Въведение
В днешно време високата наличност е изискване за много системи, без значение каква технология използвате. Това е особено важно за базите данни, тъй като те съхраняват данни, на които разчитат критичните приложения и системи. Най-често срещаната стратегия за постигане на висока наличност е репликацията. Има различни начини за репликиране на данни в множество сървъри и трафик при отказ, когато например основен сървър спре да отговаря.
Архитектура с висока достъпност за PostgreSQL
Има няколко архитектури за внедряване на висока наличност в PostgreSQL, но основните са архитектури Primary-Standby и Primary-Primary.
Първични-готови архитектури
Primary-Standby може да е най-основната HA архитектура, която можете да настроите, и често най-лесната за внедряване и поддръжка. Базира се на една основна база данни с един или повече сървъри в режим на готовност. Тези резервни бази данни ще останат синхронизирани (или почти синхронизирани) с първичния възел, в зависимост от това дали репликацията е синхронна или асинхронна. Ако основният сървър се повреди, сървърът в режим на готовност съдържа почти всички данни на основния сървър и може бързо да бъде превърнат в новия основен сървър на база данни.
Можете да внедрите два типа резервни бази данни в зависимост от естеството на репликацията:
- Логически режими на готовност – Репликацията между първичен и режим на готовност се извършва чрез SQL оператори.
- Физически режими на готовност – Репликацията между първичен и режим на готовност се извършва чрез модификации на вътрешната структура на данните.
В случая на PostgreSQL се използва поток от записи в дневника с предварителна запис (WAL), за да се поддържат синхронизирани бази данни в режим на готовност. Това може да бъде синхронно или асинхронно и целият сървър на база данни се репликира.
От версия 10 нататък PostgreSQL включва вградена опция за настройка на логическа репликация, която конструира поток от модификации на логически данни от информацията в дневника за предварителна запис. Този метод на репликация позволява промените в данните от отделни таблици да бъдат репликирани, без да е необходимо да се определя основен сървър. Освен това позволява на данните да протичат в множество посоки.
За съжаление, настройката за първичен режим на готовност не е достатъчна, за да гарантира ефективно висока наличност, тъй като трябва да се справяте и с неуспехите. За да се справите с неуспехите, трябва да можете да ги откривате. След като разберете, че има повреда, например грешки на основния възел или възелът не отговаря, можете да изберете възел в режим на готовност, за да замените неуспешния възел с възможно най-малко забавяне. Този процес трябва да бъде възможно най-ефективен, за да възстанови пълната функционалност на приложенията. Самият PostgreSQL не включва механизъм за автоматичен отказ, така че това ще изисква някои персонализирани скриптове или инструменти на трети страни за тази автоматизация.
След като се случи отказ, приложението ви трябва да бъде съответно уведомено, за да започне да използва новия Основен. Вие също трябва да оцените състоянието на вашата архитектура след отказ, тъй като можете да попаднете в ситуация, в която работи само новият първичен (например, вие сте имали първичен възел и само един режим на готовност преди проблема). В този случай ще трябва да добавите възел в режим на готовност, за да създадете отново първоначалната настройка за първичен режим на готовност за висока наличност.
Първични-първични архитектури
Първична-първична архитектура осигурява начин за минимизиране на въздействието на грешка върху един от възлите, тъй като другият(и) възел(и) може да се погрижи за целия трафик, като само потенциално повлияе малко на производителността но никога не губи функционалност. Първично-първичната архитектура често се използва с двойна цел за създаване на среда с висока наличност и хоризонтално мащабиране (в сравнение с концепцията за вертикална мащабируемост, при която добавяте повече ресурси към сървър).
PostgreSQL все още не поддържа тази архитектура "нативно", така че ще трябва да се обърнете към инструменти и реализации на трети страни. Когато избирате решение, трябва да имате предвид, че има много проекти/инструменти, но някои от тях вече не се поддържат, докато други са нови и може да не са тествани в битка в производството.
Балансиране на натоварването
Балансьорите на натоварване са инструменти, които могат да се използват за управление на трафика от вашето приложение, за да извлечете максимума от архитектурата на вашата база данни.
Тези инструменти не само са полезни за балансиране на натоварването на вашите бази данни, но също така помагат на приложенията да бъдат пренасочени към наличните/изправни възли и дори да определят портове с различни роли.
HAProxy е средство за балансиране на натоварването, което разпределя трафика от един източник към една или повече дестинации и може да дефинира специфични правила и/или протоколи за тази задача. Ако някоя от дестинациите спре да отговаря, те се маркират като офлайн и трафикът се изпраща до останалите налични дестинации.
Keepalived е услуга, която ви позволява да конфигурирате виртуален IP адрес в рамките на активна/пасивна група сървъри. Този виртуален IP адрес се присвоява на активен сървър. Ако този сървър не успее, IP адресът автоматично се мигрира към „Вторичния“ пасивен сървър, което му позволява да продължи да работи със същия IP адрес по прозрачен за системите начин.
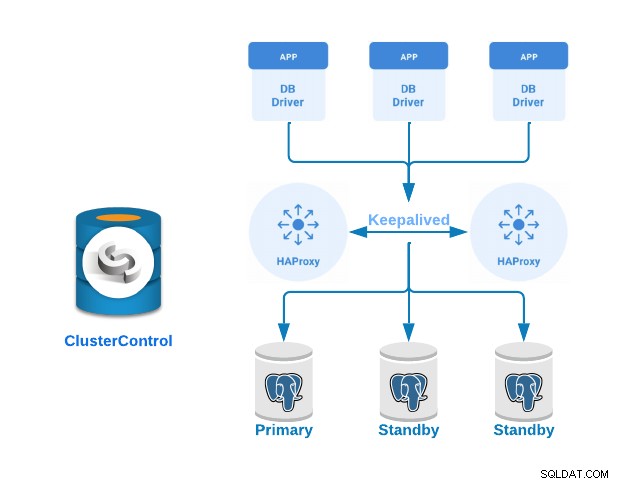
Нека сега да видим как да внедрим първичен и изчакващ PostgreSQL клъстер със сървъри за балансиране на натоварването и поддържане на активност, конфигурирани между тях. Ще демонстрираме това с помощта на лесния за използване интерфейс на ClusterControl.
За този пример ще създадем:
- 3 PostgreSQL сървъра (един основен и два режима на готовност).
- 2 HAProxy балансира на натоварването.
- Пазете конфигуриран между сървърите за балансиране на натоварването.
Разгръщане на база данни
За да разположите база данни с помощта на ClusterControl, просто изберете опцията „Разгръщане“ и следвайте инструкциите, които се появяват.
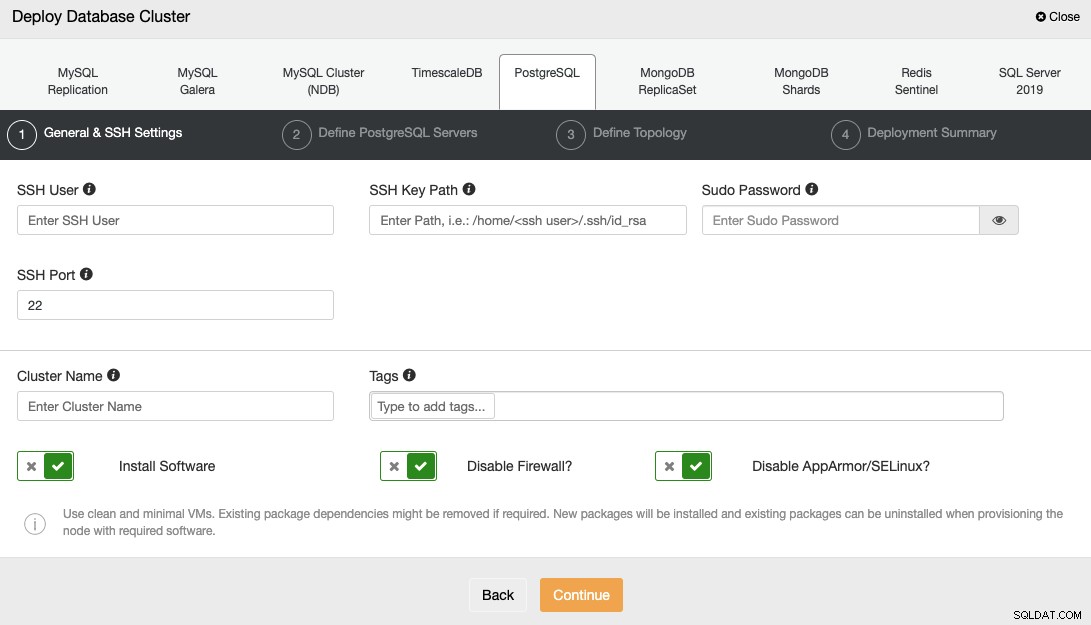
Когато избирате PostgreSQL, трябва да посочите потребителя, ключа или паролата и Порт за свързване чрез SSH към вашите сървъри. Трябва ви също и името за вашия нов клъстер и изберете дали искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
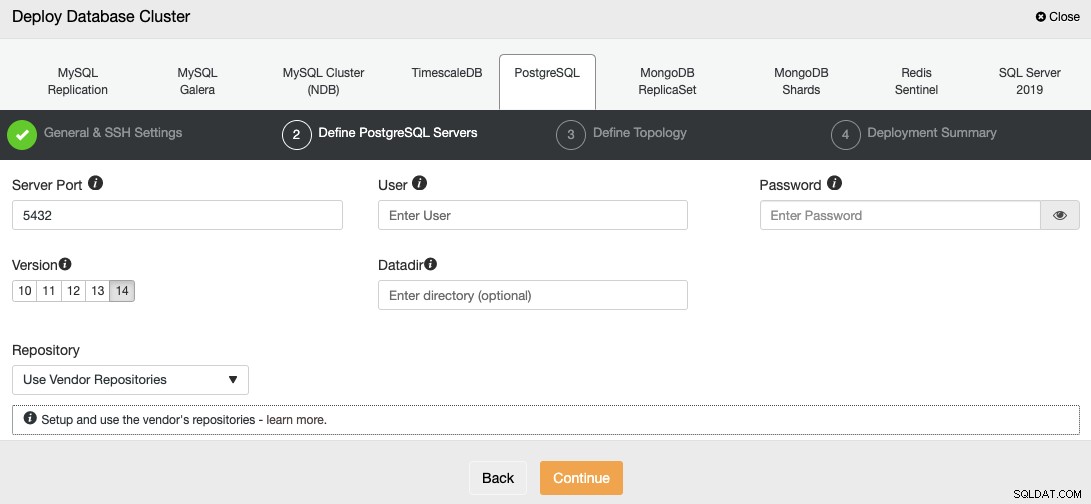
След като настроите информацията за SSH достъп, трябва да дефинирате потребителя на базата данни, версия и datadir (по избор). Можете също така да посочите кое хранилище да използвате; официалното хранилище на доставчик ще се използва по подразбиране.
В следващата стъпка трябва да добавите вашите сървъри към клъстера, който ще създадете.
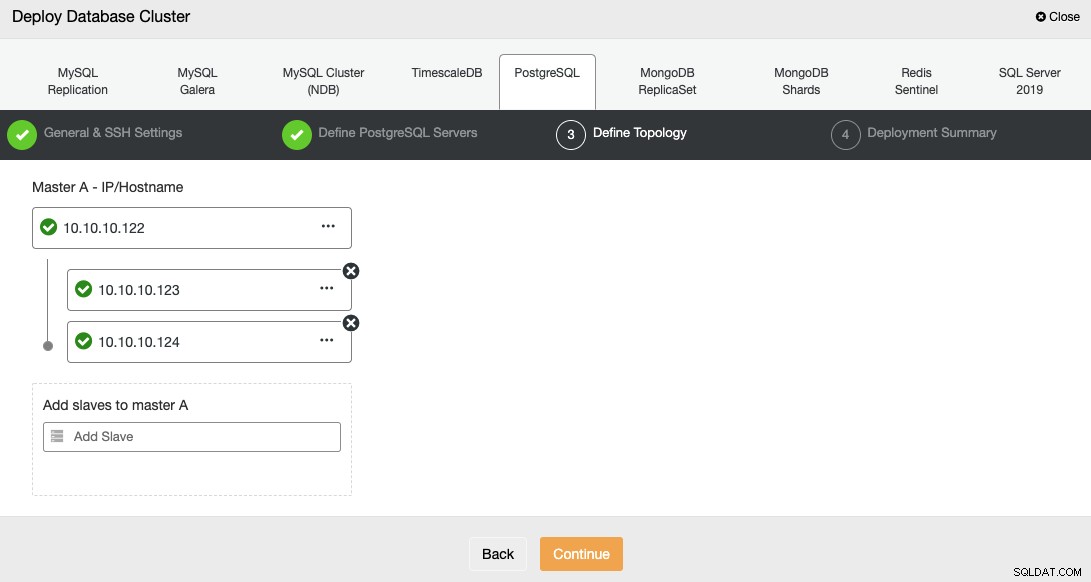
Когато добавяте вашите сървъри, можете да въведете IP или име на хост.
В последната стъпка можете да изберете дали вашата репликация ще бъде синхронна или асинхронна.
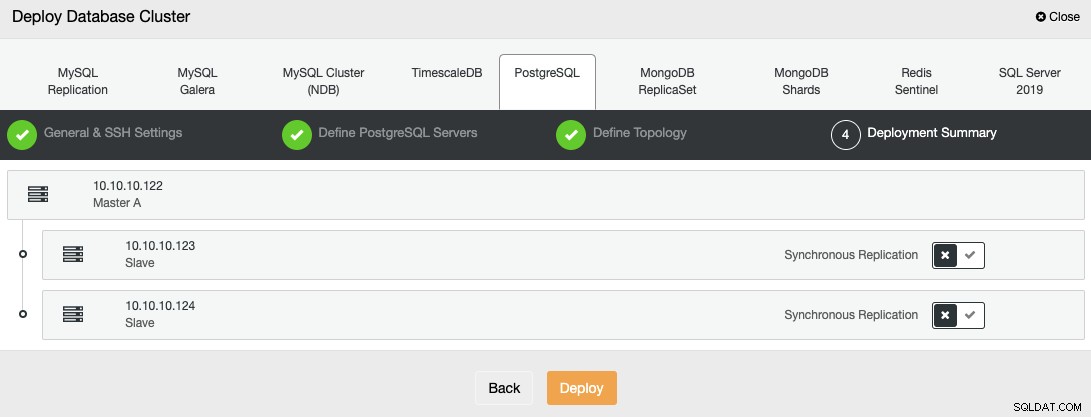
Можете да наблюдавате състоянието на създаването на вашия нов клъстер от ClusterControl монитор на активността.
След като задачата приключи, можете да видите своя клъстер в главния ClusterControl екран.
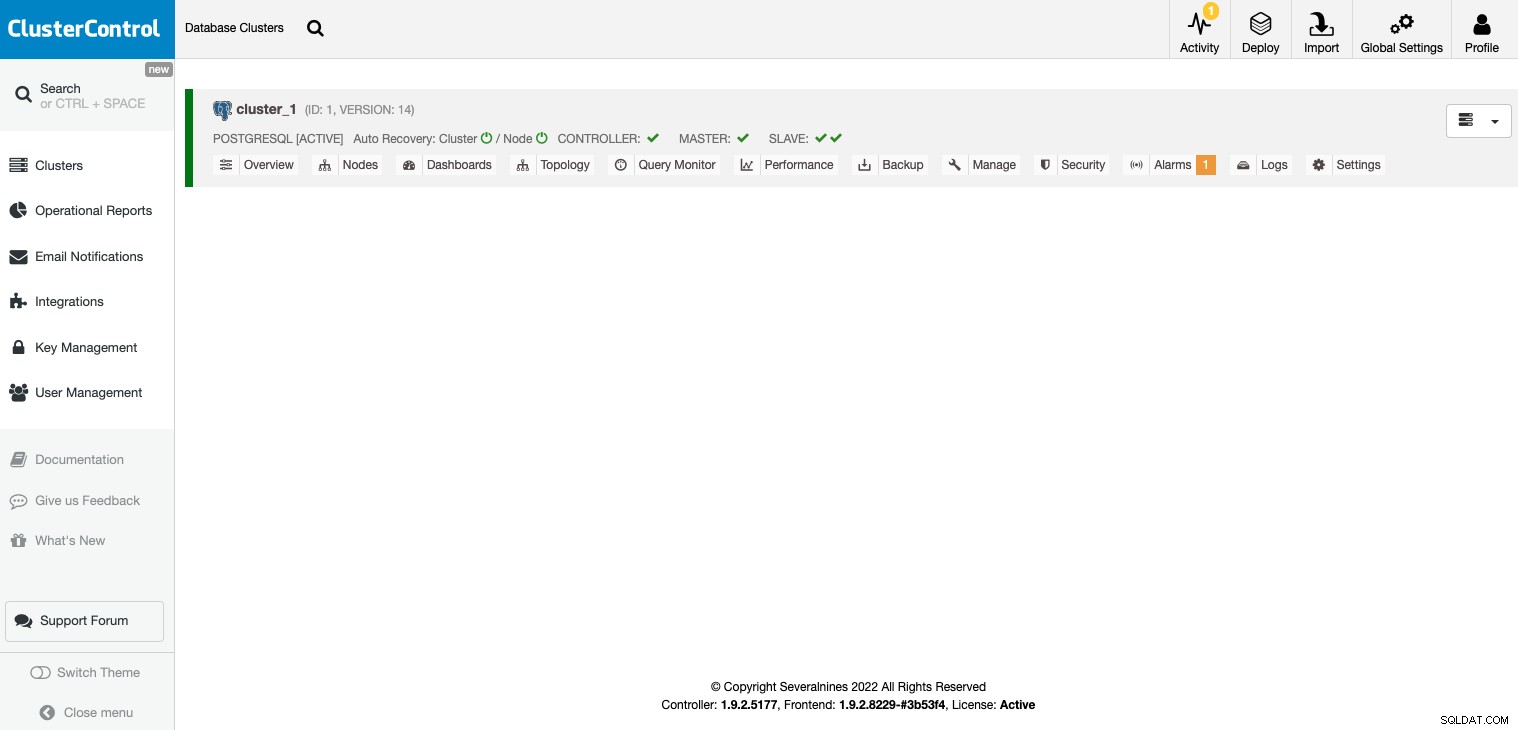
След като вашият клъстер бъде създаден, можете да изпълнявате няколко задачи, като например добавяне на балансьор на натоварване (HAProxy) или нова реплика.
Разгръщане на Load Balancer
За да извършите разгръщане на балансиране на натоварването, изберете опцията „Добавяне на балансиране на натоварването“ в действията на клъстера и попълнете исканата информация.
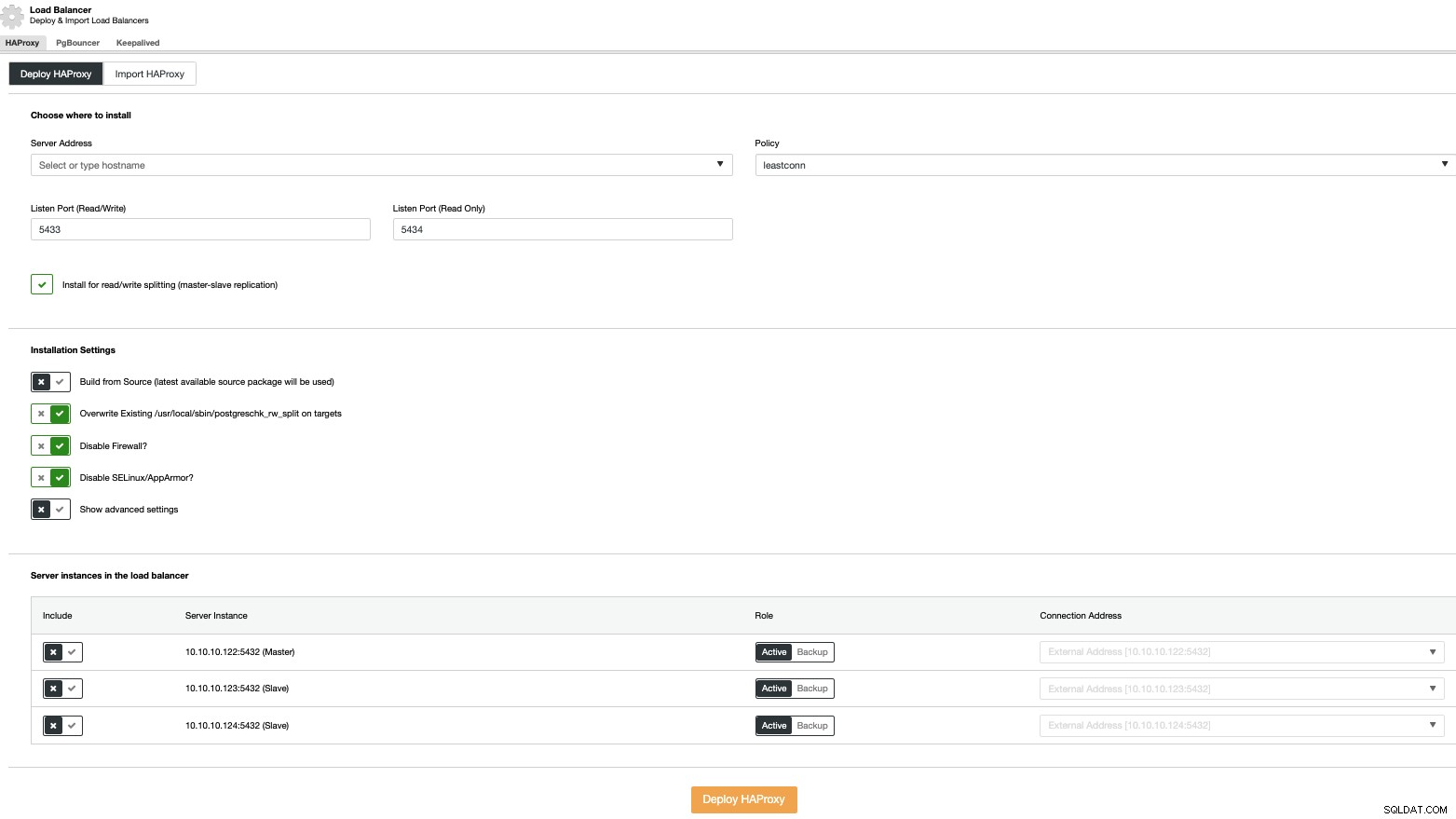
Трябва да добавите само IP адреса или име на хост, порт, политика, и възлите, които ще конфигурирате във вашите балансатори на натоварване.
Поддържано разполагане
За да извършите поддържащо разгръщане, изберете клъстера, отидете в менюто „Управление“ и секцията „Балансиране на натоварването“ и след това изберете опцията „Keepalived“.
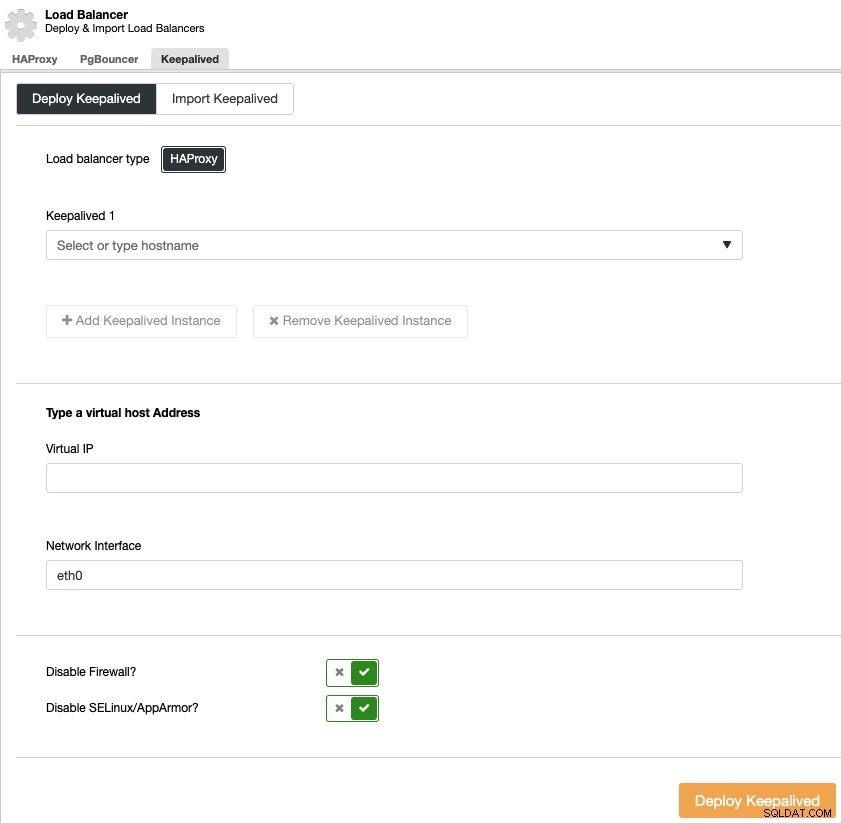
Трябва да изберете сървърите за балансиране на натоварването и виртуалния IP адрес за вашия високо среда за наличност.
Keepalived използва виртуалния IP адрес и го мигрира от един балансьор на натоварване към друг в случай на повреда, така че системите ви да могат да продължат да функционират нормално.
Ако сте изпълнили предишните стъпки, трябва да имате следната топология:
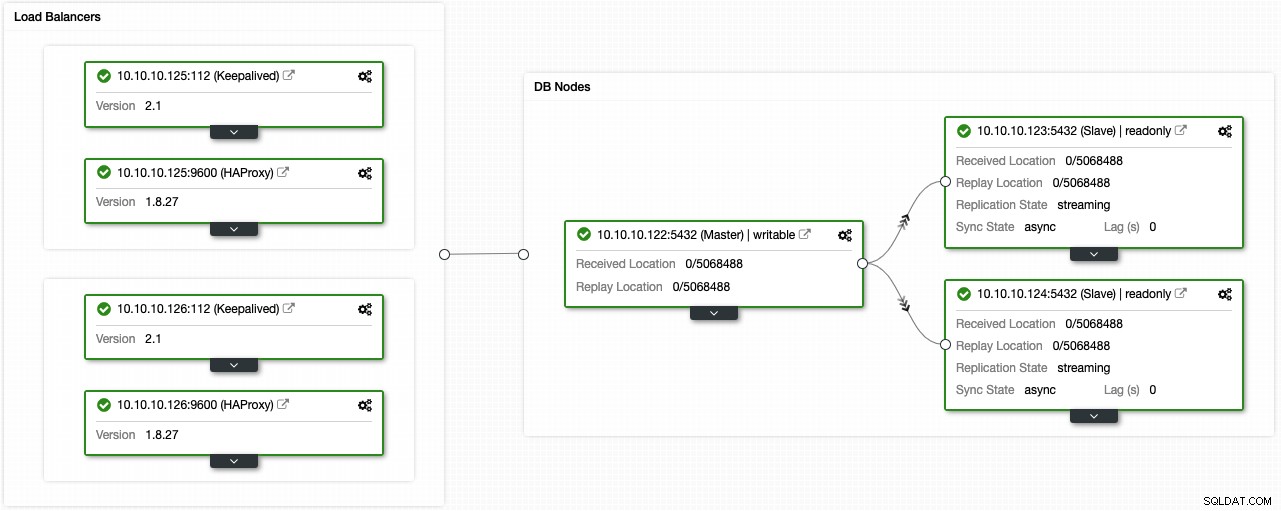
Можете да подобрите тази среда с висока наличност, като добавите пул за свързване като PgBouncer. Това не е задължително, но може да бъде полезно за подобряване на производителността и справяне с активни връзки в случай на неуспех, а най-хубавото е, че можете също да го разгърнете с помощта на ClusterControl.
Отказ при ClusterControl
Да предположим, че опцията „Автоматично възстановяване“ е ВКЛЮЧЕНА във вашия ClusterControl сървър. В случай на първична неизправност, ClusterControl ще повиши най-модерния режим на готовност (ако не е в черния списък) до първичен, както и ще ви уведоми за проблема. Той също така ще превключи при отказ останалите възли в режим на готовност, за да се репликират от новия Основен.
HAProxy е конфигуриран по подразбиране с два различни порта; портове за четене-запис и само за четене.
В порта за четене и запис имате своя първичен сървър като онлайн, а останалите си възли като офлайн, а в порта само за четене имате както първичен, така и режим на готовност онлайн.
Когато HAProxy открие, че един от вашите възли, първичен или резервен, не е достъпен, той автоматично го маркира като офлайн. Не го взема предвид за изпращане на трафик към него. Откриването се извършва от скриптове за проверка на състоянието, които ClusterControl конфигурира по време на внедряването. Те проверяват дали екземплярите са актуални, дали са в процес на възстановяване или са само за четене.
Когато ClusterControl промотира Standby към Основен, вашият HAProxy маркира стария Primary като офлайн за двата порта и поставя повишения възел онлайн в порта за четене и запис.
Ако вашият активен HAProxy, който е присвоил виртуалния IP адрес, към който се свързват системите ви, не успее, Keepalived мигрира този IP адрес към вашия пасивен HAProxy автоматично. Това означава, че вашите системи могат да продължат да функционират нормално.
По този начин вашите системи продължават да работят според очакванията и без вашата ръчна намеса.
Съображения
Ако успеете да възстановите стария си неуспешен първичен възел, той НЯМА да бъде въведен отново автоматично в клъстера по подразбиране. Трябва да го направите ръчно. Една от причините за това е, че ако вашата реплика е била забавена в момента на неуспеха и ClusterControl добави стария Primary към клъстера, това би означавало загуба на информация или несъответствие на данните между възлите. Може също да искате да анализирате проблема подробно. Ако ClusterControl просто въведе отново неуспешния възел в клъстера, вероятно ще загубите диагностична информация.
Освен това, ако преминаването при отказ не успее, не се правят повече опити. Необходима е ръчна намеса за анализиране на проблема и извършване на съответните действия. Това е, за да се избегне ситуацията, при която ClusterControl, като мениджър с висока наличност, се опитва да популяризира следващия режим на готовност и следващия. Може да има проблем и ще трябва да проверите това.
Сигурност
Едно важно нещо, което не можете да забравите, преди да влезете в производство с вашата среда с висока наличност, е да гарантирате нейната сигурност.
Няколко аспекта на сигурността, които трябва да имате предвид, включват криптиране, управление на ролите и ограничаване на достъпа по IP адрес, които разгледахме подробно в предишен блог.
Във вашата PostgreSQL база данни имате файла pg_hba.conf, който обработва удостоверяването на клиента. Можете да ограничите вида на връзката, IP адреса на източника или мрежата, към коя база данни можете да се свържете и с кои потребители. Следователно този файл е критична част за сигурността на PostgreSQL.
Можете да конфигурирате вашата база данни PostgreSQL от файла postgresql.conf, така че тя слуша само на конкретен мрежов интерфейс и различен порт от този по подразбиране (5432), като по този начин избягвате основни опити за свързване от нежелани източници .
Правилното управление на потребителите, било с помощта на защитени пароли, било с ограничаване на достъпа и привилегиите, е друга жизненоважна част от вашите настройки за сигурност. Препоръчително е да зададете възможно най-малко привилегии на всички потребители и да посочите, ако е възможно, източника на връзката.
Можете също да активирате криптиране на данни, било то по време на пренос или покой, като избягвате достъпа до информация на неупълномощени лица.
Регистърът на одита е полезен за разбиране какво се случва или се е случило във вашата база данни. PostgreSQL ви позволява да конфигурирате няколко параметъра за регистриране или дори да използвате разширението pgAudit за тази задача.
Не на последно място, препоръчително е да поддържате базата си данни и сървърите си актуални с най-новите корекции, за да избегнете рискове за сигурността. За целта ClusterControl ви позволява да генерирате оперативни отчети, за да проверите дали имате налични актуализации и дори да ви помогне да актуализирате сървърите на вашите бази данни.
Заключение
Внедряването с висока наличност може да изглежда трудно постижимо, особено когато става въпрос за разбиране на различните архитектури и необходимите компоненти, за да ги конфигурирате правилно.
Ако управлявате HA ръчно, не забравяйте да разгледате Извършване на промени в топологията на репликация за PostgreSQL. Мнозина ще търсят инструменти като ClusterControl, за да помогнат за управлението на внедряването, балансирането на натоварването, преодоляването при отказ, сигурността и други за пълна среда с висока наличност. Можете да изтеглите ClusterControl безплатно за 30 дни, за да видите как може да облекчи тежестта от управлението на инфраструктура на база данни с висока наличност.
Въпреки това изберете да управлявате своите PostgreSQL бази данни с висока наличност, не забравяйте да ни последвате в Twitter или LinkedIn или да се абонирате за нашия бюлетин, за да получавате най-новите актуализации и най-добри практики за управление на настройките на вашата база данни.