Базите данни са проектирани по различни начини. През повечето време можем да използваме „училищни примери“:нормализирайте базата данни и всичко ще работи добре. Но има ситуации, които изискват друг подход. Можем да премахнем препратките, за да постигнем повече гъвкавост. Но какво ще стане, ако трябва да подобрим производителността, когато всичко е направено по книгата? В този случай денормализацията е техника, която трябва да разгледаме. В тази статия ще обсъдим ползите и недостатъците на денормализацията и какви ситуации могат да я наложат.
Какво е денормализация?
Денормализирането е стратегия, използвана в по-рано нормализирана база данни за повишаване на производителността. Идеята зад него е да добавим излишни данни там, където смятаме, че ще ни помогнат най-много. Можем да използваме допълнителни атрибути в съществуваща таблица, да добавяме нови таблици или дори да създаваме екземпляри на съществуващи таблици. Обичайната цел е да се намали времето за изпълнение на избраните заявки, като се направят данните по-достъпни за заявките или чрез генериране на обобщени отчети в отделни таблици. Този процес може да доведе до някои нови проблеми и ще ги обсъдим по-късно.
Нормализираната база данни е отправната точка за процеса на денормализация. Важно е да се разграничи базата данни, която не е нормализирана, и базата данни, която е била нормализирана първо и след това денормализирана по-късно. Второто е наред; първият често е резултат от лош дизайн на база данни или липса на знания.
Пример:нормализиран модел за много прост CRM
Моделът по-долу ще служи като наш пример:
Нека да разгледаме набързо таблиците:
user_accountтаблицата съхранява данни за потребители, които влизат в нашето приложение (опростяване на модела, ролите и потребителските права са изключени от нея).clientтаблицата съдържа някои основни данни за нашите клиенти.productтаблицата изброява продуктите, предлагани на нашите клиенти.taskтаблицата съдържа всички задачи, които сме създали. Можете да мислите за всяка задача като набор от свързани действия спрямо клиенти. Всяка задача има свързани разговори, срещи и списъци с предлагани и продавани продукти.callиmeetingтаблиците съхраняват данни за всички разговори и срещи и ги свързват със задачи и потребители.- Речниците
task_outcome,meeting_outcomeиcall_outcomeсъдържа всички възможни опции за крайното състояние на задача, среща или обаждане. product_offeredсъхранява списък с всички продукти, които са били предлагани на клиенти при определени задачи, докатоproduct_soldсъдържа списък на всички продукти, които клиентът действително е купил.supply_orderтаблицата съхранява данни за всички поръчки, които сме направили, иproducts_on_orderв таблицата са изброени продуктите и тяхното количество за конкретни поръчки.writeoffтаблицата е списък с продукти, които са били отписани поради злополуки или подобни (например счупени огледала).
Базата данни е опростена, но е идеално нормализирана. Няма да намерите никакви съкращения и трябва да свърши работата. В никакъв случай не трябва да изпитваме проблеми с производителността, стига да работим с относително малко количество данни.
Кога и защо да използваме денормализация
Както при почти всичко, трябва да сте сигурни защо искате да приложите денормализация. Трябва също така да сте сигурни, че печалбата от използването му надвишава всяка вреда. Има няколко ситуации, в които определено трябва да помислите за денормализация:
- Поддържане на история: Данните могат да се променят с течение на времето и трябва да съхраняваме стойности, които са били валидни при създаването на записа. Какъв вид промени имаме предвид? Е, името и фамилията на човек могат да се променят; клиент също може да промени името на фирмата си или други данни. Подробностите за задачата трябва да съдържат стойности, които са били действителни в момента на генериране на задача. Не бихме могли да пресъздадем правилно минали данни, ако това не се случи. Бихме могли да решим този проблем, като добавим таблица, съдържаща историята на тези промени. В този случай заявка за избор, връщаща задачата и валидно име на клиент, ще стане по-сложна. Може би допълнителната маса не е най-доброто решение.
- Подобряване на ефективността на заявката: Някои от заявките може да използват множество таблици за достъп до данни, от които често се нуждаем. Помислете за ситуация, в която ще трябва да обединим 10 таблици, за да върнем името на клиента и продуктите, които са му продадени. Някои таблици по пътя също могат да съдържат големи количества данни. В такъв случай може би би било разумно да добавите
client_idприписвайте директно наproducts_soldмаса. - Ускоряване на отчитането: Много често имаме нужда от определена статистика. Създаването им от живи данни отнема доста време и може да повлияе на цялостната производителност на системата. Да кажем, че искаме да проследяваме продажбите на клиенти през определени години за някои или всички клиенти. Генерирането на такива отчети от живи данни би „разровило“ почти цялата база данни и би я забавило много. И какво ще стане, ако използваме тази статистика често?
- Изчисляване на често необходими стойности предварително: Искаме да имаме готови изчислени стойности, за да не се налага да ги генерираме в реално време.
Важно е да се отбележи, че не е необходимо да използвате денормализация, ако няма проблеми с производителността в приложението. Но ако забележите, че системата се забавя – или ако сте наясно, че това може да се случи – тогава трябва да помислите за прилагането на тази техника. Преди да започнете обаче, помислете за други опции, като оптимизиране на заявки и правилно индексиране. Можете също да използвате денормализация, ако вече сте в производство, но е по-добре да решите проблемите във фазата на разработка.
Какви са недостатъците на денормализацията?
Очевидно най-голямото предимство на процеса на денормализация е повишената производителност. Но ние трябва да платим цена за това и тази цена може да се състои от:
- Пространство на диска: Това се очаква, тъй като ще имаме дублиращи се данни.
- Аномалии в данните: Трябва да сме много наясно с факта, че данните вече могат да се променят на повече от едно място. Трябва да коригираме съответно всяка част от дублираните данни. Това важи и за изчислените стойности и отчети. Можем да постигнем това, като използваме тригери, транзакции и/или процедури за всички операции, които трябва да бъдат завършени заедно.
- Документация: Трябва правилно да документираме всяко правило за денормализация, което сме приложили. Ако променим дизайна на базата данни по-късно, ще трябва да разгледаме всички наши изключения и да ги вземем под внимание още веднъж. Може би вече не ни трябват, защото сме решили проблема. Или може би трябва да добавим към съществуващите правила за денормализация. (Например:Добавихме нов атрибут към клиентската таблица и искаме да съхраним стойността му на историята заедно с всичко, което вече съхраняваме. Ще трябва да променим съществуващите правила за денормализиране, за да постигнем това).
- Забавяне на други операции: Можем да очакваме, че ще забавим операциите по вмъкване, модифициране и изтриване на данни. Ако тези операции се случват сравнително рядко, това може да бъде от полза. По принцип бихме разделили един бавен избор на по-голям брой по-бавни заявки за вмъкване/актуализиране/изтриване. Въпреки че много сложна заявка за избор технически може значително да забави цялата система, забавянето на множество „по-малки“ операции не би трябвало да навреди на използваемостта на нашето приложение.
- Още кодиране: Правила 2 и 3 ще изискват допълнително кодиране, но в същото време те ще опростят много някои заявки за избор. Ако денормализираме съществуваща база данни, ще трябва да модифицираме тези заявки за избор, за да се възползваме от ползите от нашата работа. Ще трябва също да актуализираме стойности в новодобавените атрибути за съществуващи записи. Това също ще изисква малко повече кодиране.
Примерният модел, денормализиран
В модела по-долу приложих някои от гореспоменатите правила за денормализация. Розовите маси са модифицирани, докато светлосинята маса е напълно нова.
Какви промени се прилагат и защо?

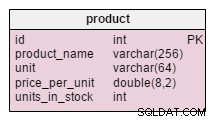
Единствената промяна в product таблицата е добавянето на units_in_stock атрибут. В нормализиран модел бихме могли да изчислим тези данни като поръчани единици – продадени единици – (предложени единици) – отписани единици . Ще повтаряме изчислението всеки път, когато клиент поиска този продукт, което би отнело много време. Вместо това ще изчислим стойността предварително; когато клиент ни попита, ние ще го подготвим. Разбира се, това много опростява заявката за избор. От друга страна, units_in_stock атрибутът трябва да се коригира след всяко вмъкване, актуализиране или изтриване в products_on_order , writeoff , product_offered и product_sold таблици.
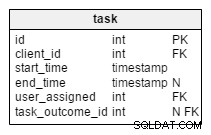
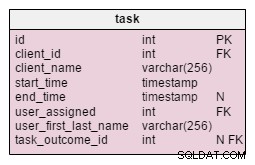
В модифицираната task таблица, намираме два нови атрибута:client_name и user_first_last_name . И двете съхраняват стойности при създаването на задачата. Причината е, че и двете стойности могат да се променят с течение на времето. Ние също така ще запазим външен ключ, който ги свързва с оригиналния клиент и потребителски идентификатор. Има още стойности, които бихме искали да съхраняваме, като клиентски адрес, идентификационен номер по ДДС и др.




Денормализираният product_offered таблицата има два нови атрибута, price_per_unit и price . price_per_unit атрибутът се съхранява, защото трябва да съхраняваме действителната цена когато продуктът е бил предложен . Нормализираният модел ще покаже само текущото си състояние, така че когато цената на продукта се промени, нашите „исторически“ цени също ще се променят. Нашата промяна не само кара базата данни да работи по-бързо:тя също така я кара да работи по-добре. price атрибутът е изчислената стойност units_sold * price_per_unit . Добавих го тук, за да избегна това изчисление всеки път, когато искаме да разгледаме списък с предлаганите продукти. Това е малка цена, но подобрява производителността.
Промените, направени в product_sold таблицата са много сходни. Структурата на таблицата е същата, но съхранява списък с продадени артикули.
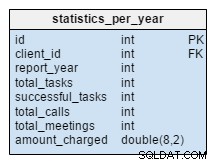
statistics_per_year масата е напълно нова за нашия модел. Трябва да гледаме на нея като на денормализирана таблица, защото всички нейни данни могат да бъдат изчислени от другите таблици. Идеята зад тази таблица е да съхранява броя на задачите, успешните задачи, срещите и обажданията, свързани с всеки клиент. Той също така обработва общата сума, начислена за всяка година. След вмъкване, актуализиране или изтриване на нещо в task , meeting , call и product_sold таблици, трябва да преизчислим данните на тази таблица за този клиент и съответната година. Можем да очакваме, че най-вече ще имаме промени само за текущата година. Отчетите за минали години не трябва да се променят.
Стойностите в тази таблица са изчислени предварително, така че ще отделим по-малко време и ресурси в момента, в който се нуждаем от резултата от изчислението. Помислете за ценностите, от които ще имате нужда често. Може би няма да имате нужда редовно от всички и можете да рискувате да изчислите някои от тях на живо.
Денормализацията е много интересна и мощна концепция. Въпреки че не е първото, което трябва да имате предвид за подобряване на производителността, в някои ситуации може да бъде най-доброто или дори единственото решение.
Преди да изберете да използвате денормализация, уверете се, че я искате. Направете някакъв анализ и проследете ефективността. Вероятно ще решите да преминете към денормализация, след като вече сте излезли на живо. Не се страхувайте да го използвате, но следете промените и не би трябвало да изпитвате проблеми (т.е. страшните аномалии в данните).