Какви проблеми ще разгледаме?
Ако сървърът уведоми „няма повече място на E устройството“ – не е необходим задълбочен анализ. Няма да разглеждаме грешки, чието решение е очевидно от текста на съобщението и за които Google незабавно хвърля връзка към MSDN с решението.
Нека разгледаме проблемите, които не са очевидни за Google, като например внезапен спад в производителността или липсата на връзка. Помислете за основните инструменти за персонализиране и анализ. Нека видим къде се намират регистрационните файлове и друга полезна информация. Всъщност ще се опитам да събера в една статия цялата необходима информация за бърз старт.
Първо
Ще започнем с най-честите въпроси и ще ги разгледаме отделно.
Ако вашата база данни изведнъж, без видима причина, започне да работи бавно, но не сте променили нищо – първо, актуализирайте статистиката и изградете отново индексите.
В Интернет има много методи като този, предоставени са примери за скриптове. Предполагам, че всички тези методи са за професионалисти. Е, ще опиша най-простия начин:имате нужда само от мишка, за да го приложите.
Съкращение
- SSMS е приложение на Microsoft SQL Server Management Studio. Започвайки от версията за 2016 г., тя е достъпна безплатно на уебсайта на MS като самостоятелно приложение. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler е приложение на „SQL Server Profiler“, инсталирано със SSMS.
- Performance Monitor е добавка на контролния панел, която ви позволява да наблюдавате броячите на производителността, да регистрирате и преглеждате хронологията на измерванията.
Актуализация на статистиката с помощта на „план за обслужване“:
- изпълни SSMS;
- свържете се с необходим сървър;
- разширете дървото в Object Inspector:Management\Maintenance Plans (Service Plans);
- щракнете с десния бутон върху възела и изберете „Съветник за план за поддръжка“;
- в съветника маркирайте необходимите задачи:възстановяване на индекса и актуализиране на статистиката
- можете да маркирате и двете задачи наведнъж или да направите два плана за поддръжка с по една задача във всяка (вижте „важните бележки“ по-долу);
- Освен това проверяваме необходимата БД (или няколко бази данни). Правим това за всяка задача (ако са избрани две задачи, ще има два диалога с избор на база данни);
- Напред, Следващ, Край.
След тези действия ще бъде създаден „план за поддръжка“ (не се изпълнява). Можете да го стартирате ръчно, като щракнете с десния бутон върху него и изберете „Execute“. Друга възможност е да конфигурирате стартирането чрез SQL агент.
Важни бележки:
- Актуализирането на статистическите данни е неблокираща операция. Можете да го изпълнявате в работен режим.
- Възстановяването на индекс е блокираща операция. Можете да го стартирате само извън работното време. Има изключение — Enterprise изданието на сървъра позволява изпълнението на „онлайн повторно изграждане“. Тази опция може да бъде активирана в настройките на задачата. Моля, имайте предвид, че има отметка във всички издания, но тя работи само в Enterprise.
- Разбира се, тези задачи трябва да се изпълняват редовно. Предлагам лесен начин да определите колко често правите това:
– При първите проблеми изпълнете плана за поддръжка;
– Ако е помогнало, изчакайте, докато проблемите се появят отново (обикновено до следващото месечно приключване/изчисляване на заплата/ и т.н. на групови транзакции);
– Полученият период на нормална работа ще бъде вашата референтна точка;
– Например, конфигурирайте изпълнението на плана за поддръжка два пъти по-често.
Сървърът е бавен – какво трябва да направите?
Ресурсите, използвани от сървъра
Както всяка друга програма, сървърът се нуждае от процесорно време, данни на диска, количество RAM и мрежова честотна лента.
Task Manager ще ви помогне да оцените липсата на даден ресурс в първо приближение, колкото и ужасно да звучи.
ЦП Зареждане
Дори ученик може да провери използването в Мениджъра. Просто трябва да се уверим, че ако процесорът е зареден, това е процесът sqlserver.exe.
Ако това е вашият случай, трябва да отидете на анализа на активността на потребителите, за да разберете какво точно е причинило натоварването (вижте по-долу).
Диск Лоа г
Много хора гледат само натоварването на процесора, но забравят, че СУБД е хранилище на данни. Обемът на данни нараства, производителността на процесора се увеличава, докато скоростта на твърдия диск е почти същата. При SSD дисковете ситуацията е по-добра, но съхраняването на терабайти на тях е скъпо.
Оказва се, че често срещам ситуации, в които дисковата система се превръща в тесното място, а не в процесора.
За дисковете са важни следните показатели:
- средна дължина на опашката (неизпълнени I/O операции, брой);
- скорост на четене-запис (в Mb/s).
Сървърната версия на диспечера на задачите, като правило (в зависимост от версията на системата), показва и двете. Ако не, стартирайте приставката Performance Monitor (системен монитор). Интересуваме се от следните броячи:
- Физически (логически) диск/Средно време за четене (запис)
- Физически (логически) диск/Средна дължина на дисковата опашка
- Физически (логически) диск/скорост на диска
За повече подробности можете да прочетете ръководствата на производителя, например тук:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
Накратко:
- Опашката не трябва да надвишава 1. Допускат се кратки серии, ако бързо отшумяват. Пусканията могат да бъдат различни в зависимост от вашата система. За обикновено RAID огледало от два HDD – опашката от повече от 10-20 е проблем. За страхотна библиотека със супер кеширане видях пакети до 600-800, които бяха незабавно разрешени, без да причиняват забавяния.
- Нормалният обменен курс също зависи от типа на дисковата система. Обичайният (настолен) твърд диск предава с 50-100 MB/s. Добра дискова библиотека – при 500 MB/s и повече. За малки произволни операции скоростта е по-малка. Това може да е вашата отправна точка.
- Тези параметри трябва да се разглеждат като цяло. Ако вашата библиотека предава 50MB/s и се нареди опашка от 50 операции — очевидно, нещо не е наред с хардуера. Ако опашката се нареди, когато предаването е близо до максимума – най-вероятно дисковете не са виновни – те просто не могат да направят повече – трябва да търсим начин да намалим натоварването.
- Натоварването трябва да се проверява отделно на дисковете (ако има няколко) и да се сравнява с местоположението на сървърните файлове. Мениджърът на задачите може да показва най-активно използваните файлове. Това може да се използва, за да се гарантира, че натоварването е причинено от СУБД.
Какво може да причини проблеми с дисковата система:
- проблеми с хардуера
- кешът изгори, производителността спадна драстично;
- дисковата система се използва от нещо друго;
- Недостиг на RAM. Размяна. Кеширането се разпадна, производителността спадна (вижте раздела за RAM по-долу).
- Натоварването на потребителите се увеличи. Необходимо е да се оцени работата на потребителите (проблемна заявка/нова функционалност/увеличаване на броя на потребителите/увеличаване на количеството данни/и т.н.).
- Фрагментация на данните от базата данни (вижте възстановяването на индекса по-горе), фрагментация на системните файлове.
- Дисковата система е достигнала максималните си възможности.
В случай на последния вариант – не изхвърляйте хардуера наведнъж. Понякога можете да извлечете малко повече от системата, ако подходите към проблема разумно. Проверете местоположението на системните файлове за съответствие с препоръчаните изисквания:
- Не смесвайте OS файлове с файлове с данни от база данни. Съхранявайте ги на различни физически носители, така че системата да не се конкурира с СУБД за I/O.
- Базата данни се състои от два типа файлове:данни (*.mdf, *.ndf) и регистрационни файлове (*.ldf).
Файловете с данни, като правило, се използват предимно за четене. Дневниците служат за писане (при което записването е последователно). Поради това се препоръчва да се съхраняват регистрационни файлове и данни на различни физически носители, така че регистрирането да не прекъсва четенето на данни (по правило операцията на запис има предимство пред четенето). - MS SQL може да използва „временни таблици“ за обработка на заявки. Те се съхраняват в системната база данни tempdb. Ако имате голямо натоварване на файловете от тази база данни, можете да опитате да я изобразите на физически отделен носител.
Обобщавайки проблема с местоположението на файла, използвайте принципа „разделяй и владей“. Оценете кои файлове са достъпни и се опитайте да ги разпространите на различни медии. Също така използвайте функциите на RAID системите. Например четенето на RAID-5 е по-бързо от записа – което е добре за файлове с данни.
Нека проучим как да извлечем информация за производителността на потребителите:кой какво прави и колко ресурси се консумират
Разделих задачите за одит на потребителската активност в следните групи:
- Задачи за анализиране на конкретна заявка.
- Задачи за анализиране на натоварването от приложението при специфични условия (например, когато потребител щракне върху бутон в приложение на трета страна, съвместимо с базата данни).
- Задачи за анализиране на текущата ситуация.
Нека разгледаме всеки от тях подробно.
Предупреждение
Анализът на производителността изисква дълбоко разбиране на структурата и принципите на работа на сървъра на базата данни и операционната система. Ето защо четенето само на тези статии няма да ви направи професионалист.
Разглежданите критерии и броячи в реалните системи зависят един от друг в голяма степен. Например, високото натоварване на твърдия диск често е причинено от липса на RAM. Дори да извършите някои измервания, това не е достатъчно, за да оцените проблемите разумно.
Целта на статиите е да въведе основното на прости примери. Не бива да разглеждате моите препоръки като ръководство. Препоръчвам ви да ги използвате като учебни задачи, които могат да обяснят потока на мислите.
Надявам се, че ще се научите как да рационализирате заключенията си за производителността на сървъра в цифри.
Вместо да кажете „сървърът се забавя“, ще предоставите конкретни стойности на конкретни индикатори.
Анализирайте P ставенR конен
Първата точка е доста проста, нека се спрем на нея накратко. Ще разгледаме някои по-малко очевидни проблеми.
В допълнение към резултатите от заявката, SSMS позволява извличане на допълнителна информация за изпълнението на заявката:
- Можете да получите плана на заявката, като щракнете върху бутоните „Показване на приблизителен план за изпълнение“ и „Включване на действителен план за изпълнение“. Разликата между тях е, че планът за оценка се изгражда без изпълнение на заявка. По този начин ще бъде оценена информацията за броя на обработените редове. В действителния план ще има както прогнозни, така и действителни данни. Силните несъответствия на тези стойности показват, че статистическите данни не са релевантни. Анализът на плана обаче е тема за друга статия – засега няма да навлизаме по-дълбоко.
- Можем да получим измервания на разходите на процесора и дисковите операции на сървъра. За да направите това, е необходимо да активирате опцията SET. Можете да го направите или в диалоговия прозорец „Опции за заявка“ по следния начин:
Или с директните команди SET в заявката:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDВ резултат на това ще получим данни за времето, прекарано за компилиране и изпълнение, както и за броя на операциите с диска.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Бих искал да насоча вниманието ви към времето за компилиране, логическите четения 96 и физическите четения 5. При изпълнение на една и съща заявка за втори път и по-късно, физическите четения може да намалеят и може да не се изисква повторно компилиране. Поради този факт често се случва заявката да се изпълнява по-бързо през втория и следващите пъти, отколкото за първи път. Причината, както разбирате, е в кеширането на данните и съставените планове за заявки.
- Бутонът «Включване на клиентска статистика» показва информацията за мрежовия обмен, количеството изпълнени операции и общото време за изпълнение, включително разходите за мрежов обмен и обработка от клиента. Примерът показва, че отнема повече време за изпълнение на заявката за първи път:
- В SSMS 2016 има бутон „Включване на статистически данни за заявка на живо“. Той показва изображението, както в случая на плана на заявката, но съдържа неслучайните цифри на обработените редове, които се променят на екрана по време на изпълнение на заявката. Картината е много ясна – мигащи стрелки и вървящи числа, веднага се вижда къде е загубено времето. Бутонът работи и за SQL Server 2014 и по-нови версии.
За да обобщим:
- Проверете разходите на процесора, като използвате SET STATISTICS TIME ON.
- Дискови операции:ВКЛЮЧЕТЕ STATISTICS IO. Не забравяйте, че логическото четене е операция за четене, завършена в кеша на диска без физически достъп до дисковата система. „Физическото четене“ отнема много повече време.
- Оценете обема на мрежовия трафик, като използвате „Включване на клиентска статистика“.
- Анализирайте алгоритъма за изпълнение на заявката от плана за изпълнение, като използвате „Включване на действителен план за изпълнение“ и „Включване на статистически данни за заявка на живо“.
Анализирайте натоварването на приложението
Тук ще използваме SQL Server Profiler. След стартиране и свързване със сървъра е необходимо да изберете лог събития. За да направите това, стартирайте профилиране със стандартен шаблон за проследяване. Вобща раздела в Използване на шаблона поле, изберете Стандартно (по подразбиране) и щракнете върху Изпълни .
По-сложният начин е да добавяте/пускате филтри или събития към/от избрания шаблон. Тези опции могат да бъдат намерени във втория раздел на диалоговото меню. За да видите пълния набор от възможни събития и колони за избор, изберете Показване на всички събития и Показване на всички колони квадратчета за отметка.

Ще ни трябват следните събития:
- Съхранени процедури \ RPC:Завършено
- TSQL \ SQL:BatchCompleted
Тези събития наблюдават всички външни SQL повиквания към сървъра. Те се появяват след приключване на обработката на заявката. Има подобни събития, които следят старта на SQL Server:
- Съхранени процедури \ RPC:Стартиране
- TSQL \ SQL:BatchStarting
Въпреки това, ние не се нуждаем от тези процедури, тъй като те не съдържат информация за ресурсите на сървъра, изразходвани за изпълнение на заявката. Очевидно е, че такава информация е налична едва след приключване на процеса на изпълнение. По този начин колоните с данни за CPU, Reads, Writes в *Началните събития ще бъдат празни.
Следните събития също може да ни заинтересуват, но засега няма да ги активираме:
- Съхранени процедури \ SP:Стартиране (*Завършено) следи вътрешното извикване към съхранената процедура не от клиента, а в рамките на текущата заявка или друга процедура.
- Съхранени процедури \ SP:StmtStarting (*Completed) проследява началото на всеки израз в рамките на съхранената процедура. Ако в процедурата има цикъл, броят на събитията за командите в цикъла ще бъде равен на броя на повторенията в цикъла.
- TSQL \ SQL:StmtStarting (*Completed) следи началото на всеки израз в SQL-пакета. Ако във вашата заявка има няколко команди, всяка от тях ще съдържа едно събитие. По този начин работи за командите, намиращи се в заявката.
Тези събития са удобни за наблюдение на процеса на изпълнение.
От C колони
Кои колони да изберете е ясно от името на бутона. Ще ни трябват следните:
- TextData, BinaryData съдържат текста на заявката.
- CPU, Reads, Writes, Duration показва данни за потреблението на ресурси.
- StartTime, EndTime е времето за започване и завършване на процеса на изпълнение. Удобни са за сортиране.
Добавете други колони въз основа на вашите предпочитания.
Филтрите за колони... бутон отваря диалогов прозорец за конфигуриране на филтри за събития. Ако се интересувате от дейността на конкретния потребител, можете да зададете филтъра по SID номер или потребителско име. За съжаление, в случай на свързване на приложението през ап-сървъра с привличане на връзки, наблюдението на конкретния потребител става по-сложно.
Можете да използвате филтри за избор само на сложни заявки (Продължителност>X), заявки, които причиняват интензивно писане (Writes>Y), както и избор на съдържание на заявка и др.
Какво още ни трябва от профайлъра? Разбира се, планът за изпълнение!
Към трасирането е необходимо да се добави събитието «Performance \ Showplan XML Statistics Profile». Докато изпълняваме нашата заявка, ще получим следното изображение:
Текстът на заявката:
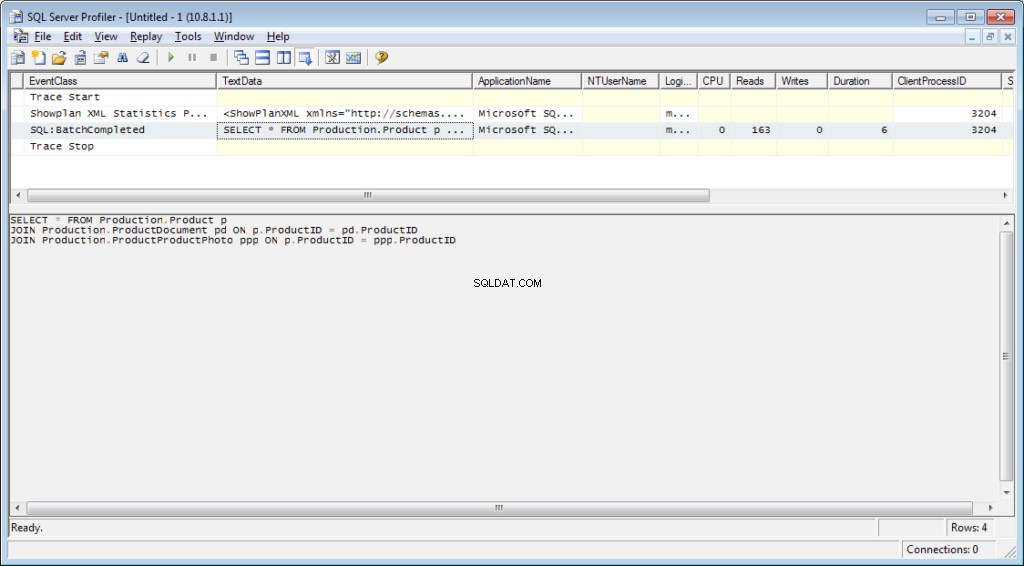
Планът за изпълнение:
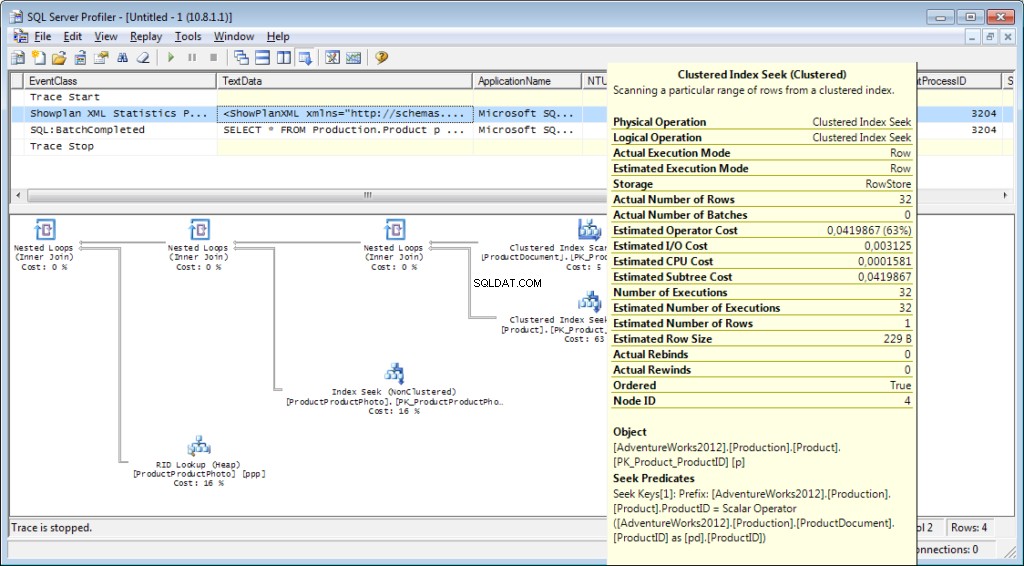
И това не е всичко
Възможно е да се запише следа във файл или таблица на база данни. Настройките за проследяване могат да се съхраняват като личен шаблон за бързо изпълнение. Можете да стартирате проследяването без профайлър, като просто използвате T-SQL код и процедурите sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Можете да намерите пример тук. Този подход може да бъде полезен, например, за автоматично започване на съхраняване на следа към файл по график. Можете да имате подъл връх в профайлъра, за да видите как да използвате тези команди. Можете да стартирате две трасета и в една от тях да проследявате какво се случва, когато стартира втората. Проверете дали няма филтър по колоната „ApplicationName“ в самия профайлър.
Списъкът на събитията, наблюдавани от профайлъра, е много голям и не се ограничава до получаване на текстове на заявка. Има събития, които проследяват пълно сканиране, прекомпилиране, автоматично нарастване, блокиране и много други.
Анализиране на потребителската активност на сървъра
Има различни ситуации. Една заявка може да виси на „изпълнение“ за дълго време и не е ясно дали ще бъде завършена или не. Бих искал да анализирам отделно проблемната заявка; обаче първо трябва да определим каква е заявката. Безполезно е да го хванете с профайлър – вече сме пропуснали началното събитие и не е ясно колко време да чакаме процесът да приключи.
Нека го разберем
Може би сте чували за „Монитор на активността“. По-високите му издания имат наистина богата функционалност. Как може да ни помогне? Activity Monitor включва много полезни и интересни функции. Ще получим всичко необходимо от системни изгледи и функции. Мониторът сам по себе си е полезен, защото можете да зададете на него профайлъра и да видите какви заявки изпълнява.
Ще ни трябва:
- dm_exec_sessions предоставя информация за сесиите на свързани потребители. В нашата статия полезните полета са тези, които идентифицират потребител (име_за вход, време_за влизане, име_хост, име_на_програма,...) и полета с информация за изразходваните ресурси (cpu_time, reads, writes, memory_usage,…)
- dm_exec_requests предоставя информация за заявки, изпълнявани в момента.
- session_id е идентификатор на сесията за свързване към предишния изглед.
- start_time е времето за изпълнение на изгледа.
- командата е поле, което съдържа тип на изпълнената команда. За потребителски заявки това е select/update/delete/
- sql_handle, statement_start_offset, statement_end_offset предоставят информация за извличане на текст на заявката:манипулатор, както и начална и крайна позиция в текста на заявката, което означава частта, която се изпълнява в момента (за случая, когато вашата заявка съдържа няколко команди).
- plan_handle е манипулатор на генерирания план.
- blocking_session_id указва номера на сесията, която е причинила блокиране, ако има блокове, които пречат на изпълнението на заявката
- wait_type, wait_time, wait_resource са полета с информация за причината и продължителността на чакането. За някои видове изчаквания, например заключване на данни, е необходимо да посочите допълнително код за блокирания ресурс.
- percent_complete е процентът на завършеност. За съжаление, той е достъпен само за команди с ясно предвидим напредък (например архивиране или възстановяване).
- cpu_time, reads, writes, logical_reads, granted_query_memory са разходи за ресурси.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) са функции за получаване на текст и план за изпълнение. По-долу ще разгледаме пример за използването му.
- dm_exec_query_stats е обобщена статистика за изпълнение на заявки. Показва заявката, броя на нейните изпълнения и обема на изразходваните ресурси.
Важни бележки
Горният списък е само малка част. Пълен списък на всички системни изгледи и функции е описан в документацията. Също така има красиво изображение, показващо диаграма на връзките между основните обекти.
Текстът на заявката, нейният план и статистика за изпълнение са данни, съхранявани в кеша на процедурите. Те са достъпни по време на изпълнение. Тогава наличността не е гарантирана и зависи от натоварването на кеша. Да, кешът може да бъде почистен ръчно. Понякога се препоръчва, когато плановете за изпълнение се „обърнат“. Все пак има много нюанси.
Полето „команда“ е безсмислено за потребителски заявки, тъй като можем да получим пълния текст. Въпреки това, той е много важен за получаване на информация за системните процеси. Като правило те изпълняват някои вътрешни задачи и нямат SQL текст. За такива процеси информацията за командата е единственият намек за типа дейност.
В коментарите към предишната статия имаше въпрос за това в какво участва сървърът, когато не трябва да работи. Отговорът вероятно ще бъде в смисъла на това поле. В моята практика полето „команда“ винаги предоставяше нещо съвсем разбираемо за активните системни процеси:autoshrink / autogrow / checkpoint / logwriter / и т.н.
Как да го използвам
Ще преминем към практическата част. Ще дам няколко примера за използването му. Възможностите на сървъра не са ограничени – можете да измислите свои собствени примери.
Пример 1. Какъв процес консумира процесор/четене/запис/памет
Първо, разгледайте сесиите, които консумират повече ресурси, например CPU. Можете да намерите тази информация в sys.dm_exec_sessions. Въпреки това данните за процесора, включително четене и запис, са кумулативни. Това означава, че номерът съдържа общата сума за цялото време на свързване. Ясно е, че потребителят, който се е свързал преди месец и не е бил прекъснат, ще има по-висока стойност. Това не означава, че те претоварват системата.
Код със следния алгоритъм може да реши този проблем:
- Направете избор и го съхранете във временна таблица
- Изчакайте известно време
- Направете избор за втори път
- Сравнете тези резултати. Тяхната разлика ще показва разходите, изразходвани на стъпка 2.
- За удобство разликата може да се раздели на продължителността на стъпка 2, за да се получат средните „разходи за секунда“.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Използвам две таблици в кода:#tmp – за първата селекция и #tmp1 – за втората. По време на първото изпълнение скриптът създава и запълва #tmp и #tmp1 на интервал от една секунда и след това изпълнява други задачи. При следващото изпълнение скриптът използва резултатите от предишното изпълнение като база за сравнение. По този начин продължителността на стъпка 2 ще бъде равна на продължителността на вашето чакане между изпълнението на скрипта.
Опитайте да го изпълните, дори на производствения сървър. Скриптът ще създаде само „временни таблици“ (достъпни в рамките на текущата сесия и изтрити, когато е деактивиран) и няма нишка.
Тези, които не обичат да изпълняват заявка в MS SSMS, могат да я обвият в приложение, написано на любимия им език за програмиране. Ще ви покажа как да направите това в MS Excel без нито един ред код.
В менюто Данни се свържете със сървъра. Ако бъдете подканени да изберете таблица, изберете произволна. Щракнете върху Напред и Край, докато не видите диалоговия прозорец Импортиране на данни. В този прозорец трябва да щракнете върху Свойства. В Properties е необходимо да замените тип команда със стойността на SQL и да вмъкнете нашата модифицирана заявка в текстовото поле на командата.
Ще трябва да промените малко заявката:
- Добавете „ЗАДАВАНЕ НА NOCOUNT ON“
- Заменете временните таблици с променливи таблици
- Забавянето ще продължи в рамките на 1 сек. Полетата със осреднени стойности не са задължителни
Променената заявка за Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Резултат:
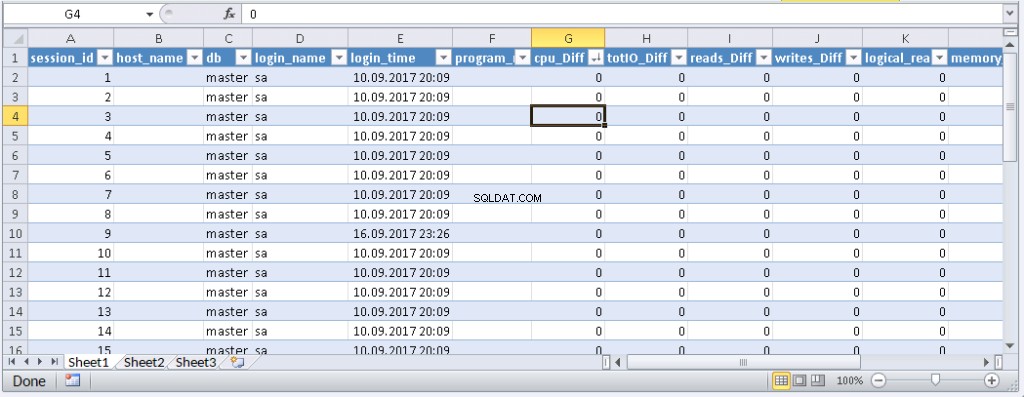
Когато данните се появят в Excel, можете да ги сортирате, както ви е необходимо. За да актуализирате информацията, щракнете върху „Обновяване“. В настройките на работната книга можете да поставите „автоматична актуализация“ в определен период от време и „актуализация в началото“. Можете да запазите файла и да го предадете на вашите колеги. Така създадохме удобен и прост инструмент.
Пример 2. За какво се изразходват ресурси за сесия?
Сега ще определим какво всъщност правят проблемните сесии. За да направите това, използвайте sys.dm_exec_requests и функции, за да получите текст на заявка и план за заявка.
Заявката и планът за изпълнение по номера на сесията
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Поставете номера на сесията в заявката и я стартирайте. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
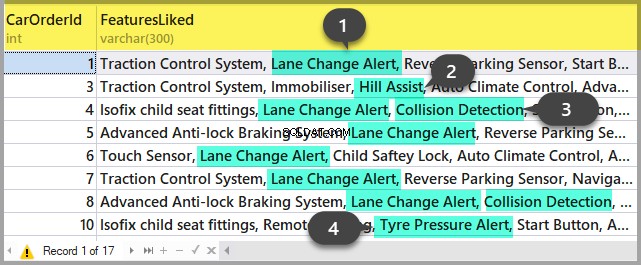
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Заключение
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.