В първата част на този блог споменахме някои важни концепции, свързани с добра среда за репликация на PostgreSQL. Сега нека видим как да комбинираме всички тези неща заедно по лесен начин с помощта на ClusterControl. За това ще приемем, че имате инсталиран ClusterControl, но ако не, можете да отидете на официалния сайт или да се обърнете към официалната документация, за да го инсталирате.
Разгръщане на поточно репликация на PostgreSQL
За да извършите разгръщане на PostgreSQL клъстер от ClusterControl, изберете опцията Разгръщане и следвайте инструкциите, които се появяват.
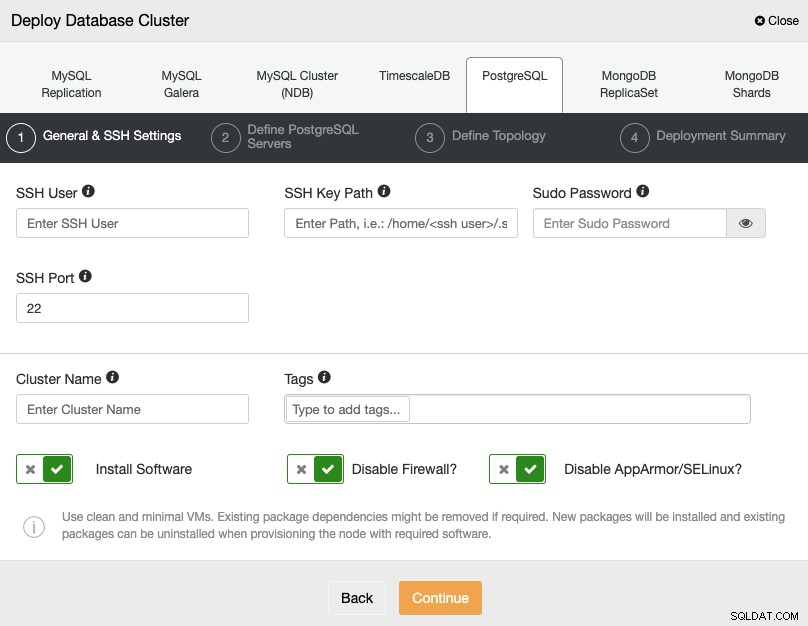
Когато избирате PostgreSQL, трябва да посочите потребителя, ключа или паролата и Порт за свързване чрез SSH към вашите сървъри. Можете също да добавите име за вашия нов клъстер и да посочите дали искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
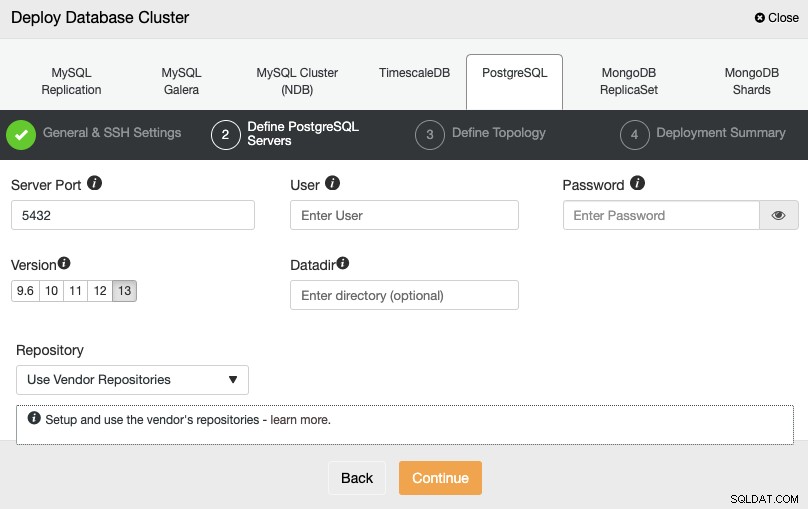
След като настроите информацията за SSH достъп, трябва да дефинирате идентификационните данни за базата данни , версия и datadir (по избор). Можете също да посочите кое хранилище да използвате.
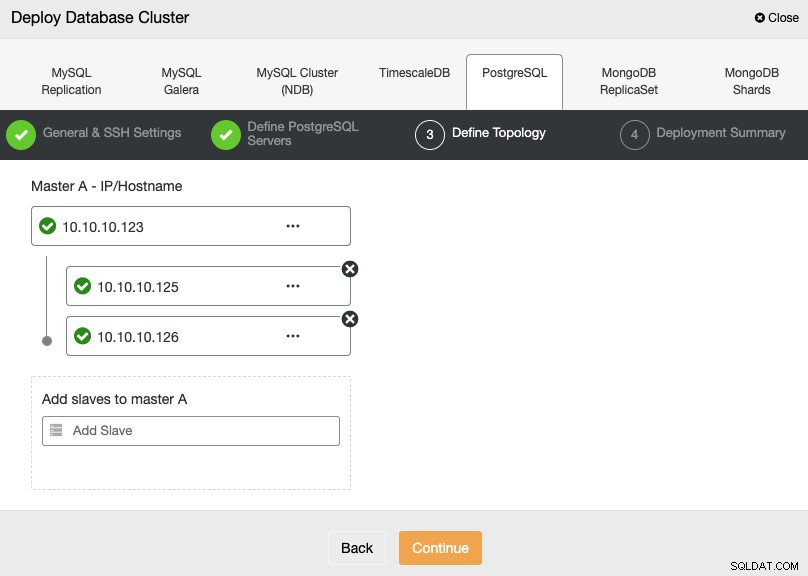
В следващата стъпка трябва да добавите вашите сървъри към клъстера, който ще създадете, използвайки IP адреса или името на хоста.
В последната стъпка можете да изберете дали репликацията ви ще бъде синхронна или Асинхронно и след това просто натиснете Разгръщане.
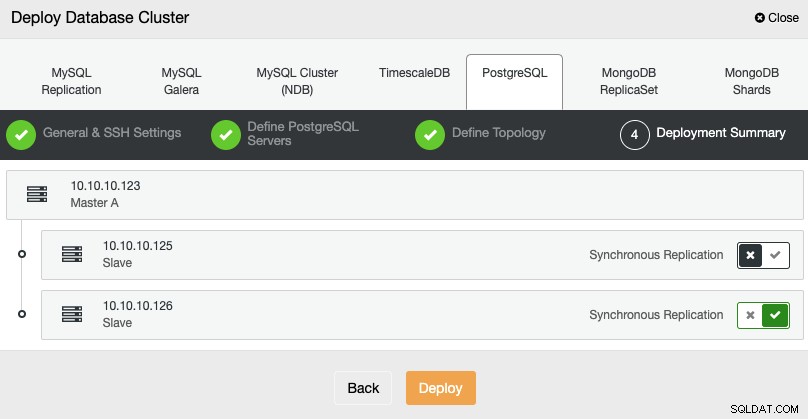
След като задачата приключи, можете да видите своя нов PostgreSQL клъстер в главен екран на ClusterControl.

Сега имате създаден клъстер, можете да изпълнявате няколко задачи върху него, като добавяне на балансьор на натоварване (HAProxy), пул за свързване (PgBouncer) или нов подчинен синхронен или асинхронен репликация.
Добавяне на подчинени синхронни и асинхронни репликации
Отидете на ClusterControl -> Cluster Actions -> Add Replication Slave.
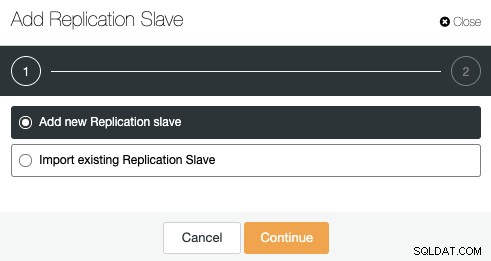
Можете да добавите ново подчинено устройство за репликация или дори да импортирате съществуващ. Нека изберем първата опция и да продължим.
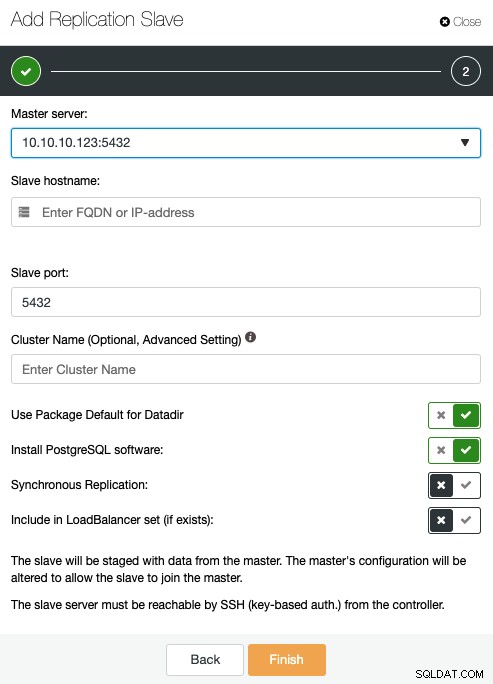
Тук трябва да посочите главния сървър, IP адрес или име на хост на новият подчинен за репликация, порт и ако искате ClusterControl, инсталирайте софтуера или включете този възел в съществуващ балансьор на натоварване. Можете също да конфигурирате репликацията да бъде синхронна или асинхронна.
Сега имате своя PostgreSQL клъстер на място със съответните реплики, нека видим как да подобрим производителността чрез добавяне на пул за връзки.
Разгръщане на PgBouncer
Отидете на ClusterControl -> Изберете PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer -> PgBouncer. Тук можете да разположите нов възел PgBouncer, който ще бъде разгърнат в избрания възел на базата данни, или дори да импортирате съществуващ PgBouncer.
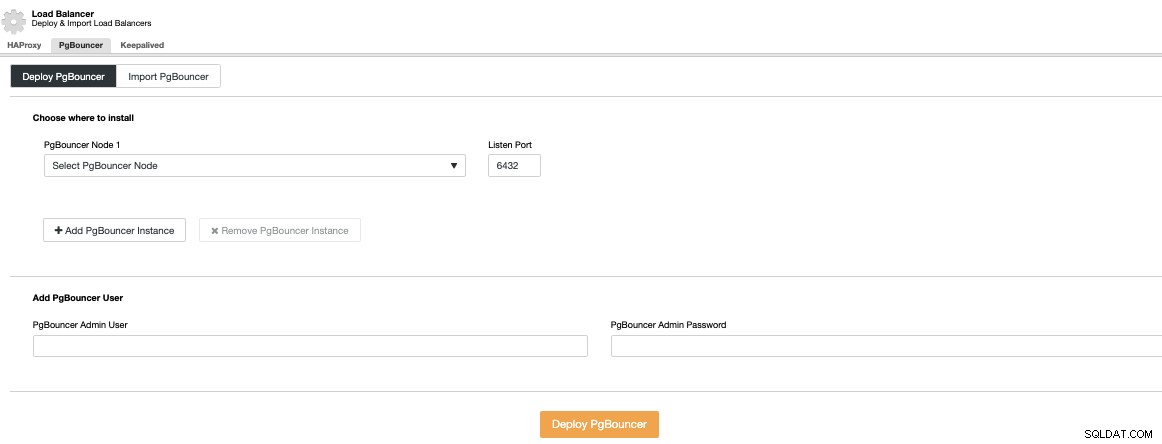
Ще трябва да посочите IP адрес или име на хост, порта за слушане и Удостоверения за PgBouncer. Когато натиснете Deploy PgBouncer, ClusterControl ще получи достъп до възела, ще инсталира и конфигурира всичко без никаква ръчна намеса.
Можете да наблюдавате напредъка в секцията за активност на ClusterControl. Когато приключи, трябва да създадете новия пул. За това отидете на ClusterControl -> Изберете PostgreSQL Cluster -> Nodes -> PgBouncer възел.
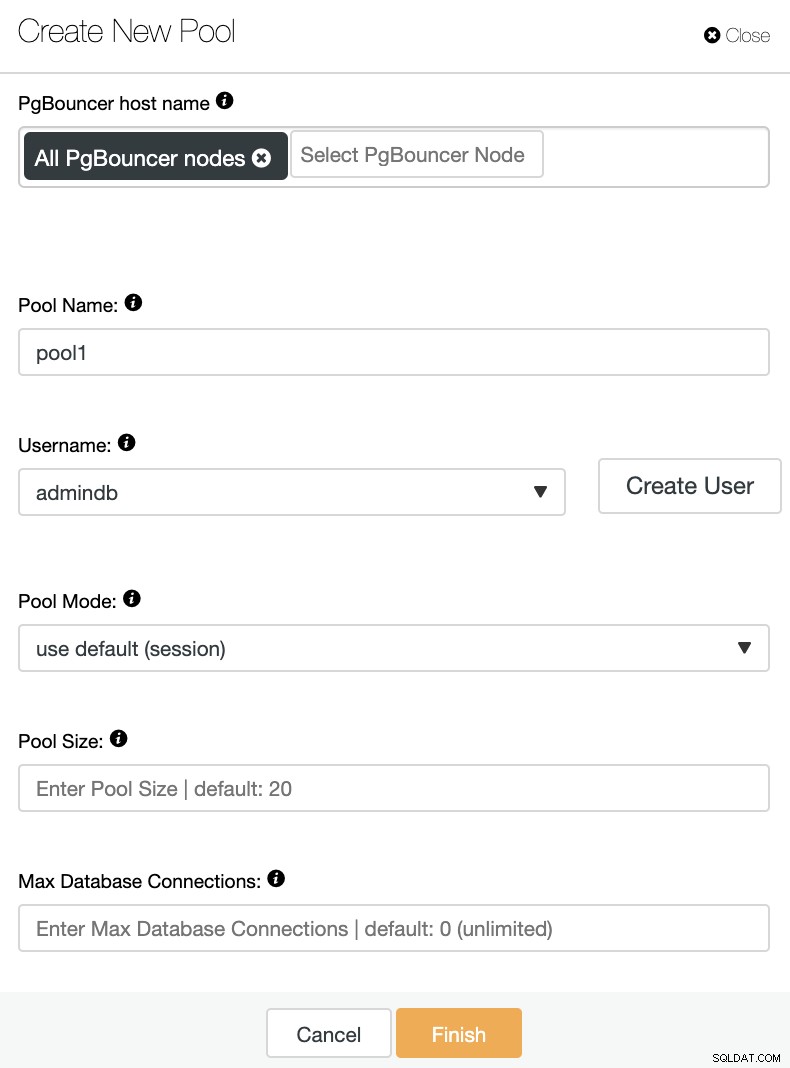
Ще трябва да добавите следната информация:
-
Име на хост PgBouncer:Изберете хостовете на възела, за да създадете пула за връзки.
-
Име на пул:Имената на пула и базата данни трябва да са еднакви.
-
Потребителско име: Изберете потребител от основния възел на PostgreSQL или създайте нов.
-
Режим на пул:Може да бъде:сесия (по подразбиране), транзакция или обединяване на оператори.
-
Размер на пул:максимален размер на пуловете за тази база данни. Стойността по подразбиране е 20.
-
Максимален брой връзки към базата данни:Конфигурирайте максимум за цялата база данни. Стойността по подразбиране е 0, което означава неограничено.
Сега трябва да можете да видите пула в секцията Node.
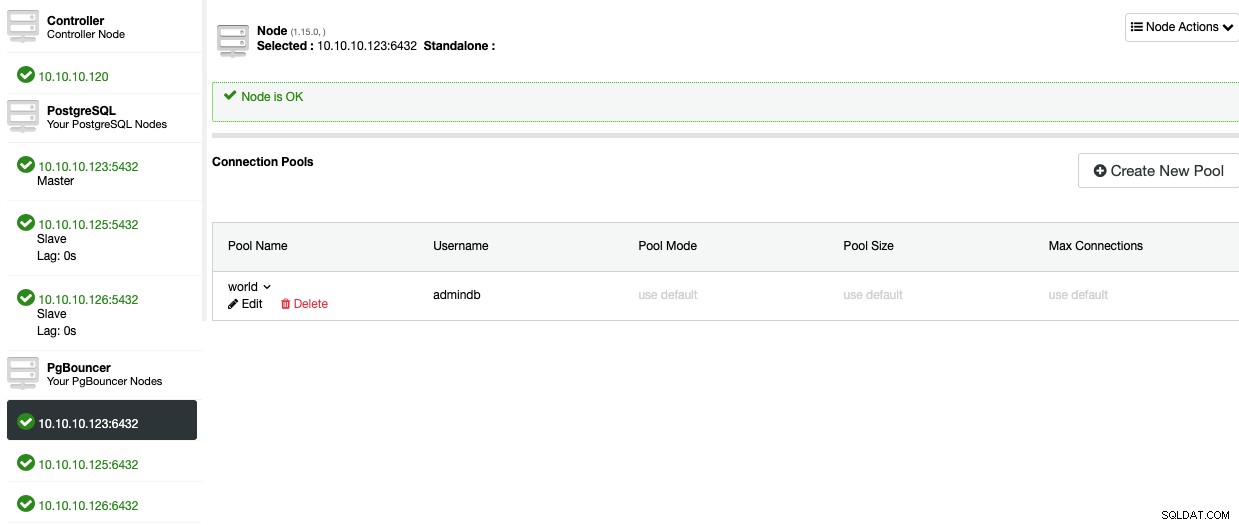
За да добавите висока достъпност към вашата база данни PostgreSQL, нека да видим как да разположите балансиране на натоварването.
Разгръщане на Load Balancer
За да извършите разгръщане на балансиране на натоварването, изберете опцията Добавяне на балансьор на натоварване в менюто Действия на клъстера и попълнете исканата информация.
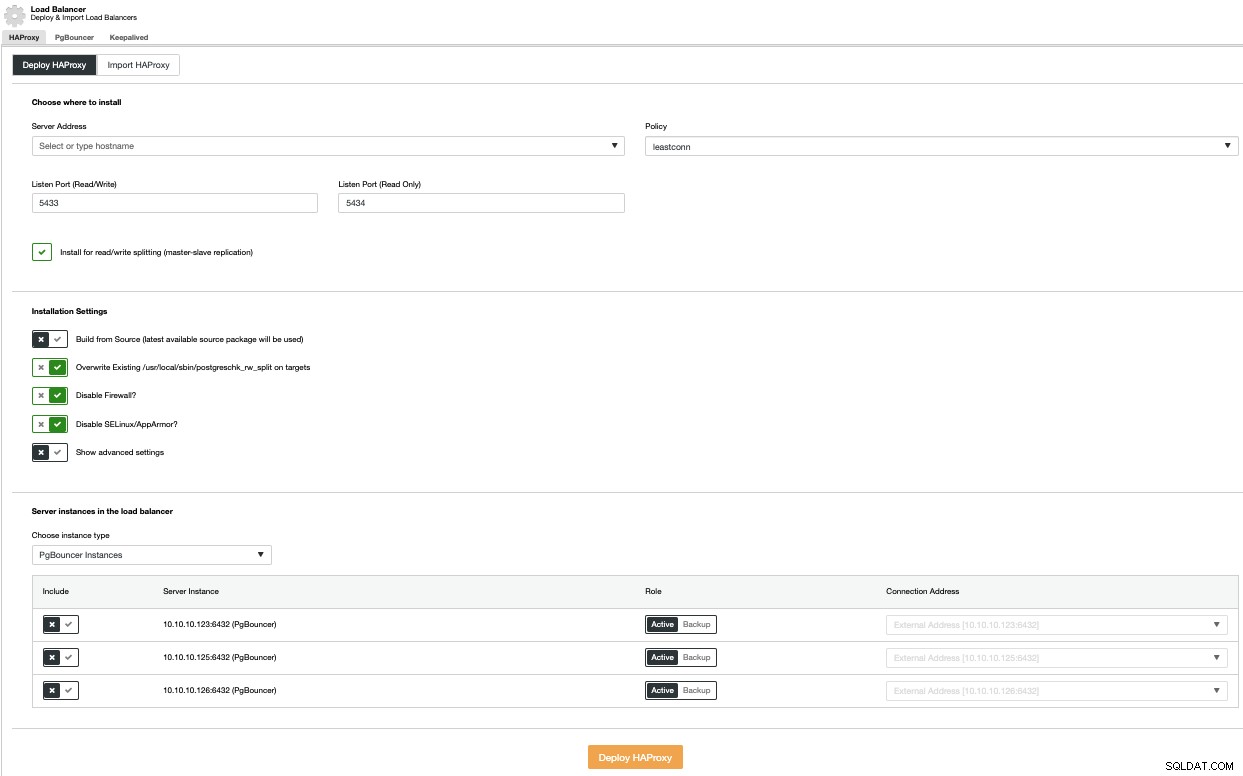
Трябва да добавите IP или име на хост, порт, политика и възлите ще използвате. Ако използвате PgBouncer, можете да го изберете в комбинираното поле за тип екземпляр.
За да избегнете една точка на отказ, трябва да разположите поне два HAProxy възела и да използвате Keepalived, който ви позволява да използвате виртуален IP адрес във вашето приложение, който е присвоен на активния HAProxy възел. Ако този възел не успее, виртуалният IP адрес ще бъде мигриран към вторичния балансьор на натоварване, така че приложението ви все още може да работи както обикновено.
Поддържано разполагане
За да извършите разгръщане с Keepalived, изберете опцията Добавяне на Load Balancer в менюто Действия на клъстера и след това отидете в раздела Keepalived.
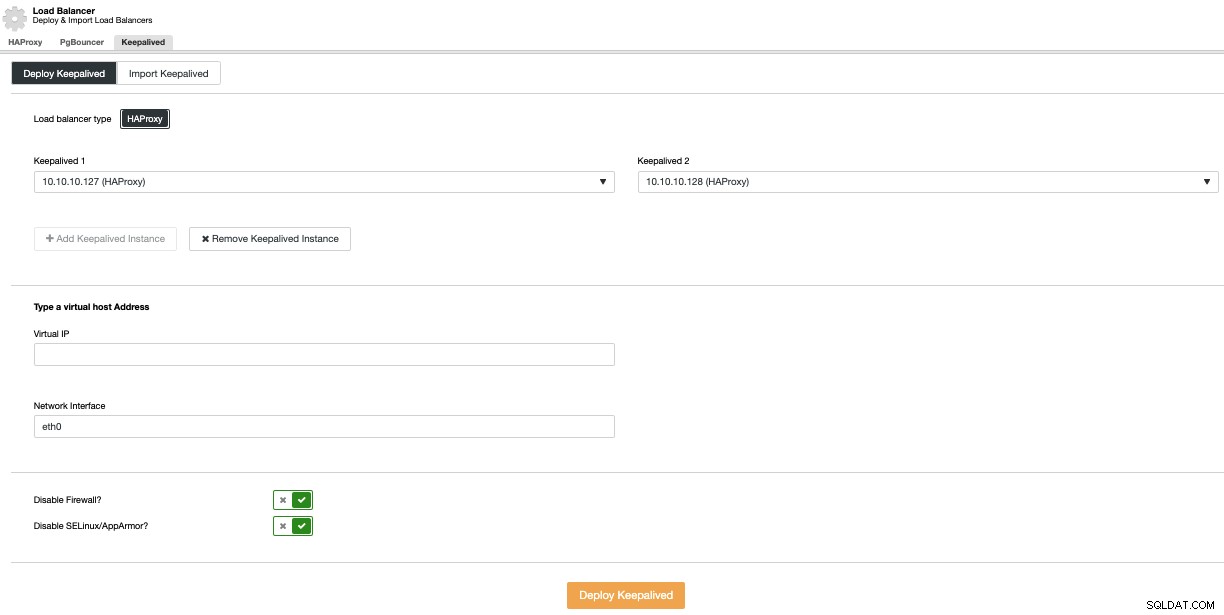
Тук изберете HAProxy възлите и посочете виртуалния IP адрес, който ще да се използва за достъп до базата данни (или пул за свързване).
В този момент трябва да имате следната топология:
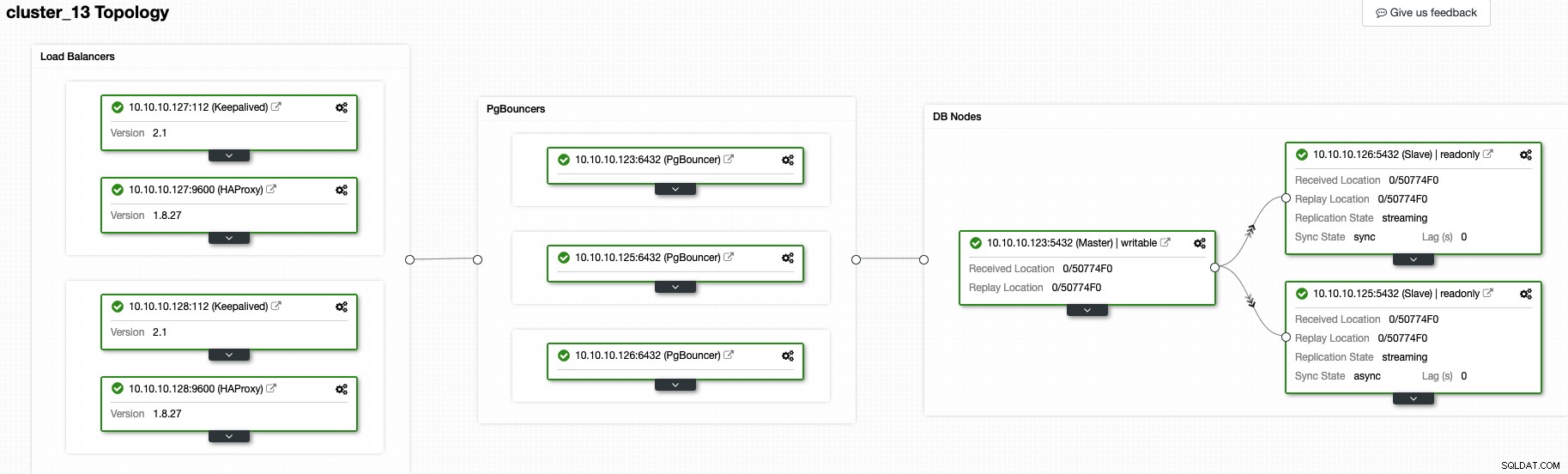
И това означава:HAProxy + Keepalived -> PgBouncer -> възли на PostgreSQL база данни , това е добра топология за вашия PostgreSQL клъстер.
Функция за автоматично възстановяване на ClusterControl
В случай на неуспех, ClusterControl ще повиши най-напредналия резервен възел до основен, както и ще ви уведоми за проблема. Освен това не успява да се репликира върху останалата част от възела в режим на готовност от новия първичен сървър.
По подразбиране HAProxy е конфигуриран с два различни порта:за четене-запис и само за четене. В порта за четене и запис имате своя първичен възел на базата данни (или PgBouncer) като онлайн, а останалите възли като офлайн, а в порта само за четене имате както основния, така и резервния възел онлайн.
Когато HAProxy открие, че един от вашите възли не е достъпен, той автоматично го маркира като офлайн и не го взема предвид за изпращане на трафик към него. Откриването се извършва чрез скриптове за проверка на здравето, които са конфигурирани от ClusterControl по време на внедряването. Те проверяват дали екземплярите са актуални, дали са в процес на възстановяване или са само за четене.
Когато ClusterControl популяризира възел в режим на готовност, HAProxy маркира стария първичен като офлайн за двата порта и поставя повишения възел онлайн в порта за четене и запис.
Ако вашият активен HAProxy, на който е присвоен виртуален IP адрес, към който се свързват системите ви, не успее, Keepalived мигрира този IP адрес към вашия пасивен HAProxy автоматично. Това означава, че вашите системи могат да продължат да функционират нормално.
Заключение
Както можете да видите, наличието на добра топология на PostgreSQL е лесно, ако използвате ClusterControl и ако следвате основните концепции за най-добри практики за репликация на PostgreSQL. Разбира се, най-добрата среда зависи от работното натоварване, хардуера, приложението и т.н., но можете да го използвате като пример и да премествате парчетата, както ви е необходимо.