Използването на репликация за вашите PostgreSQL бази данни може да бъде полезно не само за осигуряване на среда с висока наличност и отказоустойчивост, но и за подобряване на производителността на вашата система чрез балансиране на трафика между резервните възли. В тази първа част на блога от две части ще видим някои концепции, свързани с репликацията на PostgreSQL.
Методи за репликации в PostgreSQL
Има различни методи за репликиране на данни в PostgreSQL, но тук ще се съсредоточим върху двата основни метода:поточно репликация и логическа репликация.
Поточно репликация
Поточно репликацията на PostgreSQL, най-често срещаната PostgreSQL репликация, е физическа репликация, която репликира промените на ниво байт по байт, създавайки идентично копие на базата данни в друг сървър. Той се основава на метода за доставка на трупи. WAL записите се преместват директно от един сървър на база данни в друг, за да бъдат приложени. Можем да кажем, че е един вид непрекъснат PITR.
Това прехвърляне на WAL се извършва по два различни начина, чрез прехвърляне на WAL записи един файл (сегмент на WAL) наведнъж (прехвърляне на дневник на базата на файлове) и чрез прехвърляне на WAL записи (WAL файл се състои от WAL записи) в движение (доставка базирана на записи), между основен сървър и един или повече, отколкото на резервни сървъри, без да се чака запълването на WAL файла.
На практика процес, наречен WAL приемник, работещ на сървъра в режим на готовност, ще се свърже с основния сървър чрез TCP/IP връзка. В основния сървър съществува друг процес, наречен WAL sender, и отговаря за изпращането на WAL регистрите до сървъра в режим на готовност, когато се случват.
Основна поточно репликация може да бъде представена по следния начин:
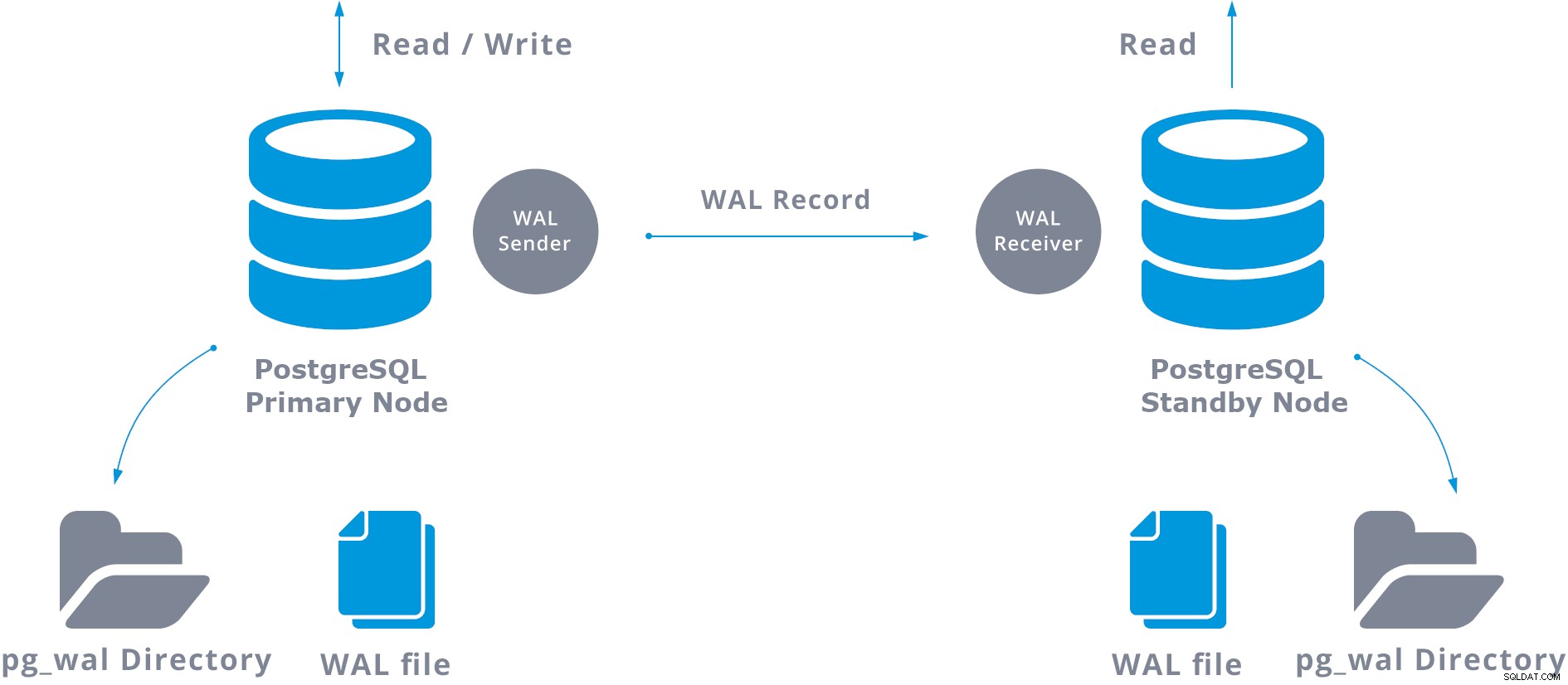
Когато конфигурирате поточно репликация, имате опцията да активирате WAL архивиране. Това не е задължително, но е изключително важно за стабилна настройка на репликация, тъй като е необходимо да се избягва основният сървър да рециклира стари WAL файлове, които все още не са приложени към сървъра в режим на готовност. Ако това се случи, ще трябва да пресъздадете репликата от нулата.
Логическа репликация
Логическата репликация на PostgreSQL е метод за репликиране на обекти с данни и техните промени въз основа на тяхната идентичност на репликация (обикновено първичен ключ). Базира се на режим на публикуване и абонамент, при който един или повече абонати се абонират за една или повече публикации на възел на издател.
Публикацията е набор от промени, генерирани от таблица или група от таблици. Възелът, където е дефинирана публикация, се нарича издател. Абонаментът е долната страна на логическата репликация. Възелът, където е дефиниран абонаментът, се нарича абонат и той дефинира връзката с друга база данни и набор от публикации (една или повече), за които иска да се абонира. Абонатите изтеглят данни от публикациите, за които се абонират.
Логическата репликация е изградена с архитектура, подобна на физическата поточно репликация. Реализира се чрез процеси "walsender" и "apply". Процесът на walsender стартира логическото декодиране на WAL и зарежда стандартния плъгин за логическо декодиране. Плъгинът преобразува промените, прочетени от WAL към протокола за логическа репликация и филтрира данните според спецификацията на публикацията. След това данните се прехвърлят непрекъснато с помощта на протокола за поточно репликация към работника за прилагане, който картографира данните в локални таблици и прилага отделните промени при получаването им в правилен транзакционен ред.
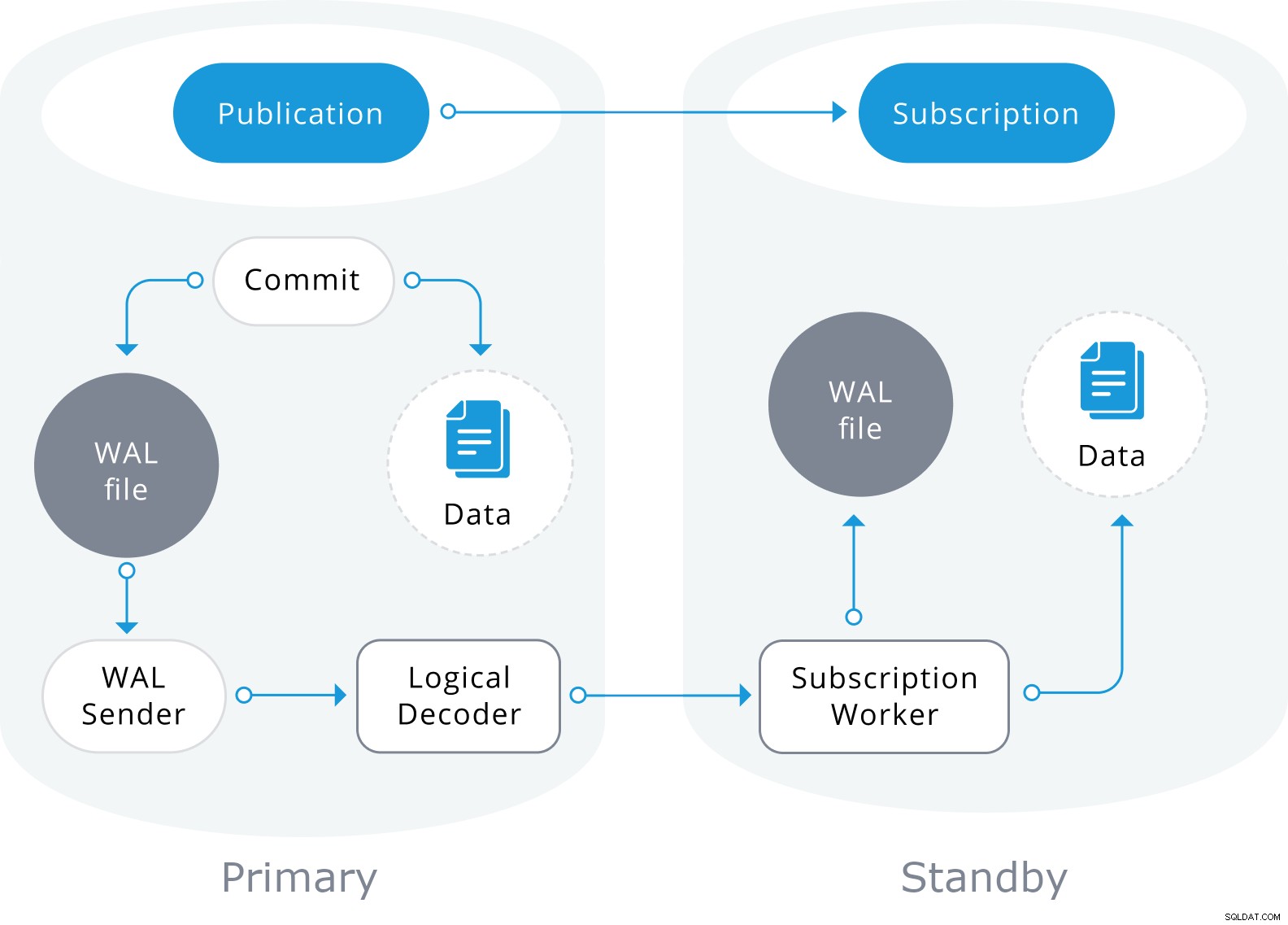
Логическата репликация започва с правене на моментна снимка на данните в базата данни на издателя и копиране на това на абоната. Първоначалните данни в съществуващите абонирани таблици се заснемат и копират в паралелен екземпляр на специален вид процес на прилагане. Този процес ще създаде свой собствен временен слот за репликация и ще копира съществуващите данни. След като съществуващите данни бъдат копирани, работникът влиза в режим на синхронизация, който гарантира, че таблицата е приведена в синхронизирано състояние с основния процес на прилагане чрез поточно предаване на всички промени, настъпили по време на първоначалното копиране на данни, като се използва стандартна логическа репликация. След като синхронизацията бъде извършена, контролът върху репликацията на таблицата се връща на основния процес на прилагане, където репликацията продължава както обикновено. Промените на издателя се изпращат на абоната, когато се извършват в реално време.
Режими на репликация в PostgreSQL
Репликацията в PostgreSQL може да бъде синхронна или асинхронна.
Асинхронна репликация
Това е режимът по подразбиране. Тук е възможно да има някои транзакции, ангажирани в първичния възел, които все още не са репликирани на сървъра в режим на готовност. Това означава, че има вероятност от потенциална загуба на данни. Предполага се, че това забавяне в процеса на записване е много малко, ако сървърът в режим на готовност е достатъчно мощен, за да се справи с натоварването. Ако този малък риск от загуба на данни не е приемлив за компанията, вместо това можете да използвате синхронна репликация.
Синхронна репликация
Всяко записване на транзакция за запис ще изчака до потвърждението, че записването е било записано в дневника за предварителна запис на диска както на основния, така и на резервния сървър. Този метод минимизира възможността от загуба на данни. За да възникне загуба на данни, ще трябва и основният, и резервният да се провалят едновременно.
Недостатъкът на този метод е същият за всички синхронни методи, тъй като при този метод времето за отговор за всяка транзакция на запис се увеличава. Това се дължи на необходимостта да се изчака до всички потвърждения, че транзакцията е извършена. За щастие транзакциите само за четене няма да бъдат засегнати от това, но; само транзакциите за запис.
Висока наличност за PostgreSQL репликация
Високата наличност е изискване за много системи, без значение каква технология използваме, и има различни подходи за постигане на това с помощта на различни инструменти.
Балансиране на натоварването
Балансьорите на натоварване са инструменти, които могат да се използват за управление на трафика от вашето приложение, за да извлечете максимума от архитектурата на вашата база данни. Той не само е полезен за балансиране на натоварването на нашите бази данни, но също така помага на приложенията да бъдат пренасочени към наличните/здравословни възли и дори да посочат портове с различни роли.
HAProxy е средство за балансиране на натоварването, което разпределя трафика от един източник към една или повече дестинации и може да дефинира специфични правила и/или протоколи за тази задача. Ако някоя от дестинациите спре да отговаря, тя се маркира като офлайн и трафикът се изпраща към останалите налични дестинации. Наличието само на един възел на Load Balancer ще генерира единична точка на отказ, така че за да избегнете това, трябва да разположите поне два HAProxy възела и да конфигурирате Keepalived между тях.
Keepalived е услуга, която ни позволява да конфигурираме виртуален IP в рамките на активна/пасивна група сървъри. Този виртуален IP се присвоява на активен сървър. Ако този сървър не успее, IP адресът автоматично се мигрира към „Вторичния“ пасивен сървър, което му позволява да продължи да работи със същия IP по прозрачен за системите начин.
Подобряване на производителността при репликация на PostgreSQL
Ефективността винаги е важна във всяка система. Ще трябва да използвате добре наличните ресурси, за да осигурите възможно най-доброто време за реакция и има различни начини да направите това. Всяко свързване към база данни консумира ресурси, така че един от начините за подобряване на производителността на вашата PostgreSQL база данни е като имате добър пул за връзки между вашето приложение и сървърите на базата данни.
Пулери за връзки
Обединяването на връзки е метод за създаване на пул от връзки и повторното им използване, като се избягва непрекъснатото отваряне на нови връзки към базата данни, което значително ще увеличи производителността на вашите приложения. PgBouncer е популярен пул за връзки, създаден за PostgreSQL.
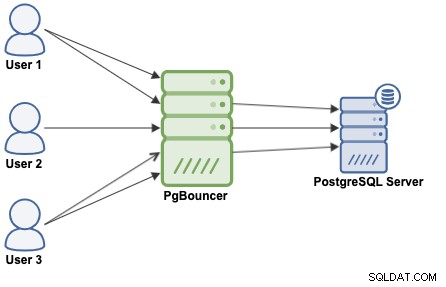
PgBouncer действа като PostgreSQL сървър, така че просто трябва да получите достъп до вашата база данни използвайки информацията на PgBouncer (IP адрес/име на хост и порт), и PgBouncer ще създаде връзка със сървъра на PostgreSQL или ще използва повторно такава, ако съществува.
Когато PgBouncer получи връзка, той извършва удостоверяване, което зависи от метода, посочен в конфигурационния файл. PgBouncer поддържа всички механизми за удостоверяване, които PostgreSQL сървърът поддържа. След това PgBouncer проверява за кеширана връзка със същата комбинация потребителско име+база данни. Ако е намерена кеширана връзка, тя връща връзката към клиента, ако не, създава нова връзка. В зависимост от конфигурацията на PgBouncer и броя на активните връзки е възможно новата връзка да бъде поставена на опашка, докато може да бъде създадена или дори прекратена.
С всички тези споменати концепции във втората част на този блог ще видим как можете да ги комбинирате, за да имате добра среда за репликация в PostgreSQL.