра. Ние наричаме това паралелно изпълнение. Това ще изразходва повече ресурси, но ще работи по-бързо в сравнение със серийното изпълнение.
Друг момент, който трябва да се вземе предвид, е статистиката. Оптимизаторът на заявки разчита на него, за да създаде планове за изпълнение. Ако статистическите данни са остарели, не очаквайте най-доброто решение от оптимизатора на заявки.
Когато планът бъде решен и изпълнението продължи, ще видите резултатите. Какво сега?
Проверете плана за изпълнение на заявка в SQL Server
Когато формирате заявка, първо искате да видите резултатите. Резултатите трябва да са правилни. Когато е, сте готови.
Така ли?
Ако ви липсва време и работата е заложена, можете да се съгласите с това. Освен това винаги можете да се върнете. Въпреки това, ако възникнат други проблеми, можете да ги забравите отново и отново. И тогава призракът от миналото ще ви преследва.
Сега, какво е най-добре да направите, след като получите правилните резултати?
Проверете Реалния план за изпълнение или Статистика на заявките на живо !
Последното е добро, ако заявката ви работи бавно и искате да видите какво се случва всяка секунда, докато редовете се обработват.
Понякога ситуацията ще ви принуди незабавно да прегледате плана. За да започнете, натиснете Control-M или кликнете върху Включи действителен план за изпълнение от лентата с инструменти на SQL Server Management Studio. Ако предпочитате dbForge Studio за SQL Server, отидете на Query Profiler – предоставя същата информация + някои звънци, които не можете да намерите в SSMS.
Видяхме Реалния план за изпълнение . Да продължим по-нататък.
Има ли липсващ индекс или препоръки за индекси?
Липсващ индекс е лесно да се забележи – веднага получавате предупреждението.
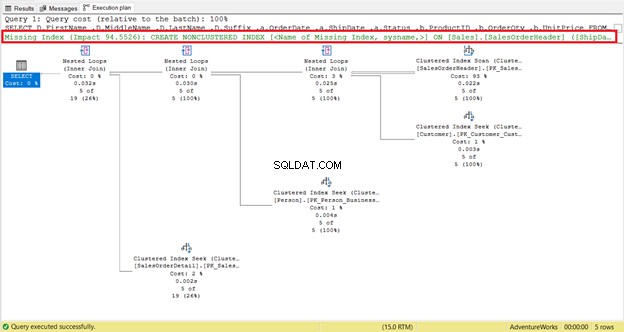
За да получите незабавен код за създаване на индекса, щракнете с десния бутон върху Липсващия индекс съобщение (оградено в червено). След това изберете Липсващи подробности за индекса . Ще се появи нов прозорец за заявка с кода за създаване на липсващия индекс. Създайте индекса.
Тази част е лесна за следване. Това е добра отправна точка за постигане на по-бързо изпълнение. Но в някои случаи няма да има ефект. Защо? Някои колони, необходими за вашата заявка, не са в индекса. Следователно, той ще се върне към сканиране на клъстериран индекс.
Трябва да проверите отново плана за изпълнение, след като създадете индекса, за да видите дали са необходими Включени колони. След това коригирайте съответно индекса и изпълнете отново заявката си. След това проверете отново плана за изпълнение.
Но какво ще стане, ако няма липсващ индекс?
Прочетете плана за изпълнение
Трябва да знаете няколко основни неща, за да започнете:
- Оператори
- Свойства
- Посока на четене
- Предупреждения
ОПЕРАТОРИ
Оптимизаторът на заявки използва някакъв вид мини-програми, наречени оператори. Видяхте някои от тях на Фигура 4 – Клъстерно търсене на индекси , Клъстерно индексно сканиране , Вложени цикли и Изберете .
За да получите изчерпателен списък с имена, икони и описания, можете да проверите тази справка от Microsoft.
Свойства
Графичните диаграми не са достатъчни, за да се разбере какво се случва зад кулисите. Трябва да копаете по-дълбоко в свойствата на всеки оператор. Например Клъстерното индексно сканиране на фигура 4 има следните свойства:
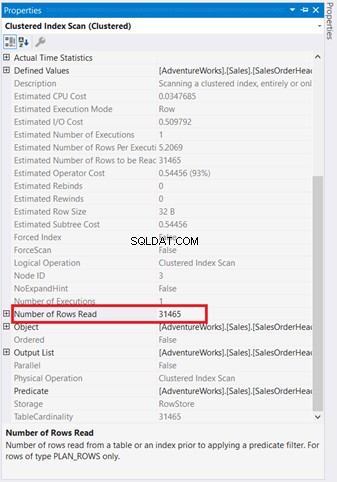
Ако го разгледате внимателно, Клъстерното индексно сканиране операторът е ужасен. Както показва Фигура 5, тя отчита 31 465 реда, но крайният резултат е само 5 реда. Ето защо на фигура 4 има препоръка за индекс за намаляване на броя на прочетените редове. Логическите показания на заявката също са високи и това обяснява защо.
За да научите повече от тези свойства, вижте списъка с общи свойства на оператора и свойства на плана.
ПОСОКА НА ЧЕТЕНЕ
Като цяло, това е като четене на японска манга - от дясно на ляво. Следвайте стрелките, които сочат наляво. Ето един прост пример от dbForge Studio за SQL Server.
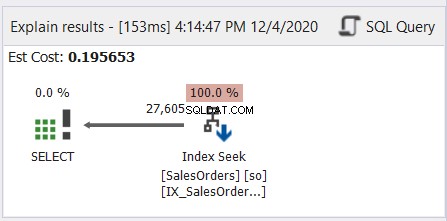
Както показва фигура 6, стрелката сочи наляво от оператора Index Seek към оператора SELECT.
Въпреки това, четенето отдясно наляво може да не винаги е правилно. Вижте Фигура 7 с пример от SSMS:
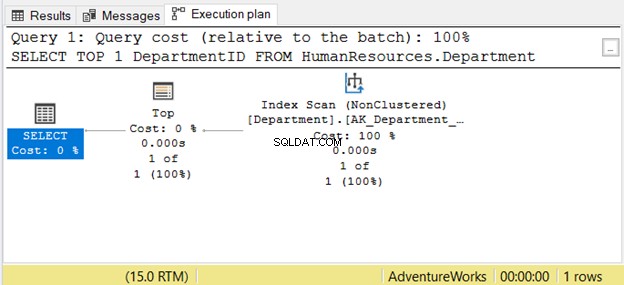
Ако го прочетете отдясно наляво, ще видите, че Индексното сканиране изходът на оператора е 1 от 1 ред. Как може да знае само 1 ред за извличане? Това е заради вгора оператор. Това ще ни обърка, ако го четем отдясно наляво.
За да разберете по-добре този случай, прочетете го като „операторът SELECT използва Top, за да извлече 1 ред с помощта на индексно сканиране“. Това е отляво надясно.
Какво трябва да използваме? Отдясно наляво или отляво надясно?
Това е вид и двете – което ви помага да разберете плана.
Докато стрелката ни дава посоката на потока от данни, нейната дебелина ни дава някои намеци за размера на данните. Нека се обърнем отново към Фигура 4.
Клъстерното индексно сканиране отидете на Вложен цикъл има по-дебела стрелка в сравнение с другите. Свойства подробности за Индексно сканиране на фигура 5 ни кажете защо е дебел (31 465 реда прочетени за краен резултат от 5 реда).
ПРЕДУПРЕЖДЕНИЯ
Икона за предупреждение, появяваща се в оператора на плана за изпълнение, ни казва, че нещо лошо се е случило в този оператор. Това може да попречи на оптимизирането на вашите SQL заявки, като изразходва повече ресурси.
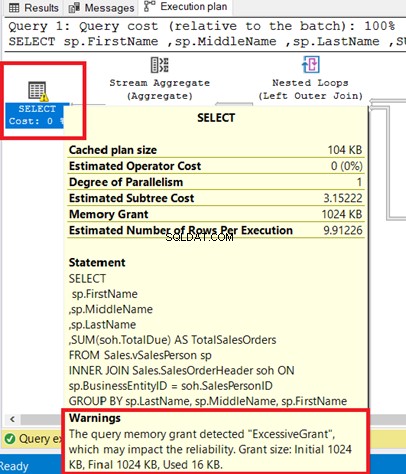
Можете да видите предупреждението в оператора SELECT. Задържането на курсора на този оператор разкрива предупредителното съобщение. Прекомерен грант предизвика това предупреждение.
Прекомерен грант се случва, когато се използва по-малко памет, отколкото е била запазена за заявката. За повече информация вижте тази документация на Microsoft.
Фигура 8 показва заявката, използвана като INNER JOIN на изглед към таблица. Можете да премахнете предупреждението, като присъедините основни таблици вместо изгледа.
Сега, когато имате основна идея за четене на планове за изпълнение, как да дефинирате какво прави заявката ви бавна?
Запознайте се с 5-те измамници на оператора на общ план
Закъснението в изпълнението на вашата заявка е като престъпление. Трябва да преследвате и арестувате тези измамници.
1. Клъстерно или неклъстерно сканиране на индекс
Първият мошеник, за който всички научават, е Clustered или Неклъстерно индексно сканиране . Неговите общи познания в оптимизацията на SQL заявки, че сканирането е лошо, а търсенията са добри. Видяхме такъв на фигура 4. Поради липсващия индекс, Клъстерното сканиране на индекса чете 31 465, за да получите 5 реда.
Не винаги обаче е така. Помислете за 2 заявки в една и съща таблица на фигура 9. Едната ще има търсене, а другата ще има сканиране.
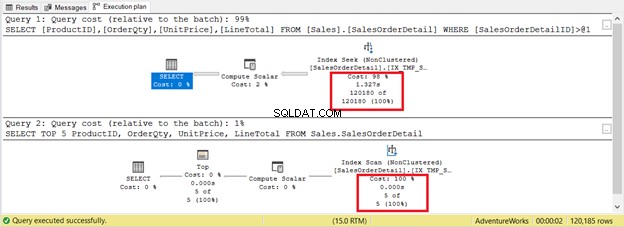
Ако базирате критериите само на броя на записите, сканирането на индекса печели само с 5 записа срещу 120 180. Изпълнението на търсенето на индекс ще отнеме повече време.
Ето още един случай, когато сканирането или търсенето почти няма значение. Те връщат едни и същи 6 записа от една и съща таблица. Логическите показания са еднакви и изминалото време е нула и в двата случая. Таблицата е много малка с само 6 записа. Включете действителния план за изпълнение и изпълнете изявленията по-долу.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
След това запазете плана за изпълнение за сравнение по-късно. Щракнете с десния бутон върху плана за изпълнение> Запазване на плана за изпълнение като .
Сега изпълнете заявката по-долу.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
След това щракнете с десния бутон върху плана за изпълнение и изберете Сравни плана за показване . След това изберете файла, който сте запазили по-рано. Трябва да имате същия изход като на фигура 10 по-долу.
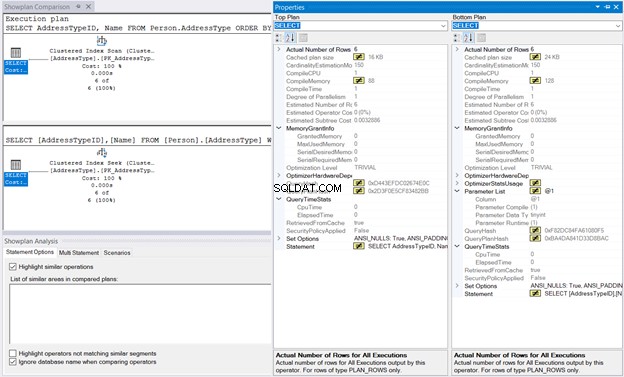
MemoryGrant и QueryTimeStats са същите. 128KBCompileMemory използван в Клъстерно търсене на индекси в сравнение с 88 КБ от Клъстерното индексно сканиране е почти незначително. Без тези цифри за сравнение, изпълнението ще изглежда същото.
2. Избягване на сканиране на таблица
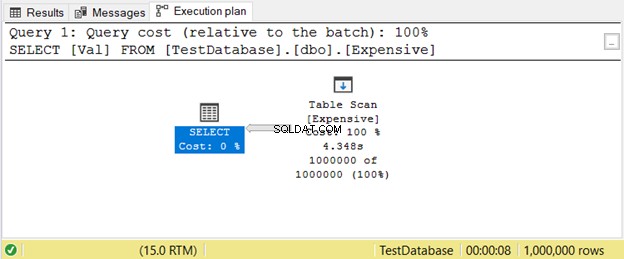
Това се случва, когато нямате индекс. Вместо да търси стойности с помощта на индекс, SQL Server ще сканира редове един по един, докато получи това, от което се нуждаете във вашата заявка. Това ще изостава много на големи маси. Простото решение е да добавите подходящия индекс.
Ето пример за план за изпълнение с Сканиране на таблица оператор на фигура 11.
3. Управление на производителността на сортиране
Тъй като идва от името, то променя реда на редовете. Това може да бъде скъпа операция.
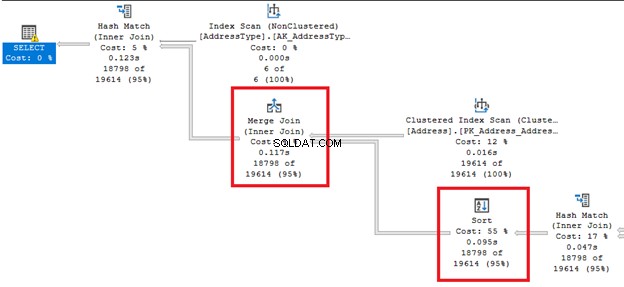
Вижте тези дебели стрелки от дясно и отляво на Сортиране оператор. Тъй като оптимизаторът на заявки реши да направи сливане на присъединяване ,а Сортиране изисква се. Забележете също, че той има най-висок процент разходи от всички оператори (55%).
Сортирането може да бъде по-обезпокоително, ако SQL Server трябва да подреди редове няколко пъти. Можете да избегнете този оператор, ако вашата таблица е предварително сортирана въз основа на изискването за заявка. Или можете да разделите една заявка на няколко.
4. Премахване на ключови търсения
На Фигура 4 преди това SQL Server препоръчва добавянето на друг индекс. Направих го, но не ми даде точно това, което исках. Вместо това ми даде търсене на индекс към новия индекс, съчетан с Ключово търсене оператор.
И така, новият индекс добави допълнителна стъпка.
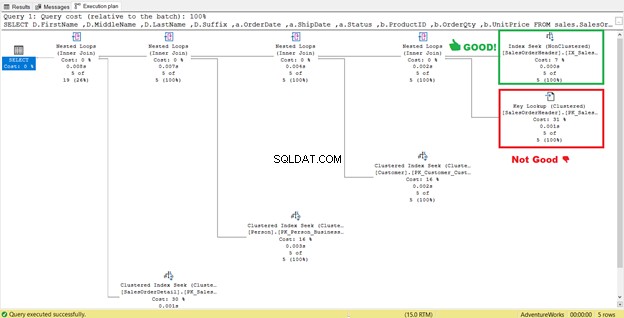
Какво означава това Ключово търсене оператор прави?
Процесорът на заявки използва нов неклъстериран индекс, поставен в зелено на фигура 13. Тъй като нашата заявка изисква колони, които не са в новия индекс, той трябва да получи тези данни с помощта на Ключово търсене от клъстерирания индекс. откъде знаем това? Задръжте курсора на мишката върху Ключовото търсене разкрива някои от неговите свойства и доказва нашата теза.
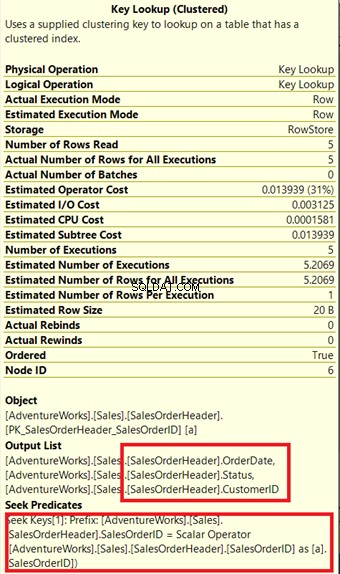
На фигура 14 забележете изходния списък. Трябва да извлечем 3 колони с помощта на PK_SalesOrderHeader_SalesOrderID клъстериран индекс. За да премахнете това, трябва да включите тези колони в новия индекс. Ето новия план, след като тези колони бъдат включени.
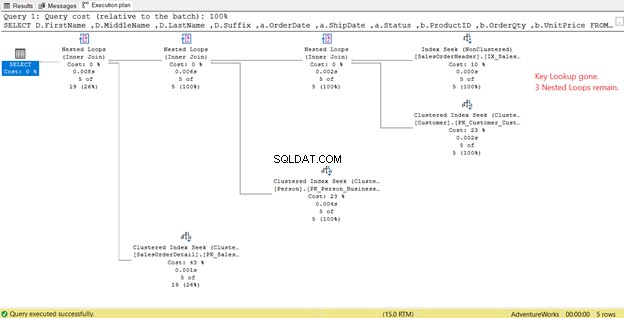
На фигура 14 видяхме 4 вложени цикъла . Четвъртият е необходим за добавеното Ключово търсене . Но след добавяне на 3 колони като включени колони в новия индекс, само 3 вложени цикъла остават и Ключово търсене се отстранява. Нямаме нужда от допълнителни стъпки.
5. Паралелизъм в плана за изпълнение на SQL Server
Досега виждахте планове за изпълнение в серийно изпълнение. Но ето планът, който използва паралелно изпълнение. Това означава, че повече от 1 процесор се използва от оптимизатора на заявки за изпълнение на заявката. Когато използваме паралелно изпълнение, виждаме Паралелизъм оператори в плана, както и други промени.
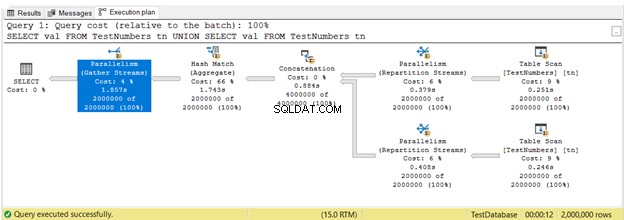
На фигура 16, 3Паралелизъм бяха използвани оператори. Забележете също, че Сканиране на таблица иконата на оператор е малко по-различна. Това се случва, когато се използва паралелно изпълнение.
Паралелизмът по своята същност не е лош. Той увеличава скоростта на заявките, като използва повече процесорни ядра. Въпреки това, той използва повече ресурси на процесора. Когато много от вашите заявки използват паралелизми, това забавя сървъра. Може да искате да проверите прага на разходите за настройка на паралелизъм във вашия SQL Server.
5. Най-добри практики за оптимизация на SQL заявки
Досега сме се занимавали с оптимизация на SQL заявки с методи, които разкриват проблеми, които е трудно да се забележи. Но има начини да го забележите в кода. Ето някои миризми на код в SQL.
Използване на SELECT *
Бързам? Тогава въвеждането на * може да бъде по-лесно от посочването на имена на колони. Въпреки това, има уловка. Колоните, от които не се нуждаете, ще изоставят заявката ви.
Има доказателство. Примерната заявка, която използвах за Фигура 15, е следната:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Вече го оптимизирахме. Но нека го променим на SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Добре е по-кратко, но проверете плана за изпълнение по-долу:
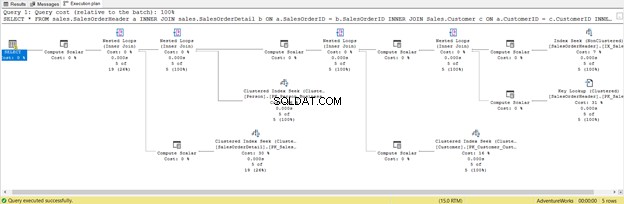
Това е следствие от включването на всички колони, дори тези, от които не се нуждаете. Върна Ключово търсене и много Compute Scalar . Накратко, тази заявка има голямо натоварване и в резултат ще изостава. Обърнете внимание и на предупреждението в оператора SELECT. Преди това го нямаше. Каква загуба!
Функции в клауза WHERE или JOIN
Друга миризма на код има функция в клаузата WHERE. Помислете за следните 2 оператора SELECT, имащи същия набор от резултати. Разликата е в клаузата WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
Първият SELECT използва функциите за дата YEAR и MONTH, за да посочи датите на доставка в рамките на юли 2011 г. Вторият оператор SELECT използва оператор BETWEEN с литерали за дата.
Първият оператор SELECT ще има план за изпълнение, подобен на фигура 4, но без препоръката за индекс. Вторият ще има по-добър план за изпълнение, подобен на Фигура 15.
По-добре оптимизираният е очевиден.
Използване на заместващи знаци
Как заместващите символи могат да повлияят на нашата оптимизация на SQL заявки? Нека имаме пример.
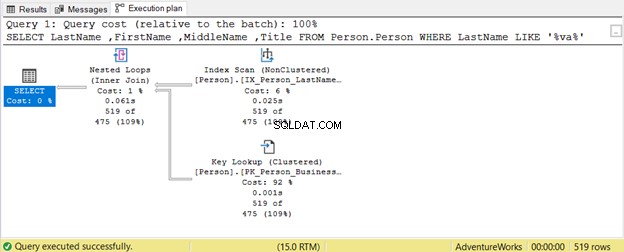
Заявката се опитва да търси наличие на низ в Фамилия във всяка позиция. Следователно Фамилия КАТО „%va%“ . Това е неефективно при големи таблици, тъй като редовете ще се проверяват един по един за наличието на този низ. Ето защо Индексно сканиране се използва. Тъй като нито един индекс не включва Заглавие колона, Ключово търсене също се използва.
Това може да бъде поправено с дизайн.
Приложението за повикване изисква ли това? Или ще е достатъчно да използвате LIKE ‘va%’?
LIKE ‘va%’ използва търсене на индекс защото таблицата има индекс на фамилно име , собствено име , и междинно име .
Можете ли да добавите още филтри в клаузата WHERE, за да намалите четенето на записите?
Вашите отговори на тези въпроси ще ви помогнат как да коригирате тази заявка.
Неявно преобразуване
SQL Server прави имплицитно преобразуване зад кулисите, за да съгласува типове данни при сравняване на стойности. Например, удобно е да присвоите номер на колона с низ без кавички. Но има уловка. Ефектът е подобен, когато използвате функция в клауза WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner е NVARCHAR(15), но се равнява на число. Той ще работи успешно поради имплицитно преобразуване. Но забележете плана за изпълнение на фигура 19 по-долу.
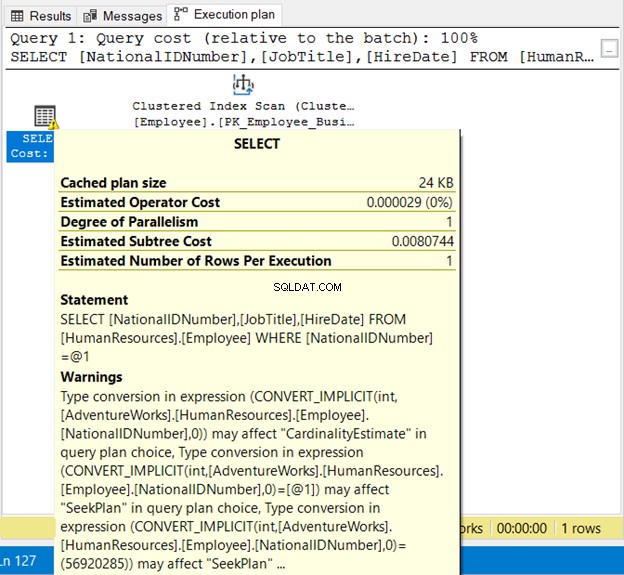
Тук виждаме 2 лоши неща. Първо, предупреждението. След това Индексното сканиране . Сканирането на индекса се случи поради имплицитно преобразуване. По този начин се уверете, че сте поставили низове в кавички или тествайте литерални стойности със същия тип данни като колоната.
Изводи за оптимизиране на заявки за SQL
Това е. Основите на оптимизацията на SQL заявки ви накараха да се почувствате малко готови за вашите заявки? Нека направим обобщение.
- Ако искате вашите заявки да бъдат оптимизирани, започнете с добър дизайн на база данни.
- Ако базата данни вече е в производство, открийте проблемните заявки, като използвате стандартните отчети на SQL Server.
- Научете колко голямо е въздействието на бавната заявка с логически четения от STATISTICS IO.
- Разровете по-дълбоко в историята на вашата бавна заявка с планове за изпълнение.
- Гледайте 4 миризми на код, които забавят заявките ви.
Има и други съвети за оптимизиране на SQL заявки, за да накарате бавната заявка да работи бързо. Както казах в началото, това е голяма тема. Така че, уведомете ни в секцията за коментари какво още сме пропуснали.
И ако ви харесва тази публикация, споделете я в любимите си социални медийни платформи.
Още оптимизация на SQL заявки от предишни статии
Ако имате нужда от още примери, ето няколко полезни публикации, свързани с техниките за оптимизиране на заявки в SQL Server.
- Влоши ли са подзаявките за ефективността? Вижте Лесно ръководство за това как да използвате подзаявки в SQL Server .
- Използване на HierarchyID спрямо дизайн на родител/дете – кое е по-бързо? Посетете Как да използвате SQL Server HierarchyID чрез лесни примери .
- Могат ли заявките за графична база данни да превъзхождат своите релационни еквиваленти в система за препоръки в реално време? Вижте Как да използвате функциите на SQL Server Graph Database .
- Кое е по-бързо:COALESCE или ISNULL? Разберете в Водещи отговори на 5 горящи въпроса относно функцията SQL COALESCE .
- ИЗБЕРЕТЕ ОТ изглед срещу ИЗБЕРЕТЕ ОТ базови таблици – коя ще работи по-бързо? Посетете 3-те най-добри съвета, които трябва да знаете, за да пишете по-бързи SQL изгледи .
- CTE спрямо временни таблици спрямо подзаявки. Знайте кой ще спечели в Всичко, което трябва да знаете за SQL CTE на едно място .
- Използване на SQL SUBSTRING в клауза WHERE – капан на производителността? Вижте дали е вярно с примери в Как да анализирате низове като професионалист с помощта на функцията SQL SUBSTRING()?
- SQL UNION ALL е по-бърз от UNION. Разберете защо в SQL UNION Cheat Sheet с 10 лесни и полезни съвета .