Балансьорите на натоварване са основен компонент от всяка високодостъпна настройка на база данни. Те се използват за увеличаване на капацитета и надеждността на вашите критични системи и приложения, като предотвратяват претоварването на всеки един сървър. Говорим много за тях в блога на Severalnines, като например защо имате нужда от тях и как работят. Един от най-популярните балансьори на натоварване, налични за MySQL и MariaDB, е HAProxy.
По отношение на функциите HAProxy не е сравним с ProxySQL или MaxScale. Въпреки това, HAProxy е бърз, здрав балансьор на натоварването, който ще работи перфектно във всяка среда, стига приложението да може да извършва разделяне на четене/запис и да изпраща SELECT заявки към един бекенд и всички записва и SELECT...FOR UPDATE към отделен бекенд.
Проследяването на всички показатели, предоставени от HAProxy, е много важно; трябва да можете да знаете състоянието на вашия прокси, особено за да разберете дали сте срещали някакви проблеми.
ClusterControl винаги е предоставял страница за състоянието на HAProxy, показваща състоянието на прокси сървъра в реално време. Сега, с новите базирани на Prometheus SCUMM (Severalnines ClusterControl Unified Monitoring &Management) табла за управление е възможно лесно да се проследи как тези показатели се променят с течение на времето.
Тази публикация в блога ще изследва различните показатели, представени в таблото за управление на HAProxy SCUMM.
Проучване на таблото за управление на HAProxy в ClusterControl
Всички табла за управление на Prometheus и SCUMM са деактивирани по подразбиране в ClusterControl. Въпреки това, разгръщането им за всеки даден клъстер е само въпрос на едно щракване. Ако наблюдавате множество клъстери с ClusterControl, можете да използвате повторно същия екземпляр на Prometheus за всеки клъстер.
След внедряване можете да получите достъп до таблото за управление на HAProxy. Нека да разгледаме наличните данни в таблото:
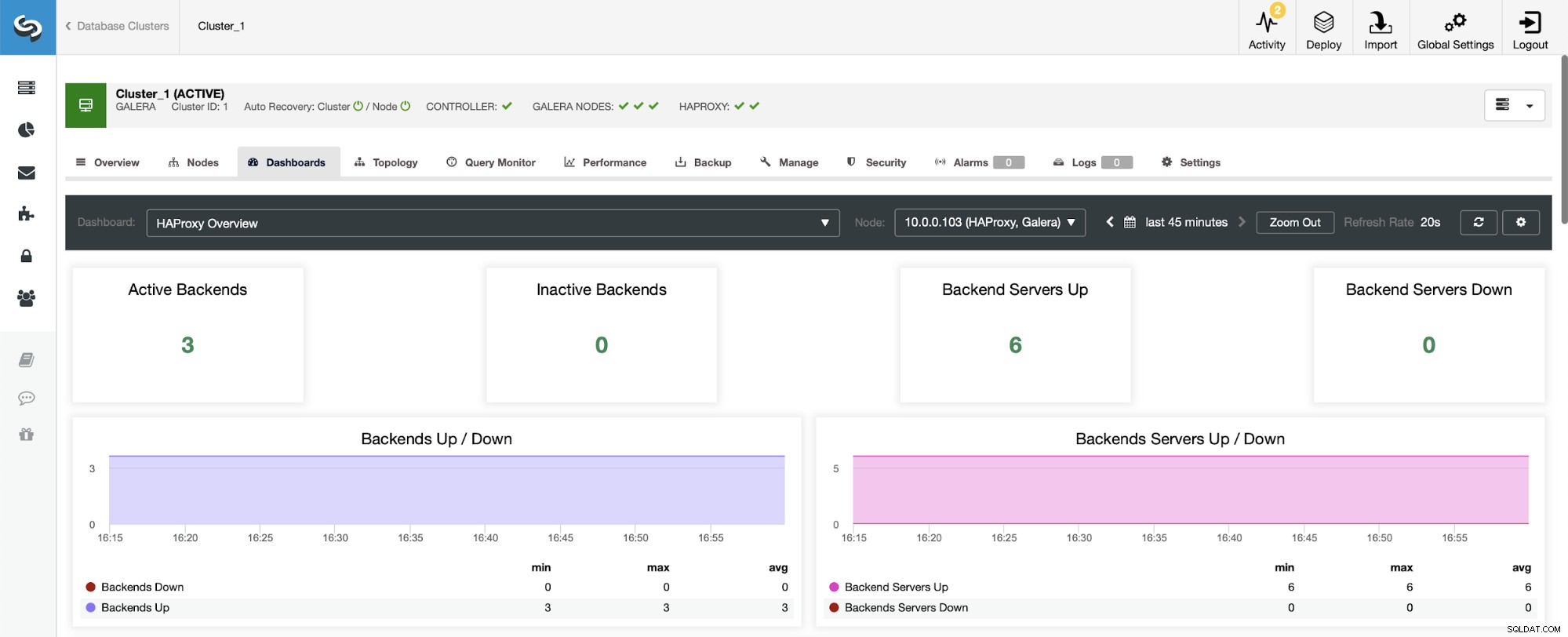
Първото нещо, което ще видите, когато отидете до таблото за управление на HAProxy е информация за състоянието на вашите бекендове. Тук, моля, имайте предвид, че това, което виждате, може да зависи от типа на клъстера и начина, по който сте внедрили HAProxy. В този случай разположихме клъстер Galera, а HAProxy беше разгърнат по кръговрат. Следователно виждате три бекенда за четене и три за запис - общо шест. Ето защо виждате всички бекендове, маркирани като „Нагоре“.
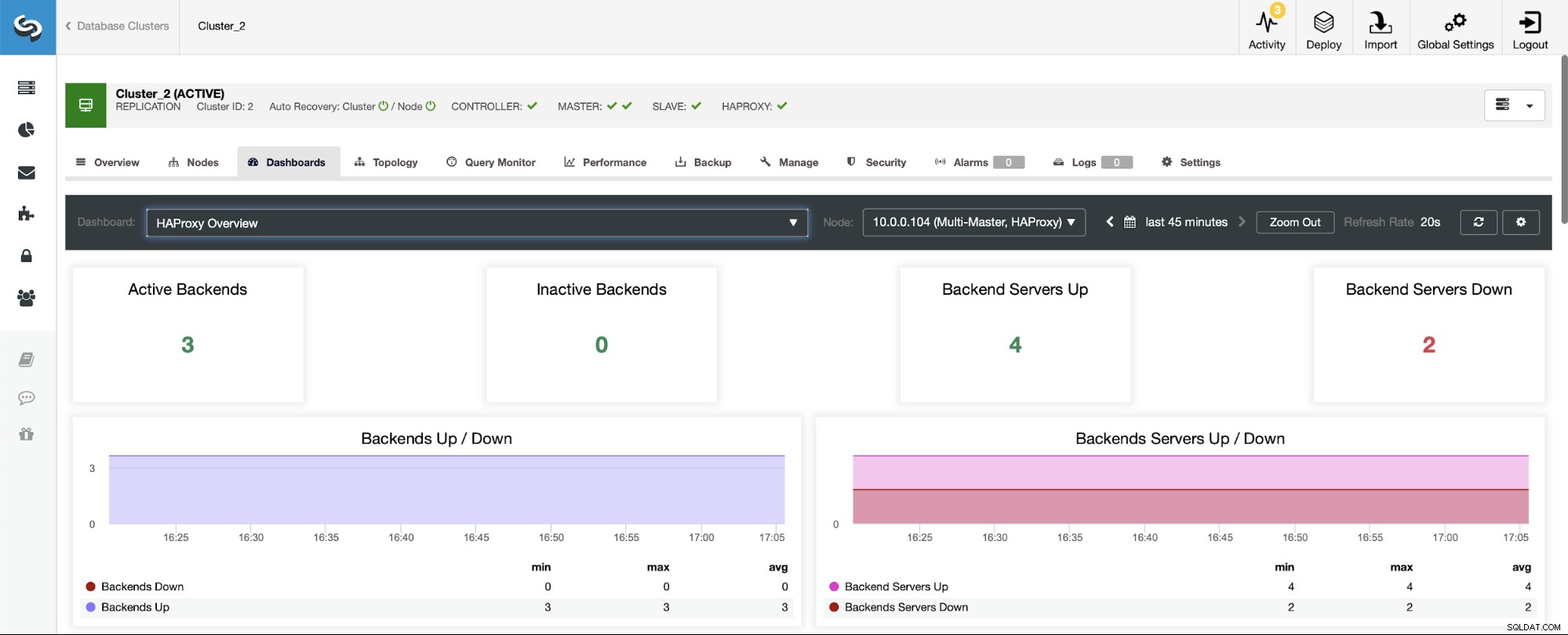
В сценарий с клъстер за репликация, нещата ще изглеждат различно, тъй като HAProxy ще бъде разгърнат в разделяне за четене/запис и скриптовете ще поддържат само един хост (главен) работещ и работещ в бекенд.
Забележете, ето защо по-долу виждате два бекенд сървъра, маркирани като „Надолу“:
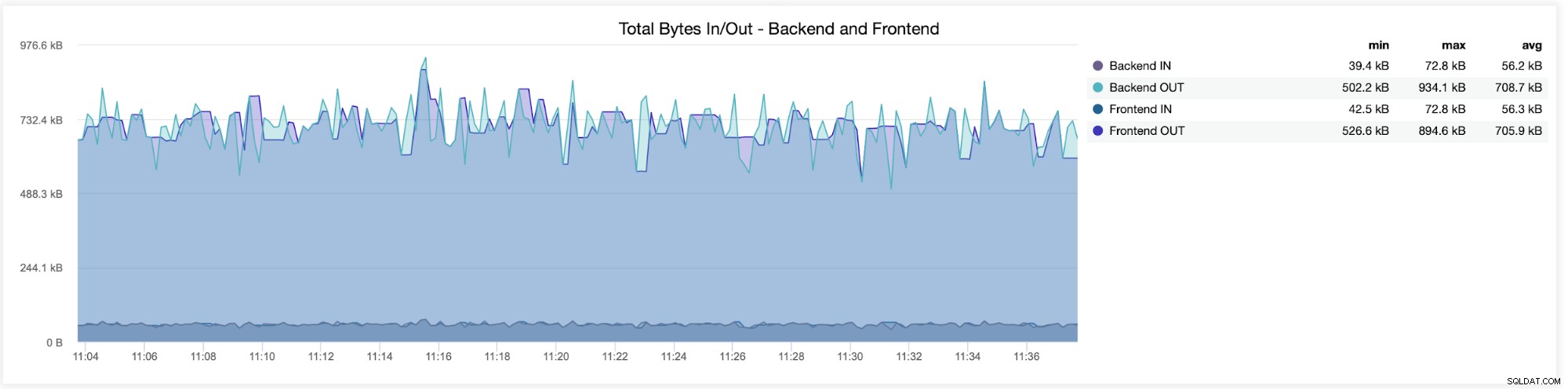
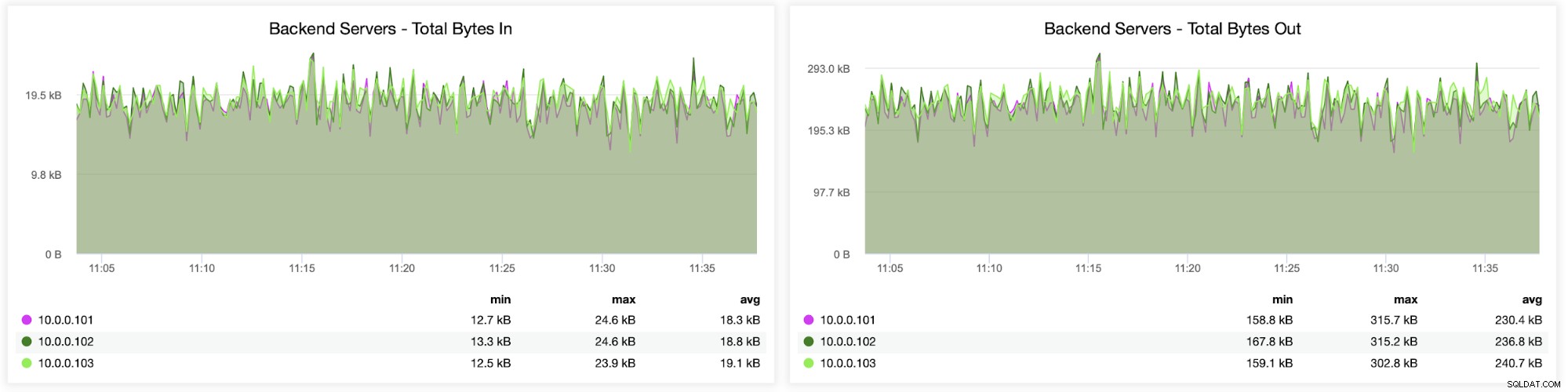
В следващата графика ще видите данните, изпратени и получени от двамата бекенд (от HAProxy към сървърите на базата данни) и преден интерфейс (между HAProxy и клиентските хостове):
Можете също да проверите разпределението на трафика между бекендовете във вашата HAProxy конфигурация. В този случай имаме два бекенда и заявките се изпращат през порт 3308, който действа като кръгова точка за достъп до нашия клъстер Galera:
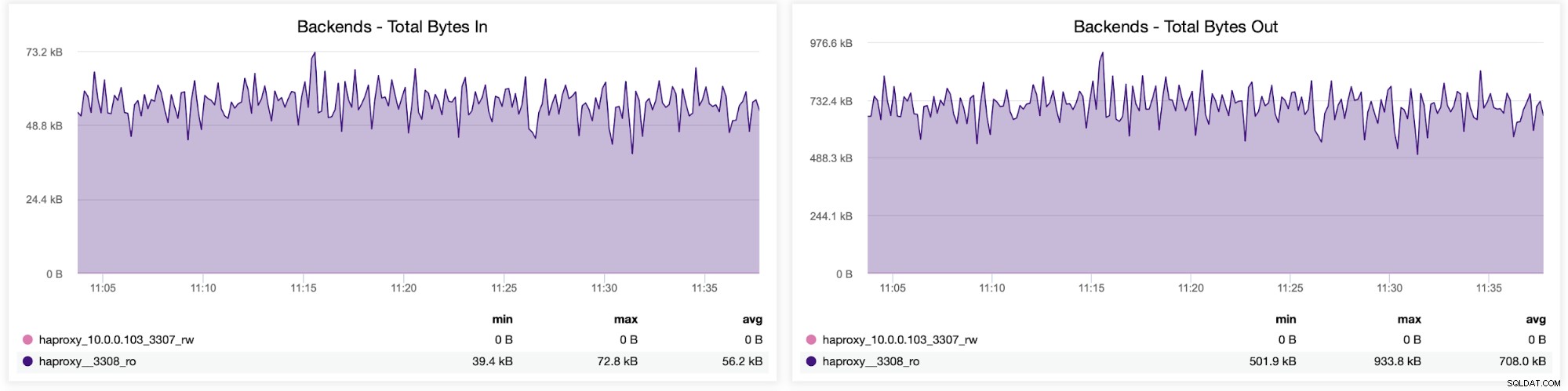
След това можете да видите как трафикът е бил разпределен между всички бекенд сървъри. В този сценарий — поради схемата за кръгов достъп — данните бяха повече или по-малко равномерно разпределени между трите бекенд сървъра на Galera:
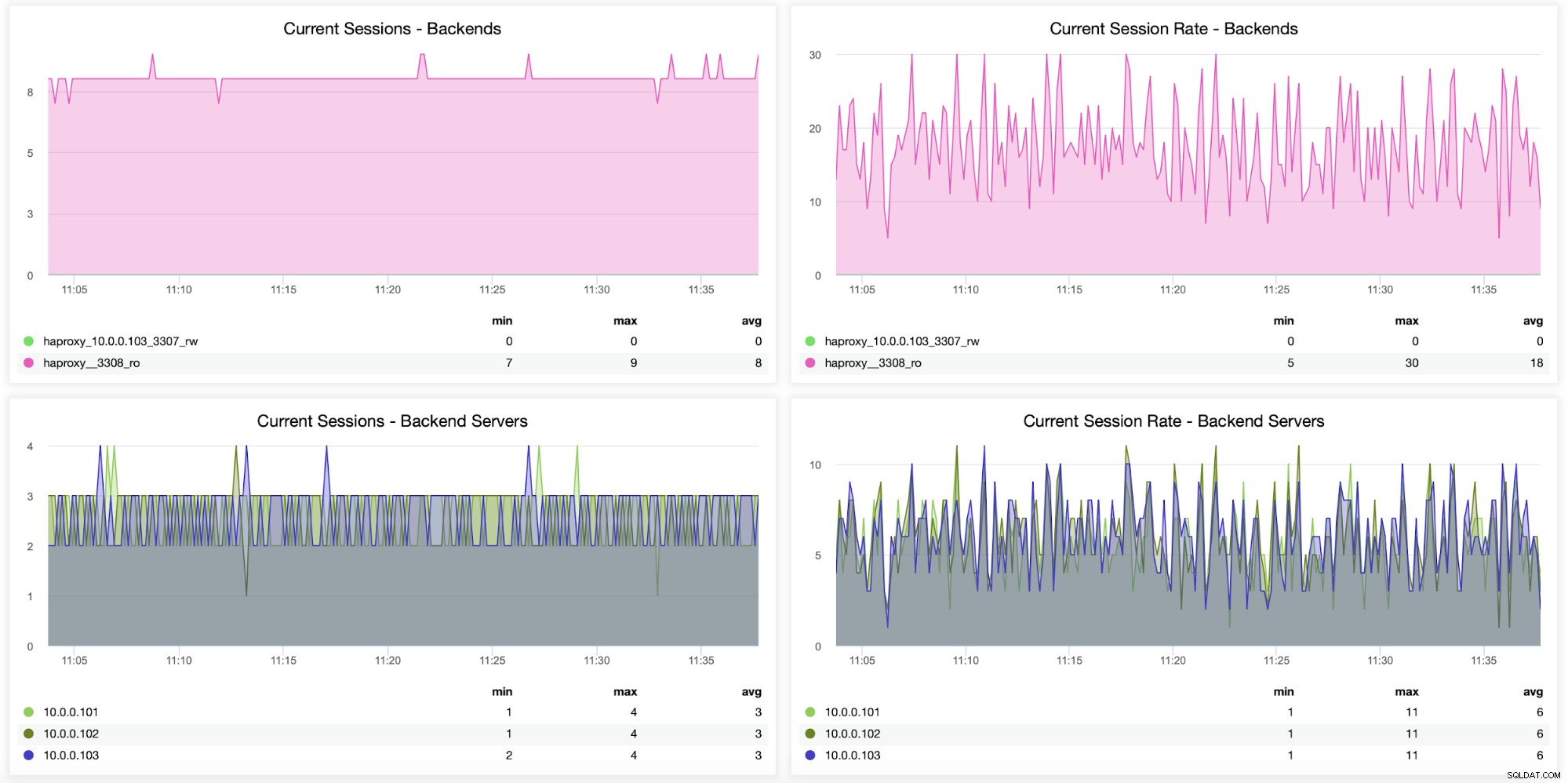
Информация за сесиите, включително колко сесии са отворени от HAProxy към бекенда сървъри, също могат да бъдат наблюдавани, както се вижда на следващата графика. Можете също така да проследите колко пъти в секунда е била отворена нова сесия за бекенда и как изглеждат тези показатели на база на бекенд сървър.
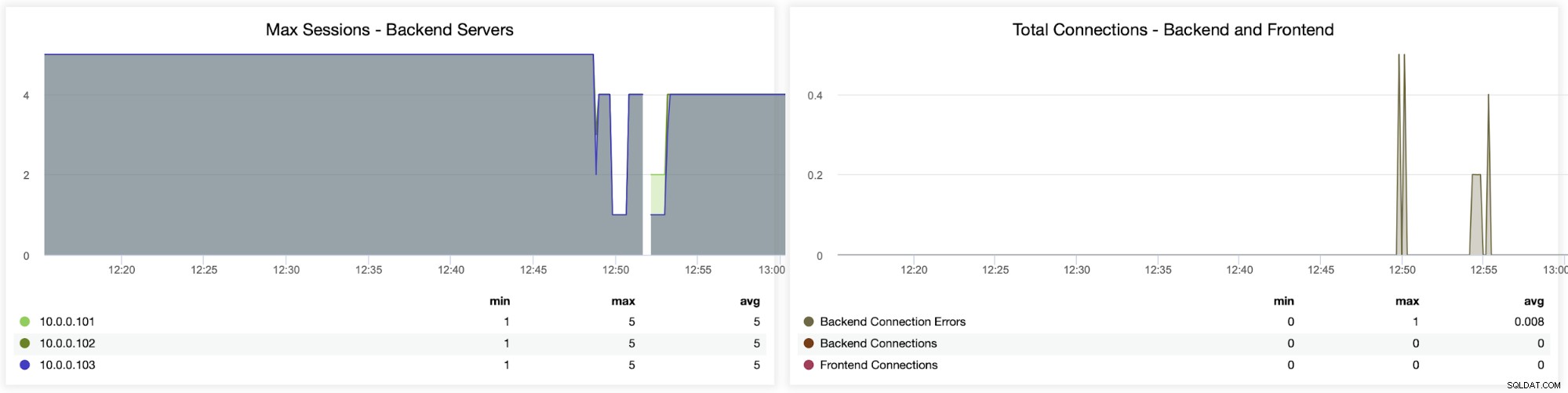
Следните две графики показват максималния брой сесии на бекенд сървър и кога се появиха проблеми със свързаността. Това може да бъде доста полезно за целите на отстраняване на грешки, когато срещнете грешка в конфигурацията на вашия HAProxy екземпляр и връзките започват да прекъсват.
Тази следващата графика е потенциално по-ценна, тъй като показва различни показатели, свързани с грешка обработка, като грешки, грешки при заявки, повторни опити от задната страна и т.н. Има и графика „Сесии“, показваща общ преглед на показателите за сесиите.
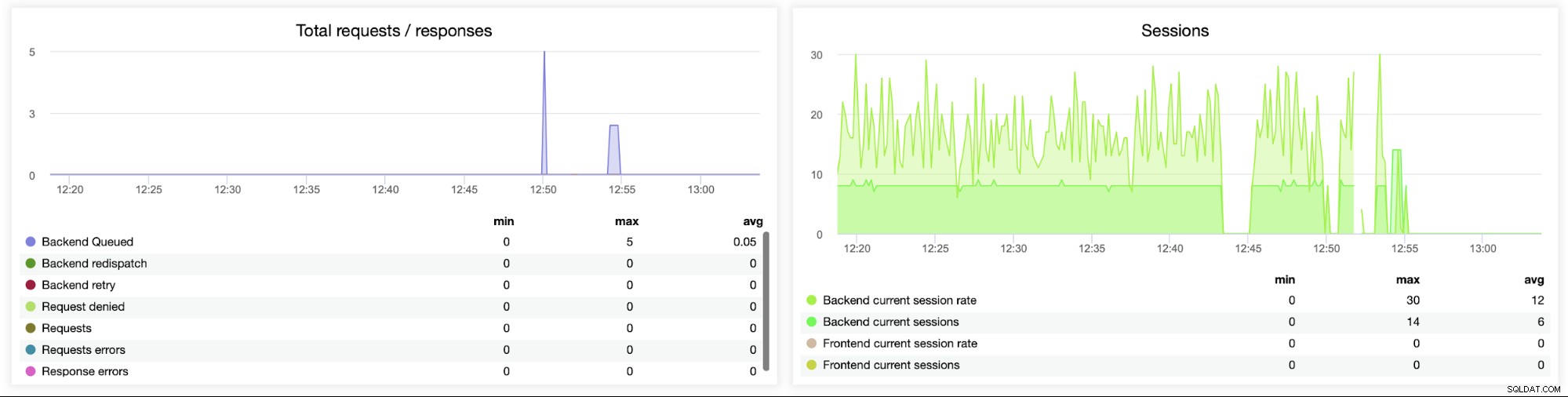
Тук можете да видите, че ClusterControl проследява грешките при връзката в реално време, което може да помогне да се определи точното време, когато проблемите са започнали да се развиват.
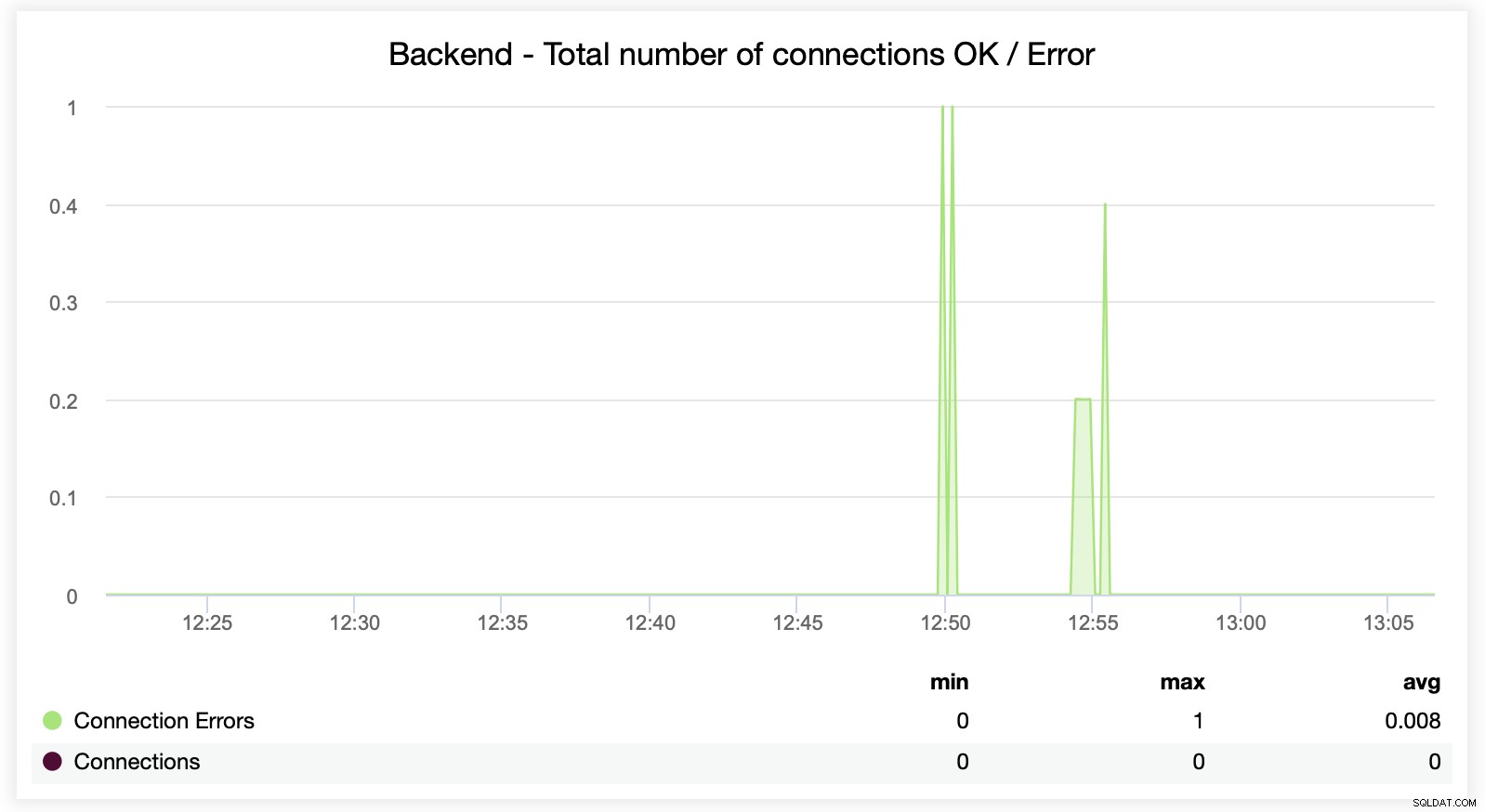
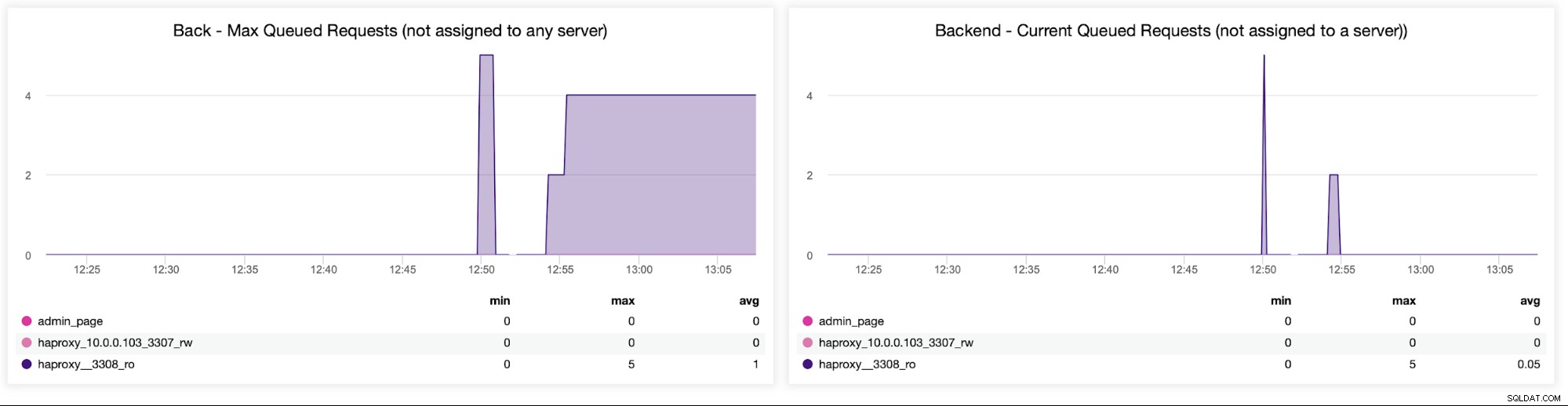
Накрая ще разгледаме следните две графики, свързани със заявки на опашка . HAProxy поставя на опашка заявки към бекенда, ако бекенд сървърите са пренаситени. Това може да сочи например към претоварените сървъри на база данни, които не могат да обработват повече трафик.
Приключване
Разгръщането и наблюдението на вашия HAProxy балансьор на натоварване в ClusterControl може да помогне за лесна работа по управлението и наблюдението на вашите връзки. Наличието на ясна видимост върху производителността на вашите бекендове, разпределението на трафика, показателите на сесиите, грешките при свързване и броя на заявките в опашката може да помогне да се гарантира наличността и мащабируемостта на всяка настройка на базата данни.
ClusterControl прави настройката и наблюдението на балансиращите устройства лесна за всяка конфигурация на база данни. Все още не използвате ClusterControl? Ако искате сами да се уверите колко лесно е да разгръщате и наблюдавате вашия HAProxy балансьор на натоварване с ClusterControl, ние ви каним на безплатна 30-дневна пробна версия на платформата, без никакви ограничения. За по-подробно описание защо и как да използвате HAProxy за балансиране на натоварването, вижте нашия урок за MySQL Load Balancing с HAProxy.



