Четенето от памет винаги ще бъде по-ефективно, отколкото преминаването на диск, така че за всички технологии за бази данни бихте искали да използвате възможно най-много памет. Ако не сте сигурни за конфигурацията или имате грешка, това може да доведе до високо използване на паметта или дори проблем с липсата на памет.
В този блог ще разгледаме как да проверим използването на вашата PostgreSQL памет и кой параметър трябва да вземете предвид, за да го настроите. За това нека започнем с преглед на архитектурата на PostgreSQL.
Архитектура на PostgreSQL
Архитектурата на PostgreSQL се основава на три основни части:процеси, памет и диск.
Паметта може да бъде класифицирана в две категории:
- Локална памет :Зарежда се от всеки бекенд процес за собствена употреба за обработка на заявки. Разделен е на подзони:
- Работна памет:Работната памет се използва за сортиране на кортежи по операции ORDER BY и DISTINCT и за свързване на таблици.
- Работна памет за поддръжка:Някои видове операции по поддръжка използват тази област. Например, VACUUM, ако не сте посочили autovacuum_work_mem.
- Временни буфери:Използва се за съхраняване на временни таблици.
- Споделена памет :Разпределя се от PostgreSQL сървъра при стартиране и се използва от всички процеси. Разделен е на подзони:
- Споделен буферен пул:Където PostgreSQL зарежда страници с таблици и индекси от диск, за да работи директно от паметта, намалявайки достъпа до диска.
- WAL буфер:WAL данните са регистърът на транзакциите в PostgreSQL и съдържат промените в базата данни. Буферът на WAL е областта, където WAL данните се съхраняват временно, преди да бъдат записани на диск в WAL файловете. Това се прави на всеки предварително определено време, наречено контролна точка. Това е много важно, за да избегнете загубата на информация в случай на повреда на сървъра.
- Регистър на записите:Записва състоянието на всички транзакции за контрол на едновременност.
Как да разберем какво се случва
Ако имате висока степен на използване на паметта, първо трябва да потвърдите кой процес генерира консумацията.
Използване на командата „Top“ Linux
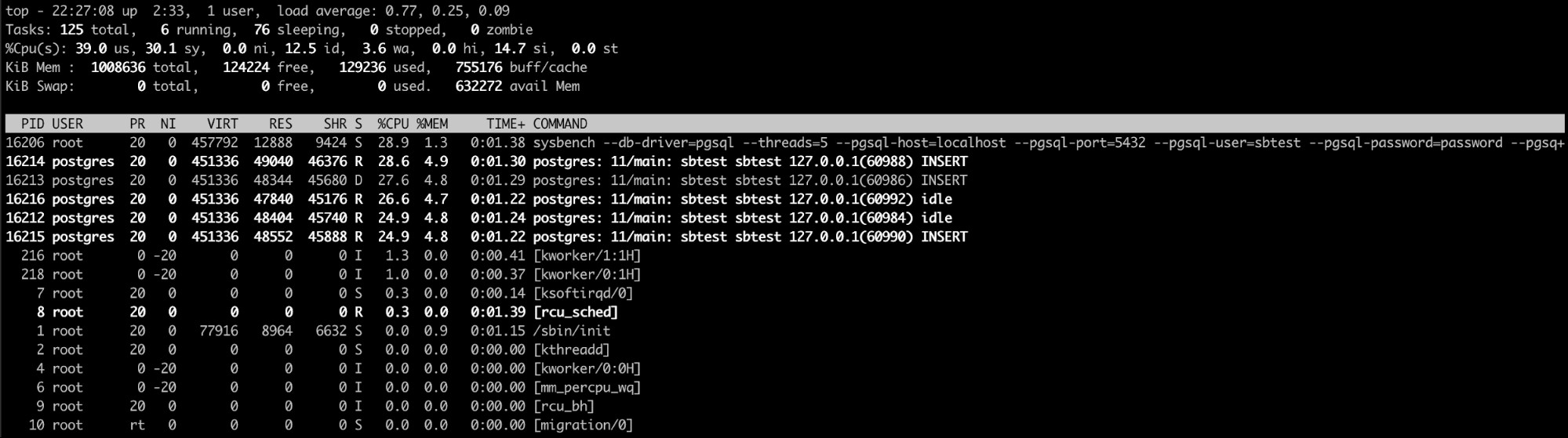
Горната команда на linux е може би най-добрият вариант тук (или дори подобен един като htop). С тази команда можете да видите процесите/процесите, които консумират твърде много памет.
Когато потвърдите, че PostgreSQL е отговорен за този проблем, следващата стъпка е да проверите защо.
Използване на регистрационния файл на PostgreSQL
Проверката както на PostgreSQL, така и на системните регистрационни файлове определено е добър начин да имате повече информация за това какво се случва във вашата база данни/система. Можете да видите съобщения като:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childАко нямате достатъчно свободна памет.
Или дори множество грешки в съобщенията в базата данни като:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedКогато имате някакво неочаквано поведение от страна на базата данни. Така че регистрационните файлове са полезни за откриване на тези видове проблеми и дори повече. Можете да автоматизирате този мониторинг, като анализирате регистрационните файлове, търсещи работи като „FATAL“, „ERROR“ или „Kill“, така че ще получите предупреждение, когато това се случи.
Използване на Pg_top
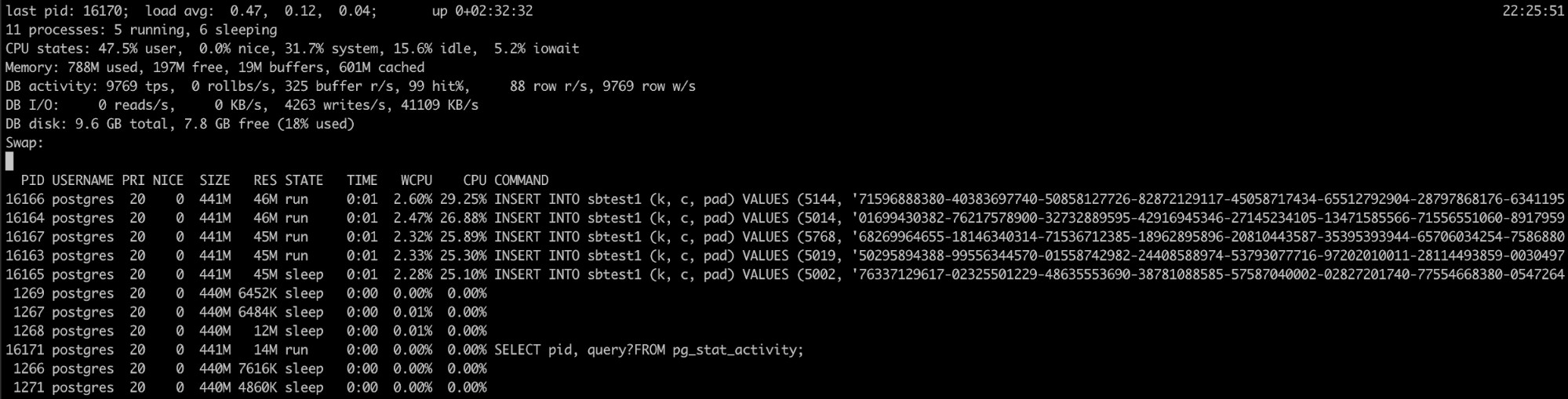
Ако знаете, че процесът PostgreSQL има високо използване на паметта, но регистрационните файлове не помогнаха, имате друг инструмент, който може да бъде полезен тук, pg_top.
Този инструмент е подобен на най-добрия инструмент за Linux, но е специално за PostgreSQL. Така че, като го използвате, ще имате по-подробна информация за това какво работи с вашата база данни и дори можете да убиете заявки или да стартирате задача за обяснение, ако откриете нещо нередно. Можете да намерите повече информация за този инструмент тук.
Но какво се случва, ако не можете да откриете грешка и базата данни все още използва много RAM. Така че вероятно ще трябва да проверите конфигурацията на базата данни.
Кои конфигурационни параметри да се вземат предвид
Ако всичко изглежда наред, но все още имате проблем с високото използване, трябва да проверите конфигурацията, за да потвърдите дали е правилна. И така, по-долу са параметрите, които трябва да вземете предвид в този случай.
споделени_буфери
Това е количеството памет, което сървърът на базата данни използва за споделени буфери на паметта. Ако тази стойност е твърде ниска, базата данни ще използва повече диск, което би причинило повече забавяне, но ако е твърде висока, може да генерира високо използване на паметта. Според документацията, ако имате специален сървър на база данни с 1 GB или повече RAM, разумна начална стойност за shared_buffers е 25% от паметта във вашата система.
work_mem
Той указва количеството памет, което ще се използва от ORDER BY, DISTINCT и JOIN преди да запише във временните файлове на диска. Както при shared_buffers, ако конфигурираме този параметър твърде нисък, можем да имаме повече операции, влизащи в диска, но твърде високото е опасно за използването на паметта. Стойността по подразбиране е 4 MB.
max_connections
Work_mem също върви ръка за ръка със стойността max_connections, тъй като всяка връзка ще изпълнява тези операции по едно и също време и всяка операция ще има право да използва толкова памет, колкото е посочено от тази стойност преди нея започва да записва данни във временни файлове. Този параметър определя максималния брой едновременни връзки към нашата база данни, ако конфигурираме голям брой връзки и не вземем това под внимание, можете да започнете да имате проблеми с ресурсите. Стойността по подразбиране е 100.
temp_buffers
Временните буфери се използват за съхраняване на временните таблици, използвани във всяка сесия. Този параметър задава максималното количество памет за тази задача. Стойността по подразбиране е 8 MB.
maintenance_work_mem
Това е максималната памет, която може да заеме операция като вакуумиране, добавяне на индекси или външни ключове. Хубавото е, че само една операция от този тип може да се изпълнява в една сесия и не е най-често срещаното нещо да се изпълняват няколко от тях едновременно в системата. Стойността по подразбиране е 64 MB.
autovacuum_work_mem
Вакуумът използва по подразбиране support_work_mem, но можем да го разделим с помощта на този параметър. Тук можем да посочим максималния обем памет, която да се използва от всеки работещ за автоматично прахосмукачка.
wal_buffers
Обемът споделена памет, използвана за WAL данни, които все още не са записани на диска. Настройката по подразбиране е 3% от shared_buffers, но не по-малко от 64kB, нито повече от размера на един WAL сегмент, обикновено 16MB.
Заключение
Има различни причини за високо използване на паметта и откриването на основния проблем може да е отнемаща време задача. В този блог споменахме различни начини да проверите използването на вашата PostgreSQL памет и кой параметър трябва да вземете предвид, за да го настроите, за да избегнете прекомерно използване на паметта.