С Disaster Recovery се стремим да настроим системи за справяне с всичко, което може да се обърка с нашата база данни. Какво се случва, ако базата данни се срине? Ами ако разработчик случайно съкрати таблица? Ами ако разберем, че някои данни са били изтрити миналата седмица, но не сме ги забелязали до днес? Тези неща се случват и наличието на солиден план и система ще направи DBA да изглежда като герой, когато сърцата на всички останали вече са спрели, когато бедствие издигне грозната си глава.
Всяка база данни, която има някаква стойност, трябва да има начин за прилагане на една или повече опции за възстановяване след бедствие. PostgreSQL има вградена много солидна система за репликация и е достатъчно гъвкава, за да бъде настроена в много конфигурации, за да помогне с Disaster Recovery, ако нещо се обърка. Ще се съсредоточим върху сценарии като въпросните по-горе, как да настроим нашите опции за възстановяване след бедствие и предимствата на всяко решение.
Висока наличност
С поточно репликацията в PostgreSQL, високата наличност е лесна за настройка и поддръжка. Целта е да се осигури сайт за преодоляване на срив, който може да бъде промотиран за овладяване, ако основната база данни се повреди по някаква причина, като хардуерна повреда, софтуерна повреда или дори прекъсване на мрежата. Хостването на реплика на друг хост е страхотно, но хостването й в друг център за данни е още по-добре.
За подробности относно настройката на стрийминг репликация, Severalnines има подробно дълбоко гмуркане, достъпно тук. Официалната документация за поточно репликация на PostgreSQL съдържа подробна информация за протокола за поточно репликация и как работи всичко.
Стандартната настройка ще изглежда така, главна база данни, приемаща връзки за четене/запис, с база данни с копия, която получава цялата WAL активност в почти реално време, като възпроизвежда цялата активност за промяна на данни локално.
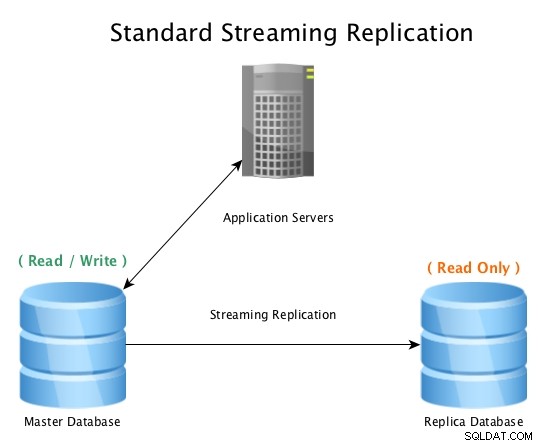 Стандартна поточно репликация с PostgreSQL
Стандартна поточно репликация с PostgreSQL Когато главната база данни стане неизползваема, се инициира процедура за преодоляване на срив, за да се изведе в офлайн режим и да се повиши базата данни реплика до главна, след което насочва всички връзки към новопромотирания хост. Това може да стане чрез преконфигуриране на балансьор на натоварване, конфигурация на приложението, IP псевдоними или други умни начини за пренасочване на трафика.
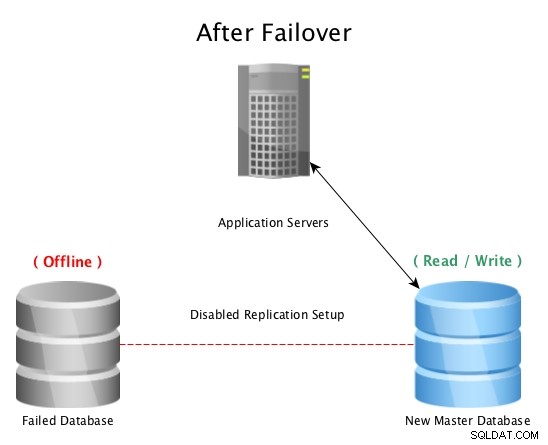 След отказ с PostgreSQL поточно репликация
След отказ с PostgreSQL поточно репликация Когато бедствие удари главна база данни (като отказ на твърдия диск, прекъсване на захранването или нещо, което пречи на главния да работи по предназначение), преминаването към горещ режим на готовност е най-бързият начин да останете онлайн, обслужвайки заявки към приложения или клиенти без сериозни престой. След това започва състезанието или за коригиране на неуспешния хост на базата данни, или за въвеждане на нова реплика онлайн, за да се поддържа мрежата за безопасност от готовност за работа. Наличието на множество режими на готовност ще гарантира, че прозорецът след катастрофална повреда също е готов за вторична повреда, колкото и малко вероятно да изглежда.
Забележка:Когато се прехвърли към реплика за поточно предаване, тя ще продължи там, където е спрял предишният главен код, така че това помага за поддържането на базата данни онлайн, но не и за възстановяване на случайно загубени данни.
Възстановяване във времето
Друга опция за аварийно възстановяване е възстановяване на точка във времето (PITR). С PITR копие на базата данни може да бъде върнато по всяко време, което пожелаем, стига да имаме базов архив от преди това време и всички сегменти на WAL, необходими до този момент.
Опцията за възстановяване във времето не се въвежда толкова бързо онлайн, колкото Hot Standby, но основното предимство е възможността да възстанови моментна снимка на база данни преди голямо събитие, като изтрита таблица, вмъкване на лоши данни или дори необяснимо повреждане на данните . Всичко, което би унищожило данни по начин, при който бихме искали да получим копие преди това унищожаване, PITR спасява положението.
Point in Time Recovery работи чрез създаване на периодични снимки на базата данни, обикновено с помощта на програмата pg_basebackup и съхраняване на архивирани копия на всички WAL файлове, генерирани от главния
Настройка за възстановяване във времето
Настройката изисква няколко опции за конфигурация, зададени на главния, някои от които са добре да се използват със стойности по подразбиране в текущата най-нова версия, PostgreSQL 11. В този пример ще копираме 16MB файла директно на нашия отдалечен PITR хост с помощта на rsync и ги компресирате от другата страна с помощта на cron.
WAL архивиране
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'ЗАБЕЛЕЖКА: Настройката archive_command може да бъде много неща, като общата цел е да се изпратят всички архивирани WAL файлове на друг хост с цел безопасност. Ако загубим WAL файлове, PITR след изгубения WAL файл става невъзможен. Позволете на вашата креативност в програмирането да полудее, но се уверете, че е надеждна.
[По избор] Компресирайте архивираните WAL файлове:
Всяка настройка ще варира донякъде, но освен ако въпросната база данни не е много лека за актуализации на данни, натрупването на 16MB файлове ще запълни пространството на устройството доста бързо. Лесен скрипт за компресиране, настроен чрез cron, може да изглежда по-долу.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]ЗАБЕЛЕЖКА: По време на всеки метод за възстановяване, всички компресирани файлове ще трябва да бъдат декомпресирани по-късно. Някои администратори избират да компресират файлове само след като са на възраст X дни, запазвайки общото пространство ниско, но също така поддържайки по-новите WAL файлове готови за възстановяване без допълнителна работа. Изберете най-добрата опция за въпросните бази данни, за да увеличите максимално скоростта на възстановяване.
Базови архиви
Един от ключовите компоненти за архивиране на PITR е базовото архивиране и честотата на базовите архиви. Те могат да бъдат почасови, ежедневни, седмични, месечни, но се избира най-добрият вариант въз основа на нуждите за възстановяване, както и трафика на потока от данни от базата данни. Ако имаме седмични резервни копия всяка неделя и трябва да възстановим чак до събота следобед, тогава пренасяме онлайн резервното копие от предишната неделя с всички WAL файлове между това архивиране и събота следобед. Ако този процес на възстановяване отнема 10 часа за обработка, това вероятно е нежелателно твърде дълго, Ежедневните базови архиви ще намалят това време за възстановяване, тъй като базовото архивиране ще бъде от тази сутрин, но също така ще увеличат количеството работа на хоста за базовото архивиране себе си.
Ако едноседмично възстановяване на WAL файлове отнема само няколко минути, тъй като базата данни вижда нисък отток, тогава ежеседмичните архиви са добре. В крайна сметка ще има същите данни, но от ключово значение е колко бързо ще имате достъп до тях.
В нашия пример ще настроим седмично базово архивиране и тъй като използваме поточно репликация за висока наличност, както и за намаляване на натоварването на главния, ще създадем базовото архивиране извън базата данни с реплика.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zЗАБЕЛЕЖКА: Командата pg_basebackup предполага, че този хост е настроен за достъп без парола за потребителска „репликация“ на главния, което може да бъде направено или чрез „доверие“ в pg_hba за този PITR резервен хост, парола във файла .pgpass или други по-сигурни начини . Имайте предвид сигурността, когато настройвате резервни копия.
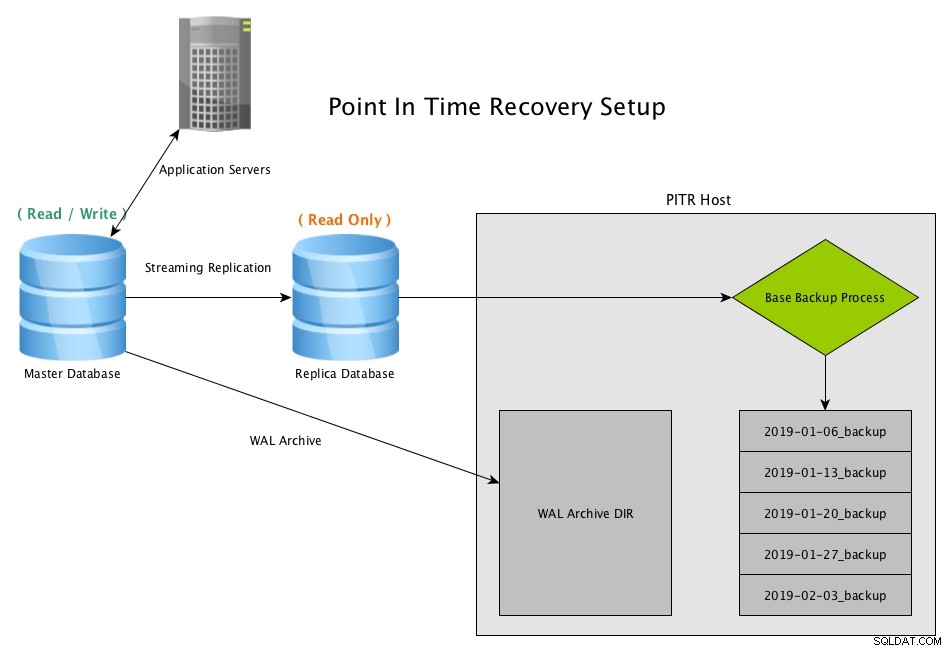 Възстановяване на точка във времето (PITR) от стрийминг реплика с PostgreSQLD Изтеглете Бялата книга днес PostgreSQL с Lester за управление и автоматизация какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книга
Възстановяване на точка във времето (PITR) от стрийминг реплика с PostgreSQLD Изтеглете Бялата книга днес PostgreSQL с Lester за управление и автоматизация какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книга Сценарий за възстановяване на PITR
Настройката на Point In Time Recovery е само част от работата, необходимостта от възстановяване на данни е другата част. Ако имате късмет, това може никога да не се случи, но е силно препоръчително периодично да правите възстановяване на архив на PITR, за да потвърдите, че системата работи, и да се уверите, че процесът е известен/скриптиран правилно.
В нашия тестов сценарий ще изберем момент от време за възстановяване и ще започнем процеса на възстановяване. Например:петък сутринта, разработчик насочва нова промяна на кода към производството, без да преминава през преглед на кода, и това унищожава куп важни данни за клиентите. Тъй като нашият Hot Standby е винаги в синхрон с главния, отказът към него няма да поправи нищо, тъй като това ще бъде едни и същи данни. PITR архивирането е това, което ще ни спаси.
Натискането на кода влезе в 11 часа сутринта, така че трябва да възстановим базата данни точно преди този час, 10:59 часа, ние решаваме, и за щастие правим ежедневни архиви, така че имаме резервно копие от полунощ тази сутрин. Тъй като не знаем какво всичко е унищожено, ние също решаваме да направим пълно възстановяване на тази база данни на нашия PITR хост и да я пуснем онлайн като главен, тъй като има същите хардуерни спецификации като главния, само в случай, че това случи се сценарий.
Изключване на главния
Тъй като решихме да възстановим напълно от резервно копие и да го повишим до master, няма нужда да поддържаме това онлайн. Затваряме го, но го съхраняваме, в случай че трябва да вземем нещо от него по-късно, за всеки случай.
Настройте базово архивиране за възстановяване
След това на нашия хост PITR извличаме най-новото си базово резервно копие от преди събитието, което е резервно „2018-12-21_backup“.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/С това базовото архивиране, както и WAL файловете, предоставени от pg_basebackup, са готови за работа, ако го пуснем онлайн сега, той ще се възстанови до точката, в която бе извършено архивирането, но ние искаме да възстановим всички WAL транзакции между полунощ и 11:59 ч., така че настроихме нашия файл recovery.conf.
Създайте recovery.conf
Тъй като това архивиране всъщност идва от стрийминг реплика, вероятно вече има файл recovery.conf с настройки за реплика. Ще го презапишем с нови настройки. Списък с подробна информация за всички различни опции е наличен в документацията на PostgreSQL тук.
Като внимавате с WAL файловете, командата за възстановяване ще копира компресираните файлове, от които се нуждае, в директорията за възстановяване, ще ги декомпресира и след това ще се премести там, където PostgreSQL се нуждае от тях за възстановяване. Оригиналните WAL файлове ще останат там, където са, в случай че са необходими по други причини.
Нов recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Стартирайте процеса на възстановяване
След като всичко е настроено, ще започнем процеса на възстановяване. Когато това се случи, добра идея е да следите регистъра на базата данни, за да се уверите, че се възстановява по предназначение.
Стартирайте DB:
pg_ctl -D /var/lib/pgsql/11/data startОгледайте дневниците:
Ще има много записи в дневника, показващи, че базата данни се възстановява от архивни файлове и в определен момент тя ще покаже ред, който казва „възстановяването спира преди извършване на транзакцията...“
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07В този момент процесът на възстановяване е погълнал всички WAL файлове, но също така се нуждае от преглед, преди да влезе онлайн като главен. В този пример дневникът отбелязва, че следващата транзакция след целевото време за възстановяване от 11:59:00 е била 11:59:01 и не е била възстановена. За да потвърдите, влезте в базата данни и разгледайте, работещата база данни трябва да е моментна снимка към 11:59 точно.
Когато всичко изглежда добре, време е да насърчите възстановяването като майстор.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Сега базата данни е онлайн, възстановена до точката, която решихме, и приема връзките за четене/запис като главен възел. Уверете се, че всички конфигурационни параметри са правилни и готови за производство.
Базата данни е онлайн, но процесът на възстановяване все още не е завършен! Сега, когато това архивиране на PITR е онлайн като главен, трябва да се настроят нов режим на готовност и настройка на PITR, дотогава този нов главен файл може да е онлайн и да обслужва приложения, но не е в безопасност от друго бедствие, докато всичко не бъде настроено отново.
Други сценарии за възстановяване във времето
Връщането на архив на PITR за цяла база данни е краен случай, но има и други сценарии, при които само подмножество данни липсват, са повредени или са лоши. В тези случаи можем да проявим креативност с нашите опции за възстановяване. Без да извеждаме главния офлайн и да го заменяме с резервно копие, можем да пренесем PITR архив онлайн до точното време, което искаме на друг хост (или друг порт, ако мястото не е проблем) и да експортираме възстановените данни от архива директно в главната база данни. Това може да се използва за възстановяване на шепа редове, шепа таблици или всякаква конфигурация на необходими данни.
С поточно репликация и Point In Time Recovery, PostgreSQL ни дава голяма гъвкавост, за да се уверим, че можем да възстановим всички данни, от които се нуждаем, стига да имаме резервни хостове, готови да работят като главен, или резервни копия, готови за възстановяване. Добрата опция за възстановяване след бедствие може да бъде допълнително разширена с други опции за архивиране, повече възли за копия, множество сайтове за архивиране в различни центрове за данни и континенти, периодични pg_dumps на друга реплика и т.н.
Тези опции могат да се сумират, но истинският въпрос е „колко ценни са данните и колко сте готови да похарчите, за да ги върнете?“. В много случаи загубата на данни е краят на бизнеса, така че трябва да има добри опции за възстановяване след бедствие, за да се предотврати случването на най-лошото.