Общ преглед на индекса на SQL сървър
Когато говорим за настройка на производителността на SQL Server и подобряване на заявките, първото нещо, което трябва да вземете предвид, е индексът на SQL Server. Той служи за ускоряване на четенето на данни от основните таблици, като осигурява бърз достъп до заявените редове. По този начин няма да е необходимо да сканира всички записи на таблицата.
Индексът на SQL Server предоставя тези възможности за бързо търсене поради структурата на B-дървото на индекса. Тази структура дава възможност за бързо придвижване през редовете на таблицата въз основа на индексния ключ и извличане на исканите записи наведнъж. Няма нужда да чете цялата таблица.
Типове индекси на SQL Server
Сред основните типове обръщаме внимание на клъстерираните и неклъстерирани индекси.
Клъстерният индекс сортира действителните данни в страниците с данни според стойностите на клъстерирания индекс. Той съхранява данните на ниво „лист“ на индекса, като гарантира възможността за създаване само на един клъстериран индекс за всяка таблица. Клъстерираният индекс се създава автоматично, когато ограничение за първичен ключ се появи в таблицата на heap.
Неклъстерираният индекс съдържа стойността на ключа на индекса и указател към останалите колони на редовете в основната таблица. Това е „листовото“ ниво на индекса, с възможност за създаване на до 999 неклъстерирани индекса за всяка таблица.
Ако вашата таблица няма клъстериран индекс, създаден в нея, таблицата се нарича „Heap table“. Такава таблица няма критерии за определяне на реда на данните вътре в страниците и сортирането и свързването на страниците заедно.
Когато в тази таблица се създаде клъстериран индекс, ние наричаме сортираната таблица клъстерирана таблица.
Съществуват и други типове индекси, предоставени от SQL Server:
- Уникалният индекс налага уникалността на стойностите на колоните;
- Покриващият индекс съдържа всички колони, поискани от заявката;
- Съставният индекс съдържа множество колони в ключа на индекса;
- Други конкретни типове индекси са XML, Spatial и Columnstore индекси.
Предимството на индекса на SQL Server е, че подобрява производителността на заявките. Въпреки това работи, ако само индексът е правилен. Ако го проектирате погрешно, това ще повлияе негативно на производителността на заявките и ще изразходва ресурсите на SQL Server за съхраняване и поддържане на безполезни индекси.
Изборът на най-добрия индекс, който коригира всички проблеми, не е лесна задача. Добавянето на нов индекс може да ускори процеса на извличане на данни, но забавя процесите на промяна на данните. Всяка промяна, извършена в основната таблица getы, се отразява директно във всички свързани индекси, за да поддържа данните последователни.
Ето защо трябва да проучите и тествате въздействието на новия индекс, преди да го създадете в производствената среда. Също така е необходимо да се следи неговото въздействие и употреба след внедряването му в производствената среда.
Фактори, които трябва да се вземат предвид при проектирането на нов индекс на SQL Server
Първият фактор е типът на натоварване на базата данни . Да предположим, че имаме работа с OLTP натоварване с голям брой операции за запис. Той изисква възможно най-малък брой индекси. Друг случай е OLAP работно натоварване с много операции за четене – това ще изисква възможно най-много индекси, за да се ускори извличането на данни.
Също така, трябва да разгледате размера на таблицата . SQL Server Engine предпочита да сканира директно основната таблица, вместо да губи време и ресурси за избор на най-добрия индекс за извличане на данни от тази малка таблица.
След като решите да създадете индекс в тази таблица, трябва да идентифицирате типа индекс, който да обслужва вашата заявка . Там посочвате колоните, добавени към индексния ключ. Базите са типът данни на колоната и позицията в предикатите на заявката и условията за присъединяване.
Тези фактори трябва да гарантират най-доброто извличане на данни, в правилния ред и да поддържат индекса възможно най-кратък и опростен.
Друг фактор, който трябва да се вземе предвид при проектирането на нов индекс, е съхранението на индекса . Препоръчително е да създавате неклъстерирани индекси на отделна файлова група и дисково устройство. По този начин изолирате I/O операциите, извършени в индексните страници с данни от файловете с данни на базата данни.
Помислете за задаване на индекса FILLFACTOR , който определя процента пространство на всяка страница на ниво лист, пълна с данни (стойността се различава от 0 или 100 процента по подразбиране). Целта е да се остави място във всяка страница с данни на индекса за нововмъкнатите или актуализирани записи. Освен това намалява до минимум случаите на разделяне на страници, което може да доведе до проблема с фрагментирането на индекса.
Управление на индекси
Ролята на администратора на базата данни за подобряване на производителността на заявките с индекси на SQL Server не се ограничава до създаването на индекса. Трябва проактивно да наблюдавате използването на индекса, за да идентифицирате неговото качество. Освен това трябва да поддържаме индекса редовно, за да коригираме проблемите с фрагментацията.
SQL Server Management Studio, със своята стабилна функционалност за отчитане, предоставя най-полезните статистически данни на администраторите на базата данни. Един от тези вградени отчети е Статистика за използване на индекса :
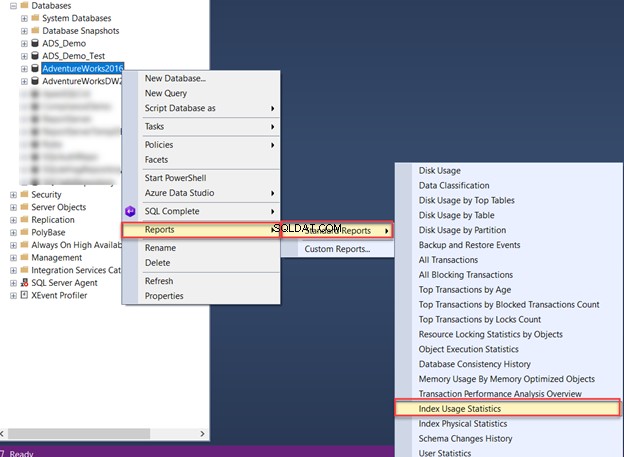
Докладът за статистика за използване на индекси описва как се използват индексите на базата данни под формата на:
- Търси :колко пъти индексът се използва от SQL Engine за намиране на конкретен ред.
- Сканира :колко пъти страниците на индекса са сканирани от SQL Engine.
- Търси :броят пъти, когато неклъстериран индекс е бил използван като клъстериран индекс за извличане на останалите колони, които не са изброени в неклъстерирания индекс.
- Актуализации :броят пъти, когато индексните данни се променят.
Обърнете внимание, че основната цел на създаването на индекс е да се извърши операция за търсене на индекс, както е показано по-долу:
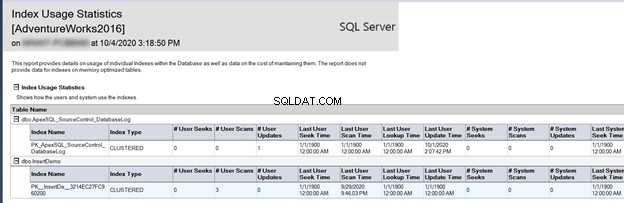
Предишният доклад помага значително при уточняването дали SQL Server се възползва от тези индекси, за да ускори процеса на извличане на данни или не. Ако се окаже, че някой конкретен индекс не работи както трябва, изхвърлете го и го заменете с по-добър.
Вторият отчет, предоставен от SSMS, е Индексна физическа статистика . Той връща статистическата информация за процента на фрагментация на индекса за всеки индексен дял, с броя на страниците на всеки индексен дял.
Той също така препоръчва как да коригирате проблемите с фрагментирането на индекса чрез повторно изграждане или реорганизиране на този индекс според процента на фрагментация, както е показано по-долу:
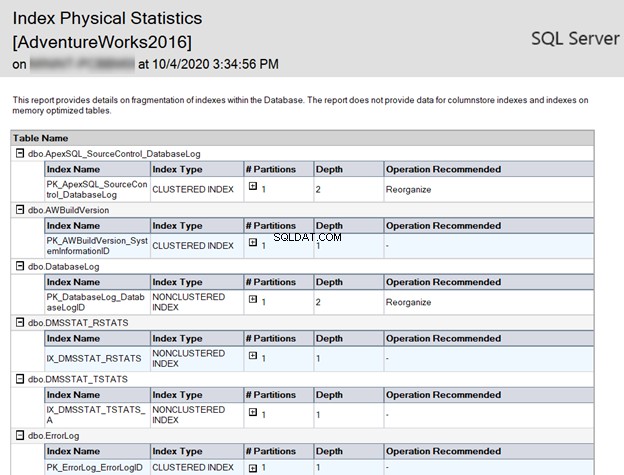
За да приложите препоръките, предоставени от отчета, можете да изпълните командата за дефрагментиране на индекса за всеки индекс. Или можете да създадете план за поддръжка с помощта на SSMS, за да поддържате индекса по най-добрия начин.
dbForge Index Manager
dbForge Index Manager е добавка за SSMS, която служи за откриване и коригиране на проблеми с фрагментацията на индексите на SQL Server.
Той също така е централизиран инструмент, осигуряващ възможност за откриване на процента на фрагментация на индекса в базите данни. Можете да коригирате тези проблеми, като извършите възстановяване на индекс. Друг начин е да се реорганизират операциите въз основа на сериозността на фрагментацията на този индекс. Наред с други опции, има генериране на T-SQL скриптове за изпълнение на свързани с индекса команди, експортиране на резултатите от анализа на индекса за по-късна справка и използване на интерфейса на командния ред за автоматизиране на задачите за поддръжка на индекса.
dbForge Index Manager е достъпен на страницата за изтегляне на Devart. Можете да го инсталирате на вашето устройство с помощта на лесен съветник за инсталиране. След успешната инсталация тази добавка е готова за използване.
За да го използвате в рамките на SSMS, щракнете с десния бутон върху базата данни и изберете Manage Index Fragmentation от списъка на Index Manager:
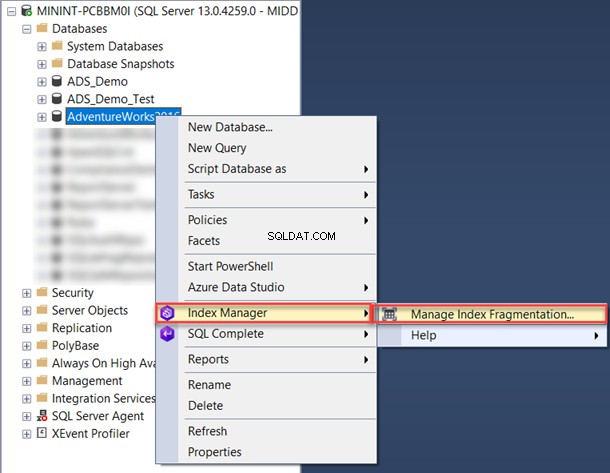
От прозореца Index Manager можете да филтрирате името на базата данни, което ви интересува.
Кликнете върху Повторно анализиране за да извършите проверката за фрагментация на индекса за избраната база данни. Той автоматично показва статистиката за фрагментация на индекси за всички индекси, създадени под избраната база данни по време на този процес.
Инструментът Index Manager също препоръчва действията за отстраняване на проблемите с фрагментацията на индекса въз основа на процента на фрагментация:
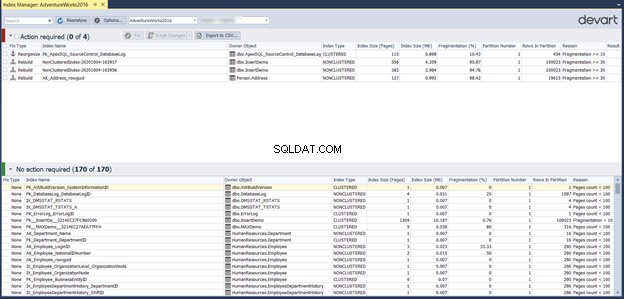
Проверката на индекси в раздела Необходими действия в предишния прозорец прави възможно експортирането на списъка с действия като CSV отчет. Позволява ви да изпълните предложената корекция чрез реорганизиране или възстановяване на проблемни индекси директно от тази страница или генериране на скрипт, за да го направите по-късно:
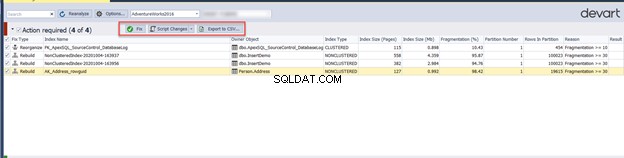
Корекцията на фрагментацията на индекса в нашия сценарий ще бъде както следва:
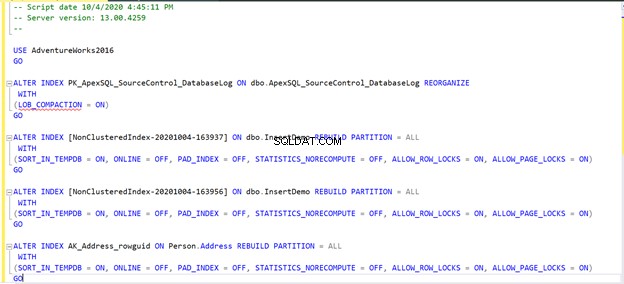
Ако стартирате предишния скрипт или кликнете върху Fix опция и след това Повторно анализиране В резултат виждате, че проблемът с фрагментацията е отстранен директно:
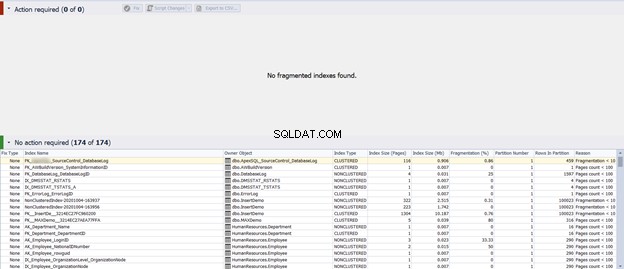
По този начин ние се възползваме от dbForge Index Manager, за да анализираме и идентифицираме проблемите с фрагментацията на индекса и след това да ги докладваме или коригираме директно от същото място.
Полезен инструмент
dbForge Index Manager внася интелигентно фиксиране на индекси и фрагментиране на индекса направо в SSMS. Инструментът ви позволява бързо да събирате статистически данни за фрагментацията на индекса и да откривате бази данни, които изискват поддръжка. Можете незабавно да възстановите и реорганизирате индексите на SQL Server във визуален режим или да генерирате SQL скриптове за бъдеща употреба. dbForge Index Manager за SQL Server значително ще повиши производителността ви без много усилия.