Пролетно маршрутизиране на транзакции
Първо, ще създадем DataSourceType Java Enum, който дефинира нашите опции за маршрутизиране на транзакции:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
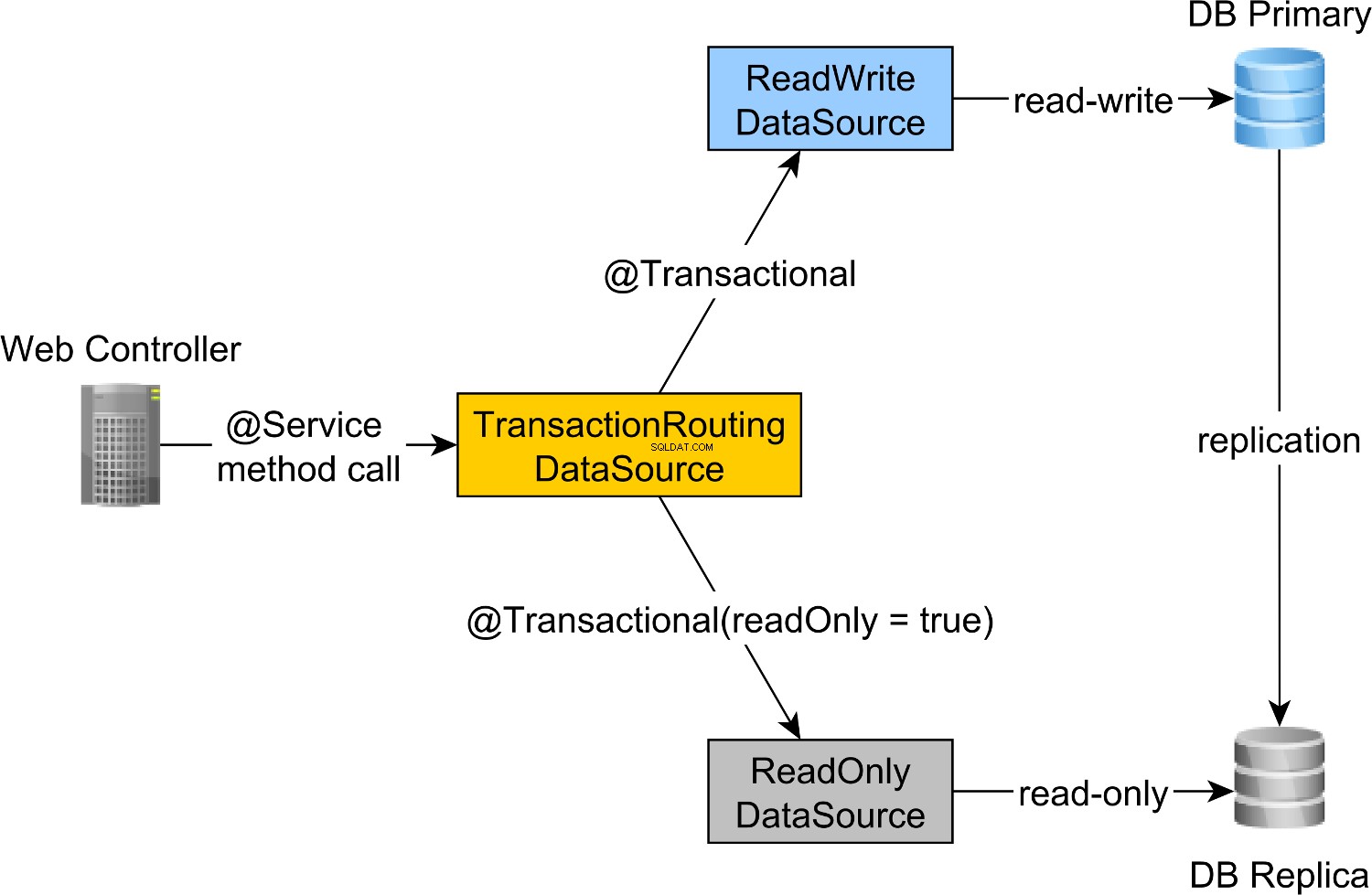
За да насочим транзакциите за четене-запис към основния възел и транзакциите само за четене към възела Replica, можем да дефинираме ReadWriteDataSource който се свързва с първичния възел и ReadOnlyDataSource които се свързват с възела Replica.
Маршрутизирането на транзакциите за четене-запис и само за четене се извършва от Spring AbstractRoutingDataSource абстракция, която се реализира от TransactionRoutingDatasource , както е илюстрирано от следната диаграма:
TransactionRoutingDataSource е много лесен за изпълнение и изглежда по следния начин:
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
По принцип проверяваме Spring TransactionSynchronizationManager клас, който съхранява текущия транзакционен контекст, за да провери дали текущо изпълняваната Spring транзакция е само за четене или не.
determineCurrentLookupKey методът връща стойността на дискриминатора, която ще се използва за избор на четене-запис или само за четене JDBC DataSource .
Пролетна конфигурация на JDBC DataSource за четене-запис и само за четене
DataSource конфигурацията изглежда по следния начин:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
/META-INF/jdbc-postgresql-replication.properties ресурсния файл предоставя конфигурацията за JDBC DataSource за четене-запис и само за четене компоненти:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
jdbc.url.primary свойството дефинира URL адреса на основния възел, докато jdbc.url.replica дефинира URL адреса на възела Replica.
readWriteDataSource Компонентът Spring дефинира JDBC DataSource за четене и запис докато readOnlyDataSource компонент дефинира JDBC DataSource само за четене .
Имайте предвид, че както източниците на данни за четене-запис, така и само за четене използват HikariCP за обединяване на връзки.
actualDataSource действа като фасада за източниците на данни за четене-запис и само за четене и се реализира с помощта на TransactionRoutingDataSource полезност.
readWriteDataSource се регистрира с помощта на DataSourceType.READ_WRITE ключ и readOnlyDataSource използвайки DataSourceType.READ_ONLY ключ.
Така че, когато изпълнявате четене-запис @Transactional метод, readWriteDataSource ще се използва, докато се изпълнява @Transactional(readOnly = true) метод, readOnlyDataSource вместо това ще се използва.
Имайте предвид, че
additionalPropertiesметодът дефинираhibernate.connection.provider_disables_autocommitСвойство Hibernate, което добавих към Hibernate, за да отложа придобиването на база данни за RESOURCE_LOCAL JPA транзакции.Не само, че
hibernate.connection.provider_disables_autocommitви позволява да използвате по-добре връзките към базата данни, но това е единственият начин, по който можем да накараме този пример да работи, тъй като без тази конфигурация връзката се придобива преди извикване наdetermineCurrentLookupKeyметодTransactionRoutingDataSource.
Останалите компоненти на Spring, необходими за изграждане на JPA EntityManagerFactory се дефинират от AbstractJPAConfiguration базов клас.
По принцип actualDataSource допълнително се обвива от DataSource-Proxy и се предоставя на JPA EntityManagerFactory . Можете да проверите изходния код на GitHub за повече подробности.
Време за тестване
За да проверим дали маршрутизирането на транзакциите работи, ще активираме дневника на заявките на PostgreSQL, като зададем следните свойства в postgresql.conf конфигурационен файл:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
log_min_duration_statement настройката на свойството е за регистриране на всички PostgreSQL изрази, докато вторият добавя името на базата данни към SQL дневника.
И така, при извикване на newPost и findAllPostsByTitle методи, като този:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
Можем да видим, че PostgreSQL регистрира следните съобщения:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
Регистрационните оператори, използващи high_performance_java_persistence префиксът се изпълняваше на първичния възел, докато тези, използващи high_performance_java_persistence_replica на възела Replica.
Така че всичко работи като чар!
Целият изходен код може да бъде намерен в моето високопроизводително хранилище на Java Persistence GitHub, така че можете да го изпробвате и вие.
Заключение
Трябва да сте сигурни, че сте задали правилния размер за вашите пулове за връзки, защото това може да направи огромна разлика. За това препоръчвам да използвате Flexy Pool.
Трябва да сте много усърдни и да се уверите, че маркирате съответно всички транзакции само за четене. Необичайно е, че само 10% от вашите транзакции са само за четене. Възможно ли е да имате такова приложение за най-много записване или да използвате транзакции за запис, при които издавате само изрази за заявка?
За пакетна обработка определено се нуждаете от транзакции за четене и запис, така че не забравяйте да активирате пакетирането на JDBC, като това:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
За пакетиране можете също да използвате отделен DataSource който използва различен пул за връзки, който се свързва с основния възел.
Просто се уверете, че общият ви размер на връзката на всички пулове за връзки е по-малък от броя на връзките, с които е конфигуриран PostgreSQL.
Всяко групово задание трябва да използва специална транзакция, така че се уверете, че използвате разумен размер на партидата.
Нещо повече, искате да задържите заключванията и да завършите транзакциите възможно най-бързо. Ако пакетният процесор използва едновременно обработващи работници, уверете се, че размерът на асоциирания пул за връзки е равен на броя работници, така че те да не чакат другите да освободят връзките.