Управлението на инсталация на PostgreSQL включва проверка и контрол върху широк спектър от аспекти в софтуера/инфраструктурния стек, на който работи PostgreSQL. Това трябва да обхваща:
- Настройка на приложението по отношение на използването на базата данни/транзакциите/връзките
- Код на базата данни (заявки, функции)
- Система за бази данни (производителност, HA, архивиране)
- Хардуер/инфраструктура (дискове, процесор/памет)
Ядрото на PostgreSQL предоставя слоя на базата данни, на който вярваме, че нашите данни ще бъдат съхранявани, обработвани и обслужвани. Той също така предоставя цялата технология за една наистина модерна, ефективна, надеждна и сигурна система. Но често тази технология не е налична като готов за използване, усъвършенстван продукт от бизнес/предприятия в основната дистрибуция на PostgreSQL. Вместо това има много продукти/решения или от общността на PostgreSQL, или от търговски предложения, които отговарят на тези нужди. Тези решения идват или като удобни за потребителя подобрения на основните технологии, или разширения на основните технологии, или дори като интеграция между компонентите на PostgreSQL и други компоненти на системата. В предишния ни блог, озаглавен Десет съвета за навлизане в производство с PostgreSQL, разгледахме някои от тези инструменти, които могат да помогнат за управлението на инсталация на PostgreSQL в производството. В този блог ще разгледаме по-подробно аспектите, които трябва да бъдат обхванати при управлението на инсталация на PostgreSQL в производството, и най-често използваните инструменти за тази цел. Ще разгледаме следните теми:
- Внедряване
- Управление
- Мащабиране
- Мониторинг
Внедряване
В старите времена хората изтегляха и компилираха PostgreSQL на ръка и след това конфигурираха параметрите по време на изпълнение и контрола на потребителския достъп. Все още има някои случаи, в които това може да е необходимо, но тъй като системите узряха и започнаха да се разрастват, възникна необходимостта от по-стандартизирани начини за внедряване и управление на Postgresql. Повечето ОС предоставят пакети за инсталиране, внедряване и управление на PostgreSQL клъстери. Debian е стандартизирал собственото си системно оформление, поддържащо много версии на Postgresql и много клъстери на версия едновременно. postgresql-common debian пакетът предоставя необходимите инструменти. Например, за да създадем нов клъстер (наречен i18n_cluster) за PostgreSQL версия 10 в Debian, можем да го направим, като дадем следните команди:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsСлед това обновете systemd:
$ sudo systemctl daemon-reloadи накрая стартирайте и използвайте новия клъстер:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(обърнете внимание, че Debian обработва различни клъстери чрез използване на различни портове 5432, 5433 и така нататък)
С нарастването на нуждата от по-автоматизирани и масови внедрявания, все повече и повече инсталации използват инструменти за автоматизация като Ansible, Chef и Puppet. Освен автоматизацията и възпроизводимостта на внедряванията, инструментите за автоматизация са страхотни, защото са приятен начин за документиране на внедряването и конфигурацията на клъстер. От друга страна, автоматизацията се е развила, за да се превърне в голямо самостоятелно поле, което изисква квалифицирани хора да пишат, управляват и изпълняват автоматизирани скриптове. Повече информация за предоставянето на PostgreSQL можете да намерите в този блог:Станете PostgreSQL DBA:Осигуряване и внедряване.
Управление
Управлението на жива система включва задачи като:насрочване на архивиране и наблюдение на тяхното състояние, възстановяване след бедствие, управление на конфигурацията, управление на висока наличност и автоматична обработка при отказ. Архивирането на Postgresql клъстер може да се извърши по различни начини. Инструменти на ниско ниво:
- традиционен pg_dump (логическо архивиране)
- Архивиране на ниво файлова система (физическо архивиране)
- pg_basebackup (физическо архивиране)
Или по-високо ниво:
- Барман
- PgBackRest
Всеки от тези начини обхваща различни случаи на използване и сценарии за възстановяване и се различава по сложност. Архивирането на PostgreSQL е тясно свързано с понятията за PITR, WAL архивиране и репликация. През годините процедурата по вземане, тестване и накрая (стискам палци!) използване на архивиране с PostgreSQL се превърна в сложна задача. В този блог може да се намери хубав преглед на решенията за архивиране на PostgreSQL:Най-добрите инструменти за архивиране за PostgreSQL.
Що се отнася до високата наличност и автоматичното преминаване при отказ, основният минимум, който една инсталация трябва да има, за да приложи това, е:
- Работна основна
- Горещ режим на готовност, приемащ WAL поточно от основния
- В случай на неуспешен първичен, метод, който да каже на основния, че вече не е първичен (понякога наричан STONITH)
- Механизъм на сърдечен ритъм за проверка за свързаност между двата сървъра и здравето на основния
- Метод за извършване на отказ (напр. чрез pg_ctl популяризиране или файл за задействане)
- Автоматизирана процедура за възстановяване на стария първичен като нов режим на готовност:След като се открие прекъсване или неизправност на основния, тогава режимът на готовност трябва да бъде популяризиран като нов първичен. Старият първичен вече не е валиден или използваем. Така че системата трябва да има начин да се справи с това състояние между преодоляването на отказ и повторното създаване на стария първичен сървър като нов режим на готовност. Това състояние се нарича изродено състояние, а PostgreSQL предоставя инструмент, наречен pg_rewind, за да се ускори процеса на връщане на старото основно в състояние на синхронизиране от новото основно.
- Метод за извършване на превключване при поискване/планирано превключване
Широко използван инструмент, който се справя с всичко по-горе, е Repmgr. Ще опишем минималната настройка, която ще позволи успешно превключване. Започваме с работещ PostgreSQL 10.4 първичен, работещ на FreeBSD 11.1, ръчно изграден и инсталиран, и repmgr 4.0 също ръчно изграден и инсталиран за тази версия (10.4). Ще използваме два хоста с имена fbsd (192.168.1.80) и fbsdclone (192.168.1.81) с идентични версии на PostgreSQL и repmgr. На основния (първоначално fbsd, 192.168.1.80) се уверяваме, че са зададени следните параметри на PostgreSQL:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' След това създаваме потребител на repmgr (като суперпотребител) и база данни:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgrи настройте базиран на хост контрол на достъпа в pg_hba.conf, като поставите следните редове отгоре:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustНие се уверяваме, че сме настроили влизане без парола за потребител repmgr във всички възли на клъстера, в нашия случай fbsd и fbsdclone, като задаваме authorized_keys в .ssh и след това споделяме .ssh. След това създаваме repmrg.conf на основния като:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'След това регистрираме основния:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredИ проверете състоянието на клъстера:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Сега работим в режим на готовност, като задаваме repmgr.conf както следва:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Също така се уверяваме, че директорията с данни, посочена точно в горния ред, съществува, е празна и има правилните разрешения:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataСега трябва да клонираме към нашия нов режим на готовност:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"И стартирайте режим на готовност:
example@sqldat.com:~ % pg_ctl -D data startВ този момент репликацията трябва да работи както се очаква, проверете това, като потърсите pg_stat_replication (fbsd) и pg_stat_wal_receiver (fbsdclone). Следващата стъпка е да регистрирате режим на готовност:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerСега можем да получим състоянието на клъстера или на резервния, или на основния и да проверим дали резервният режим е регистриран:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Сега да предположим, че искаме да извършим планирано ръчно превключване, за да напр. да върши някаква административна работа на възел fbsd. На възела в режим на готовност изпълняваме следната команда:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyПревключването е извършено успешно! Нека видим какво дава клъстерното шоу:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Двата сървъра са си разменили ролите! Repmgr предоставя демон repmgrd, който осигурява наблюдение, автоматично преминаване при отказ, както и известия/известия. Комбинирайки repmgrd с pgbouncer, е възможно да се приложи автоматична актуализация на информацията за връзката на базата данни, като по този начин се осигури защита за неуспешния първичен (предотвратяване на неуспешния възел от всякакво използване от приложението), както и осигуряване на минимално време за престой на приложението. При по-сложни схеми друга идея е да се комбинира Keepalived с HAProxy върху pgbouncer и repmgr, за да се постигне:
- балансиране на натоварването (мащабиране)
- висока наличност
Обърнете внимание, че ClusterControl също управлява отказоустойчивостта на настройките за репликация на PostgreSQL и интегрира HAProxy и VirtualIP за автоматично пренасочване на клиентски връзки към работния главен. Повече информация можете да намерите в тази бяла книга за PostgreSQL Automation.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаМащабиране
От PostgreSQL 10 (и 11) все още няма начин да има мулти-главна репликация, поне не от ядрото на PostgreSQL. Това означава, че само активността за избор (само за четене) може да бъде увеличена. Мащабирането в PostgreSQL се постига чрез добавяне на повече горещи режими на готовност, като по този начин се осигуряват повече ресурси за дейност само за четене. С repmgr е лесно да добавите нов режим на готовност, както видяхме по-рано чрез клониране в режим на готовност и регистър в режим на готовност команди. Добавените (или премахнати) режими на готовност трябва да бъдат известни на конфигурацията на балансира на натоварването. HAProxy, както бе споменато по-горе в темата за управление, е популярен балансьор на натоварване за PostgreSQL. Обикновено той е съчетан с Keepalived, който предоставя виртуален IP чрез VRRP. Приятен преглед на използването на HAProxy и Keepalived заедно с PostgreSQL можете да намерите в тази статия:Балансиране на натоварването на PostgreSQL с помощта на HAProxy &Keepalived.
Наблюдение
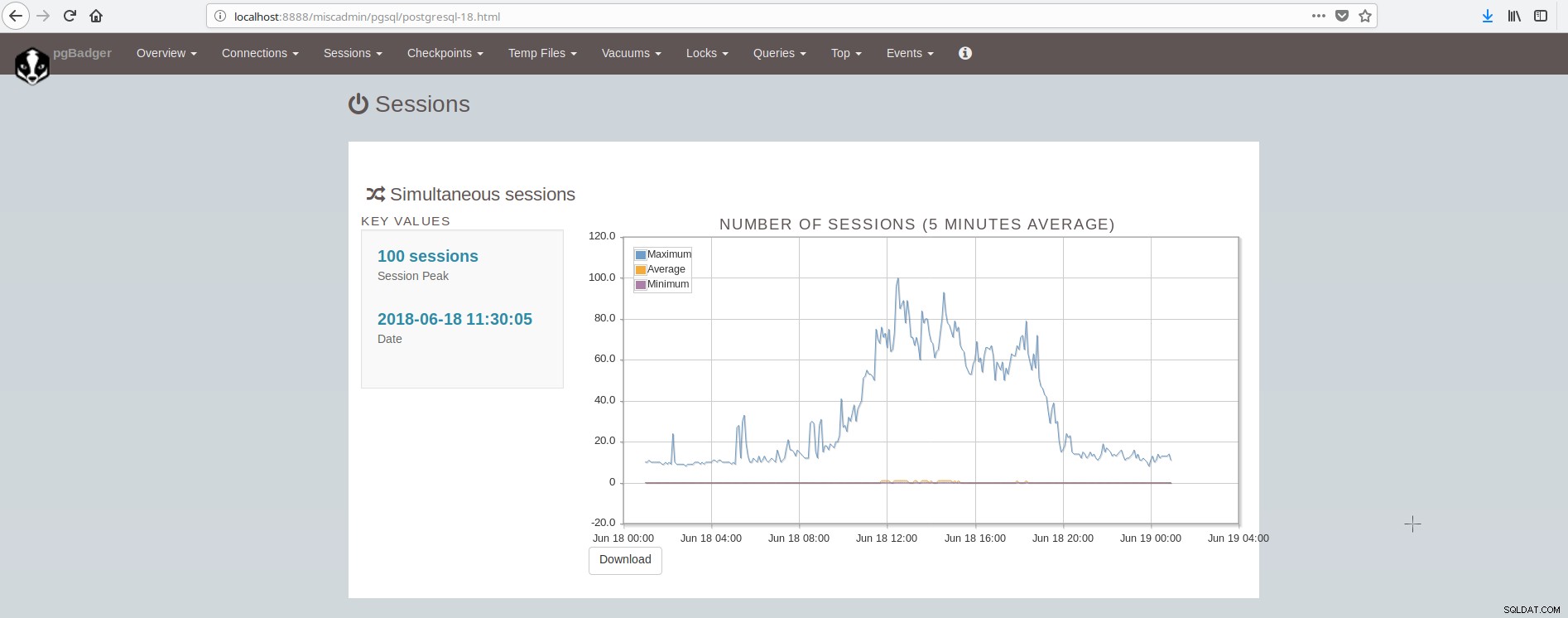
Преглед на това какво да наблюдавате в PostgreSQL можете да намерите в тази статия:Ключови неща за наблюдение в PostgreSQL – Анализиране на вашето работно натоварване. Има много инструменти, които могат да осигурят мониторинг на системата и postgresql чрез плъгини. Някои инструменти покриват областта на представяне на графична диаграма на исторически стойности (munin), други инструменти покриват областта на наблюдение на данни в реално време и предоставяне на сигнали на живо (nagios), докато някои инструменти покриват и двете области (zabbix). Списък с такива инструменти за PostgreSQL можете да намерите тук:https://wiki.postgresql.org/wiki/Monitoring. Популярен инструмент за наблюдение офлайн (базирано на регистрационни файлове) е pgBadger. pgBadger е скрипт на Perl, който работи чрез анализиране на дневника на PostgreSQL (който обикновено обхваща дейността за един ден), извличане на информация, изчисляване на статистически данни и накрая създава фантастична html страница, представяща резултатите. pgBadger не ограничава настройката log_line_prefix, може да се адаптира към вашия вече съществуващ формат. Например, ако сте задали във вашия postgresql.conf нещо като:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'тогава командата pgbadger за анализиране на регистрационния файл и получаване на резултатите може да изглежда така:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger предоставя отчети за:
- Общ преглед (предимно SQL трафик)
- Връзки (за секунда, за база данни/потребител/хост)
- Сесии (брой, времена на сесия, за база данни/потребител/хост/приложение)
- Контролни точки (буфери, wal файлове, активност)
- Използване на временни файлове
- Вакуум/Анализиране на активността (на таблица, кортежи/страници са премахнати)
- Ключи
- Заявки (по тип/база данни/потребител/хост/приложение, продължителност по потребител)
- Най-горе (запитвания:най-бавно, отнемащо време, по-често, нормализирано най-бавно)
- Събития (Грешки, Предупреждения, Фатални и т.н.)
Екранът, показващ сесиите, изглежда така:
Както можем да заключим, средната инсталация на PostgreSQL трябва да интегрира и да се грижи за много инструменти, за да има модерна надеждна и бърза инфраструктура и това е доста сложно за постигане, освен ако няма големи екипи, участващи в postgresql и системна администрация. Прекрасен пакет, който прави всичко по-горе и повече, е ClusterControl.