Когато разгръщате клъстер на база данни в различни сървъри, вие ще постигнете предимството на репликацията за подобряване на наличността на данни. Въпреки това има нужда да следите процесите и да видите дали те работят или не. Една от програмите, използвани в този процес, е Heartbeat, която има способността да проверява и проверява наличието на ресурси на една или повече системи в даден клъстер. Освен PostgreSQL и файловите системи, за които се съхраняват PostgreSQL данни, DRBD е един от ресурсите, които ще обсъдим в тази статия за това как може да се използва програмата Heartbeat.
HA сърдечен ритъм
Както беше обсъдено по-рано в блога DRBD, високата наличност на данни се постига чрез стартиране на различни копия на сървъра, но обслужване на едни и същи данни. Тези работещи сървърни екземпляри могат да бъдат дефинирани като клъстер по отношение на Heartbeat. По принцип всеки екземпляр на сървъра е физически способен да предоставя същата услуга като другите в този клъстер. Въпреки това, само един екземпляр може активно да предоставя услуга в даден момент с цел осигуряване на висока наличност на данни. Следователно можем да определим другите случаи като „горещи резерви“, които могат да бъдат въведени в експлоатация в случай на повреда на главния. Пакетът Heartbeat може да бъде изтеглен от тази връзка. След като инсталирате този пакет, можете да го конфигурирате да работи с вашата система с процедурата по-долу. Проста структура на конфигурацията на Heartbeat е:
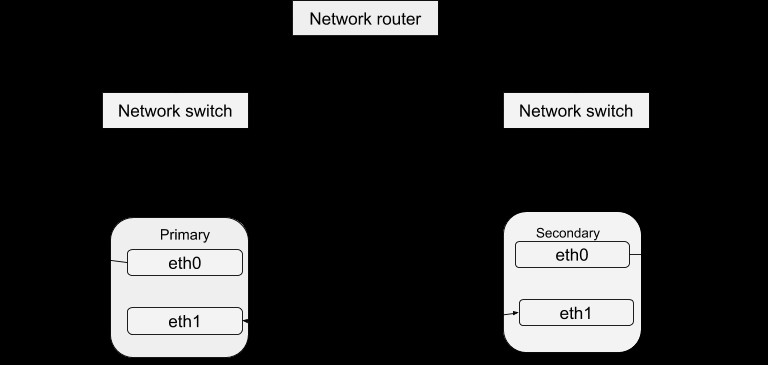
Конфигурация на сърдечния ритъм
Разглеждайки тази директория /etc/ha.d ще намерите някои файлове, които се използват в процеса на конфигуриране. Файлът ha.cf формира основната конфигурация на сърдечния ритъм. Той включва списък на всички възли и времена за идентифициране на неизправност, освен насочване на сърдечния ритъм за това кой тип медийни пътища да се използват и как да ги конфигурирате. Информацията за сигурността на клъстера се записва във файла с ключове за удостоверяване. Записаната информация в тези файлове трябва да бъде идентична за всички хостове в клъстера и това може лесно да се постигне чрез синхронизиране между всички хостове. Това означава, че всяка промяна на информацията в един хост трябва да бъде копирана във всички останали.
Ha.cf файл
Основното очертание на файла ha.cf е
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:този се използва за насочване на сърдечния ритъм върху това кое средство за регистриране на системния журнал трябва да използва за записване на съобщения. Най-често използваните стойности са auth, authpriv, user, local0, syslog и daemon. Можете също да решите да нямате никакви регистрационни файлове, за да можете да зададете стойността на none .i.e.
logfacility none - Keepalive:това е времето между ударите на сърцето, тоест честотата, с която сигналът за сърдечен ритъм се изпраща до другите хостове. В примерния код по-горе е зададено на 3 секунди.
- Мертво време:това е закъснението в секунди, след което възелът се обявява като неуспешен.
- Време на предупреждение:е закъснението в секунди, след което в дневника се записва предупреждение, което показва, че вече не може да се осъществи връзка с възел.
- Initdead:това е времето в секунди за изчакване по време на стартиране на системата, преди да се счита, че другият хост не работи.
- Mcast:това е процедура с определен метод за изпращане на сигнал за сърдечен ритъм. За примерния код по-горе, мрежовият адрес за множествено предаване се използва през ограничено мрежово устройство. За множествен клъстер, адресът за множествено предаване трябва да е уникален за всеки клъстер. Можете също да изберете серийна връзка през мултикаст или ако настроите е по такъв начин, че да има множество мрежови интерфейси, използвайте и двете за сърдечна връзка като примера. Предимството при използването и на двете е да се преодолеят шансовете за преходен отказ, който следователно може да причини невалидно събитие за отказ.
- Auto_failback:това свързва отново сървър, който не е успял да се върне обратно към клъстера, ако стане достъпен. Въпреки това може да предизвика объркване, ако сървърът е включен и след това се появи онлайн в различно време. Във връзка с DRBD, ако не е добре конфигуриран, може да се окажете с повече от един набор от данни в същия сървър. Затова е препоръчително винаги да го изключвате.
- Възел:очертава възела в клъстерната група Heartbeat. Трябва да имате поне 1 възел за всеки.
Допълнителни конфигурации
Можете също да зададете допълнителна информация за конфигурация като:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:това е важно, за да се гарантира, че имате свързаност на публичния интерфейс за сървърите и връзка с друг хост. Важно е да вземете предвид IP адреса, а не името на хоста за машината местоназначение.
- Respawn:това е командата, която се изпълнява, когато възникне грешка.
- Apiauth:е авторитетът за неуспеха. Трябва да конфигурирате потребителски и групов идентификатор, с който ще се изпълни командата. Файлът authkeys съдържа информацията за оторизация за Heartbeat клъстера и този ключ е много уникален за проверка на машини в даден Heartbeat клъстер.
- Deadping:дефинира времето за изчакване преди липса на отговор да задейства неуспех.
Интегриране на сърдечния ритъм с Postgres и DRBD
Както бе споменато по-горе, когато главен сървър се повреди, друг сървър с даден клъстер ще влезе в действие, за да предостави същата услуга. Heartbeat помага при конфигурирането на ресурси, които подобряват избора на сървър в случай на повреда. Той например определя кои отделни сървъри трябва да бъдат изведени или изхвърлени в случай на повреда. Проверявайки във файла haresources в директорията /etc/ha.d, получаваме очертание на ресурсите, които могат да бъдат управлявани. Пътят на ресурсния файл е /etc/ha.d/resource.d и дефиницията на ресурса е в един ред, който е:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(обърнете внимание на белите интервали).
- Drbd1:се отнася до името на предпочитания хост, за да бъде по-секантен сървърът, който обикновено се използва като главен по подразбиране за обработка на услугата. Както беше споменато в блога DRBD, имаме нужда от ресурси за нашия сървър и те са дефинирани в реда като drbddisk, файлова система и postgres. Последното поле е виртуален IP адрес, който трябва да се използва за споделяне на услугата, т.е. свързване към сървъра на Postgres. По подразбиране той ще бъде разпределен на сървъра, който е активен, когато Heartbeat започне. Когато възникне грешка, тези ресурси ще бъдат стартирани на сървъра за архивиране по реда на подреждане, когато се извика съответният скрипт. В настройката скриптът ще превключи DRBD диска на вторичния хост в първичен режим, което кара устройството да чете/записва.
- Файлова система:това ще управлява ресурсите на файловата система и в този случай DRBD е избран, така че ще бъде монтиран по време на извикването на скрипта за ресурси.
- Postgres:това ще стартира или ще управлява Postgres сървъра
Понякога бихте искали да получавате известия по имейл. За да направите това, добавете този ред към файла с ресурси с вашия имейл за получаване на предупредителни текстове:
MailTo:: example@sqldat.com::DRBDFailureЗа да стартирате сърдечния ритъм, можете да изпълните командата
/etc/ha.d/heartbeat startили рестартирайте както основния, така и вторичния сървър. Сега, ако изпълните командата
$ /usr/lib64/heartbeat/hb_standbyТекущият възел ще бъде задействан, за да предаде ресурсите си чисто на другия възел.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаОбработка на грешки на системно ниво
Понякога ядрото на сървъра може да е повредено, което показва потенциален проблем с вашия сървър. Ще трябва да конфигурирате сървъра да се отстранява от клъстера по време на проблем. Този проблем често се нарича паника на ядрото и следователно задейства твърдо рестартиране на вашата машина. Можете да принудително рестартирате, като зададете kernel.panic и kernel.panic_on_oop на контролния файл на ядрото /etc/sysctl.conf. т.е.
kernel.panic_on_oops = 1
kernel.panic = 1Друга възможност е да го направите от командния ред с помощта на командата sysctl, т.е.:
$ sysctl -w kernel.panic=1Можете също да редактирате файла sysctl.conf и да презаредите конфигурационната информация с помощта на тази команда.
sysctl -pСтойността показва броя секунди за изчакване преди рестартиране. След това вторият възел на сърдечния ритъм трябва да открие, че сървърът не работи и след това да превключи хоста за отказване.
Заключение
Heartbeat е подсистема, която позволява избор на вторичен сървър в основна и резервна система, когато активен сървър се повреди. Той също така определя дали всички останали сървъри са живи. Той също така осигурява прехвърляне на ресурси към новия първичен възел



