В който и да е от двигателите на релационни бази данни се изисква да се генерира възможно най-добрият план, който съответства на изпълнението на заявката с най-малко време и ресурси. Като цяло всички бази данни генерират планове във формат на дървовидна структура, където листовият възел на всяко планово дърво се нарича възел за сканиране на таблица. Този конкретен възел на плана съответства на алгоритъма, който трябва да се използва за извличане на данни от основната таблица.
Например, разгледайте прост пример за заявка като SELECT * FROM TBL1, TBL2, където TBL2.ID>1000; и да предположим, че генерираният план е както следва:
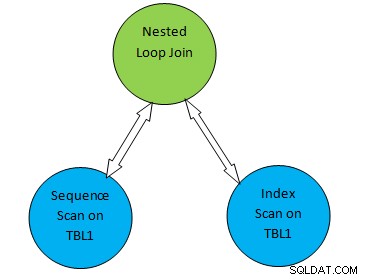
Така че в горното дърво на плана, „Последователно сканиране на TBL1“ и „ Индексно сканиране на TBL2” съответства на метода за сканиране на таблицата съответно на таблица TBL1 и TBL2. Така че съгласно този план, TBL1 ще бъде извлечен последователно от съответните страници и TBL2 може да бъде достъпен чрез INDEX Scan.
Изборът на правилния метод за сканиране като част от плана е много важен по отношение на цялостната ефективност на заявката.
Преди да се запознаем с всички видове методи за сканиране, поддържани от PostgreSQL, нека преразгледаме някои от основните ключови точки, които ще се използват често, докато разглеждаме блога.
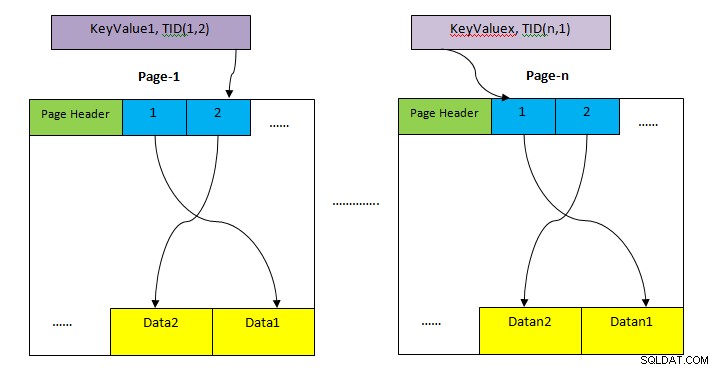
- КУЧИНА: Зона за съхранение на целия ред на масата. Това е разделено на множество страници (както е показано на горната снимка) и размерът на всяка страница по подразбиране е 8 КБ. Във всяка страница всеки указател на елемент (напр. 1, 2, ....) сочи към данни в страницата.
- Съхранение на индекси: Това хранилище съхранява само ключови стойности, т.е. стойности на колони, съдържащи се в индекса. Това също е разделено на множество страници и размерът на всяка страница по подразбиране е 8 КБ.
- Идентификатор на кортежи (TID): TID е число от 6 байта, което се състои от две части. Първата част е 4-байтов номер на страница и останалите 2 байта индекс на кортежа вътре в страницата. Комбинацията от тези две числа уникално сочи към мястото за съхранение на конкретен кортеж.
Понастоящем PostgreSQL поддържа по-долу методи за сканиране, чрез които всички необходими данни могат да бъдат прочетени от таблицата:
- Последователно сканиране
- Индексно сканиране
- Сканиране само с индекс
- Сканиране на растерно изображение
- TID сканиране
Всеки от тези методи за сканиране е еднакво полезен в зависимост от заявката и други параметри, напр. кардиналност на таблицата, селективност на таблицата, цена на дисков вход/изход, цена на произволен вход/изход, цена на последователност на вход/изход и т.н. Нека създадем някаква таблица за предварително настройка и да попълним някои данни, които ще се използват често, за да обясним по-добре тези методи за сканиране .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEТака че в този пример се вмъкват един милион записа и след това таблицата се анализира, така че всички статистически данни да са актуални.
Последователно сканиране
Както подсказва името, последователното сканиране на таблица се извършва чрез последователно сканиране на всички указатели на елементи от всички страници на съответните таблици. Така че, ако има 100 страници за определена таблица и след това има 1000 записа на всяка страница, като част от последователното сканиране той ще извлече 100*1000 записа и ще провери дали съвпада според нивото на изолация, а също и според предикатната клауза. Така че дори ако е избран само 1 запис като част от цялото сканиране на таблицата, той ще трябва да сканира 100K записа, за да намери квалифициран запис според условието.
Съгласно горната таблица и данни, следната заявка ще доведе до последователно сканиране, тъй като по-голямата част от данните се избират.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)ЗАБЕЛЕЖКА
Въпреки че без да се изчисляват и сравняват разходите на плана, е почти невъзможно да се каже кой вид сканиране ще се използва. Но за да може последователното сканиране да се използва поне по-долу критериите трябва да съвпадат:
- Няма наличен индекс за ключа, който е част от предиката.
- Повечето редове се извличат като част от SQL заявката.
СЪВЕТИ
В случай, че само много малко % от редовете се извличат и предикатът е в една (или повече) колона, тогава опитайте да оцените производителността със или без индекс.
Индексно сканиране
За разлика от последователното сканиране, индексното сканиране не извлича всички записи последователно. По-скоро използва различна структура на данните (в зависимост от типа индекс), съответстваща на индекса, участващ в заявката, и клауза за намиране на необходимите данни (по предикат) с много минимални сканирания. След това записът, намерен с помощта на сканирането на индекса, сочи директно към данни в областта на купчина (както е показано на горната фигура), които след това се извличат, за да се провери видимостта според нивото на изолация. Така че има две стъпки за индексно сканиране:
- Извличане на данни от свързана с индекс структура от данни. Връща TID на съответните данни в heap.
- След това се осъществява директен достъп до съответната страница на купчина, за да се получат цели данни. Тази допълнителна стъпка е необходима поради следните причини:
- Заявката може да е поискала извличане на колони повече от всичко, което е налично в съответния индекс.
- Информацията за видимостта не се поддържа заедно с индексните данни. Така че, за да провери видимостта на данните според нивото на изолация, той трябва да получи достъп до данни от купчина.
Сега може да се чудим защо не винаги използваме индексно сканиране, ако е толкова ефективно. Така че, както знаем, всичко идва с известна цена. Тук разходите са свързани с типа I/O, който правим. В случай на индексно сканиране участва произволен I/O, тъй като за всеки запис, намерен в индексното хранилище, той трябва да извлече съответните данни от HEAP съхранение, докато в случай на последователно сканиране се включва последователен I/O, което отнема приблизително само 25% на произволно I/O синхронизиране.
Така че индексното сканиране трябва да се избира само ако общата печалба превишава режийните разходи, възникнали поради разходите за произволен I/O.
Съгласно горната таблица и данни, следната заявка ще доведе до сканиране на индекс, тъй като се избира само един запис. Така произволното I/O е по-малко, както и търсенето на съответния запис е бързо.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Сканиране само в индекс
Сканирането само с индекс е подобно на индексното сканиране с изключение на втората стъпка, т.е. както подсказва името, сканира само структурата на индексните данни. Има две допълнителни предварителни условия, за да изберете само индексно сканиране в сравнение с индексно сканиране:
- Заявката трябва да извлича само ключови колони, които са част от индекса.
- Всички кортежи (записи) на избраната страница на купчина трябва да се виждат. Както беше обсъдено в предишния раздел, структурата на индексните данни не поддържа информация за видимост, така че, за да изберем данни само от индекса, трябва да избягваме проверката за видимост и това може да се случи, ако всички данни на тази страница се считат за видими.
Следната заявка ще доведе до сканиране само на индекс. Въпреки че тази заявка е почти подобна по отношение на избора на брой записи, но тъй като се избира само ключово поле (т.е. „num“), тя ще избере сканиране само с индекс.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Сканиране на растерно изображение
Сканирането на растерна карта е комбинация от индексно сканиране и последователно сканиране. Той се опитва да реши недостатъка на индексното сканиране, но все пак запазва пълното си предимство. Както беше обсъдено по-горе, за всяка информация, намерена в структурата на индексните данни, тя трябва да намери съответни данни в хеп страница. Така че алтернативно той трябва да извлече индексна страница веднъж и след това да бъде последвана от страница на купчина, което причинява много произволни I/O. Така методът за сканиране на растерни изображения използва предимствата на индексното сканиране без произволен I/O. Това работи на две нива, както следва:
- Сканиране на индекс на растерна карта:Първо извлича всички индексни данни от структурата на индексните данни и създава битова карта на всички TID. За по-лесно разбиране можете да помислите, че тази растерна карта съдържа хеш на всички страници (хеширани въз основа на номер на страница) и всеки запис на страница съдържа масив от всички измествания в тази страница.
- Сканиране на растерна карта:Както подсказва името, то чете растерно изображение на страници и след това сканира данни от купчина, съответстващи на съхранената страница и отместване. В края той проверява за видимост и предикат и т.н. и връща кортежа въз основа на резултата от всички тези проверки.
По-долу заявката ще доведе до растерно сканиране, тъй като не избира много малко записи (т.е. твърде много за сканиране на индекс) и в същото време не избира огромен брой записи (т.е. твърде малко за последователно сканиране).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Сега разгледайте заявката по-долу, която избира същия брой записи, но само ключови полета (т.е. само индексни колони). Тъй като избира само ключ, не е необходимо да препраща страниците на купчина за други части от данни и следователно няма включен произволен I/O. Така че тази заявка ще избере сканиране само с индекс вместо сканиране на растерни изображения.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TID сканиране
TID, както бе споменато по-горе, е номер от 6 байта, който се състои от 4-байтов номер на страница и останалите 2 байта индекс на кортежа вътре в страницата. TID сканирането е много специфичен вид сканиране в PostgreSQL и се избира само ако има TID в предиката на заявката. Помислете за по-долу заявка, демонстрираща TID сканирането:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Така че тук в предиката, вместо да се дава точна стойност на колоната като условие, се предоставя TID. Това е нещо подобно на търсене, базирано на ROWID в Oracle.
Бонус
Всички методи за сканиране са широко използвани и известни. Освен това тези методи за сканиране са налични в почти всички релационни бази данни. Но има друг метод за сканиране, който наскоро се обсъжда в общността на PostgreSQL, както и наскоро добавен в други релационни бази данни. Нарича се „Loose IndexScan“ в MySQL, „Index Skip Scan“ в Oracle и „Jump Scan“ в DB2.
Този метод на сканиране се използва за специфичен сценарий, при който е избрана различна стойност на водещата ключова колона на индекса на B-Tree. Като част от това сканиране, той избягва преминаването на всички равни стойности на ключови колони, а просто преминава през първата уникална стойност и след това преминава към следващата голяма.
Тази работа все още е в ход в PostgreSQL с условното име „Index Skip Scan” и може да очакваме да видим това в бъдеща версия.



