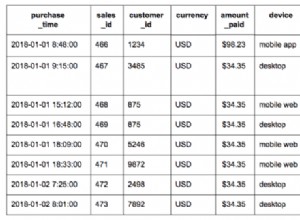
Трябва да актуализирам таблици от 1 или 2 милиарда реда с различни стойности за всеки ред. Всяко изпълнение прави ~100 милиона промени (10%). Първият ми опит беше да ги групирам в транзакция от 300K актуализации директно на конкретен дял, тъй като Postgresql не винаги оптимизира подготвените заявки, ако използвате дялове.
- Транзакции на куп от „UPDATE myTable SET myField=value WHEREmyId=id“
Дава 1500 актуализации/сек. което означава, че всяко бягане ще отнеме поне 18 часа. - HOT решение за актуализации, както е описано тук с FILLFACTOR=50. Дава 1600 актуализации/сек. Използвам SSD, така че това е скъпо подобрение, тъй като удвоява размера за съхранение.
- Вмъкнете във временна таблица с актуализирана стойност и ги обединете след това с UPDATE...FROM дава 18 000 актуализации/сек. ако направя VACUUM за всеки дял; 100 000 нагоре/сек иначе. Браво.
Ето тази последователност от операции:
CREATE TEMP TABLE tempTable (id BIGINT NOT NULL, field(s) to be updated,
CONSTRAINT tempTable_pkey PRIMARY KEY (id));
Натрупване на куп актуализации в буфер в зависимост от наличната RAM, когато е запълнена, или трябва да промените таблицата/раздела, или завърши:
COPY tempTable FROM buffer;
UPDATE myTable a SET field(s)=value(s) FROM tempTable b WHERE a.id=b.id;
COMMIT;
TRUNCATE TABLE tempTable;
VACUUM FULL ANALYZE myTable;
Това означава, че едно изпълнение вече отнема 1,5 часа вместо 18 часа за 100 милиона актуализации, включително вакуум. За да спестите време, не е необходимо да правите вакуум ПЪЛЕН в края, но дори и бързото редовно вакуумиране е полезно, за да контролирате идентификатора на транзакцията си в базата данни и да не получите нежелано автоматично вакуумиране в пиковите часове.